






神经网络笔记
注:是各大平台博主内容的一个汇总,如有侵权,请联系我。
在人工智能领域,有一个方法叫机器学习。在机器学习这个方法里,有一类算法叫神经网络。
隐藏层比较多(大于2)的神经网络叫做深度神经网络。而深度学习,就是使用深层架构(比如,深度神经网络)的机器学习方法(隐藏层多的机器学习)
感知器:下图是一个感知器:
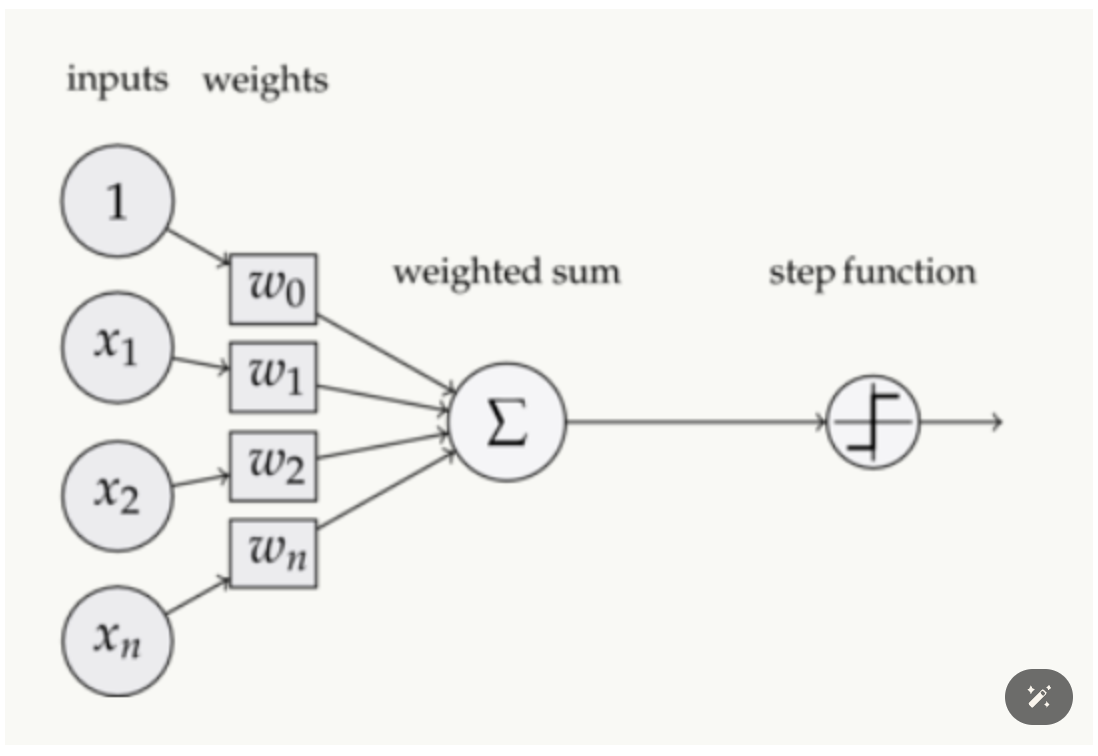
多层感知器(multilayer perceptron,MLP):是一种前向结构的神经网络,映射一组输入向量到一组输出向量。MLP可以被看作是是一个有向图,由多个的节点层所组成,每一层都全连接到下一层。除了输入节点,每个节点都是一个带有非线性激活函数的神经元(或称处理单元)。一种被称为反向传播算法的监督学习方法常被用来训练MLP。多层感知的基本结构由三层组成:第一输入层,中间隐藏层和最后输出层,输入元素和权重的乘积被馈给具有神经元偏差的求和结点,主要优势在于其快速解决复杂问题的能力。MLP是感知器的推广,克服了感知器不能对线性不可分数据进行识别的弱点.
过拟合:神经元数量过于庞大导致
批次(batch):一共有10个数据,每次输入两个,一共输入5次
周期(epoch):两个迭代(iteration)为一周期
反向传播算法(Back propagation,BP):对多层人工神经网络进行梯度下降的算法,也就是用链式法则以网络每层的权重为变量计算损失函数的梯度,以更新权重来最小化损失函数.因为计算上是由第L层的输出 y i L y^L_i yiL对损失函数 g g g的偏微分出发,一层层向后递推出前面各层的权重因子梯度,所以被称为反向传播.
