







理论知识
AlexNet 虽然很有效,但是并没有提供一个通用的模板来指导后续的研究人员设计新的网络
经典卷积神经网络的基本组成部分是下面这个序列:
- 带填充以保持分辨率的卷积层
- 非线性激活函数 ReLU
- 池化层
在一个 VGG 块中,由一系列卷积层组成,后面再加上用于空间下采样的最大池化层,在最初的 VGG 论文中,作者使用了 3x3 卷积核,填充为 1(保持尺寸)的卷积层,和带有 2x2 池化窗口,步幅为 2(每个块后的分辨率减半)的最大池化层
与 AlexNet、LeNet 一样, VGG 网络可以分为两个部分, 第一部分主要是由卷积层和池化层组成, 第二部分主要由全连接层组成
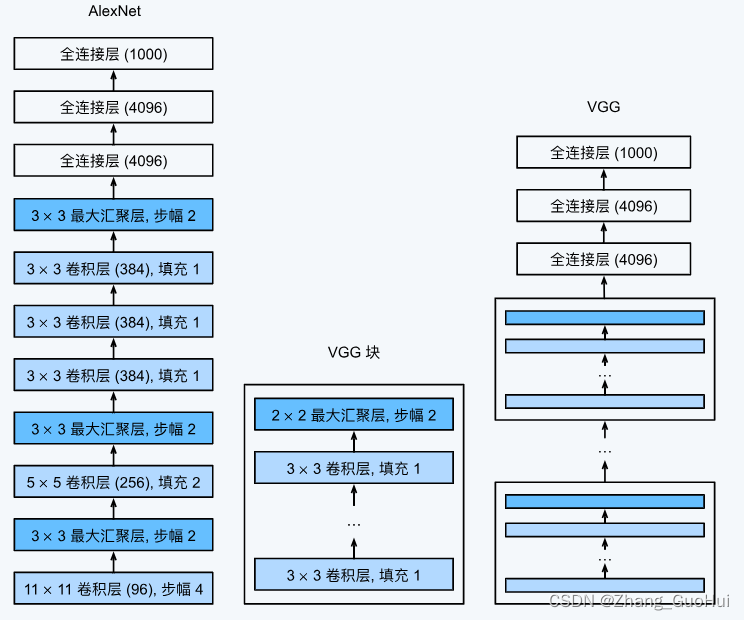
原始的 VGG 网络有五个卷积块, 其中前两个块中各有一个卷积层, 后三个块中包含两个卷积层, 第一个模块中有 64 个输出通道, 后续模块将输出通道翻倍, 直到达到 512, 该网络使用了 8 个卷积和 3 个全连接层, 也称为 VGG-11
代码实现
这里用到的数据集是FashionMNIST,但是做了一些小处理,将原来28x28的图片放大到了224x224,这是因为AlexNet用在ImageNet数据集上的,仅为了简单复现,不需要用到ImageNet数据集
import torch
import torchvision
import torch.nn as nn
from torch.utils.data import DataLoader
from tqdm import tqdm
from torchinfo import summary
import matplotlib.pyplot as plt
epochs = 10
batch_size = 128
lr = 0.001
device = 'cuda:0' if torch.cuda.is_available() else "cpu"
data_trans = torchvision.transforms.Compose([torchvision.transforms.ToTensor(),torchvision.transforms.Resize((224, 224))])
# toTensor = (torchvision.transforms.ToTensor(), torchvision.transforms.Resize((224, 224)))
train_dataset = torchvision.datasets.FashionMNIST("../00data", True, data_trans, download=True)
test_dataset = torchvision.datasets.FashionMNIST("../00data", False, data_trans, download=True)
train_dataloader = DataLoader(train_dataset, batch_size, True)
test_dataloader = DataLoader(test_dataset, batch_size, True)
# VGG块
def vgg_block(num_conv, input_channal, output_channal):
layer = []
for _ in range(num_conv):
layer.append(nn.Conv2d(input_channal, output_channal, 3, padding=1))
layer.append(nn.ReLU())
input_channal = output_channal
layer.append(nn.MaxPool2d(2, 2))
# return layer
return nn.Sequential(*layer)
blocks = ((1, 16), (1, 32), (2, 64), (2, 128), (2, 128))
def vgg():
last_output = 1
layer = []
for block in blocks:
layer.append(vgg_block(block[0], last_output, block[1]))
last_output = block[1]
# nn.Sequential()参数传的是list的时候,需要用*转化
return nn.Sequential(*layer, nn.Flatten(1), nn.Linear(last_output * 7 * 7, 4096), nn.ReLU(), nn.Dropout(),
nn.Linear(4096, 4096), nn.ReLU(), nn.Dropout(), nn.Linear(4096, 10))
vgg11 = vgg()
vgg11 = vgg11.to(device)
celoss = torch.nn.CrossEntropyLoss()
optimer = torch.optim.Adam(vgg11.parameters(), lr=lr)
train_loss_all = []
test_loss_all = []
train_acc = []
test_acc = []
for epoch in range(epochs):
test_loss = 0.0
train_loss = 0.0
right = 0.0
right_num = 0.0
for inputs, labels in tqdm(train_dataloader):
inputs = inputs.to(device)
labels = labels.to(device)
outputs = vgg11(inputs)
loss = celoss(outputs, labels)
train_loss += loss.detach().cpu().numpy()
optimer.zero_grad()
loss.backward()
optimer.step()
right = outputs.argmax(dim=1) == labels
right_num += right.sum().detach().cpu().numpy()
train_loss_all.append(train_loss / float(len(train_dataloader)))
train_acc.append(right_num / len(train_dataset))
with torch.no_grad():
right = 0.0
right_num = 0.0
for inputs, labels in tqdm(test_dataloader):
inputs = inputs.to(device)
labels = labels.to(device)
outputs = vgg11(inputs)
loss = celoss(outputs, labels)
test_loss += loss.detach().cpu().numpy()
right = outputs.argmax(dim=1) == labels
right_num += right.sum().detach().cpu().numpy()
test_loss_all.append(test_loss / float(len(test_dataloader)))
test_acc.append(right_num / len(test_dataset))
