







论文:《DSC-PoseNet: Learning 6DoF Object Pose Estimation via Dual-scale Consistency》
摘要:
-
解决问题:标注困难。
-
提出了一个两步姿态估计框架,仅从RGB图像和2D对象边界框注释中获得6D对象姿态。(使用边界框来确保在图像中正确识别感兴趣的对象,而不是高度依赖合成数据的真实感)
-
在第一步中,该框架以弱监督学习的方式从真实数据和合成数据中分割对象,并且分割掩模将充当姿态估计的先验。
- 通过在合成图像上训练分割网络来初始化分割网络。受[4,48]的启发,使用分割网络来预测未标记真实数据的伪掩码,并在合成和伪标记数据上重新训练网络。由于背景中的一些像素可能被识别为前景像素,我们充分利用我们的2D边界框来去除异常值,从而促进学习分割。
-
在第二步中,设计了一个自监督双尺度(dual-scale)姿态估计网络,即DSC-PoseNet,通过使用微分渲染器来预测对象姿态。具体来说,DSC-PoseNet (灵感:DSC-PoseNet预测的同一物体的关键点位置在不同尺度上应该是一致的,因此提出了这么一个双尺度关键点一致性约束)
- 首先通过比较分割掩模和渲染的可见物体掩模来预测原始图像尺度下的物体姿态。
- 然后,将对象区域调整为固定比例,以再次估计姿势。以这种方式,消除了大的尺度变化,专注于旋转估计,从而促进了姿态估计。
- 此外,利用初始姿态估计来生成伪标签,以自监督的方式训练DSCPoseNet。
将这两个尺度上输出的姿态估计结果进行集成,以提高模型的鲁棒性,作为模型的最终姿态估计。
-
-
效果:该方法在很大程度上优于在合成数据上训练的最先进的模型,甚至与几种完全监督的方法不相上下。
网络架构:
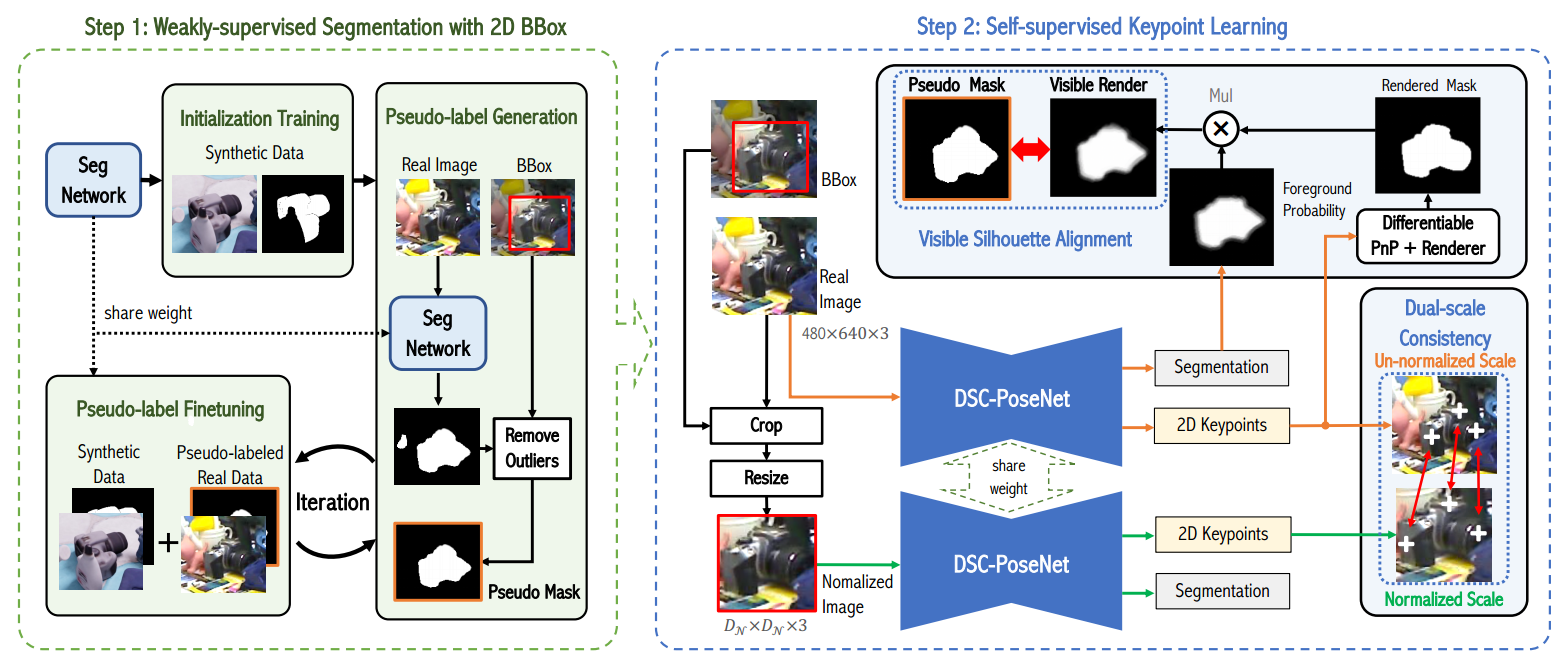
3.1节 弱监督分割学习
目标是从真实图像的粗略2D BBox注释中获得像素级的对象分割结果(分割可以提供详细的对象轮廓,从中可以粗略地确定对象姿态)。
首先通过完全监督的方式在合成数据上训练分割网络来初始化网络;初始化后,使用网络为所有BBox注释的真实图像生成伪标签,然后在伪标签的真实图像上微调网络。迭代伪标签生成和微调,直到该分割网络收敛。
在对合成数据初始化网络或对伪标记的真实数据进行微调后,为所有真实图像生成(或更新)伪分割标签,并附加增强,即多尺度输入和左右翻转。由于背景中的一些像素可能被识别为前景,这里充分利用2D BBox注释来去除这些异常值,从而促进网络微调。我们进一步将置信度低的像素设置为不确定像素,并避免计算它们的分割损失。
在最终迭代之后生成的伪标签将在下面的自监督姿态估计步骤中用作分割标签。
一些方法,如Self6D,在学习分割时不需要对象BBox,但它们要求合成图像的真实感。相反,我们使用粗略标记的BBox来弥合真实数据和合成数据之间的领域差距,而不是要求合成数据与真实数据相似。
3.2节 自监督的DSC-PoseNet
设计了一种新的自监督双尺度一致性姿态估计网络(DSC PoseNet)来预测关键点的位置,然后使用估计的关键点来预测真实图像中的物体姿态。
本文通过对真实数据中的对象尺度进行归一化来引入归一化尺度。换句话说,这里的关键点网络在未归一化和归一化尺度上预测关键点。因此,可以通过约束不同尺度之间的关键点一致性来提高尺度鲁棒性。
这里提出了两个自监督目标函数:
- 可见轮廓对齐(visible silhouette alignment,VSA),测量预测姿势的轮廓和真实图像中可见轮廓之间的对齐;
- 双尺度关键点一致性(dual-scale keypoint consistency,DKC),评估归一化图像尺度和非归一化尺度中的关键点估计一致性。
之前的关键点方法,为了解决遮挡问题,使用投票机制来预测关键点,但是投票过程是不可微的。 => 本文从所有对象像素回归2D关键点坐标,如下图。