循环神经网络(RNN)
- 用于分析语音、文字的神经网络。
将神经网络模型训练好之后,在输入层给定一个x,通过网络之后就能够在输出层得到特定的y,那么既然有了这么强大的模型,为什么还需要RNN(循环神经网络)呢?
因为他们都只能单独的去处理一个个的输入,前一个输入和后一个输入是完全没有关系的。但是,某些任务需要能够更好的处理序列的信息,即前面的输入和后面的输入是有关系的。
以一个最简单词性标注任务来说,将我 吃 苹果 三个单词标注词性为 我/nn 吃/v 苹果/nn。
那么这个任务的输入就是:
我 吃 苹果 (已经分词好的句子)
这个任务的输出是:
我/nn 吃/v 苹果/nn(词性标注好的句子)
对于这个任务来说,我们当然可以直接用普通的神经网络来做,给网络的训练数据格式了就是我-> 我/nn 这样的多个单独的单词->词性标注好的单词。
但是很明显,一个句子中,前一个单词其实对于当前单词的词性预测是有很大影响的,比如预测苹果的时候,由于前面的吃是一个动词,那么很显然苹果作为名词的概率就会远大于动词的概率,因为动词后面接名词很常见,而动词后面接动词很少见。
所以为了解决一些这样类似的问题,能够更好的处理序列的信息,RNN就诞生了。
一个简单的循环神经网络如下:
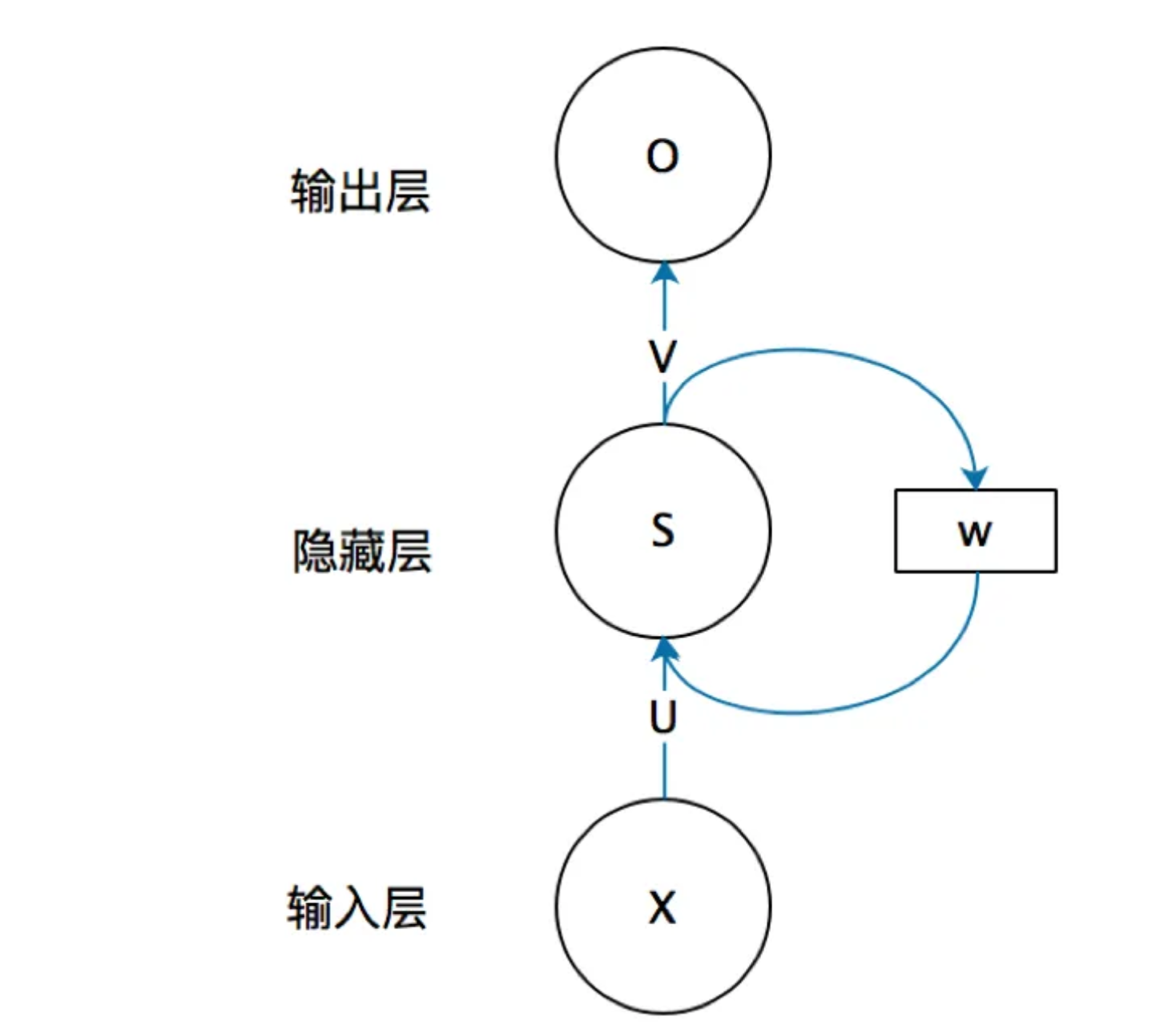
已知的是:X是一个向量,它表示输入层的值。S是一个向量,它表示隐藏层的值。U是输入层到隐藏层的权重矩阵,O也是一个向量,它表示输出层的值。V是隐藏层到输出层的权重矩阵。
