






DeepOnet
C(K)是定义在紧集K上的全体连续函数构成的空间;V是C(K)上的紧集.
这里
∑
c
i
σ
(
λ
i
x
+
θ
i
)
\sum c_i\sigma(\lambda_ix+\theta_i)
∑ciσ(λix+θi)形式上非常像
x
x
x被权重和偏置作用之后再经过一个激活函数,然后乘上一些系数再求和. 这个定理就是为了告诉我们激活函数都是TW函数.
这个定理就是为了告诉我们激活函数都是TW函数.
然后有如下的泛函万有逼近定理:
紧接着的是如下的算子的万有逼近定理: 可以发现绝对值中的第二项是形如【激活函数(权重*输入+偏置)*激活函数(权重*输入+偏置)】的形式,也即可以构造两个神经网络,让这两个神经网络的输出相乘来近似算子.
可以发现绝对值中的第二项是形如【激活函数(权重*输入+偏置)*激活函数(权重*输入+偏置)】的形式,也即可以构造两个神经网络,让这两个神经网络的输出相乘来近似算子.
如果这个G(u)(y)是PDE的解,那么对其展开: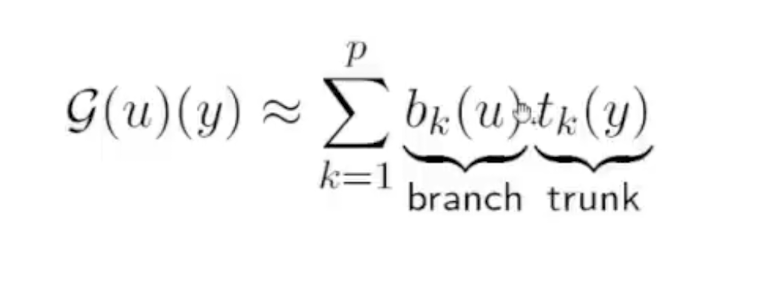
Unstacked DeepOnet: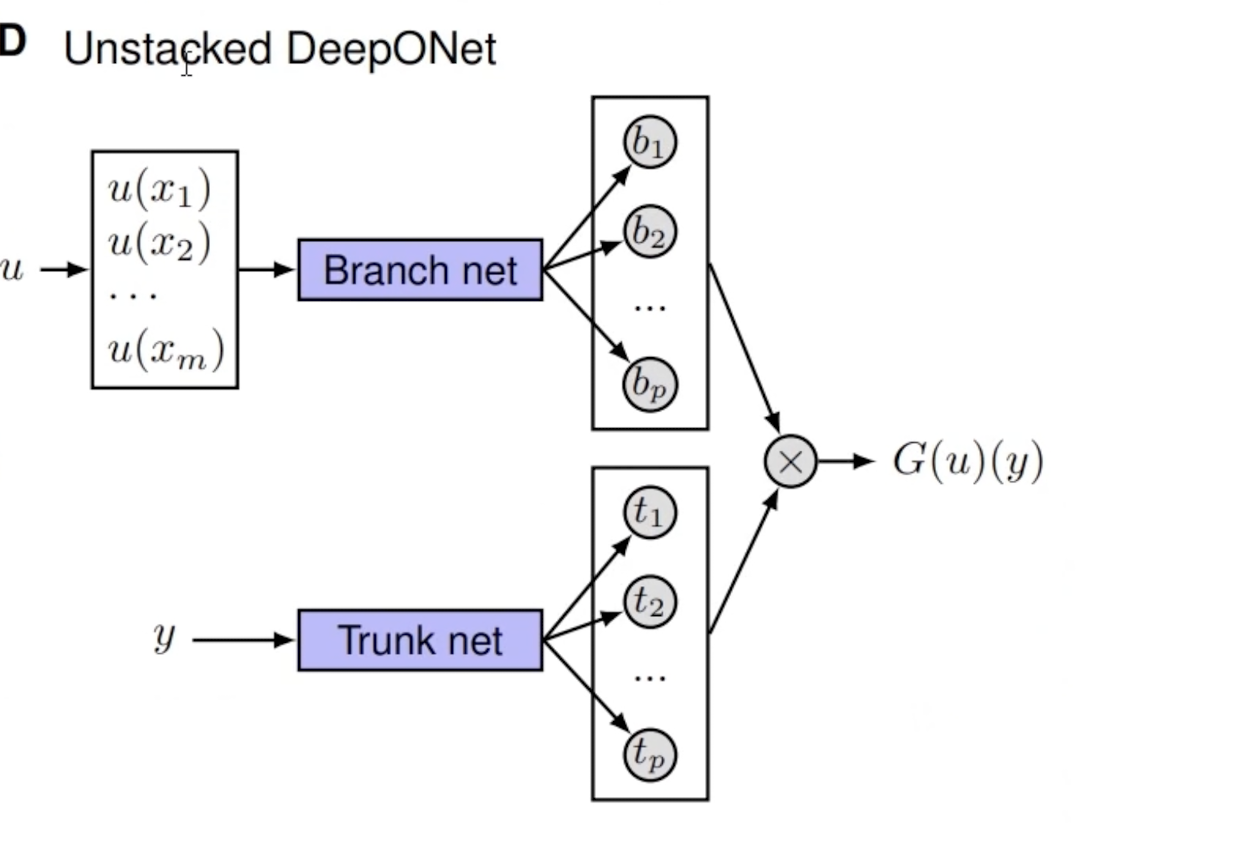 也就是先有一个输入函数,第一步是先把它离散成为信号,之后把这个信号放入Branch net便会得到一个输出;然后把y放入Trunk net会得到一些结果。把这两部分结果点乘,可以得到G(u)(y)的结果,是个数。