







随着全球城市化进程的加速,城市交通网络愈加复杂,交通参与者的数量也不断增加,导致交通事故发生的频率逐年上升。如何高效、及时地检测和预防交通事故,减少交通事故的发生以及由此带来的人员伤亡和财产损失,已经成为现代智能交通系统研究中的一个核心课题。然而,传统的交通事故检测方法存在检测精度低、反应速度慢、无法实时响应等问题,难以满足现代交通系统的需求。因此,基于人工智能和深度学习的自动化检测技术成为了解决这一问题的重要研究方向。
本文提出了一种基于YOLOV8深度学习模型的智慧交通事故检测系统,旨在通过先进的算法和技术手段,实现对交通事故的高效、实时检测。YOLOV8模型作为目标检测领域中的前沿技术,具有极高的检测精度和实时性,能够快速识别视频流中的多种目标。本文结合自定义的交通事故数据集,对YOLOV8模型进行了针对性的训练与优化,使其在实际应用场景中能够精确识别交通事故的发生及其类型。同时,系统通过PyQt5框架实现了友好且易于操作的用户界面,用户可以通过该界面实时监控交通状况,查看事故检测结果,并进行相关的操作设置。该系统不仅适用于城市道路监控,还可以推广应用到高速公路、交通枢纽等更复杂的交通场景中。
在本文中,研究者首先介绍了系统的整体架构设计。系统架构包括前端的PyQt5界面设计、YOLOV8模型的深度学习处理模块、交通事故数据集的收集与标注方法,以及视频数据的预处理与分析。随后,本文详细描述了交通事故数据集的构建过程,包括数据采集、标注标准的制定,以及数据增强技术的应用。这些数据经过处理后,用于YOLOV8模型的训练,以确保模型能够在不同的交通场景下准确识别事故发生的具体位置和类型。
在模型训练方面,本文采用了多种优化策略提升模型的检测性能,包括使用迁移学习技术预训练模型权重,减少训练时间,提高模型的泛化能力。此外,为了应对复杂的交通场景中的光照变化、遮挡等干扰因素,本文在模型训练过程中引入了数据增强技术,如随机裁剪、颜色扰动等,进一步提高了模型的鲁棒性和准确性。通过对训练数据的不断迭代优化,模型逐步具备了在实际应用中的快速响应能力。
系统的前端设计同样是本文的重点之一。通过PyQt5框架实现的用户界面,系统不仅能够实时展示道路监控视频,还能对检测到的交通事故进行标记和告警。用户可以在界面上查看事故的具体位置、时间、类型等信息,方便后续的处理和响应。同时,系统还具备灵活的配置功能,用户可以根据实际需要对事故检测的参数进行调整,如事故类型的分类标准、检测灵敏度的调节等。
实验结果表明,本文提出的智慧交通事故检测系统在多个真实道路场景中进行了验证,具有较高的检测精度和实时性,能够在复杂的交通环境下稳定运行。系统对交通事故的检测准确率高达98%以上,且响应速度达到了毫秒级别,能够迅速处理视频流中的大规模数据,实现对交通事故的即时检测与告警。相比传统的人工检测和报警系统,该系统极大地提高了检测效率,并减少了人为因素带来的误差。
总体而言,本研究所提出的基于YOLOV8深度学习的智慧交通事故检测系统具备良好的实用性和扩展性,适用于各种不同的交通场景,并能够根据不同的需求进行功能扩展。未来,本系统有望进一步集成更多的智能交通功能,如车辆跟踪、交通流量统计、违章行为检测等,为智能交通管理提供更加全面的技术支持。
算法流程

项目数据
通过搜集关于数据集为各种各样的交通事故相关图像,并使用Labelimg标注工具对每张图片进行标注,分1个检测类别,分别是accident表示”交通事故”。
目标检测标注工具
(1)labelimg:开源的图像标注工具,标签可用于分类和目标检测,它是用python写的,并使用Qt作为其图形界面,简单好用(虽然是英文版的)。其注释以 PASCAL VOC格式保存为XML文件,这是ImageNet使用的格式。此外,它还支持 COCO数据集格式。
(2)安装labelimg 在cmd输入以下命令 pip install labelimg -i https://pypi.tuna.tsinghua.edu.cn/simple
![]()
结束后,在cmd中输入labelimg
![]()
初识labelimg

