






 本文提出了一种基于神经网络的弱对抗网络方法,用于高效稳定地求解高维偏微分方程。通过将解和测试函数参数化为神经网络,无网格和无离散空间的特性使其适用于复杂几何区域。文章详细介绍了如何构造目标函数和训练算法,包括对边界条件的处理和时间依赖问题的两种求解策略。
本文提出了一种基于神经网络的弱对抗网络方法,用于高效稳定地求解高维偏微分方程。通过将解和测试函数参数化为神经网络,无网格和无离散空间的特性使其适用于复杂几何区域。文章详细介绍了如何构造目标函数和训练算法,包括对边界条件的处理和时间依赖问题的两种求解策略。
Weak adversarial networks for high-dimensional partial differential equations

本文讨论如上的文章。
由于基于有限差分和有限元的经典数值方法存在计算缓慢、不稳定和维数灾难的问题。同时因为有限元、有限差分网格点的数量相当于问题的维数d呈指数级快速增加,所以发展基于神经网络的方法。
首先考虑如下具有Dirichlet或者Neumann边界条件的二阶椭圆PDE:
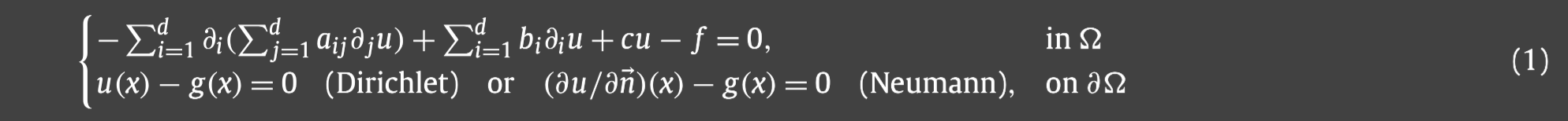
其中: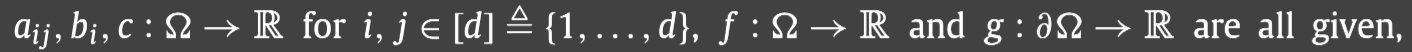
并且椭圆算子具有如下的强椭圆性:存在一个常数 θ > 0 \theta>0 θ>0,满足 ξ T A ( x ) ξ ≥ 0 \xi^TA(x)\xi\ge0 ξTA(x)ξ≥0对于所有的 ξ = ( ξ 1 , ⋯ , ξ d ) ∈ R d \xi=(\xi_1,\cdots,\xi_d)\in\mathbb{R}^d ξ=(ξ1,⋯,ξd)∈Rd
同时我们也考虑求解如下涉及时间的PDE: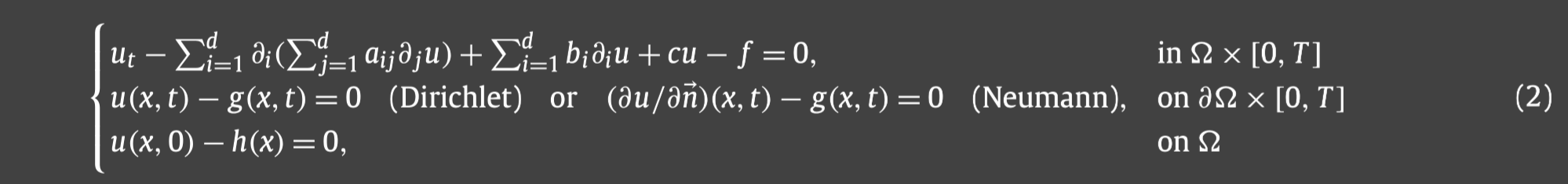
如下将弱解和测试函数分别参数化为原始和对抗神经网络,并采用无监督的形式训练他们,同时在配置点求对应误差。这种方法不需要离散空间,在求解一般高维PDE时快速稳定。同时该方法完全无网格,可以应用于任意形状区域上的PDE.