循环神经网络特殊在:隐藏层的值S不仅仅取决于当前这次的输入X,还取决于上一次隐藏层的值S。权重矩阵W就是隐藏层上一次的值作为这一次的输入的权重。
循环神经网络也可以画成下面这个样子:
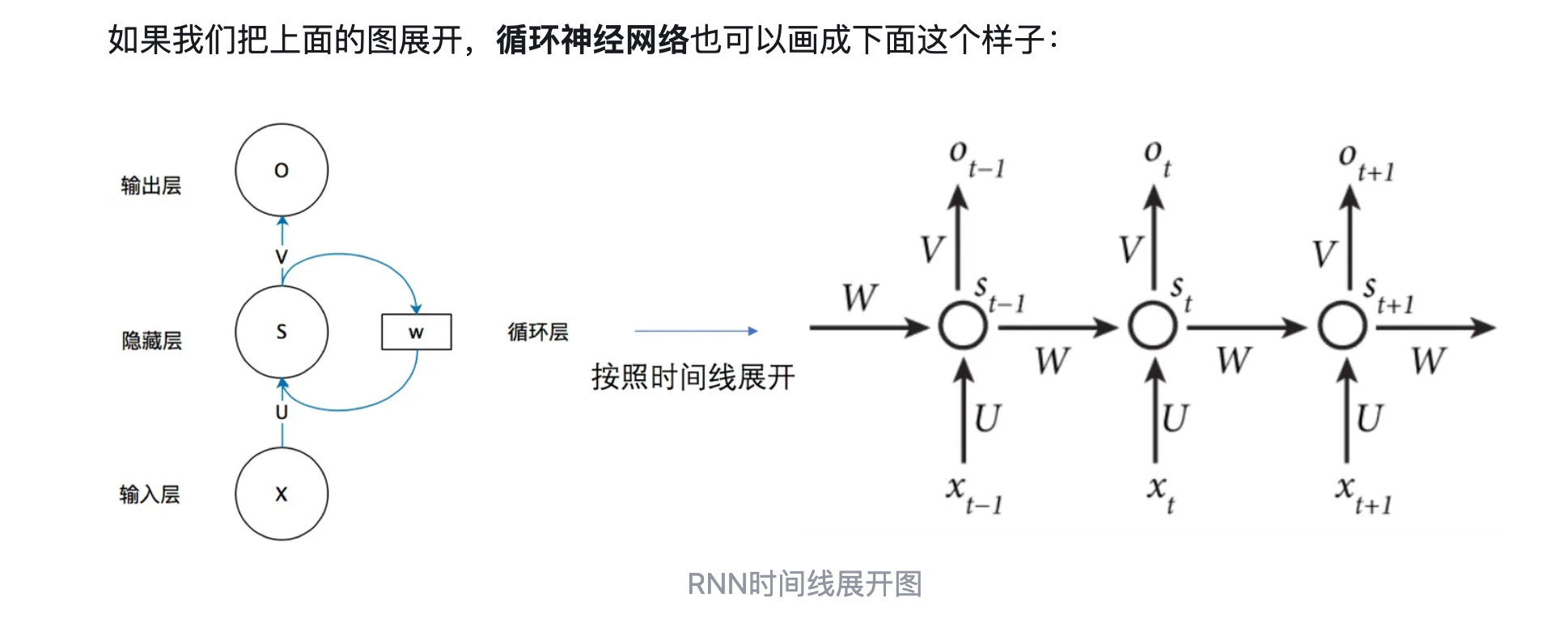
现在看上去就比较清楚了,这个网络在t时刻接收到输入 X t X_t Xt之后,隐藏层的值是 S t S_t St,输出值是O_t。关键一点是, S t S_t St的值不仅仅取决于 x t x_t xt,还取决于 S t − 1 S_{t-1} St−1。我们可以用下面的公式来表示循环神经网络的计算方法:
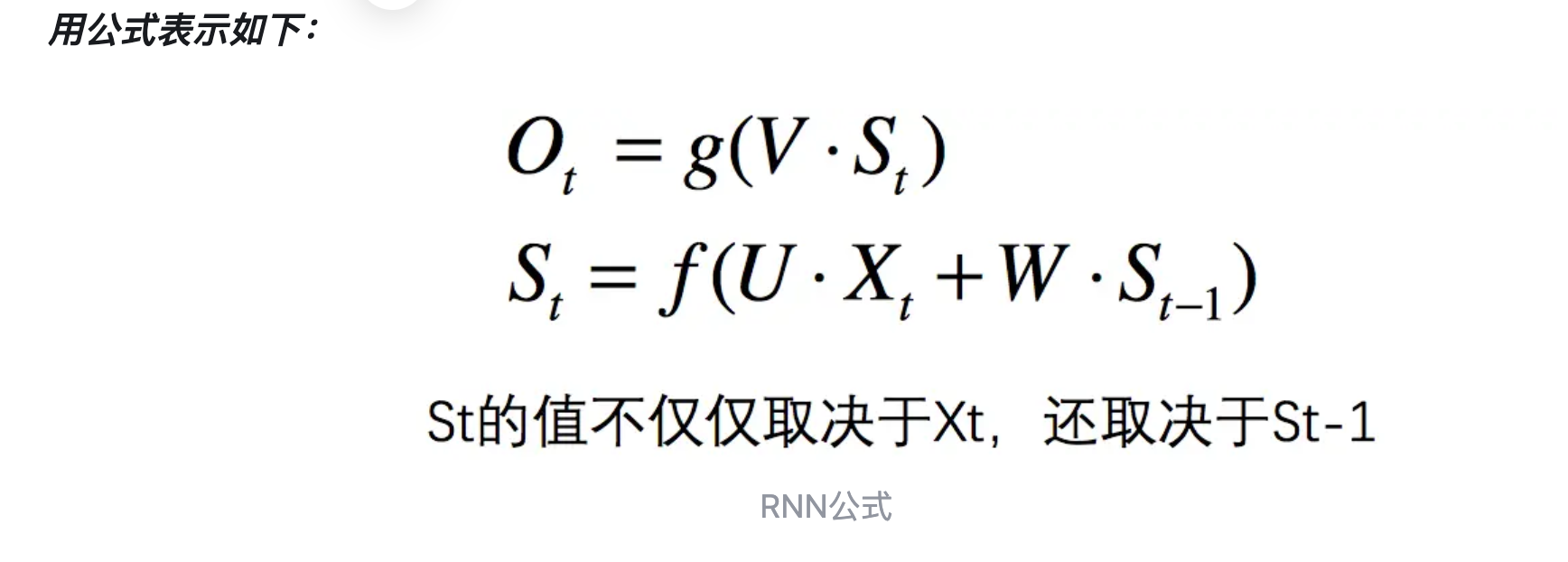
卷积神经网络(Convolutional Neural Networks,CNN)
被广泛应用在图像识别领域。CNN的结构可以分为3层:
- 卷积层:提取特征;
- 池化层:下采样,但不会破坏识别结果;
- 全连接层:分类。
下图是CNN的示意图:
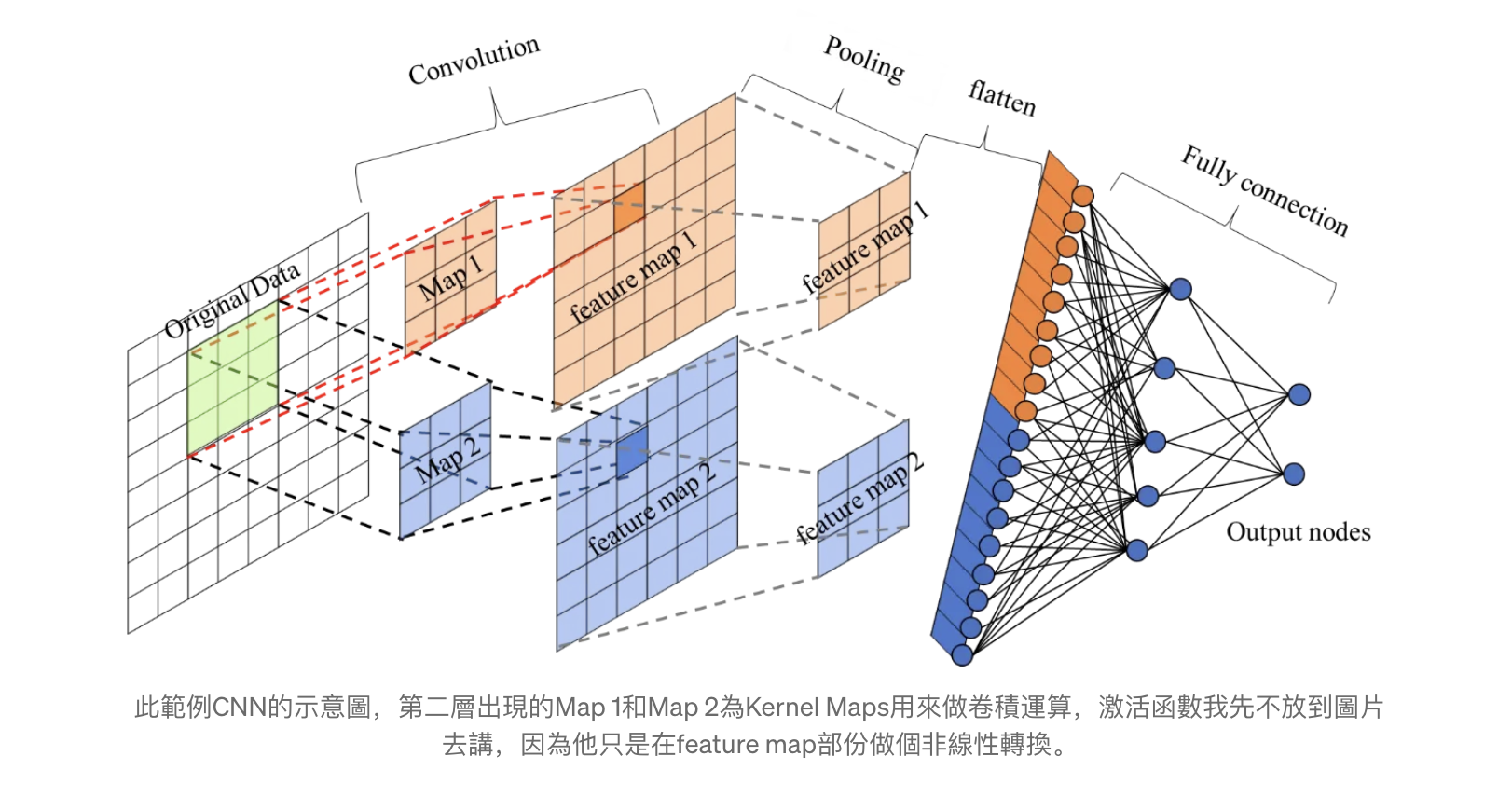
卷积层:可以理解为拿一个滤镜放在图像上,找出图像中的某些特征。例如首先有一组灰度图片,表示出来就是一个矩阵,接下来用一个过滤器(Filter)对图片过滤,就是求卷积的过程。
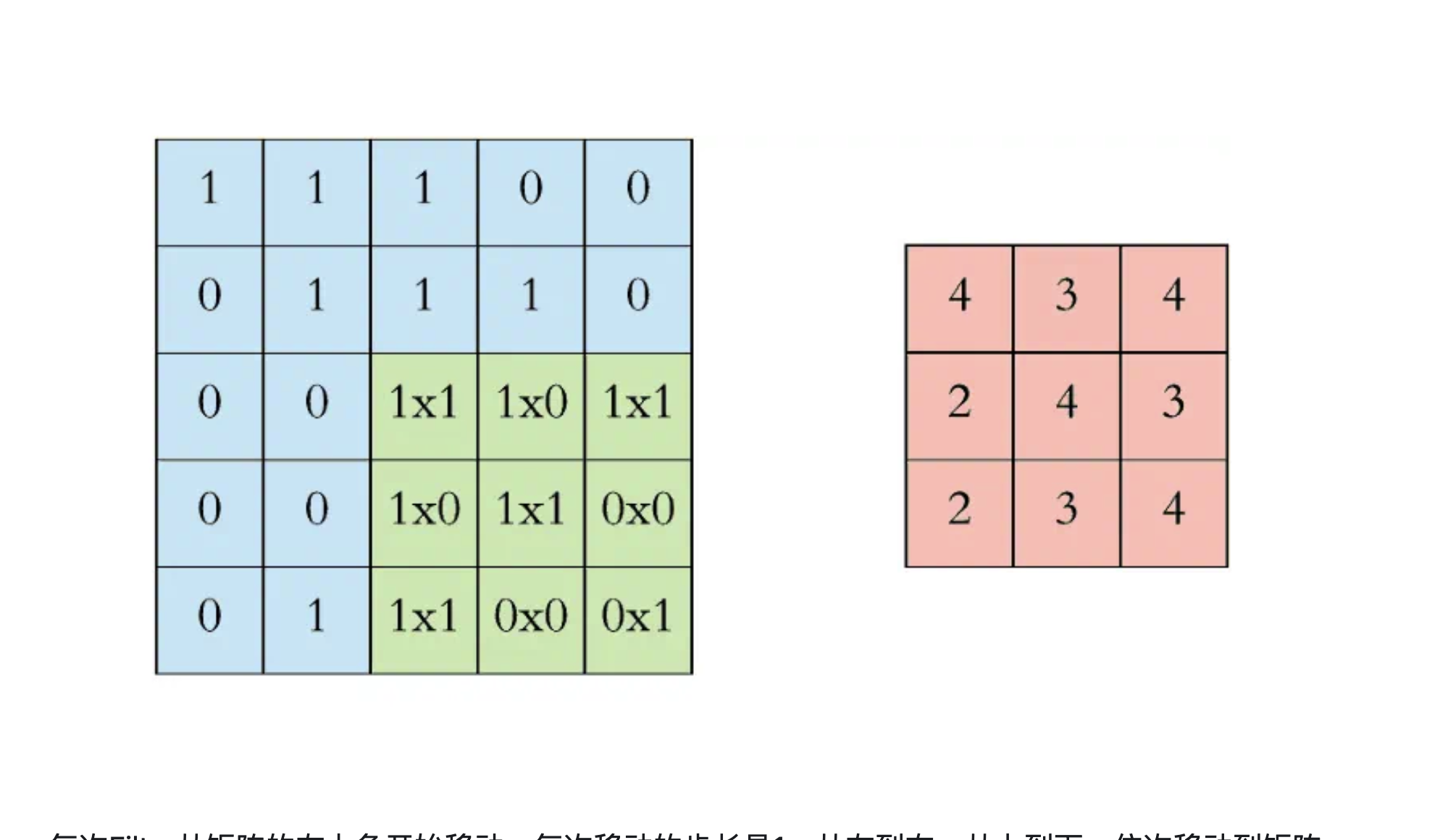
这个Filter的选择很关键,Filter决定了过滤方式,通过不同的Filter会得到不同的特征。举一个例子就是:
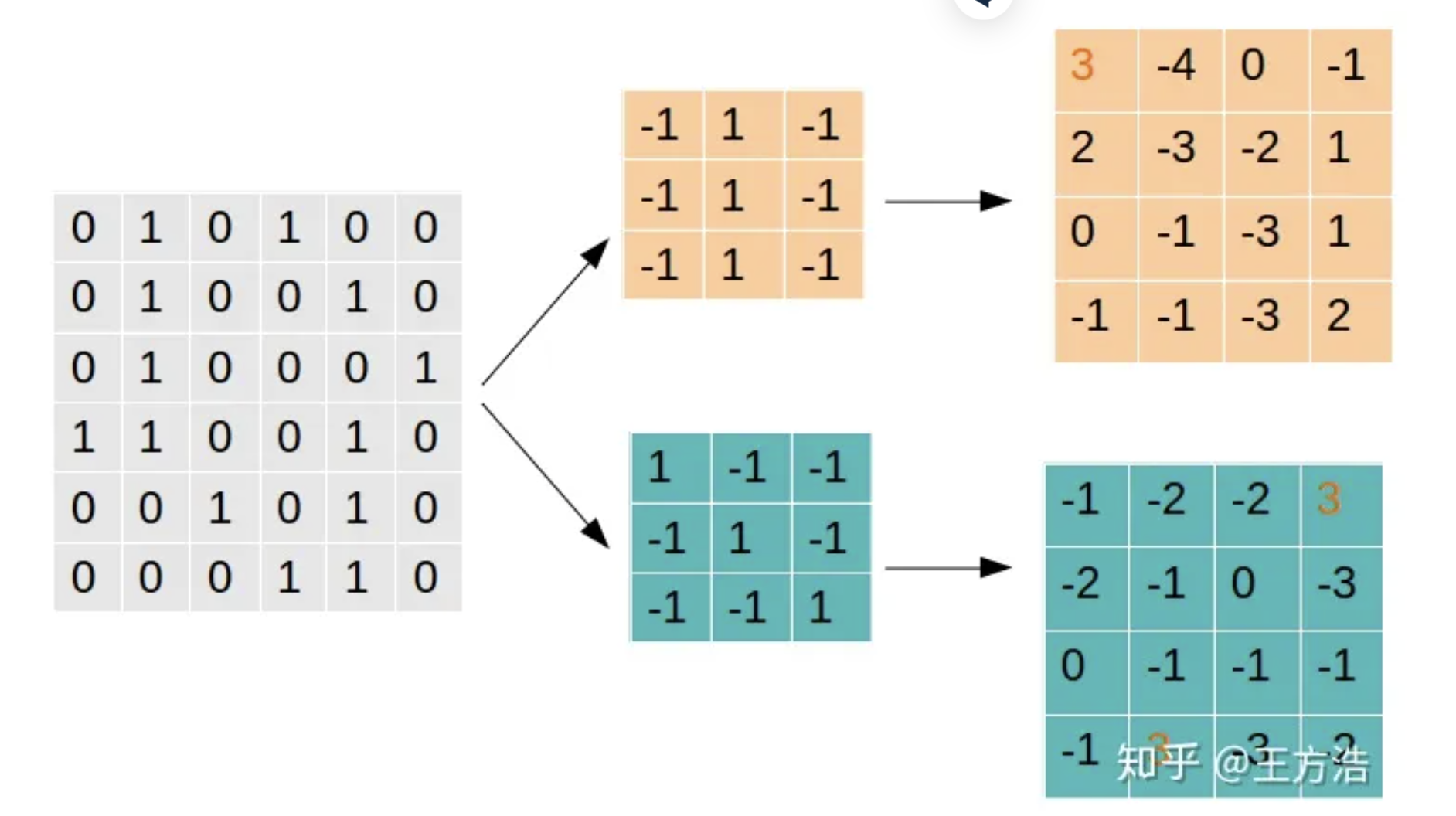
