







理论知识
玩梗 or 致敬LeNet🤣
GoogLeNet 吸收了 NiN 中串联网络的思想, 并在此基础上进行了改进, 这篇论文的重点是解决了什么样的卷积核最合适的问题, 文中的一个观点是有时候使用不同大小的卷积核的组合是有利的
7-4-1 Inception 块
It was arguably also the first network that exhibited a clear distinction among the stem (data ingest), body (data processing), and head (prediction) in a CNN
在 GoogLeNet 中, 基本的卷积块称为 Inception 块
在 Inception 中由四条并行路径组成, 前三条路径使用窗口大小分别为 1x1, 3x3 和 5x5 的卷积层, 从不同的空间大小中提取信息. 中间两条路径在输入上执行 1x1 卷积, 以减少通道数, 从而降低模型的复杂性. 第四条路使用 3x3 最大池化层, 然后使用 1x1 的卷积层改变通道数. 这四条路都使用合适的填充来使得输入与输出的高和宽一致, 最后将每条线路的输出在通道维度上连结, 构成 Inception 块的输出. 超参数一般是每层的输出通道数
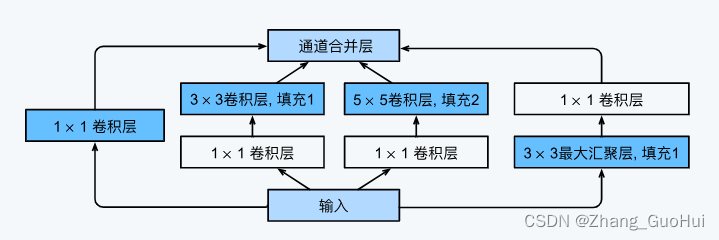
为什么 GoogLeNet 是有效的呢, 对于滤波器的各种组合, 可以使用不同的尺寸来探索图像, 意味着不同大小的滤波器可以有效地识别不同范围的图像细节,同时可以为不同的滤波器分配不同数量的参数
GoogLeNet 模型
GoogLeNet 一共使用了 9 个 Inception 块和全局平均池化层的堆叠来实现其估计值, Inception 块之间的最大池化层可以降低维度. 第一个模块类似于 AlexNet 和 LeNet, Inception 块的组合从 VGG 继承,全局平均汇聚层避免了在最后使用全连接层。

这边我详细写了每个模块的大小,本想总结规律,到最后发现,毫无规律可言
- 第一个模块
- 7x7 卷积:输出通道是 64,步幅是 2,填充是 3
- 3x3 最大池化:步幅是 2,填充是 1
- 第二个模块
- 1x1 卷积:输出通道 64
- 3x3 卷积:输出通道翻三倍 192,填充是 1
- 3x3 最大池化:步幅是 2,填充是 1
- 第三个模块
- Inception 模块
- 输出通道数分别为 64 + 128 + 32 + 32 = 256,比例为 2:4:1:1
- 第二个路径首先减少到一半 (96/192 = 1/2),第三个路径首先减少到 1/12 (16/192 = 1/12)
- Inception 模块
- 输出通道数分别为 128 + 192 + 96 + 64 = 480,比例为 4:6:3:2
- 第二个路径首先减少到一半 (128/256 = 1/2),第三个路径首先减少到 1/8 (32/256 = 1/12)
- 第四个模块
- Inception 模块
- 输出通道数分别为 192 + 208 + 48 + 64 = 512,比例为 12:13:3:4
- 第二个路径首先减少到 1/5 (96/480 = 1/5),第三个路径首先减少到 1/12 (16/192 = 1/12)
- Inception 模块
- 输出通道数分别为 160 + 224 + 64 + 64 = 512,比例为 5:7:2:2
- 第二个路径首先减少到 7/32 (112/512 = 7/32),第三个路径首先减少到 1/12 (3/64 = 1/12)
- Inception 模块
- 输出通道数分别为 128 + 256 + 64 + 64 = 512,比例为 2:4:1:1
- 第二个路径首先减少到 1/4 (128/512 = 1/4),第三个路径首先减少到 1/64 (24/512 = 1/64)
- Inception 模块
- 输出通道数分别为 112 + 288 + 64 + 64 = 528,比例为 7:18:4:4
- 第二个路径首先减少到 9/32(144/512 = 9/32),第三个路径首先减少到 1/16 (32/512 = 1/16)
- Inception 模块
- 输出通道数分别为 256 + 320 + 128 + 128 = 832,比例为 4:5:2:2
- 第二个路径首先减少到 10/33 (160/528 = 10/33),第三个路径首先减少到 2/33 (32/528 = 2/33)
- 第五个模块
- Inception 模块
- 输出通道数分别为 256 + 320 + 128 + 128 = 832,比例为 4:5:2:2
- 第二个路径首先减少到 10/33 (160/832 = 10/33),第三个路径首先减少到 2/33 (32/832 = 2/33)
- Inception 模块
- 输出通道数分别为 384 + 384 + 128 + 128 = 1024,比例为 3:3:1:1