print(f'eopch: {epoch + 1}, train_loss: {train_loss / len(train_dataloader)}, test_loss: {test_loss / len(test_dataloader) }, acc: {right_num / len(test_dataset) * 100}%')
x = range(1, epochs + 1)
plt.plot(x, train_loss_all, label = 'train_loss', linestyle='--')
plt.plot(x, test_loss_all, label = 'test_loss', linestyle='--')
plt.plot(x, train_acc, label = 'train_acc', linestyle='--')
plt.plot(x, test_acc, label = 'test_acc', linestyle='--')
plt.legend()
plt.show()
vgg11 = vgg()
print(summary(vgg11 , (1, 1, 224, 224)))
==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
Sequential [1, 10] --
├─Sequential: 1-1 [1, 64, 112, 112] --
│ └─Conv2d: 2-1 [1, 64, 224, 224] 640
│ └─ReLU: 2-2 [1, 64, 224, 224] --
│ └─MaxPool2d: 2-3 [1, 64, 112, 112] --
├─Sequential: 1-2 [1, 128, 56, 56] --
│ └─Conv2d: 2-4 [1, 128, 112, 112] 73,856
│ └─ReLU: 2-5 [1, 128, 112, 112] --
│ └─MaxPool2d: 2-6 [1, 128, 56, 56] --
├─Sequential: 1-3 [1, 256, 28, 28] --
│ └─Conv2d: 2-7 [1, 256, 56, 56] 295,168
│ └─ReLU: 2-8 [1, 256, 56, 56] --
│ └─Conv2d: 2-9 [1, 256, 56, 56] 590,080
│ └─ReLU: 2-10 [1, 256, 56, 56] --
│ └─MaxPool2d: 2-11 [1, 256, 28, 28] --
├─Sequential: 1-4 [1, 512, 14, 14] --
│ └─Conv2d: 2-12 [1, 512, 28, 28] 1,180,160
│ └─ReLU: 2-13 [1, 512, 28, 28] --
│ └─Conv2d: 2-14 [1, 512, 28, 28] 2,359,808
│ └─ReLU: 2-15 [1, 512, 28, 28] --
│ └─MaxPool2d: 2-16 [1, 512, 14, 14] --
├─Sequential: 1-5 [1, 512, 7, 7] --
│ └─Conv2d: 2-17 [1, 512, 14, 14] 2,359,808
│ └─ReLU: 2-18 [1, 512, 14, 14] --
│ └─Conv2d: 2-19 [1, 512, 14, 14] 2,359,808
│ └─ReLU: 2-20 [1, 512, 14, 14] --
│ └─MaxPool2d: 2-21 [1, 512, 7, 7] --
├─Flatten: 1-6 [1, 25088] --
├─Linear: 1-7 [1, 4096] 102,764,544
├─ReLU: 1-8 [1, 4096] --
├─Dropout: 1-9 [1, 4096] --
├─Linear: 1-10 [1, 4096] 16,781,312
├─ReLU: 1-11 [1, 4096] --
├─Dropout: 1-12 [1, 4096] --
├─Linear: 1-13 [1, 10] 40,970
==========================================================================================
Total params: 128,806,154
Trainable params: 128,806,154
Non-trainable params: 0
Total mult-adds (G): 7.55
==========================================================================================
Input size (MB): 0.20
Forward/backward pass size (MB): 59.47
Params size (MB): 515.22
Estimated Total Size (MB): 574.90
==========================================================================================
训练结果
在colab上用T4这块GPU,跑了10代的训练结果,可以看到:大力出奇迹!
eopch: 1, train_loss: 0.8505474812567615, test_loss: 0.38755199426337134, acc: 85.19%
eopch: 2, train_loss: 0.3051844020959919, test_loss: 0.3352961511928824, acc: 88.36%
eopch: 3, train_loss: 0.2583148484545222, test_loss: 0.26205789797668216, acc: 90.5%
eopch: 4, train_loss: 0.2272117935232262, test_loss: 0.25101515688473663, acc: 90.85%
eopch: 5, train_loss: 0.2091959472944233, test_loss: 0.24549187106799475, acc: 91.53%
eopch: 6, train_loss: 0.1918035917905475, test_loss: 0.24119293491674376, acc: 91.59%
eopch: 7, train_loss: 0.17655339621023328, test_loss: 0.24114930950388125, acc: 91.39%
eopch: 8, train_loss: 0.1605123550589405, test_loss: 0.25649984765656386, acc: 91.21%
eopch: 9, train_loss: 0.14848462215809424, test_loss: 0.23790175958147533, acc: 91.98%
eopch: 10, train_loss: 0.1359619579351406, test_loss: 0.2570774865489972, acc: 91.96%














 406
406











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