让我们首先关注边值问题(1):
在方程(1)两端乘函数
ϕ
∈
H
0
1
(
Ω
;
R
)
\phi\in H_0^1(\Omega;\mathbb{R})
ϕ∈H01(Ω;R),分部积分得到: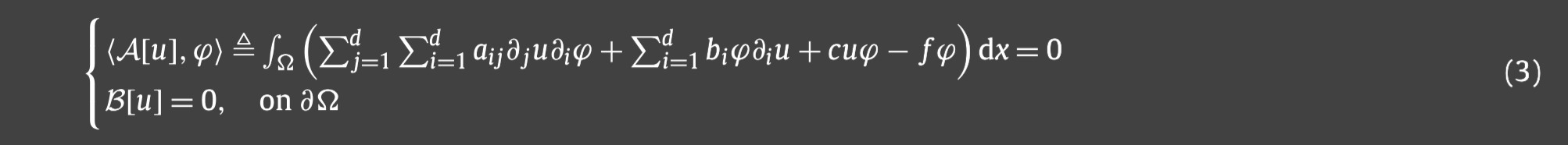
PDE(3)的解就是(1)的弱解,(1)的解称为强解。强解存在的话弱解一定存在,并且两者一定会相等,但弱解存在的话强解不一定存在。
我们可以这么考虑弱解:
A
[
u
]
:
H
0
1
(
Ω
)
→
R
\mathcal{A}[u]:H_0^1(\Omega)\rightarrow\mathbb{R}
A[u]:H01(Ω)→R作为一个泛函满足:
A
[
u
]
(
ϕ
)
:
=
<
A
[
u
]
,
ϕ
>
\mathcal{A}[u](\phi):=<\mathcal{A}[u],\phi>
A[u](ϕ):=<A[u],ϕ>,就如(3)中定义的那样。那么泛函
A
[
u
]
\mathcal{A}[u]
A[u]的范数即为(由
L
2
L^2
L2范数诱导):
所以
u
u
u是(1)的弱解当且仅当
∥
A
[
u
]
∥
o
p
=
0
\Vert\mathcal{A}[u]\Vert_{op}=0
∥A[u]∥op=0并且满足边界条件
B
[
u
]
=
0
\mathcal{B}[u]=0
B[u]=0。当
∥
A
[
u
]
∥
o
p
≥
0
\Vert\mathcal{A}[u]\Vert_{op}\ge0
∥A[u]∥op≥0时,利用弱解,我们可以得到如下的等价推论:
从而可以得到如下的定理: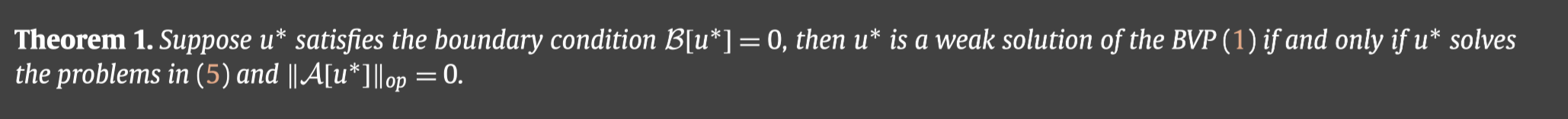
上述定理启发我们,为了得到(1)的弱解,我们可以寻找使得(5)达到最优值的最优解 u u u.
同时(5)启发我们寻找函数 u θ : R d → R u_\theta:\mathbb{R}^d\rightarrow \mathbb{R} uθ:Rd→R,使得 ∥ A [ u θ ] ∥ o p \Vert\mathcal{A}[u_\theta]\Vert_{op} ∥A[uθ]∥op最小,其中 θ \theta θ是待学习的深度神经网络的参数;另一方面,测试函数 ϕ \phi ϕ是一个参数为 η \eta η的深度对抗网络,它通过最大化 < A [ u θ ] , ϕ η > <\mathcal{A}[u_\theta],\phi_\eta> <A[uθ],ϕη>的范数来达到和 u θ u_\theta uθ对抗的目的.
