







理论知识
LeNet AlexNet VGG 都有一个共同的特征:通过一系列的卷积层和池化层来提取空间结构特征,然后通过全连接层来对特征的表征进行处理
NiN: 在每个像素的通道上分别使用多层感知机
卷积层的输入和输出由四维张量组成,张量的每个轴分别对应样本、通道、高度和宽度。另外,全连接层的输入和输出通常是分别对应于样本和特征的二维张量。
NiN 的想法是,在每个像素位置用一个全连接层,将权重连接到每个空间位置,可以视为 1 x1 卷积,或作为在每个像素位置上独立作用的全连接层。从另一个角度看,将空间维度中的每个像素是为一个样本,通道维数视作不同的特征
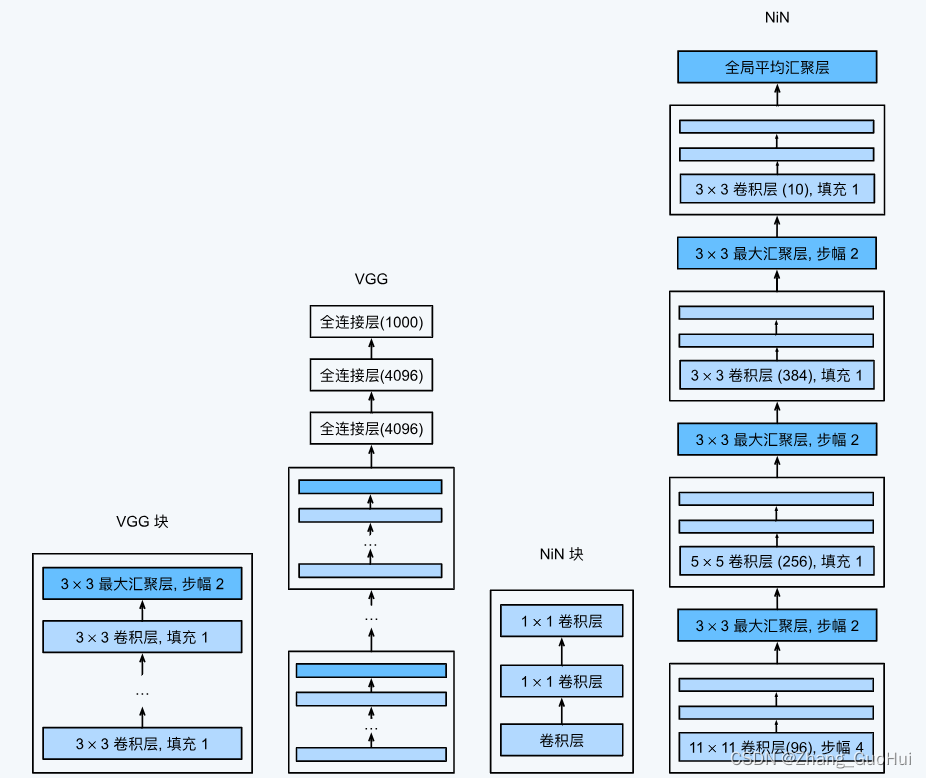
NiN 从一个普通的卷积层开始,后面是两个 1x1 卷积层,这两个 1 x1 卷积层充当带有 ReLU 激活函数的逐像素全连接层,第一层的卷积窗口形状通常由用户设置。随后的卷积窗口形状固定为 1x1
NiN 完全取消了全连接层,使用了一个 NiN 块,其输出通道等于标签类别的数量,最后放一个全局平均池化层(每个通道算出一个平均值),经过 softmax 生成一个对数概率
NiN 的优点是减少了模型所需的参数数量,但是加大了训练时间
代码实现
这里用到的数据集是FashionMNIST,但是做了一些小处理,将原来28x28的图片放大到了224x224,这是因为AlexNet用在ImageNet数据集上的,仅为了简单复现,不需要用到ImageNet数据集
import torch
import torchvision
import torch.nn as nn
from torch.utils.data import DataLoader
from tqdm import tqdm
from torchinfo import summary
epochs = 10
batch_size = 128
lr = 0.001
device = 'cuda:0' if torch.cuda.is_available() else "cpu"
data_trans = torchvision.transforms.Compose([torchvision.transforms.ToTensor(),torchvision.transforms.Resize((224, 224))])
# toTensor = (torchvision.transforms.ToTensor(), torchvision.transforms.Resize((224, 224)))
train_dataset = torchvision.datasets.FashionMNIST("../00data", True, data_trans, download=True)
test_dataset = torchvision.datasets.FashionMNIST("../00data", False, data_trans, download=True)
train_dataloader = DataLoader(train_dataset, batch_size, True)
test_dataloader = DataLoader(test_dataset, batch_size, True)
# 方法二实现NiN网络
# 卷积核大小 步幅 填充 输入通道 输出通道
blk_arc = ((11, 4, 0, 1, 96), (5, 1, 1, 96, 256), (3, 1, 1, 256, 384))
class NiN(nn.Module):
def __init__(self, nin_arc) -> None:
super().__init__()
self.layers = []
self.nin_blks(nin_arc)
self.network = nn.Sequential(*self.layers)
# x = torch.ones((1, 1, 224, 224))
# 输出每层输出结果形状
# for layer in self.layers:
# x = layer(x)
# print(layer.__class__.__name__, '\t', x.shape)
def nin_blk(self, num_conv, kernel_size, stride, padding, inchannal, outchannal):
layer = []
for _ in range(num_conv):
layer.append(nn.Conv2d(inchannal, outchannal, kernel_size, stride, padding))
layer.append(nn.ReLU())
inchannal = outchannal
return nn.Sequential(*layer, nn.Conv2d(inchannal, outchannal, 1), nn.ReLU(),