- 第二个路径首先减少到 3/13 (192/832 = 3/13),第三个路径首先减少到 3/56 (48/832 = 3/56)
- 全局池化层
- 将每个通道的高和宽改变为 1x1(类似于 NiN)
- 拉伸成二维
- 全连接层
- 输出的大小是预测的类别数
当然,Inception还有很多变种,比如
- Inception-BN 使用了 batch normalization
- Inception-V3 修改了 Inception 块
- 替换 5x5 为多个 3x3 卷积层
- 替换 5x5 为 1x7 和 7x1 卷积层
- 替换 3x3 为 1x3 和 3x1 卷积层
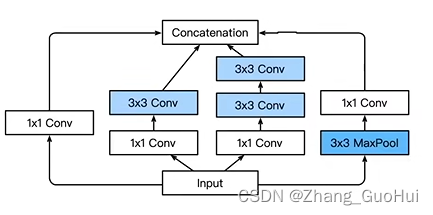
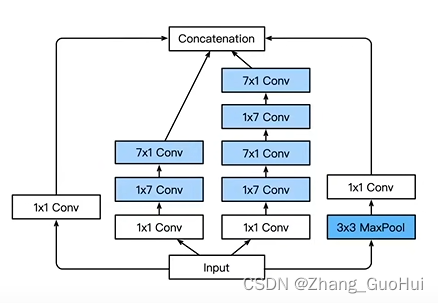
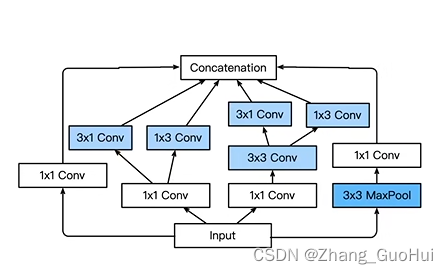
代码实现
这里用到的数据集是FashionMNIST,但是做了一些小处理,将原来28x28的图片放大到了224x224,这是因为AlexNet用在ImageNet数据集上的,仅为了简单复现,不需要用到ImageNet数据集
!pip install torchinfo
import torch
import torchvision
import torch.nn as nn
from torch.utils.data import DataLoader
from tqdm import tqdm
from torchinfo import summary
import matplotlib.pyplot as plt
# 超参数
epochs = 10
batch_size = 128
lr = 0.001
device = 'cuda:0' if torch.cuda.is_available() else "cpu"
# 数据集
data_trans = torchvision.transforms.Compose([torchvision.transforms.ToTensor(),torchvision.transforms.Resize((224, 224))])
# toTensor = (torchvision.transforms.ToTensor(), torchvision.transforms.Resize((224, 224)))
train_dataset = torchvision.datasets.FashionMNIST("../00data", True, data_trans, download=True)
test_dataset = torchvision.datasets.FashionMNIST("../00data", False, data_trans, download=True)
train_dataloader = DataLoader(train_dataset, batch_size, True)
test_dataloader = DataLoader(test_dataset, batch_size, True)
class Inception(nn.Module):
def __init__(self, inchannal, outchannal) -> None:
super(Inception, self).__init__()
self.conv1_1 = torch.nn.Conv2d(inchannal, outchannal[0], kernel_size= 1)
self.conv1_2 = torch.nn.Conv2d(inchannal, outchannal[1][0], kernel_size= 1)
self.conv1_3 = torch.nn.Conv2d(inchannal, outchannal[2][0], kernel_size= 1)
self.conv1_4 = torch.nn.Conv2d(inchannal, outchannal[3], kernel_size= 1)
self.conv2 = torch.nn.Conv2d(outchannal[1][0], outchannal[1][1], kernel_size= 3, padding=1)
self.conv3 = torch.nn.Conv2d(outchannal[2][0], outchannal[2][1], kernel_size= 5, padding=2)
self.maxpool = torch.nn.MaxPool2d(3, stride= 1, padding=1)
self.relu = torch.nn.ReLU()
def forward(self, x):
x_1 = self.relu(self.conv1_1(x))
x_2 = self.relu(self.conv2(self.relu(self.conv1_2(x))))
x_3 = self.relu(self.conv3(self.relu(self.conv1_3(x))))