Filter1主要是找到为"|“形状的特征,可以看到找到1处,转换后相乘值为3的网格就表示原始的图案中有”|“,而Filter2则表示找到”"形状的特征,我们可以看到在图中可以找到2处。
池化层:但是经过卷积层处理之后,得到的结果维数也可能非常大,我们就需要减少数据大小,但又不会对识别结果产生影响,就需要对卷积层的输出结果做采样。
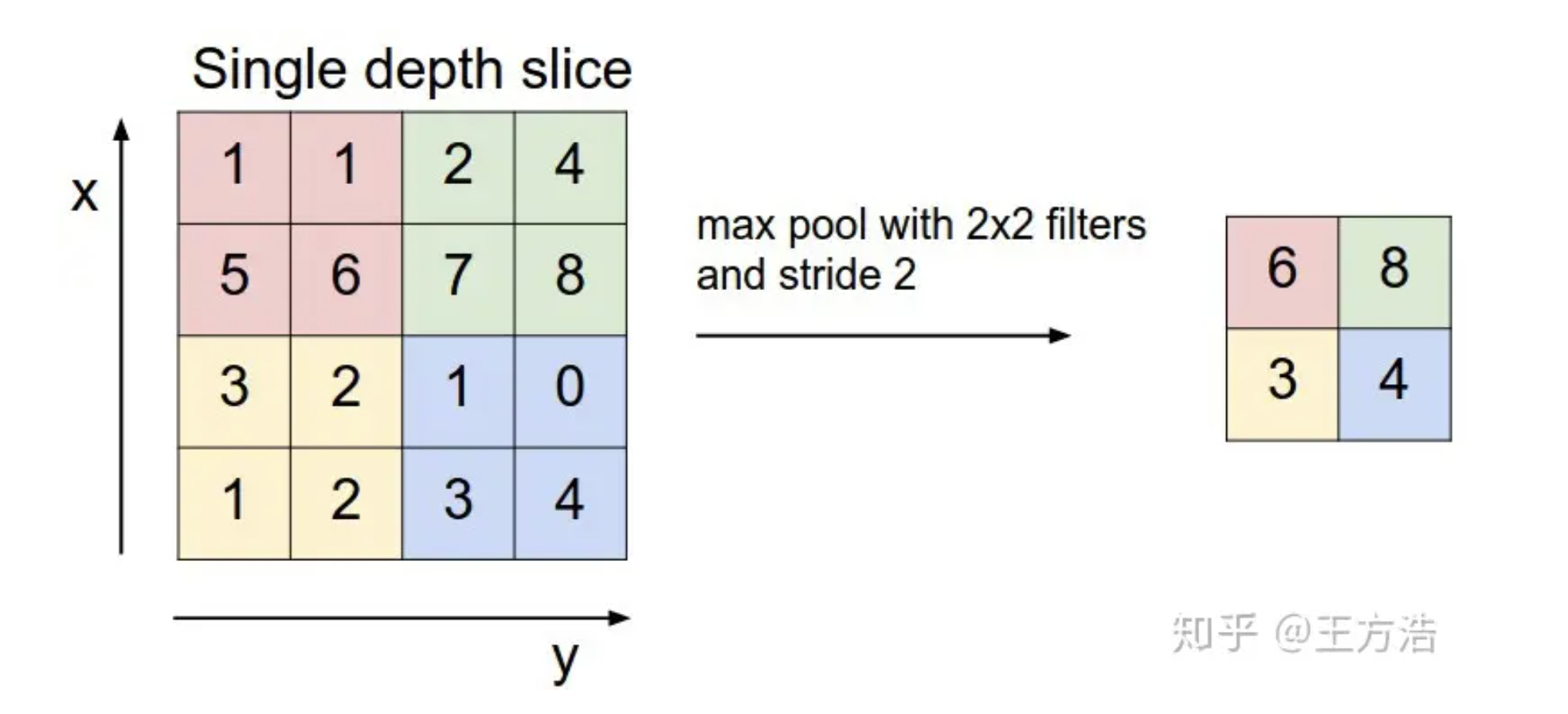
那么为什么这样做可行呢?丢失的一部分数据会不会对结果有影响,实际上,池化层不会对数据丢失产生影响,因为我们每次保留的输出都是局部最显著的一个输出,而池化之后,最显著的特征并没。我们只保留了认为最显著的特征,而把其他无用的信息丢掉,来减少运算
全连接层:全连接层的作用主要是进行分类。前面通过卷积和池化层得出的特征,在全连接层对这些总结好的特征做分类。全连接层就是一个完全连接的神经网络。
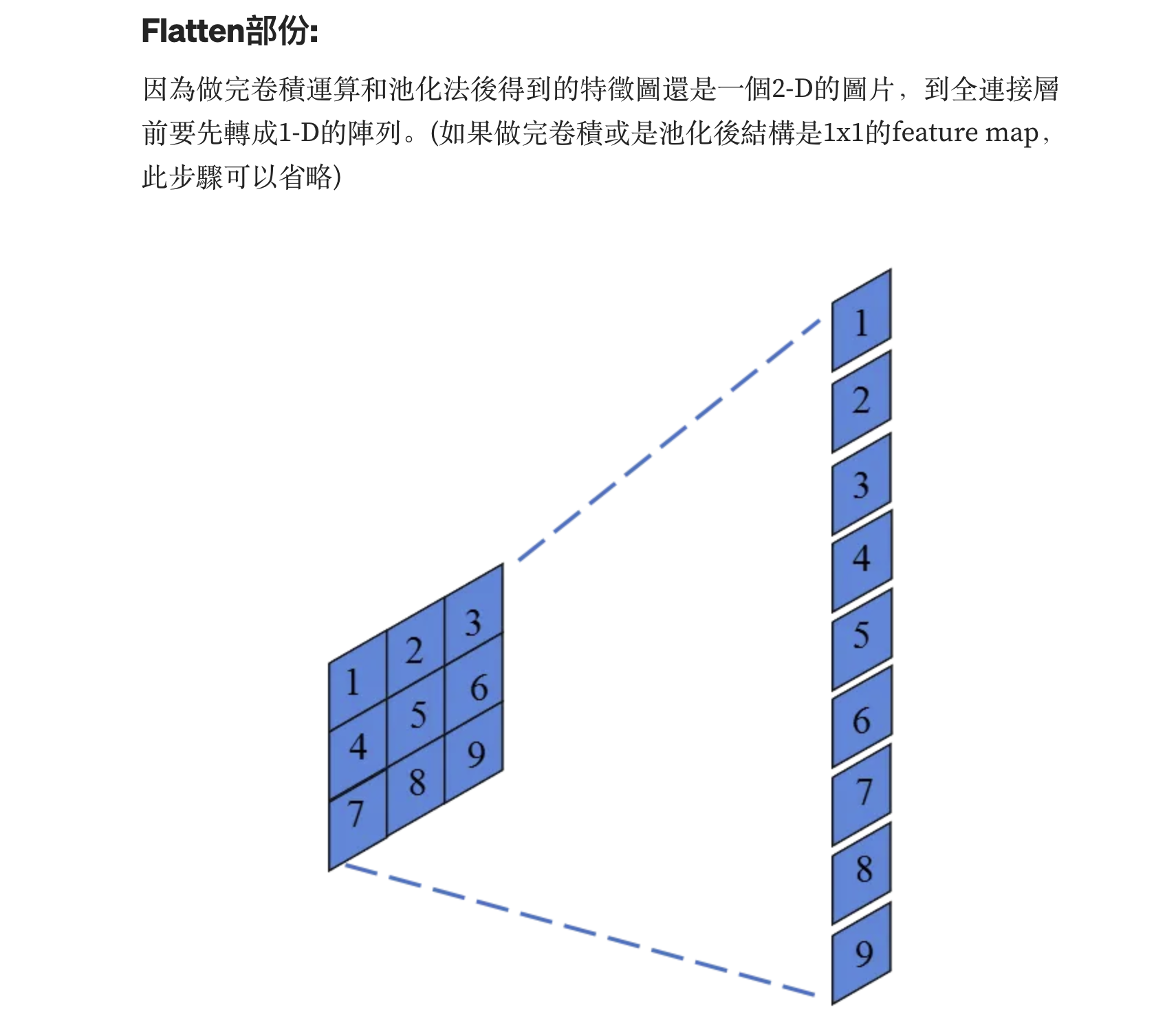
张量的flatten操作是使一个张量扁平化。如下图所示:
基于物理信息的神经网络(Physics-informed neural network,Pinn)


从一个简单的微分方程(Logistic方程)开始介绍:
{
d
f
d
t
=
R
f
(
t
)
(
1
−
f
(
t
)
f
(
t
=
0
)
=
0.5
\begin{cases} \frac{df}{dt}=Rf(t)(1-f(t)\\ f(t=0)=0.5 \end{cases}
{dtdf=Rf(t)(1−f(t)f(t=0)=0.5