(Trunk net是自适应地学习对应于这个PDE而言,最优的基函数是什么。同时这个Trunk net可以用全连接,因为y的维数低,只有1,2,3维;若u在正方形网格上,Branch net可以用CNN)
也就是先有一个输入函数,第一步是先把它离散成为信号,之后把这个信号放入Branch net便会得到一个输出;然后把y放入Trunk net会得到一些结果。把这两部分结果点乘,可以得到G(u)(y)的结果,是个数。(Trunk net是自适应地学习对应于这个PDE而言,最优的基函数是什么。同时这个Trunk net可以用全连接,因为y的维数低,只有1,2,3维;若u在正方形网格上,Branch net可以用CNN)
相比之下,之前的网络架构是如下的形式: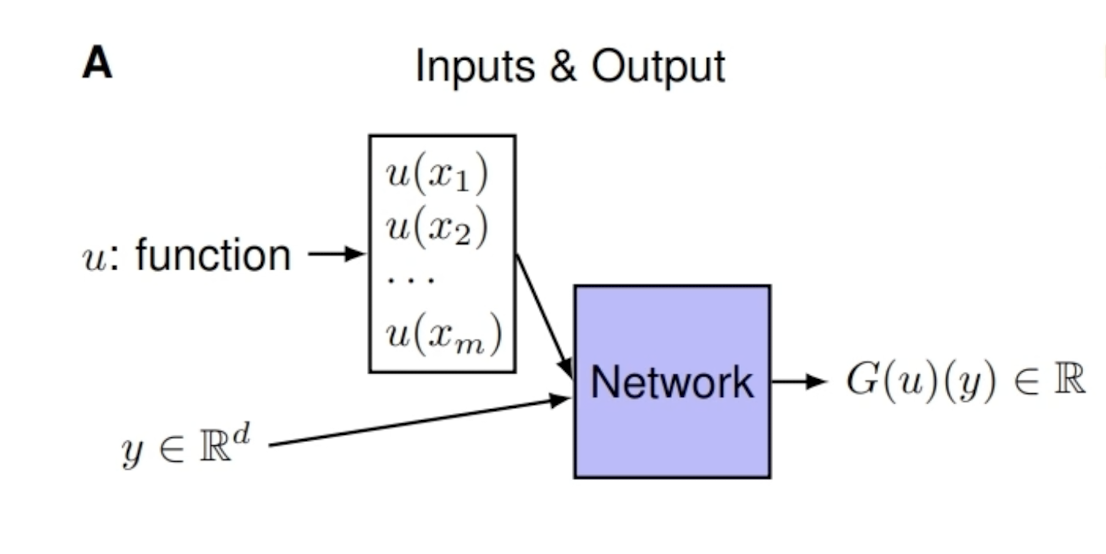
为什么需要两个神经网络来描述呢,是因为对于如下这样的情形,只知道G(u)在三个y点处的值,