x_4 = self.relu(self.conv1_4(self.maxpool(x)))
output = torch.cat((x_1, x_2, x_3, x_4),dim=1)
return output
googlenet = nn.Sequential(
torch.nn.Conv2d(1, 64, 7), nn.ReLU(),
torch.nn.MaxPool2d(kernel_size= 3),
torch.nn.Conv2d(64, 64, 1), nn.ReLU(),
torch.nn.Conv2d(64, 192, 3), nn.ReLU(),
torch.nn.MaxPool2d(kernel_size= 3),
Inception(192, (64, (96, 128), (16, 32), 32)),
Inception(256, (128, (128, 192), (32, 96), 64)),
torch.nn.MaxPool2d(3, 2, 1),
Inception(480, (192, (96, 208), (16, 48), 64)),
Inception(512, (160, (112, 224), (24, 64), 64)),
Inception(512, (112, (144, 288), (32, 64), 64)),
Inception(528, (256, (160, 320), (32, 128), 128)),
torch.nn.MaxPool2d(3, 2, 1),
Inception(832, (256, (160, 320), (32, 128), 128)),
Inception(832, (384, (192, 384), (48, 128), 128)),
nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten(),
nn.Linear(1024, 10)
)
googlenet = googlenet.to(device)
celoss = torch.nn.CrossEntropyLoss()
optimer = torch.optim.Adam(googlenet.parameters(), lr=lr)
train_loss_all = []
test_loss_all = []
train_acc = []
test_acc = []
for epoch in range(epochs):
test_loss = 0.0
train_loss = 0.0
right = 0.0
right_num = 0.0
for inputs, labels in tqdm(train_dataloader):
inputs = inputs.to(device)
labels = labels.to(device)
outputs = googlenet(inputs)
loss = celoss(outputs, labels)
train_loss += loss.detach().cpu().numpy()
optimer.zero_grad()
loss.backward()
optimer.step()
right = outputs.argmax(dim=1) == labels
right_num += right.sum().detach().cpu().numpy()
train_loss_all.append(train_loss / float(len(train_dataloader)))
train_acc.append(right_num / len(train_dataset))
with torch.no_grad():
right = 0.0
right_num = 0.0
for inputs, labels in tqdm(test_dataloader):
inputs = inputs.to(device)
labels = labels.to(device)
outputs = googlenet(inputs)
loss = celoss(outputs, labels)
test_loss += loss.detach().cpu().numpy()
right = outputs.argmax(dim=1) == labels
right_num += right.sum().detach().cpu().numpy()
test_loss_all.append(test_loss / float(len(test_dataloader)))
test_acc.append(right_num / len(test_dataset))
print(f'eopch: {epoch + 1}, train_loss: {train_loss / len(train_dataloader)}, test_loss: {test_loss / len(test_dataloader) }, acc: {right_num / len(test_dataset) * 100}%')