Pinn的想法就是:构造损失函数,当最小化时,PDE就自动满足。也即最重要的损失贡献被视为微分方程的残差,如下所示:
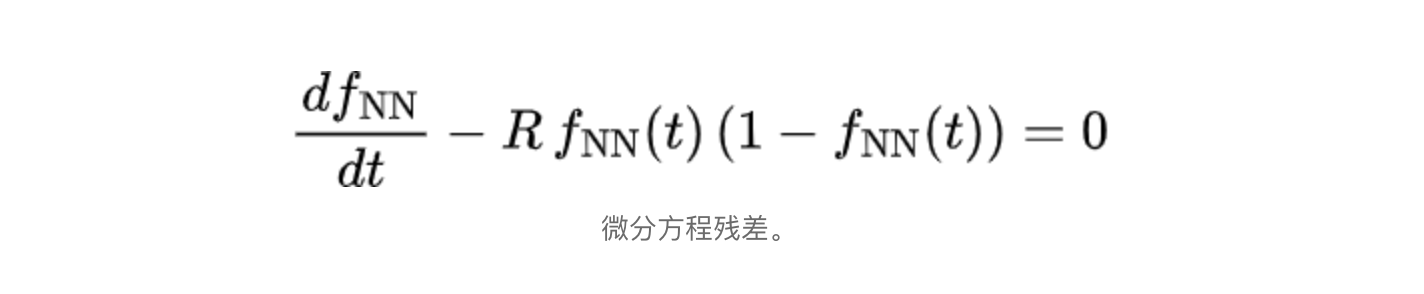
其中 f N N ( t ) f_{NN}(t) fNN(t)是具有一个输入的神经网络的输出,如果神经网络的输出符合上面的方程,那么实际上就是在求解微分方程。为了计算来自微分方程残差的实际损失贡献,需要指定方程域中的一组点(称为配置点)并评估均方误差(MSE)

然而,仅基于上述残差的损失并不能确保方程具有唯一的解。因此我们以与上面完全相同的方式将边界条件添加到损失计算中:

因此最终的损失可以写为:
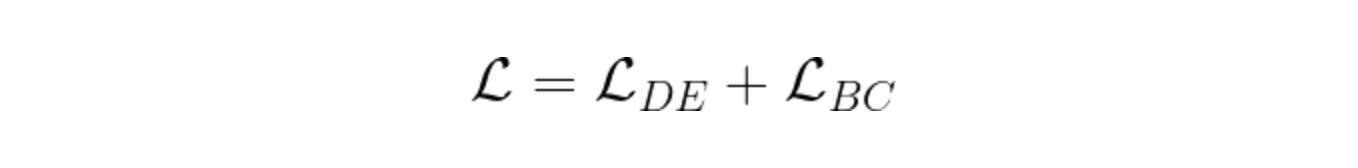
之后取 L \mathcal{L} L的最小值,可以得到满足微分方程和边界条件的近似解。
对抗生成网络(Generative Adversarial Network,GAN)
- 生成漫画人物
- 生成人脸照片
- 把草稿转换成图片
大白话版本理解:假设一个城市治安混乱,很快,这个城市里就会出现无数的小偷。在这些小偷中,有的可能是盗窃高手,有的可能毫无技术可言。假如这个城市开始整饬其治安,突然开展一场打击犯罪的「运动」,警察们开始恢复城市中的巡逻,很快,一批「学艺不精」的小偷就被捉住了。之所以捉住的是那些没有技术含量的小偷,是因为警察们的技术也不行了,在捉住一批低端小偷后,城市的治安水平变得怎样倒还不好说,但很明显,城市里小偷们的平均水平已经大大提高了。