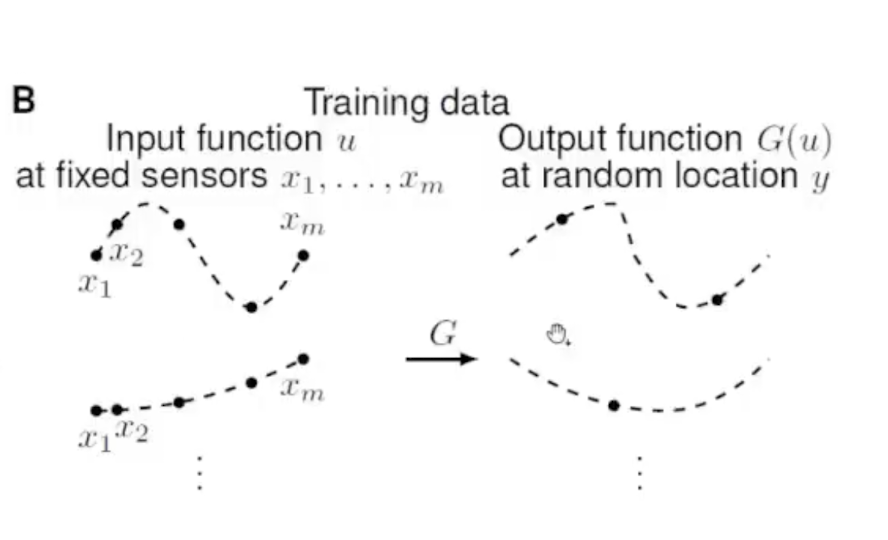
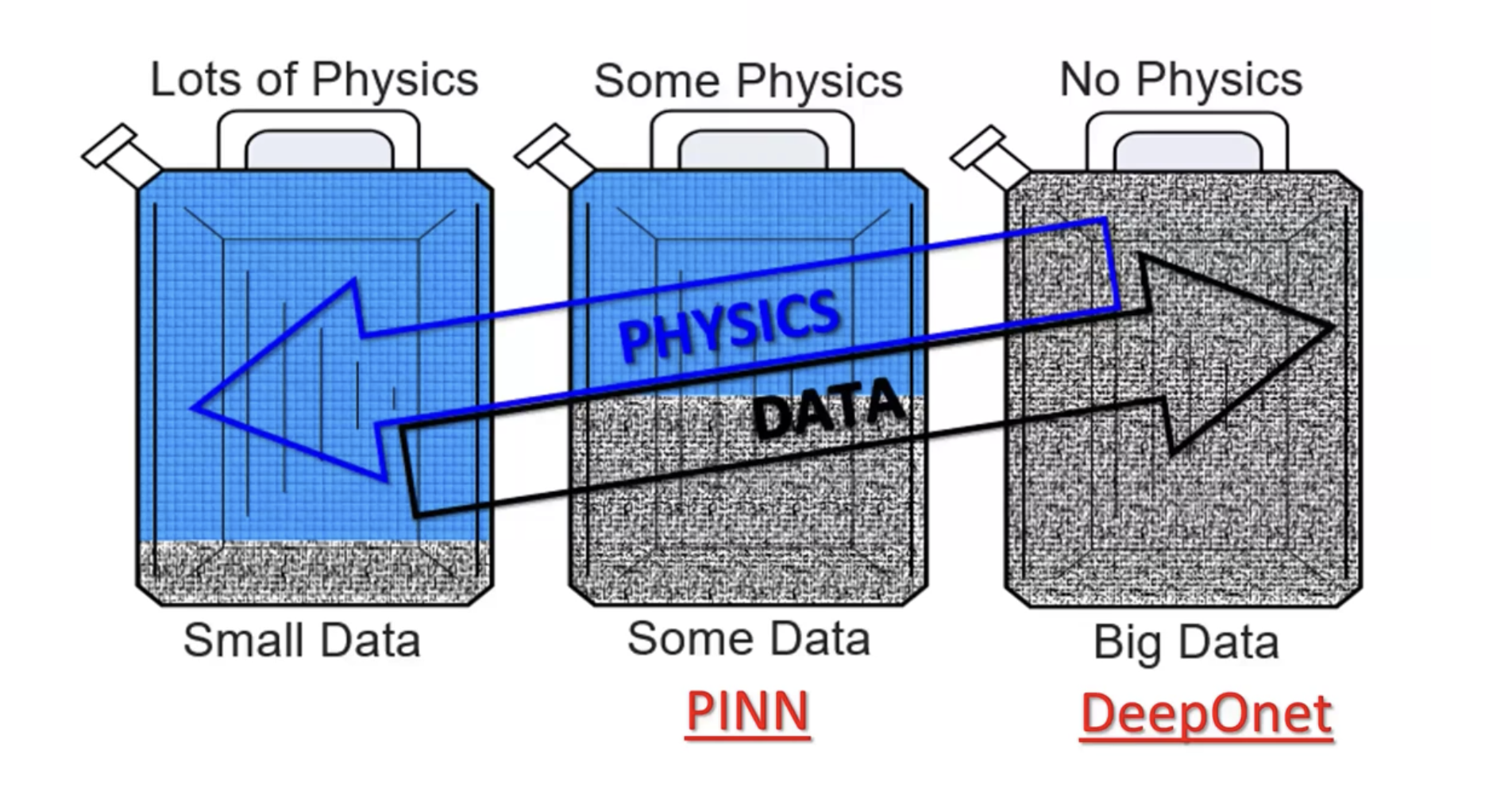
拓展:deeponet只适用于:只有初值条件或者只有边界条件的PDE求解,但是下面的方法对此进行了拓展,可以同时对初边值的PDE进行求解。
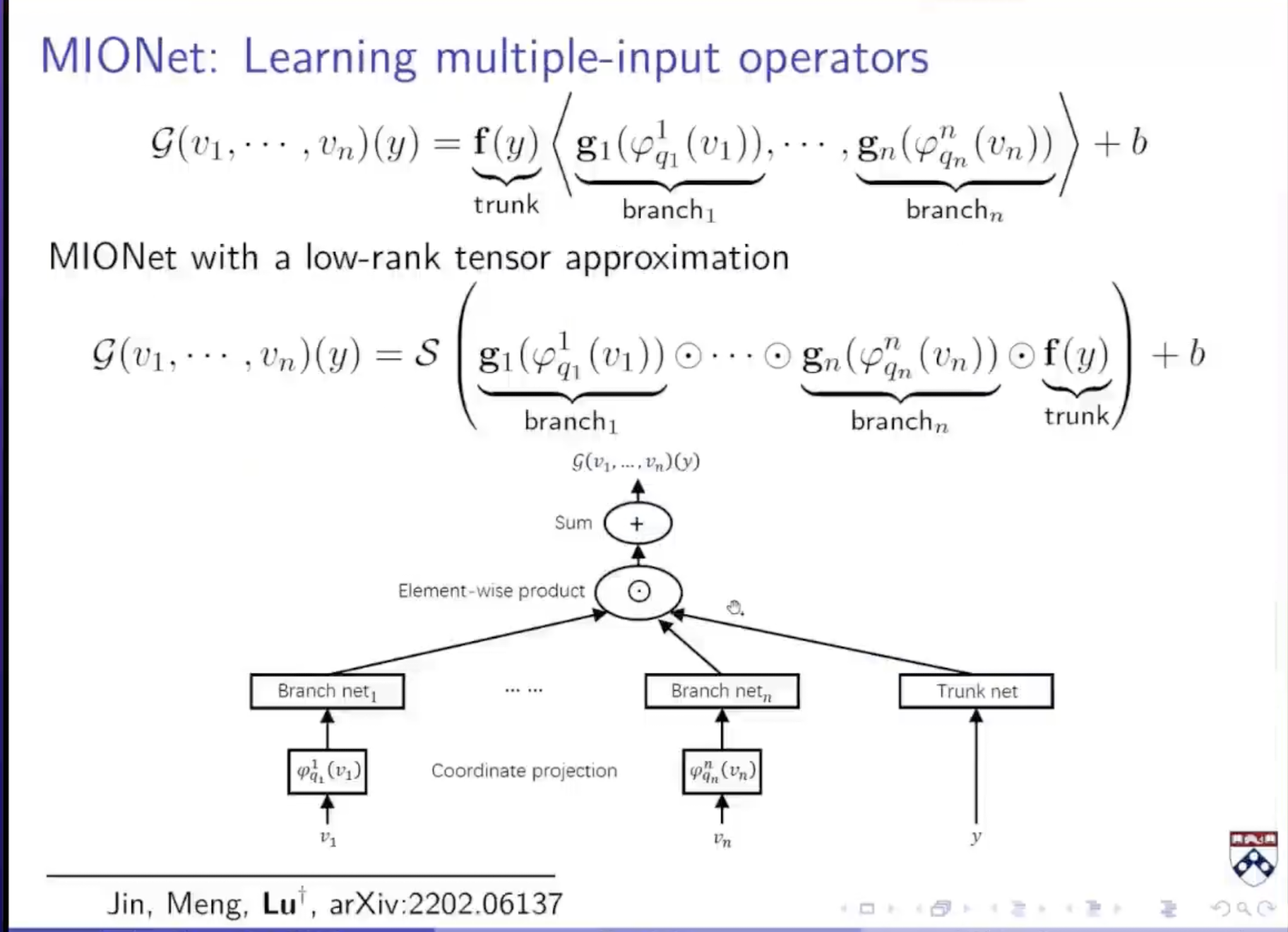
上面的定理保证了只要网格足够大,就一定能逼近任意多输入的算子