x = range(1, epochs + 1)
plt.plot(x, train_loss_all, label = 'train_loss', linestyle='--')
plt.plot(x, test_loss_all, label = 'test_loss', linestyle='--')
plt.plot(x, train_acc, label = 'train_acc', linestyle='--')
plt.plot(x, test_acc, label = 'test_acc', linestyle='--')
plt.legend()
plt.show()
summary(googlenet, (1, 1, 224, 224))
“超级超级长”
==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
Sequential [1, 10] --
├─Conv2d: 1-1 [1, 64, 218, 218] 3,200
├─ReLU: 1-2 [1, 64, 218, 218] --
├─MaxPool2d: 1-3 [1, 64, 72, 72] --
├─Conv2d: 1-4 [1, 64, 72, 72] 4,160
├─ReLU: 1-5 [1, 64, 72, 72] --
├─Conv2d: 1-6 [1, 192, 70, 70] 110,784
├─ReLU: 1-7 [1, 192, 70, 70] --
├─MaxPool2d: 1-8 [1, 192, 23, 23] --
├─Inception: 1-9 [1, 256, 23, 23] --
│ └─Conv2d: 2-1 [1, 64, 23, 23] 12,352
│ └─ReLU: 2-2 [1, 64, 23, 23] --
│ └─Conv2d: 2-3 [1, 96, 23, 23] 18,528
│ └─ReLU: 2-4 [1, 96, 23, 23] --
│ └─Conv2d: 2-5 [1, 128, 23, 23] 110,720
│ └─ReLU: 2-6 [1, 128, 23, 23] --
│ └─Conv2d: 2-7 [1, 16, 23, 23] 3,088
│ └─ReLU: 2-8 [1, 16, 23, 23] --
│ └─Conv2d: 2-9 [1, 32, 23, 23] 12,832
│ └─ReLU: 2-10 [1, 32, 23, 23] --
│ └─MaxPool2d: 2-11 [1, 192, 23, 23] --
│ └─Conv2d: 2-12 [1, 32, 23, 23] 6,176
│ └─ReLU: 2-13 [1, 32, 23, 23] --
├─Inception: 1-10 [1, 480, 23, 23] --
│ └─Conv2d: 2-14 [1, 128, 23, 23] 32,896
│ └─ReLU: 2-15 [1, 128, 23, 23] --
│ └─Conv2d: 2-16 [1, 128, 23, 23] 32,896
│ └─ReLU: 2-17 [1, 128, 23, 23] --
│ └─Conv2d: 2-18 [1, 192, 23, 23] 221,376
│ └─ReLU: 2-19 [1, 192, 23, 23] --
│ └─Conv2d: 2-20 [1, 32, 23, 23] 8,224
│ └─ReLU: 2-21 [1, 32, 23, 23] --
│ └─Conv2d: 2-22 [1, 96, 23, 23] 76,896
│ └─ReLU: 2-23 [1, 96, 23, 23] --
│ └─MaxPool2d: 2-24 [1, 256, 23, 23] --
│ └─Conv2d: 2-25 [1, 64, 23, 23] 16,448
│ └─ReLU: 2-26 [1, 64, 23, 23] --
├─MaxPool2d: 1-11 [1, 480, 12, 12] --
├─Inception: 1-12 [1, 512, 12, 12] --
│ └─Conv2d: 2-27 [1, 192, 12, 12] 92,352
│ └─ReLU: 2-28 [1, 192, 12, 12] --
│ └─Conv2d: 2-29 [1, 96, 12, 12] 46,176
│ └─ReLU: 2-30 [1, 96, 12, 12] --
│ └─Conv2d: 2-31 [1, 208, 12, 12] 179,920
│ └─ReLU: 2-32 [1, 208, 12, 12] --
│ └─Conv2d: 2-33 [1, 16, 12, 12] 7,696
│ └─ReLU: 2-34 [1, 16, 12, 12] --
│ └─Conv2d: 2-35 [1, 48, 12, 12] 19,248
