







360智算中心是一个融合了人工智能、异构计算、大数据、高性能网络、AI平台等多种技术的综合计算设施,旨在为各类复杂的AI计算任务提供高效、智能化的算力支持。360智算中心不仅具备强大的计算和数据处理能力,还结合了AI开发平台,使得计算资源的使用更加高效和智能化。
360内部对于智算中心的核心诉求是性能和稳定性,本文将深入探讨360智算中心在万卡GPU集群中的落地实践过程,包括算力基础设施搭建、集群优化、AI开发平台建设、以及训练和推理加速的实现。
01
基础设施建设
1.1 服务器选型
以A100/A800为例,主机内拓扑采用如下
2片CPU
2张存储网卡(负责带内管理、访问存储)
4块PCIe Gen4 Switch 芯片
6块NVSwitch 芯片
8块GPU芯片
4张IB网卡
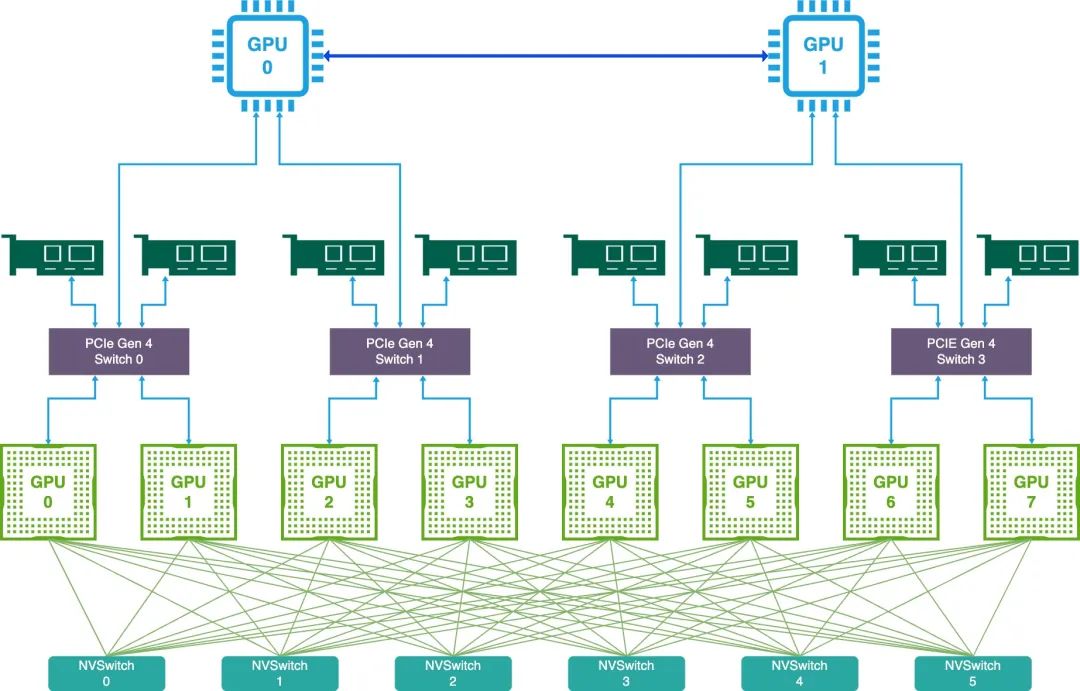
2张存储网卡采用的是25Gb/s的网卡,通过PCIe直连CPU,主要有2个用途,第一个是带内管理,如ssh登录、监控采集等,第二个是访问分布式存储,如读取训练数据、写Checkpoint等。大语言模型训练过程中,对于文本类数据读取量级要求并不高,且一般都会采用异步加载的方式,此时25Gb/s的网卡带宽可以满足需求。但是模型训练过程中保存checkPoint时,会有瞬时大量写流量,此时25Gb/s的网卡会成为瓶颈,阻塞训练的正常进行。为了平衡成本与性能的问题,我们内部采用了软硬件结合的方案,首先两张网卡采取bond4的网卡绑定方式,可以将整体带宽提高到50Gb/s,虽然牺牲了一定的容错能力,但是极大提高了网络的吞吐量。另外我们也在训练框架层做了2个方面的优化,第一个优化是通过分布式的方式存储checkpoint,将整个模型的checkpoint部分分别在不同的节点上保存以减少网卡的压力。第二个优化是多阶段异步保存,第一个阶段将模型与优化器从显存拷贝到内存,不阻塞模型的训练,第二个阶段将内存中的模型拷贝到分布式存储,其中第一个阶段结束后就可以继续训练了,第二个阶段可以在后台异步进行。软件层的优化主要是在基于网卡受限的场景下,通过减少checkpoint保存时间最大化GPU有效训练时长,最后经过验证,智脑7B的模型保存时间从最开始的383s降低到5s,性能提升约70倍。