nn.Conv2d(inchannal, outchannal, 1), nn.ReLU())
def nin_blks(self, nin_arc):
for arc in nin_arc:
self.layers.append(self.nin_blk(1, arc[0], arc[1], arc[2], arc[3], arc[4]))
self.layers.append(nn.MaxPool2d(3, 2))
self.layers.append(nn.AdaptiveAvgPool2d((1, 1)))
self.layers.append(nn.Flatten())
def forward(self, x):
return self.network(x)
nin = NiN(blk_arc)
nin = nin.to(device)
celoss = torch.nn.CrossEntropyLoss()
optimer = torch.optim.Adam(nin.parameters(), lr=lr)
train_loss_all = []
test_loss_all = []
train_acc = []
test_acc = []
for epoch in range(epochs):
test_loss = 0.0
train_loss = 0.0
right = 0.0
right_num = 0.0
for inputs, labels in tqdm(train_dataloader):
inputs = inputs.to(device)
labels = labels.to(device)
outputs = vgg11(inputs)
loss = celoss(outputs, labels)
train_loss += loss.detach().cpu().numpy()
optimer.zero_grad()
loss.backward()
optimer.step()
right = outputs.argmax(dim=1) == labels
right_num += right.sum().detach().cpu().numpy()
train_loss_all.append(train_loss / float(len(train_dataloader)))
train_acc.append(right_num / len(train_dataset))
with torch.no_grad():
right = 0.0
right_num = 0.0
for inputs, labels in tqdm(test_dataloader):
inputs = inputs.to(device)
labels = labels.to(device)
outputs = vgg11(inputs)
loss = celoss(outputs, labels)
test_loss += loss.detach().cpu().numpy()
right = outputs.argmax(dim=1) == labels
right_num += right.sum().detach().cpu().numpy()
test_loss_all.append(test_loss / float(len(test_dataloader)))
test_acc.append(right_num / len(test_dataset))
print(f'eopch: {epoch + 1}, train_loss: {train_loss / len(train_dataloader)}, test_loss: {test_loss / len(test_dataloader) }, acc: {right_num / len(test_dataset) * 100}%')
x = range(1, epochs + 1)
plt.plot(x, train_loss_all, label = 'train_loss', linestyle='--')
plt.plot(x, test_loss_all, label = 'test_loss', linestyle='--')
plt.plot(x, train_acc, label = 'train_acc', linestyle='--')
plt.plot(x, test_acc, label = 'test_acc', linestyle='--')
plt.legend()
plt.show()
blk_arc = ((11, 4, 0, 1, 96), (5, 1, 1, 96, 256), (3, 1, 1, 256, 384))
nin = NiN(blk_arc)
print(summary(nin , (1, 1, 224, 224)))
==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