│ └─ReLU: 2-36 [1, 48, 12, 12] --
│ └─MaxPool2d: 2-37 [1, 480, 12, 12] --
│ └─Conv2d: 2-38 [1, 64, 12, 12] 30,784
│ └─ReLU: 2-39 [1, 64, 12, 12] --
├─Inception: 1-13 [1, 512, 12, 12] --
│ └─Conv2d: 2-40 [1, 160, 12, 12] 82,080
│ └─ReLU: 2-41 [1, 160, 12, 12] --
│ └─Conv2d: 2-42 [1, 112, 12, 12] 57,456
│ └─ReLU: 2-43 [1, 112, 12, 12] --
│ └─Conv2d: 2-44 [1, 224, 12, 12] 226,016
│ └─ReLU: 2-45 [1, 224, 12, 12] --
│ └─Conv2d: 2-46 [1, 24, 12, 12] 12,312
│ └─ReLU: 2-47 [1, 24, 12, 12] --
│ └─Conv2d: 2-48 [1, 64, 12, 12] 38,464
│ └─ReLU: 2-49 [1, 64, 12, 12] --
│ └─MaxPool2d: 2-50 [1, 512, 12, 12] --
│ └─Conv2d: 2-51 [1, 64, 12, 12] 32,832
│ └─ReLU: 2-52 [1, 64, 12, 12] --
├─Inception: 1-14 [1, 528, 12, 12] --
│ └─Conv2d: 2-53 [1, 112, 12, 12] 57,456
│ └─ReLU: 2-54 [1, 112, 12, 12] --
│ └─Conv2d: 2-55 [1, 144, 12, 12] 73,872
│ └─ReLU: 2-56 [1, 144, 12, 12] --
│ └─Conv2d: 2-57 [1, 288, 12, 12] 373,536
│ └─ReLU: 2-58 [1, 288, 12, 12] --
│ └─Conv2d: 2-59 [1, 32, 12, 12] 16,416
│ └─ReLU: 2-60 [1, 32, 12, 12] --
│ └─Conv2d: 2-61 [1, 64, 12, 12] 51,264
│ └─ReLU: 2-62 [1, 64, 12, 12] --
│ └─MaxPool2d: 2-63 [1, 512, 12, 12] --
│ └─Conv2d: 2-64 [1, 64, 12, 12] 32,832
│ └─ReLU: 2-65 [1, 64, 12, 12] --
├─Inception: 1-15 [1, 832, 12, 12] --
│ └─Conv2d: 2-66 [1, 256, 12, 12] 135,424
│ └─ReLU: 2-67 [1, 256, 12, 12] --
│ └─Conv2d: 2-68 [1, 160, 12, 12] 84,640
│ └─ReLU: 2-69 [1, 160, 12, 12] --
│ └─Conv2d: 2-70 [1, 320, 12, 12] 461,120
│ └─ReLU: 2-71 [1, 320, 12, 12] --
│ └─Conv2d: 2-72 [1, 32, 12, 12] 16,928
│ └─ReLU: 2-73 [1, 32, 12, 12] --
│ └─Conv2d: 2-74 [1, 128, 12, 12] 102,528
│ └─ReLU: 2-75 [1, 128, 12, 12] --
│ └─MaxPool2d: 2-76 [1, 528, 12, 12] --
│ └─Conv2d: 2-77 [1, 128, 12, 12] 67,712
│ └─ReLU: 2-78 [1, 128, 12, 12] --
├─MaxPool2d: 1-16 [1, 832, 6, 6] --
├─Inception: 1-17 [1, 832, 6, 6] --
│ └─Conv2d: 2-79 [1, 256, 6, 6] 213,248
│ └─ReLU: 2-80 [1, 256, 6, 6] --
│ └─Conv2d: 2-81 [1, 160, 6, 6] 133,280
│ └─ReLU: 2-82 [1, 160, 6, 6] --
│ └─Conv2d: 2-83 [1, 320, 6, 6] 461,120
│ └─ReLU: 2-84 [1, 320, 6, 6] --
│ └─Conv2d: 2-85 [1, 32, 6, 6] 26,656
│ └─ReLU: 2-86 [1, 32, 6, 6] --
│ └─Conv2d: 2-87 [1, 128, 6, 6] 102,528
│ └─ReLU: 2-88 [1, 128, 6, 6] --
│ └─MaxPool2d: 2-89 [1, 832, 6, 6] --
