







论文:《Gen6D: Generalizable Model-Free 6-DoF Object Pose Estimation from RGB Images》
Code:https://github.com/liuyuan-pal/gen6d (469 star)
摘要:
-
现有的可推广姿态估计器要么需要高质量的对象模型,要么在测试时需要额外的深度图或对象掩码,这大大限制了其应用范围。
为了满足实际应用中的需求,我们认为姿态估计器应该具有以下性质:
- 可推广:姿态估计器可以应用于任意对象,而无需对该对象或其类别进行训练;
- 无模型:当推广到一个新物体时,估计器只需要该物体的一些已知姿态的参考图像来定义物体参考坐标系,但不依赖于物体的3D模型;
- 简单输入:当估计物体姿态时,估计器仅将RGB图像作为输入,而不需要额外的物体遮罩或深度图。
-
提出了一种可推广的无模型6-DoF物体姿态估计器,称为Gen6D,给定具有已知姿态的任意对象的输入参考图像,Gen6D能够在任何查询图像中直接预测其对象姿态。该姿态估计器是model-free的,只需要新物体的一些RGB姿态图像,不需要对象模型,在测试时也不需要额外的深度图和对象掩码,就能够在任意环境中准确预测物体的姿态。
对于常用的三种6D位姿估计方法,其中通过回归对旋转和平移的直接预测大多局限于特定的实例或类别,难以推广到新的未知对象上。同时,由于缺乏3D模型,基于PnP的方法没有3D关键点来构建2D-3D对应关系,因此也与model-free的设定不兼容。因此,我们将图像匹配应用于姿态估计的框架中,该框架可以通过学习通用的图像相似性度量来推广到新的未知物体。
-
效果:引入了一个新的数据集,称为通用无模型对象姿态数据集(GenMOP),它包含不同环境和照明条件下对象的视频序列。该方法选择一个序列作为参考图像,选择同一对象的其余序列作为测试查询图像。实验表明,在没有对这些对象进行训练的情况下,该方法在GenMOP数据集和另一个无模型MOPED[41]数据集上仍然优于实例特定估计器PVNet[42]。在LINEMOD数据集上,该方法的可推广姿态估计器获得了与需要用过多渲染图像训练的实例特定估计器相当的结果。
网络架构:
-
输入:具有已知相机姿态的物体的Nr个图像,称为参考图像;
-
输出:查询图像中物体的姿态。
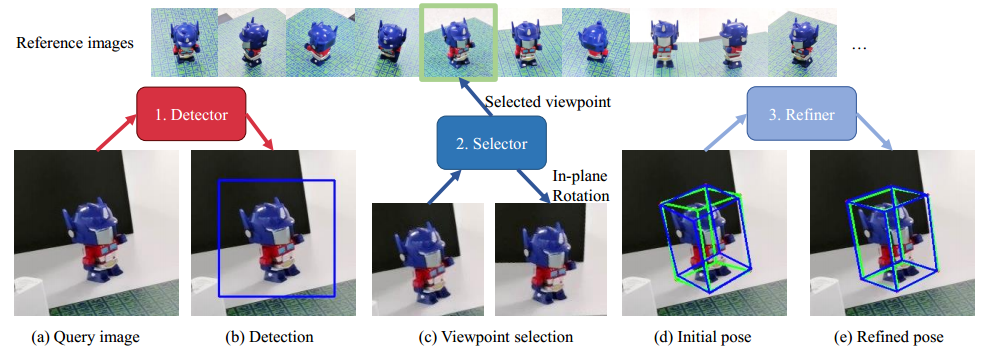
框架由一个对象检测器、一个视点选择器和一个姿态细化器组成。给定参考图像和查询图像,对象检测器(类似于《Target driven instance detection》的方法)首先通过将参考图像与查询图像相关来检测对象区域并估计初始平移;然后,视点选择器将查询图像与参考图像相匹配,选择最相似的参考图像并估计平面内旋转来找到初始旋转,以产生粗略的初始姿态;最后,初始姿态由姿态细化器进一步细化,以搜索精确的对象姿态。
**对象检测器:**3.1节

**视点选择器:**3.2节
当参考图像稀疏且包含杂乱背景时,如何设计视点选择器是一个挑战。现有的图像匹配方法[58,69,57,22,2]由于两个问题而难以处理这个问题:
-
这些图像匹配方法将图像嵌入到特征向量中,并使用特征向量的距离来计算相似性,其中杂乱的背景会干扰嵌入的特征向量,从而严重降低精度;
-
给定查询图像,可能不存在与查询图像具有完全相同视点的参考图像。在这种情况下,将有多个看似合理的参考图像,选择器必须选择视点最近的一个作为查询图像,这通常非常模糊,如下图所示。

为了解决视点选择中的这些问题,我们建议使用神经网络将查询图像与每个参考图像进行逐像素的比较,以产生相似性得分,并选择具有最高相似性得分的参考图像。这种逐像素比较使我们的选择器能够集中在对象区域,并减少杂乱背景的影响。此外,我们添加了全局归一化层和自关注层,以共享不同参考图像之间的相似性信息。这两种层使得每个参考图像能够相互交换,这为选择器选择最相似的参考图像提供了上下文信息。
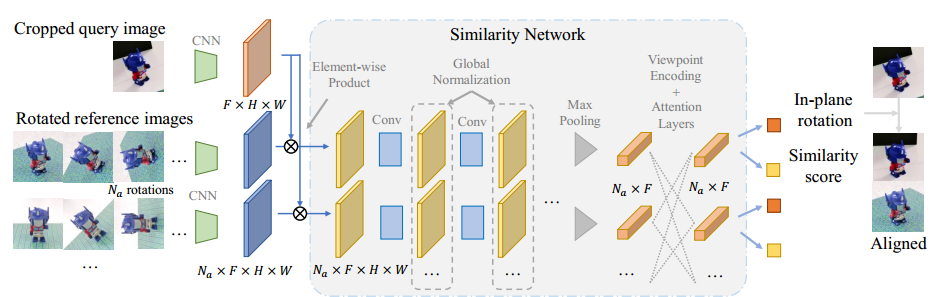
姿态细化器:
姿态细化器的主要挑战是对象模型的不可用性。现有的姿态细化器[29,74]基于渲染和比较,在输入姿态上渲染图像,然后用查询图像匹配渲染的图像以细化输入姿势。然而,如果没有对象模型,就很难在任意姿态上渲染高质量的图像,这使得这些细化方法在无模型设置中不可行。
为了解决这个问题,我们提出了一种新的基于三维体积的姿态细化方法。给定一个查询图像和一个输入姿势,我们找到了几个接近输入姿势的参考图像。这些参考图像被投影回3D空间中以构建特征体积。然后,通过3D CNN将构建的特征体积与从查询图像投影的特征相匹配,以细化输入姿态。与以前的姿势精简器[29,74]相比,我们的姿势精简机避免了渲染任何新图像。同时,构建的三维特征体使我们的方法能够推断出三维空间中的三维姿态精化。相比之下,以前的姿态细化器[29,74]仅依赖于2D图像特征来回归3D相对姿态,这不太准确,尤其是对于看不见的物体。















 313
313











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