为了训练神经网络神经网络,我们首先需要构建关于
u
θ
u_\theta
uθ和
ϕ
η
\phi_\eta
ϕη的目标函数。考虑到对数函数是单调而且严格递增的,所以我们可以重新公式化(5)为:
除此之外,弱解还需要满足(1)中的边界条件 B [ u ] = 0 \mathcal{B}[u]=0 B[u]=0,选取边界上 N b N_b Nb个配置点,那么Dirichlet边界条件可以刻画为:
 同样地,对于Neumann边界条件,可以同样处理.
同样地,对于Neumann边界条件,可以同样处理.
那么总目标函数就是两个目标(6)和(7)的加权和,为此我们需要寻找一个鞍点来解决如下的这个极小极大问题.
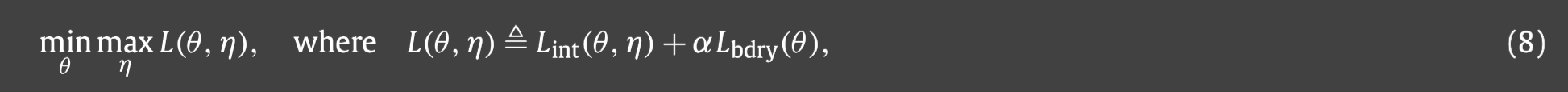
对于给定的目标函数(8),网络训练的关键要素是 L ( θ , η ) L(\theta,\eta) L(θ,η)关于参数 θ , η \theta,\eta θ,η的梯度,那么 θ , η \theta,\eta θ,η可以通过梯度下降和上升来优化.
为了获得(8)中的
L
i
n
t
L_{int}
Lint的梯度,我们首先令
<
A
[
u
]
,
ϕ
>
<\mathcal{A}[u],\phi>
<A[u],ϕ>的被积函数是
I
I
I,那么可以知道对于二阶椭圆PDE方程(1),
I
I
I的梯度即为: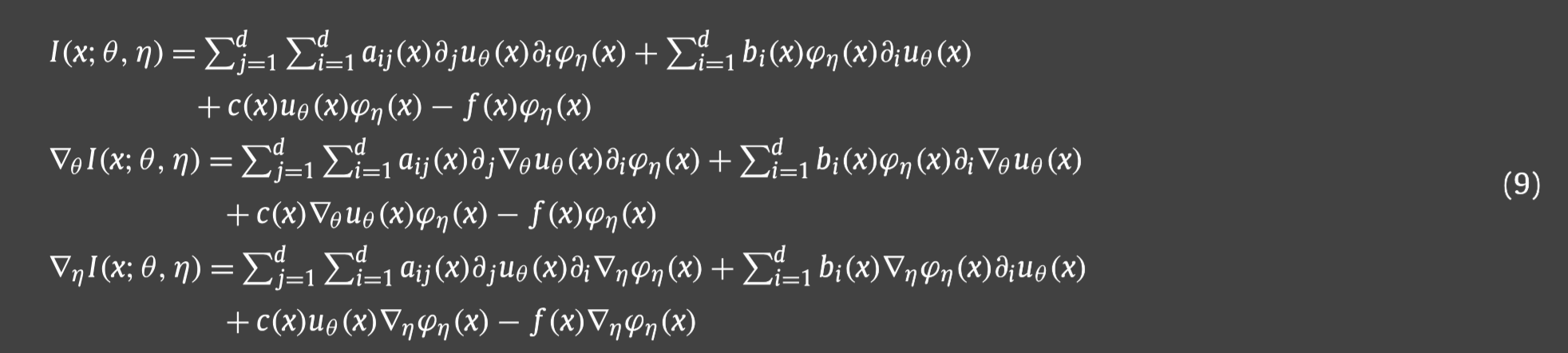
由此我们可以得到
L
i
n
t
L_{int}
Lint的梯度: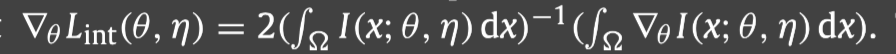
通过随机选取配置点的方法,可以将
∇
θ
L
i
n
t
\nabla_\theta L_{int}
∇θLint离散。接下去可以应用交替更新来优化参数
θ
\theta
θ和
η
\eta
η.从而产生如下的算法,称为弱对抗网络(WAN):
我们还可以把WAN扩展到求解具有时间导数的PDE,也即IBVP.如下有两种方法:一种是在时间上采用半离散化,并对每个 t n t_n tn,都是与时间无关的PDE,从而可以迭代求解 u ( x , t n ) u(x,t_n) u(x,tn),其中算法1可以直接作为求解的子程序;第二种方法是不用任何离散化操作,只是联合处理x和t,并考虑整个区域 Ω × [ 0 , T ] \Omega\times[0,T] Ω×[0,T]的弱解和测试函数.