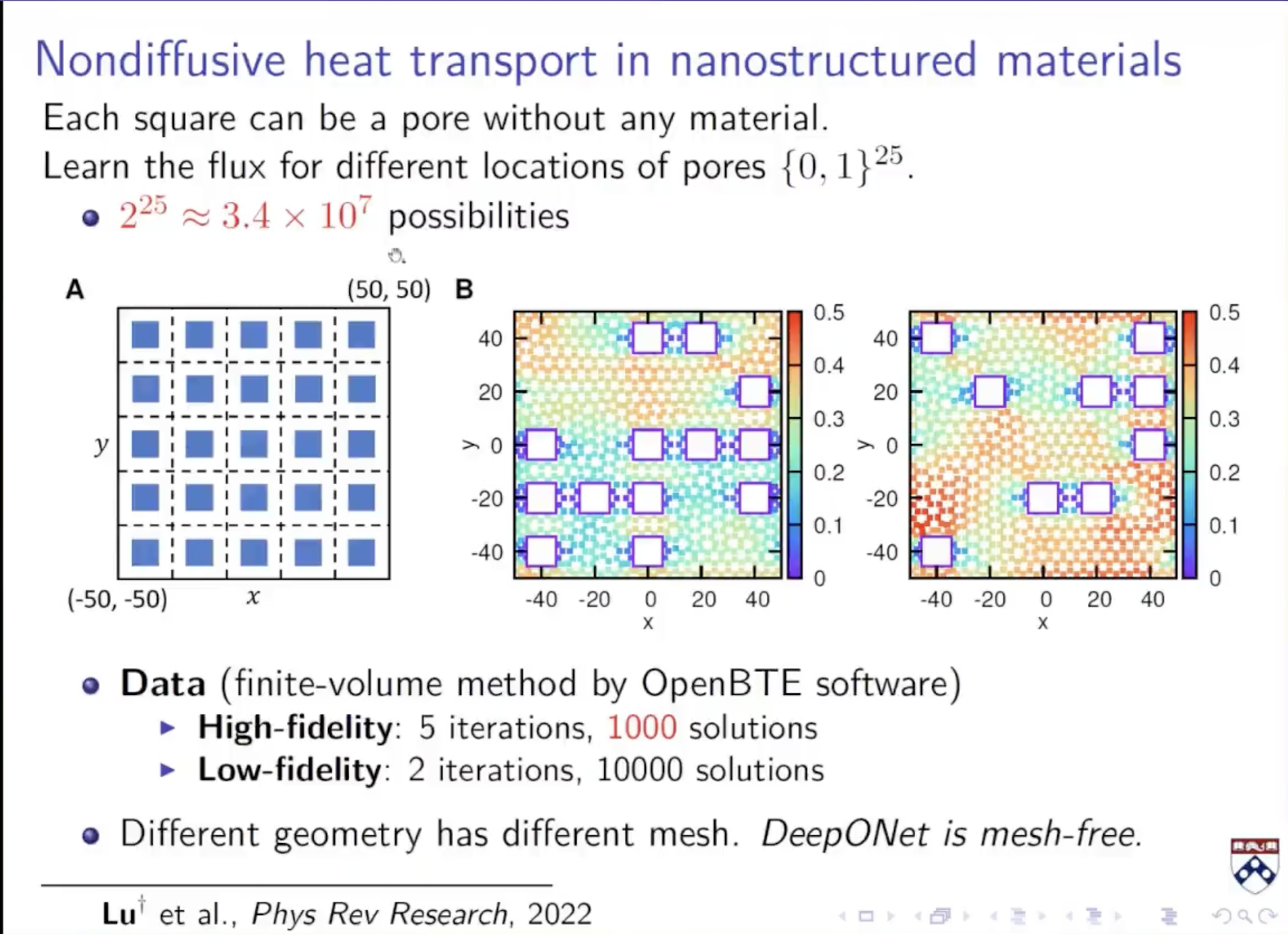
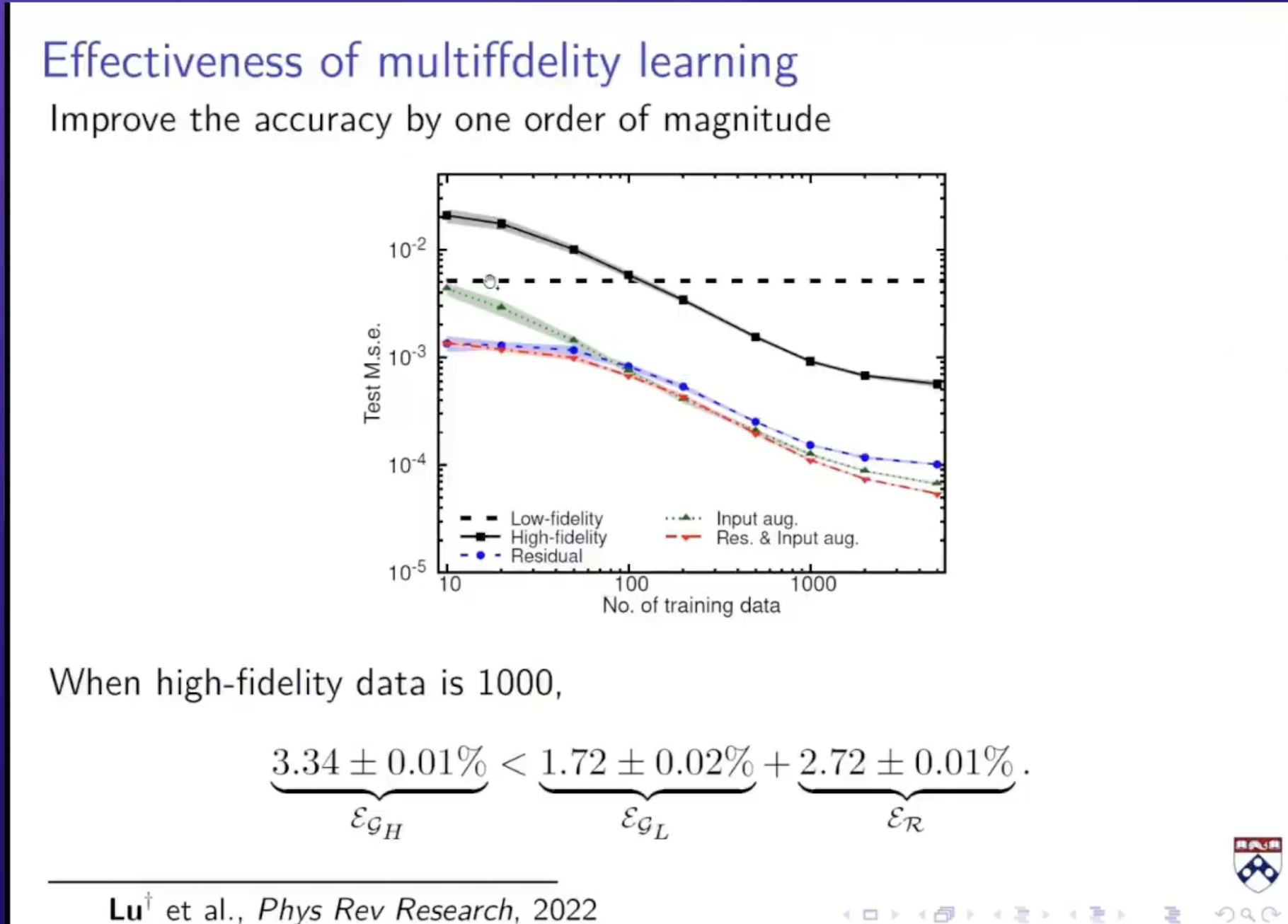
除此之外:如果我有两组数据,一组是高精度但是数据量少,一组是低精度但是数据量很多
不是直接学习输入到输出的算子。而是先学习低精度的数据,由于低精度数据足够大,所以可以训练一个得到deeponet;然后学习低精度和高精度的修正项R,得到另一个deeponet;