警察们开始继续训练自己的破案技术,开始抓住那些越来越狡猾的小偷。随着这些职业惯犯们的落网,警察们也练就了特别的本事,他们能很快能从一群人中发现可疑人员,于是上前盘查,并最终逮捕嫌犯;小偷们的日子也不好过了,因为警察们的水平大大提高,如果还想以前那样表现得鬼鬼祟祟,那么很快就会被警察捉住。

为了避免被捕,小偷们努力表现得不那么「可疑」,而魔高一尺、道高一丈,警察也在不断提高自己的水平,争取将小偷和无辜的普通群众区分开。随着警察和小偷之间的这种「交流」与「切磋」,小偷们都变得非常谨慎,他们有着极高的偷窃技巧,表现得跟普通群众一模一样,而警察们都练就了「火眼金睛」,一旦发现可疑人员,就能马上发现并及时控制——最终,我们同时得到了最强的小偷和最强的警察。

非大白话版本:
生成对抗网络(GAN)由2个重要的部分构成:
- 生成器(Generator):通过机器生成数据(大部分情况下是图像),目的是“骗过”判别器
- 判别器(Discriminator):判断这张图像是真实的还是机器生成的,目的是找出生成器做的“假数据”

下面详细介绍一下过程:
第一阶段:固定「判别器D」,训练「生成器G」
我们使用一个还 OK 判别器,让一个「生成器G」不断生成“假数据”,然后给这个「判别器D」去判断。
一开始,「生成器G」还很弱,所以很容易被揪出来。
但是随着不断的训练,「生成器G」技能不断提升,最终骗过了「判别器D」。
到了这个时候,「判别器D」基本属于瞎猜的状态,判断是否为假数据的概率为50%。

第二阶段:固定「生成器G」,训练「判别器D」
当通过了第一阶段,继续训练「生成器G」就没有意义了。这个时候我们固定「生成器G」,然后开始训练「判别器D」。