除了关键点损失,这里还使用了一个辅助损失,偏移量损失:
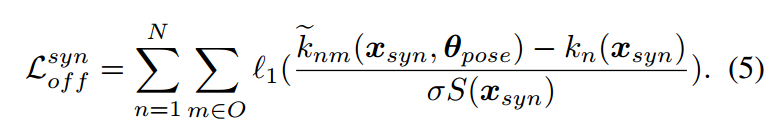
这个损失迫使DSC-PoseNet从每个前景像素回归精确的关键点。在学习关键点回归之前,可以使用偏移损失来预热DSCPoseNet,这有助于初始化关键点回归,从而稳定关键点注意力的学习。
双尺度关键点一致性:
对于真实数据,我们只有它的伪分割标签。因此,需要一种自监督的方法来从真实数据中学习关键点,而不需要姿态标注。直观地说,我们的DSC-PoseNet预测的同一物体的关键点位置在不同尺度上应该是一致的。因此,我们引入了一种用于姿态估计的双尺度关键点预测一致性约束。
对原图作transform变换和数据增强之后,关键点也应该作相应的变换,因此就引入了这两个相应的一致性约束。
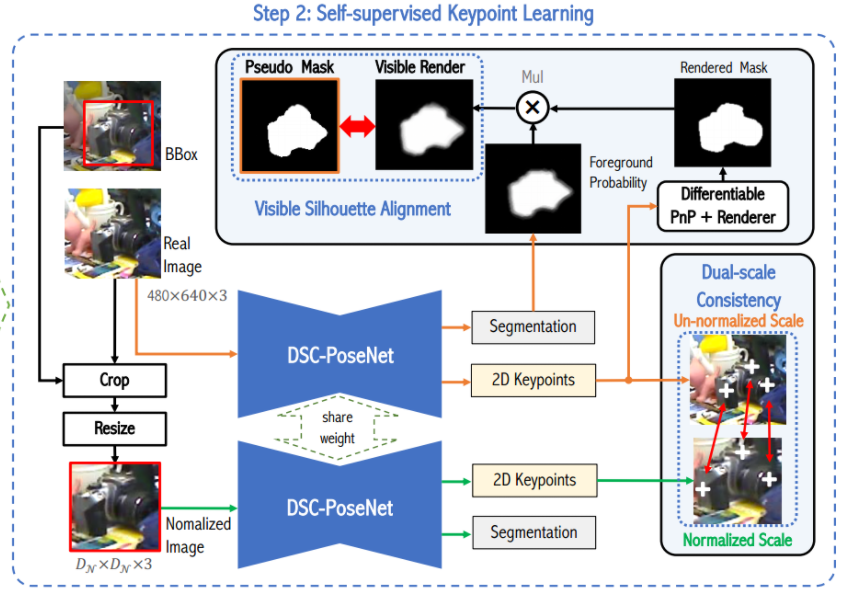
可见轮廓对齐:
使用预测的R、t、CAD模型、相机内参矩阵K,使用PyTorch3D[32]来渲染预测的物体掩膜。
使用第一步弱监督预测出来的伪分割结果作为真实图像的对象轮廓。但是这里有个问题,就是预测的分割结果是只有可见部分的,而渲染的物体掩膜是整个物体的轮廓,所以不能直接对齐。 => 使用DSC-PoseNet的分割分支选择渲染的掩膜的可见部分。具体实现如下:

至此,总的损失函数为:
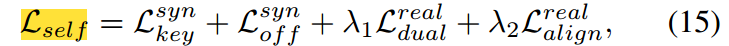















 4548
4548











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









