







在人工智能迅猛发展的时代,每一次技术突破都如同在行业湖面投下巨石,激起千层浪。2025 年 1 月 20 日,DeepSeek-R1 震撼发布,迅速点燃 AI 社区的热情,成为万众瞩目的焦点。DeepSeek-R1 的卓越表现引发广泛热议,相信大家对它充满好奇。那么,这些模型背后有着怎样的诞生逻辑?它们是如何训练而成?不同模型之间又存在哪些区别,各自适用于何种场景?今天,我们将用最简洁易懂的语言,带你快速洞悉 DeepSeek-R1 的强大之处。
★ 目录 ★
| 一、深入了解 DeepSeek 模型 二、什么是蒸馏模型 三、上下文窗口的重要性与显存估算 四、在 ZStack AIOS 平台部署 DeepSeek-R1-Distill-Qwen-7B 五、模型能力评测:DeepSeek-R1-Distill-Qwen-7B 六、蒸馏版 7B 模型的适用场景与优势 七、展望:更大参数模型的部署策略 |
一、深入了解 DeepSeek 模型
(1)什么是推理模型(Reasoning model)
-
推理模型的定义,是指 AI 领域能模拟人类逻辑思维与推理的模型,如 Deepseek - R1。它基于深度学习架构,融合多领域技术,经大量数据训练构建知识表征,运用强化学习在 “尝试 - 反馈” 中优化策略,在处理复杂问题时 主动探索、逻辑推导。
-
非推理模型如 DeepSeek - V3,是大语言稠密模型,更多基于已学习到的语言模式和统计规律处理任务。
(2)DeepSeek-V3、R1、蒸馏和量化模型的关系
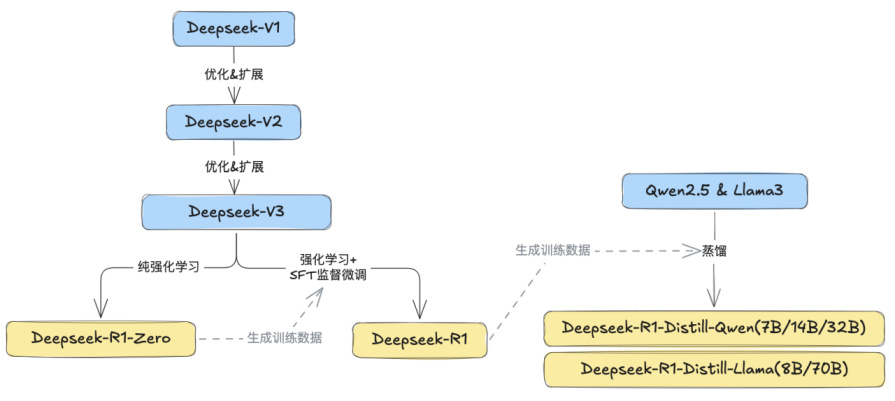
最近,Deepseek 因为 R1 受到了全球瞩目,我们按时间线快速回顾 Deepseek 模型的发展历程:
-
2024 年 1 月发布 Deepseek-V1(67B),这是 Deepseek 第一个公开的开源模型。
-
2024 年 6 月发布 Deepseek-V2(236B)。新增了两个新颖的技术特色:多头注意力、MOE 专家混合,显著提升推理速度和性能,为 V3 奠定了基础。
-
2024 年 12 月发布 Deepseek-V3(671B),其参数量更为庞大,且能更好地在多 GPU 间平衡负载。
-
2025 年 1 月发布了 R1 系列模型:
-
Deepseek-R1-zero( 671B),这是一个推理模型(Reasoning Model),使用强化学习(Reinforcement Learning,简称“RL”)训练模型,使其能围绕目标自行探索。
-
Deepseek-R1( 671B),结合了强化学习和监督微调,推理效果极大提升,表现接近全球领先闭源模型 OpenAI 的 O1,而其运行成本相比O1降低了惊人的96%。
-
Deepseek-R1-Distill-Qwen/llama 系列,训练参数量有多种,是 Qwen2.5 和 Llama3 模型经过 R1 “调教” 后生成的推理模型,满足了更多企业轻量化需求。
-
-
2025 年 2 月,另一个模型研究团队 Unsloth 发布了基于 R1 的量化模型系列:
-
Deepseek-R1-GGUF 系列,GGUF 格式可以更紧凑地存放模型参数,减少磁盘占用空间,加速模型的启动与运行。
-
Deepseek-R1-Distill-Qwen/llama-Int4/Int8 系列,采用了低比特量化,将原本模型的数据精度降低到 4 bit或 8 bit,适用于资源受限的硬件环境。
-
从 Deepseek 模型的发展可以看出,R1 并非由某一种或两种训练方法堆积而成,而是从 V1 开始,经由多个版本的模型互相构建、融合多种训练方法、逐步进化而来的推理模型。更值得称赞的是,DeepSeek-R1 秉持着开源精神,免费开放给全球开发者使用,让更多的研究人员、企业可以更低门槛使用先进的模型,推动了全球AI技术发展,被图灵奖得主、Facebook 首席人工智能科学家杨立昆称赞为 “开源战胜闭源”。
(3)什么是模型蒸馏
因为Deepseek-R1的参数量非常大,部署要求非常高,为了在小参数模型中引入长思维链推理能力,DeepSeek 团队引入了蒸馏技术。模型蒸馏就像是一场知识的传承,我们以 Deepseek-R1-Distill-Qwen2.5-7B 为例简单阐述蒸馏过程。
-
选择对象:首先选择一名优秀的学生Qwen,打算对它进行推理增强训练。强大的 R1会作为 “老师模型”,有着丰富的知识储备和卓越的推理能力。
-
准备工作:在蒸馏过程开启时,需准备大量训练数据,这些数据是模型学习的基础,随后将教师模型 R1 与学生模型 Qwen 同时置于训练环境中。
-
训练过程:教师模型 R1 对输入数据进行处理并生成输出,其输出包含了模型对数据特征的提取与理解。学生模型 Qwen 在学习原始数据的同时,会通过损失函数计算自身输出与教师模型输出的差异,就像学生模仿老师解题思路一样,不断调整自身参数以最小化这种差异。例如在分类任务中,教师模型输出各类别的概率分布,学生模型则努力模仿该分布,从而学习到教师模型的知识与推理模式。经过多轮迭代训练,学生模型 Qwen 的推理能力得到显著提升,最终生成有推理能力的 Qwen 模型。
</
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1943
1943

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