「判别器D」通过不断训练,提高了自己的鉴别能力,最终他可以准确的判断出所有的假图片。
到了这个时候,「生成器G」已经无法骗过「判别器D」。

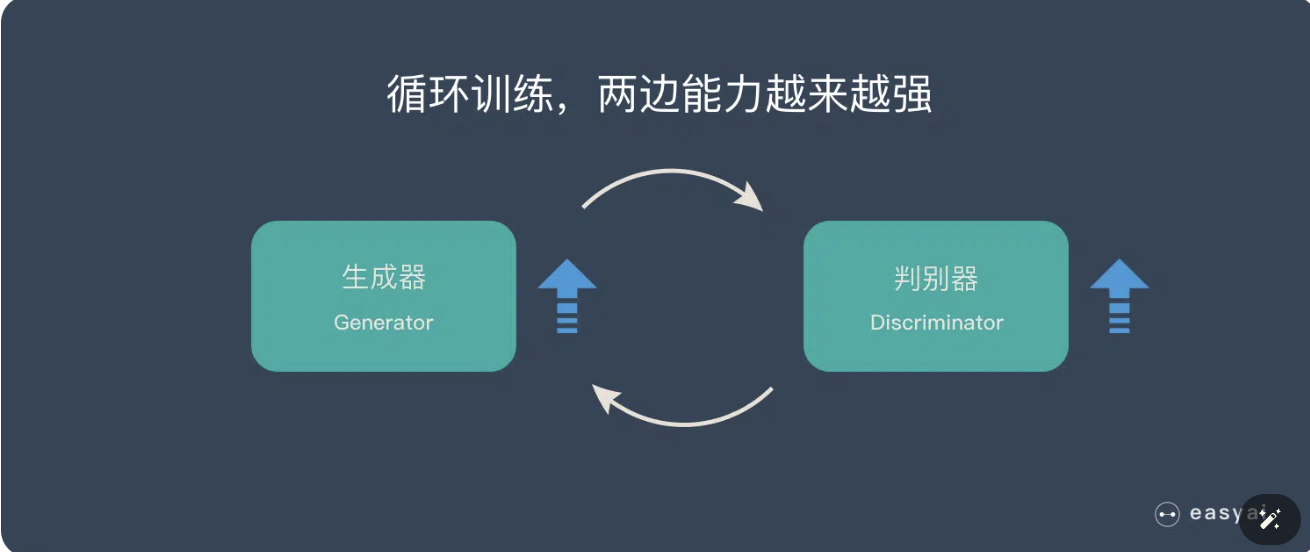
循环阶段一和阶段二
通过不断的循环,「生成器G」和「判别器D」的能力都越来越强。
最终我们得到了一个效果非常好的「生成器G」,我们就可以用它来生成我们想要的图片了。
图神经网络(Graph Neural Networks,GNN)
为什么需要GNN:像图片、语音、文本是很结构化的数据,这些可以用CNN,但是不是所有事物都可以表示成一个序列或者一个网格,例如社交网络,知识图谱,复杂的文件系统等,也就是说很多事物都是非结构化的。
流程:1.聚合 2.更新 3.循环
首先构造一个环境,
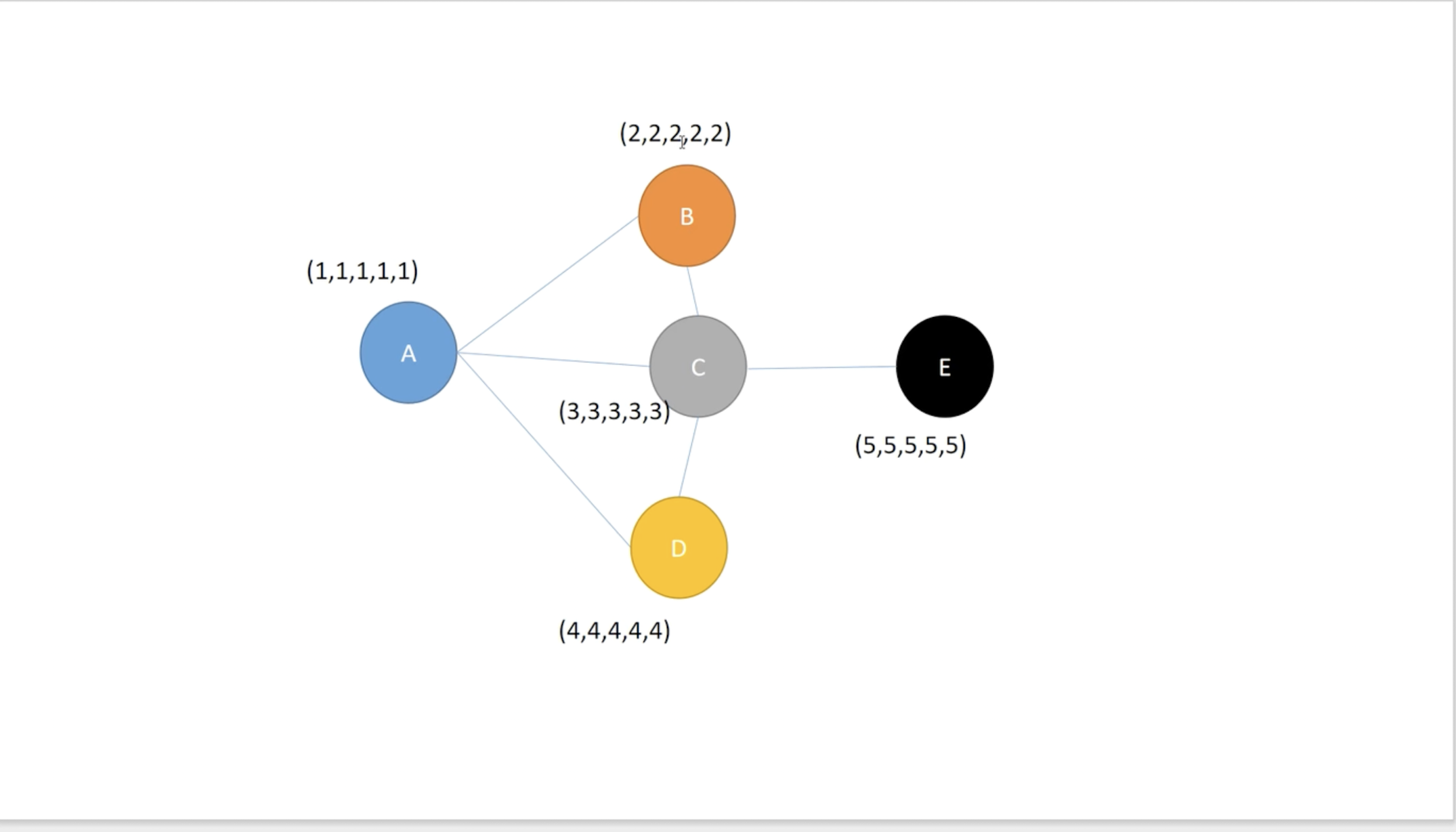
其中(1,1,1,1,1),(2,2,2,2,2),(3,3,3,3,3)是节点特征,可以是提取到的,也可以是预设的。
**聚合:**如果只看A的特征,难以判断A是属于哪一类的,但是通过B,C,D的特征,可以进一步判断A是属于哪一类的。也即如果单靠A的特征无法判断,就依靠A得邻居去判断。聚合过程即为:
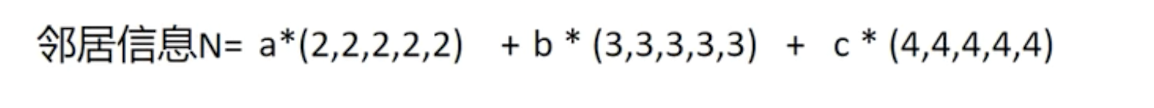
其中a,b,c可以通过模型训练确定,也可以自己设定。
也就是把A邻居的信息贴到A上面作为对A的补足。
**更新:**已知邻居信息和自己的特征之后,通过一下方式得到A最终的特征:

其中alpha可以自定义,是文章可以创新的地方。
