







简化链式规则,预测概率
对于1-gram,其假设是P(wn|w1w2…wn-1)≈P(wn|wn-1)
对于2-gram,其假设是P(wn|w1w2…wn-1)≈P(wn|wn-1,wn-2)
对于3-gram,其假设是P(wn|w1w2…wn-1)≈P(wn|wn-1,wn-2,wn-3)
通常,2gram的情况:
我爱/爱自/自然/然语/语言/言处/处理
但是,中文在实际中,使用短语的组合;英文在实际中,使用单词的组合。
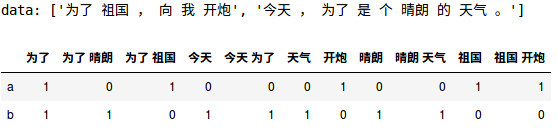
ngram的python实现,基于sklearn
from sklearn.feature_extraction.text import CountVectorizer
import pandas as pd
import jieba
data = ["为了祖国,向我开炮", "今天,为了是个晴朗的天气。"]
data = [" ".join(jieba.lcut(e)) for e in data]
print("data: %s" % data)
vec = CountVectorizer(min_df=1, ngram_range=(1,2))
X = vec.fit_transform(data)
# X.toarray(), vec.get_feature_names() 考虑了item的过滤
df = pd.DataFrame(X.toarray(), index=['a','b'],columns=vec.get_feature_names())
df.head()
code说明,对每个句子分词,得到每个句子对应的ngram,得到所有的ngram tokenization(分词)。















 1985
1985











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