│ └─Conv2d: 2-90 [1, 128, 6, 6] 106,624
│ └─ReLU: 2-91 [1, 128, 6, 6] --
├─Inception: 1-18 [1, 1024, 6, 6] --
│ └─Conv2d: 2-92 [1, 384, 6, 6] 319,872
│ └─ReLU: 2-93 [1, 384, 6, 6] --
│ └─Conv2d: 2-94 [1, 192, 6, 6] 159,936
│ └─ReLU: 2-95 [1, 192, 6, 6] --
│ └─Conv2d: 2-96 [1, 384, 6, 6] 663,936
│ └─ReLU: 2-97 [1, 384, 6, 6] --
│ └─Conv2d: 2-98 [1, 48, 6, 6] 39,984
│ └─ReLU: 2-99 [1, 48, 6, 6] --
│ └─Conv2d: 2-100 [1, 128, 6, 6] 153,728
│ └─ReLU: 2-101 [1, 128, 6, 6] --
│ └─MaxPool2d: 2-102 [1, 832, 6, 6] --
│ └─Conv2d: 2-103 [1, 128, 6, 6] 106,624
│ └─ReLU: 2-104 [1, 128, 6, 6] --
├─AdaptiveAvgPool2d: 1-19 [1, 1024, 1, 1] --
├─Flatten: 1-20 [1, 1024] --
├─Linear: 1-21 [1, 10] 10,250
==========================================================================================
Total params: 5,467,426
Trainable params: 5,467,426
Non-trainable params: 0
Total mult-adds (G): 1.43
==========================================================================================
Input size (MB): 0.20
Forward/backward pass size (MB): 42.89
Params size (MB): 21.87
Estimated Total Size (MB): 64.96
==========================================================================================
训练结果
在colab上用T4这块GPU,跑了10代的训练结果,可以看到:大力出奇迹!
eopch: 1, train_loss: 0.9660880496379918, test_loss: 0.46708034073250204, acc: 83.02%
eopch: 2, train_loss: 0.4065619704565768, test_loss: 0.3715848758628097, acc: 85.94%
eopch: 3, train_loss: 0.3352106730503314, test_loss: 0.3502238741781138, acc: 87.02%
eopch: 4, train_loss: 0.28990801455560267, test_loss: 0.2952995009814637, acc: 88.69%
eopch: 5, train_loss: 0.2581006147936463, test_loss: 0.2876935101385358, acc: 89.21%
eopch: 6, train_loss: 0.23799550161559954, test_loss: 0.2506726753862598, acc: 90.81%
eopch: 7, train_loss: 0.22299828034029331, test_loss: 0.26817411995386775, acc: 90.18%
eopch: 8, train_loss: 0.2070264855046262, test_loss: 0.24048426756753197, acc: 91.24%
eopch: 9, train_loss: 0.19492275488656213, test_loss: 0.25348345105406606, acc: 91.31%
eopch: 10, train_loss: 0.18267434406509278, test_loss: 0.23602534783414647, acc: 91.54%














 1342
1342











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