以上是一层GNN操作之后A的信息。
多层:
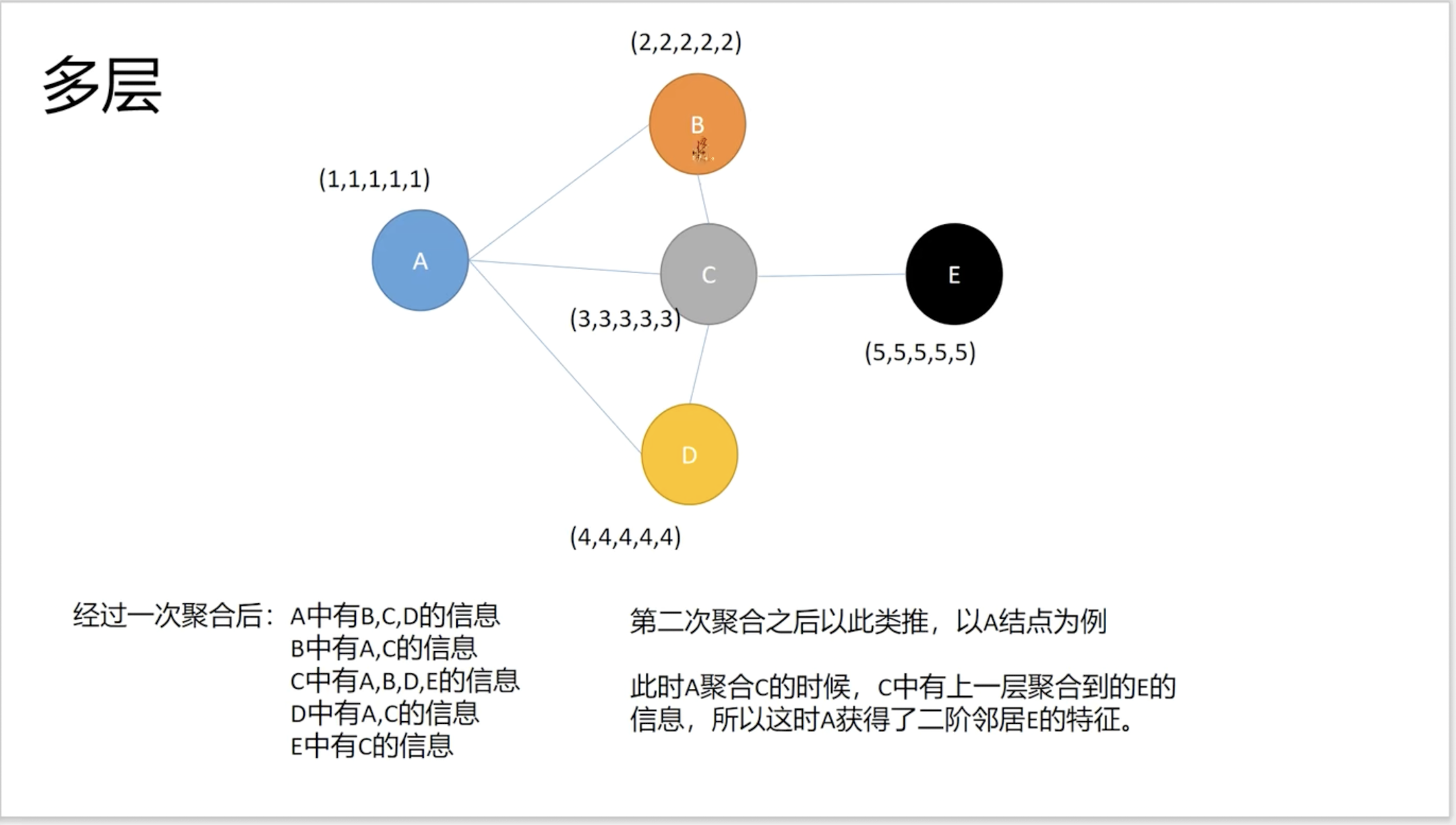
聚合一次的话,A只能聚集到B,C,D的信息;C可以聚集到A,B,D,E的信息。
然而聚合两次的话,A也会聚合C得信息,但是此时C已经包含E的信息了,所以第二次聚合的话A就会包含到E节点的信息。
最终:我们可以得到每个节点的信息,我们可以算loss去优化前面提到的权重W。
归根到底,GNN是一个提取特征的方法!!
有/无监督学习、半监督学习
**有监督学习算法:**根据指定算法输入和输出的样本数据进行训练。例如,数据可以是手写数字的图像,这些图像添加了注释以指示它们代表哪些数字。如果有足够的标记数据,有监督学习系统最终将识别与每个手写数字相关的像素和形状集群。
**无监督学习算法:**它会使用未标记的数据进行训练。该算法会扫描新数据,并在未知输入和预先确定的输出之间建立有意义的连接。例如,无监督学习算法可以将来自不同新闻网站的新闻文章分为体育和犯罪等常见类别。
举例就是:一个人参观画展,它们杂乱在一起了,我们并不知道它具体属于哪个流派,进去逛了一圈就有了自己主观的判断,会按照自己的理解去归类画作,这就相当于是无监督学习。但是如果不同的画作按照类别放在不同的展厅里,我们就可以直接去学习到这类画作的风格,这就是有监督学习,相当于打了标签。
















 2822
2822











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