NiN [1, 384] --
├─Sequential: 1-1 [1, 384] --
│ └─Sequential: 2-1 [1, 96, 54, 54] --
│ │ └─Conv2d: 3-1 [1, 96, 54, 54] 11,712
│ │ └─ReLU: 3-2 [1, 96, 54, 54] --
│ │ └─Conv2d: 3-3 [1, 96, 54, 54] 9,312
│ │ └─ReLU: 3-4 [1, 96, 54, 54] --
│ │ └─Conv2d: 3-5 [1, 96, 54, 54] 9,312
│ │ └─ReLU: 3-6 [1, 96, 54, 54] --
│ └─MaxPool2d: 2-2 [1, 96, 26, 26] --
│ └─Sequential: 2-3 [1, 256, 24, 24] --
│ │ └─Conv2d: 3-7 [1, 256, 24, 24] 614,656
│ │ └─ReLU: 3-8 [1, 256, 24, 24] --
│ │ └─Conv2d: 3-9 [1, 256, 24, 24] 65,792
│ │ └─ReLU: 3-10 [1, 256, 24, 24] --
│ │ └─Conv2d: 3-11 [1, 256, 24, 24] 65,792
│ │ └─ReLU: 3-12 [1, 256, 24, 24] --
│ └─MaxPool2d: 2-4 [1, 256, 11, 11] --
│ └─Sequential: 2-5 [1, 384, 11, 11] --
│ │ └─Conv2d: 3-13 [1, 384, 11, 11] 885,120
│ │ └─ReLU: 3-14 [1, 384, 11, 11] --
│ │ └─Conv2d: 3-15 [1, 384, 11, 11] 147,840
│ │ └─ReLU: 3-16 [1, 384, 11, 11] --
│ │ └─Conv2d: 3-17 [1, 384, 11, 11] 147,840
│ │ └─ReLU: 3-18 [1, 384, 11, 11] --
│ └─MaxPool2d: 2-6 [1, 384, 5, 5] --
│ └─AdaptiveAvgPool2d: 2-7 [1, 384, 1, 1] --
│ └─Flatten: 2-8 [1, 384] --
==========================================================================================
Total params: 1,957,376
Trainable params: 1,957,376
Non-trainable params: 0
Total mult-adds (M): 661.17
==========================================================================================
Input size (MB): 0.20
Forward/backward pass size (MB): 11.37
Params size (MB): 7.83
Estimated Total Size (MB): 19.40
==========================================================================================
训练结果
在colab上用T4这块GPU,跑了5代的训练结果,可以看到:一步就到最优了!
eopch: 1, train_loss: 0.10510292700898927, test_loss: 0.26130413853480844, acc: 92.11%
eopch: 2, train_loss: 0.10377910258228591, test_loss: 0.27324325440427927, acc: 92.05%
eopch: 3, train_loss: 0.10469645219269211, test_loss: 0.2535133291083046, acc: 92.32%
eopch: 4, train_loss: 0.10386230318006803, test_loss: 0.256068072930167, acc: 92.13%
eopch: 5, train_loss: 0.10460811025345884, test_loss: 0.25812459576733504, acc: 91.99%














 1004
1004











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