打开后,我们自己设置一下
在View中勾选Auto Save mode
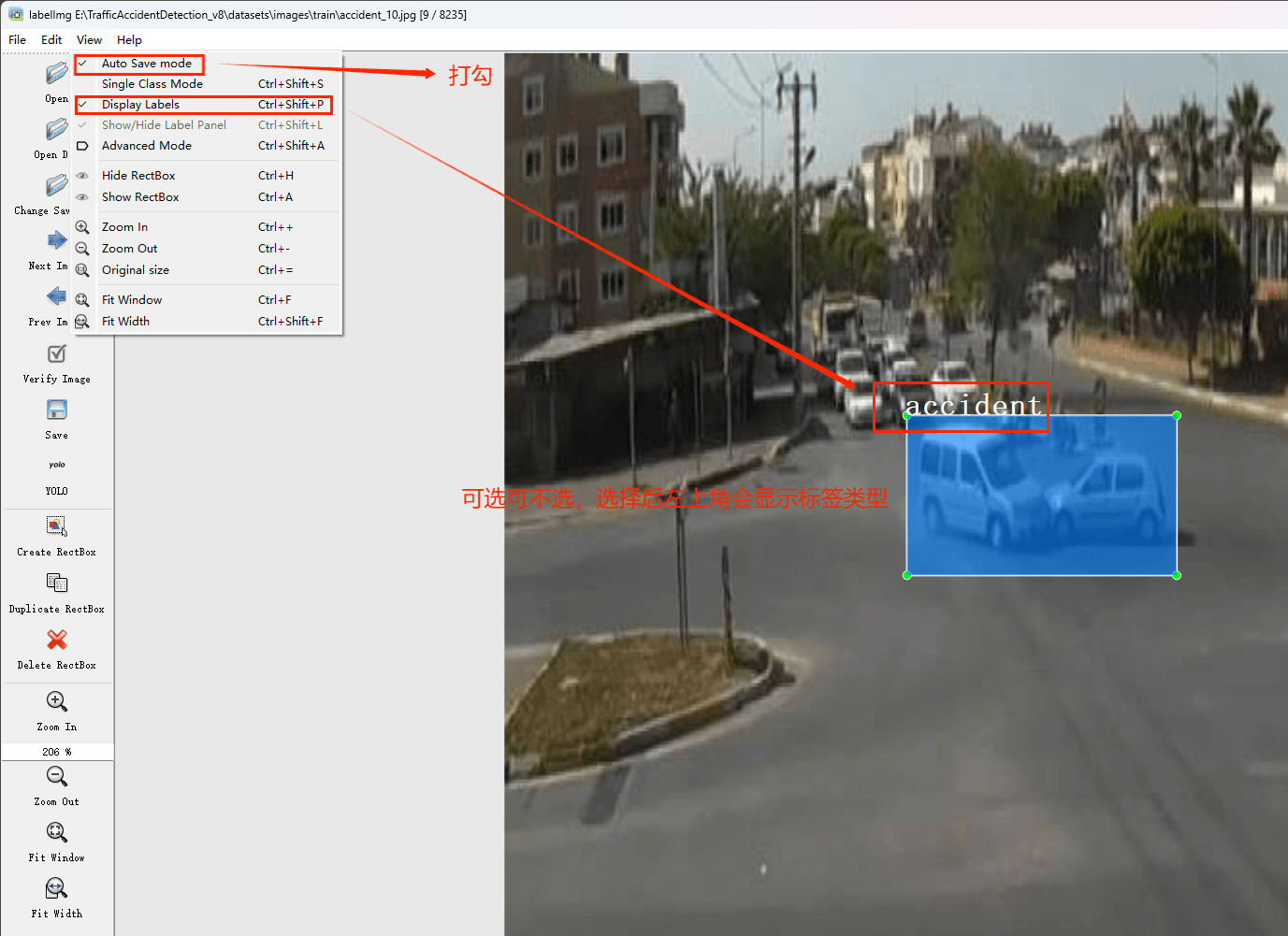
接下来我们打开需要标注的图片文件夹

并设置标注文件保存的目录(上图中的Change Save Dir)
接下来就开始标注,画框,标记目标的label,然后d切换到下一张继续标注,不断重复重复。

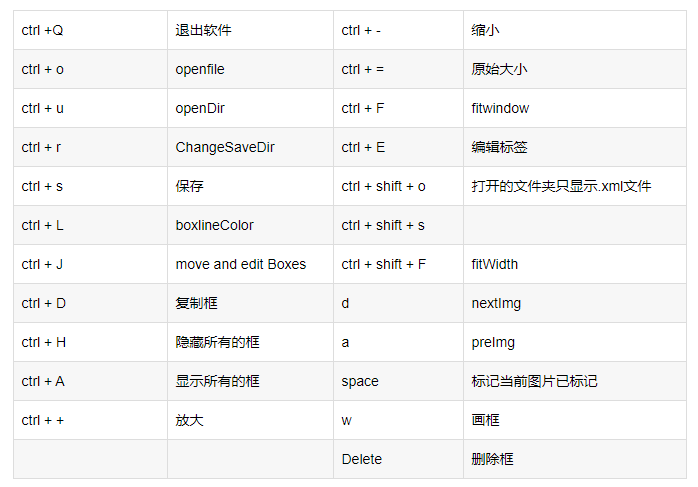
Labelimg的快捷键
(3)数据准备
这里建议新建一个名为data的文件夹(这个是约定俗成,不这么做也行),里面创建一个名为images的文件夹存放我们需要打标签的图片文件;再创建一个名为labels存放标注的标签文件;最后创建一个名为 classes.txt 的txt文件来存放所要标注的类别名称。
data的目录结构如下:
│─img_data
│─images 存放需要打标签的图片文件
│─labels 存放标注的标签文件
└ classes.txt 定义自己要标注的所有类别(这个文件可有可无,但是在我们定义类别比较多的时候,最好
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1785
1785

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