8块GPU通过6块NVSwitch芯片全互联,在A100中每块GPU与每块NVSwitch芯片由2条双向25GB/s的NVLink3连接,所以每块GPU共有12条双向25GB/s的lane,即12 25 2 = 600GB/s。A800在NVLink这里做了阉割,只有8条,所以变成了8 25 2 = 400GB/s,很多人都担心在大规模分布式训练时A800的NVLink会成为瓶颈,我们经过多次内部验证,至少在跑千卡训练任务时,NVLink并不是瓶颈。
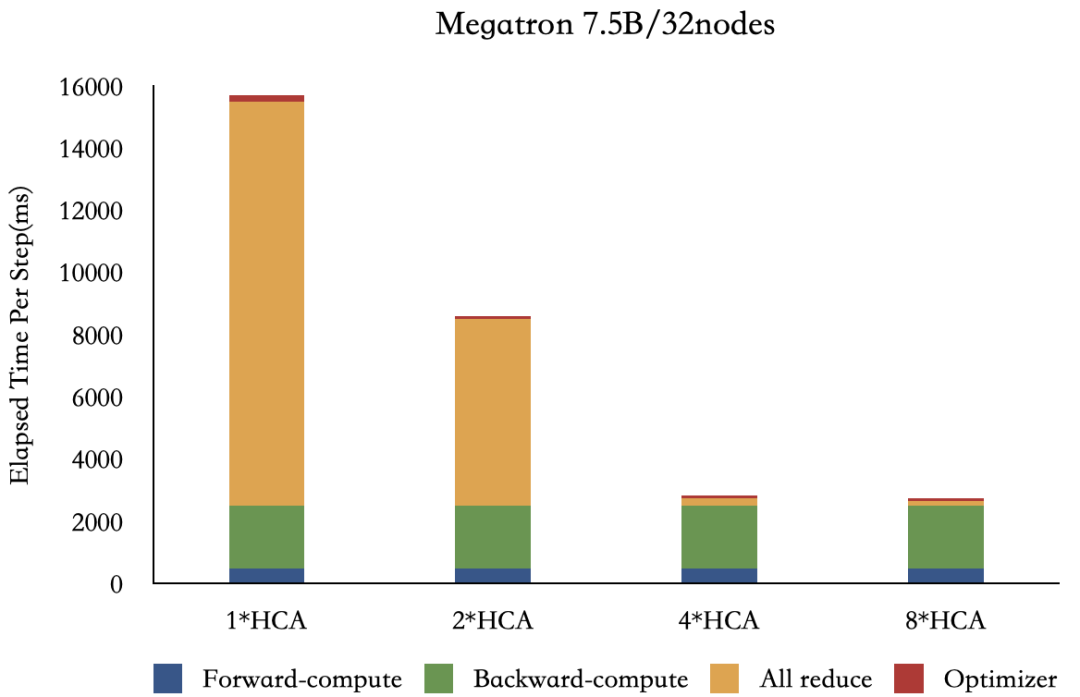
我们内部采用的是4张200Gb/s 的Mellanox CX6网卡,采用200Gb/s网卡的原因是同主机GPU与相邻的网卡之间通过PCIe Gen4 Switch芯片通信,PCIe Gen4 x16的通信带宽是单向32GB/s,网卡的通信性能是200Gb/s = 25GB/s,接近PCIe的通信性能,如果采用400Gb/s的CX7网卡,此时受限于PCIe Gen4的带宽,CX7的网卡性能很难发挥出来。NVIDIA推荐的单台A100配备8张CX6网卡,我们经过验证和调研,如上图所示,Megatron-LM在32台A100节点上跑7.5B模型的时候,4张网卡单次迭代时间是2张网卡一半,但是8张网卡相比于4张网卡提升非常小,因此为了节约成本,我们采用了4网卡的方案。硬件拓扑为每块PCIe Gen4 Switch配备一张网卡,与之相邻的2块A800可以启用GPU Direct RDMA通信,可以通过nvidia-smi topo -m佐证查看,经过实际验证,开启了GDR后大模型训练速度最高可以提升50%。
1.2 网络建设
传统的数据中心网络一版聚焦在对外提供服务的流量模型设计,流量主要是数据中心与外部流量交互,即以南北向流量(数据中心外的流量)为主,东西向流量(数据中心内部流量)为辅。而智算中心的流量则以东西向流量为主,南北向网络为辅。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1192
1192

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