1.我们首先将[0,T]划分为N等分,然后用有限差分中的CN格式对上面提到的方程(2)中的时间导数进行离散,得到: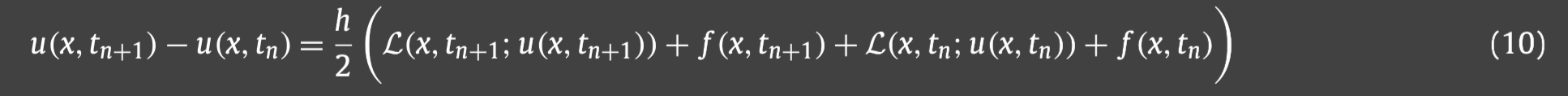
其中: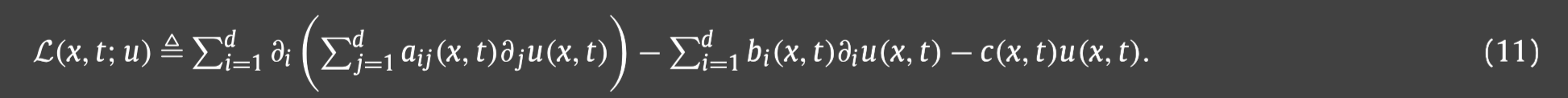
更确切地说,我们以
u
(
x
,
t
0
)
=
u
(
x
,
0
)
=
h
(
x
)
u(x,t_0)=u(x,0)=h(x)
u(x,t0)=u(x,0)=h(x)开始,然后对于n=0,从(10)中求解得到
u
(
x
,
t
1
)
u(x,t_1)
u(x,t1),由于(10)是关于
u
(
x
,
t
1
)
u(x,t_1)
u(x,t1)的椭圆PDE,所以可以直接应用算法1,得到
u
(
x
,
t
1
)
u(x,t_1)
u(x,t1)作为输出的参数为
θ
1
\theta_1
θ1的参数化神经网络
u
θ
1
(
x
)
u_{\theta_1}(x)
uθ1(x).类似的,我们可以得到
u
(
x
,
t
n
)
=
u
θ
n
(
x
)
u(x,t_n)=u_{\theta_n}(x)
u(x,tn)=uθn(x).算法过程如下:
2.第二种需要先得到(2)的弱公式(通过在(2)两边乘以检验函数),得到: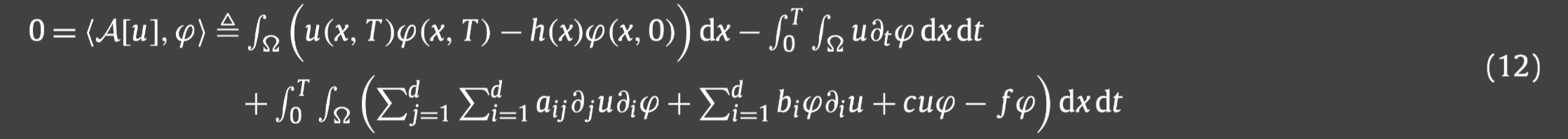
之后我们仿照之前的做法,把弱解
u
u
u和测试函数
ϕ
\phi
ϕ参数化为深度神经网络
u
θ
u_\theta
uθ和
ϕ
η
\phi_{\eta}
ϕη:
Ω
×
[
0
,
T
]
→
R
\Omega\times[0,T]\rightarrow\mathbb{R}
Ω×[0,T]→R.同时它的目标函数是:
其中:
对应的算法如下:
















 1987
1987

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