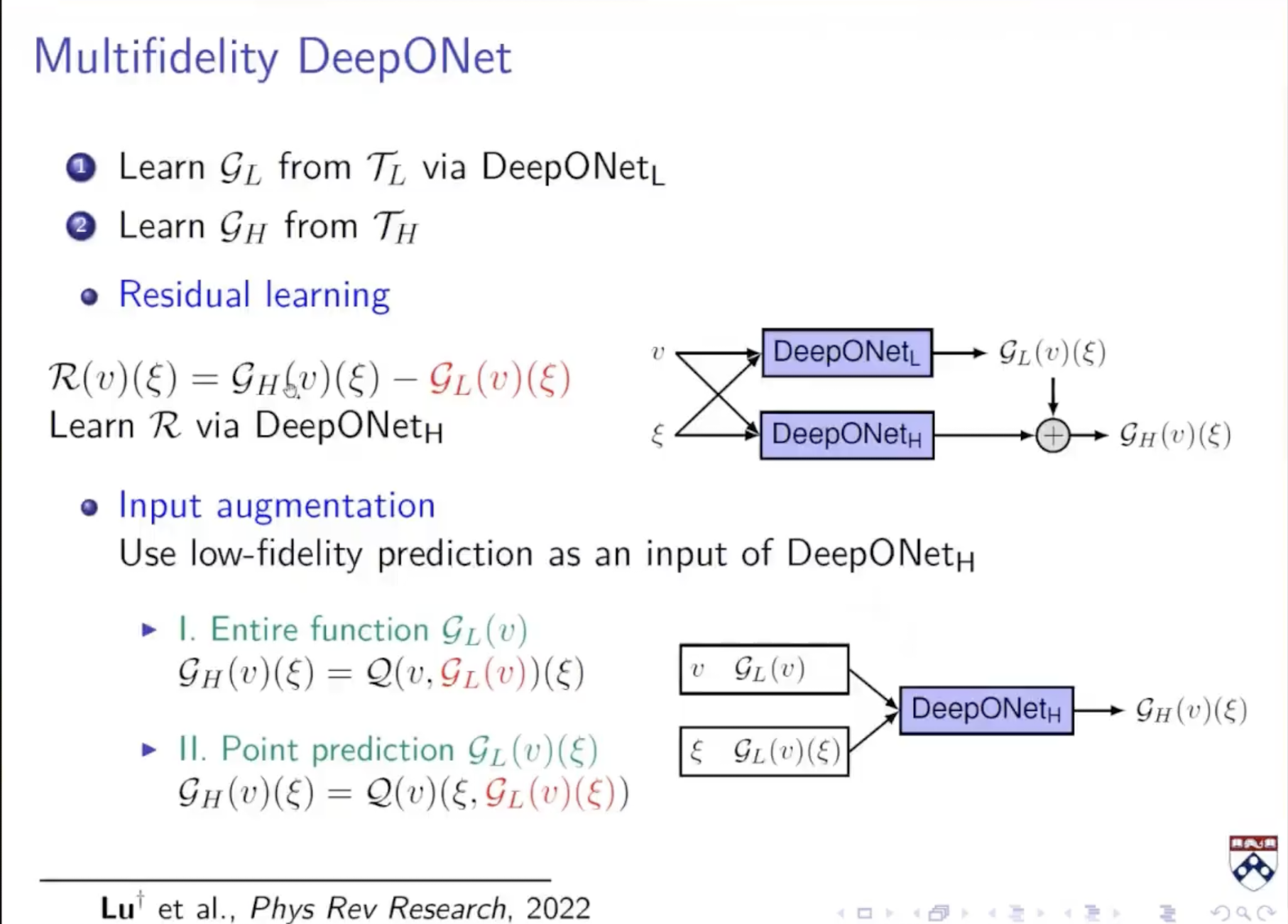
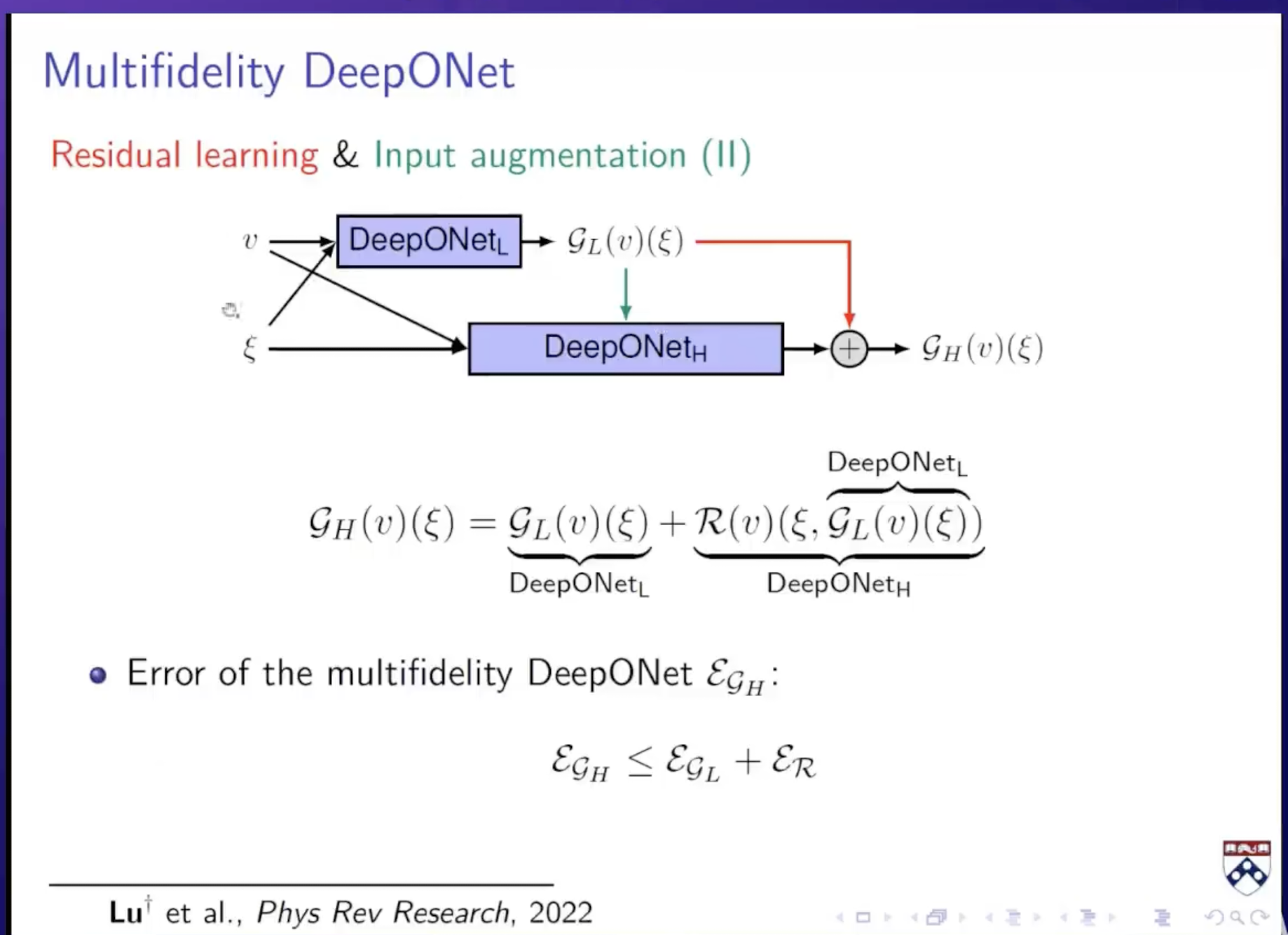
最后的网络即为:deeponet_L主要用于训练低精度的数据;deeponet_H主要用于学习修正项,对于deeponet_H,它不仅把函数和坐标作为输入,也把低精度的预测值也作为输入;最后deeponet_H的输出和低精度数据预测值加在一起作为高精度数据的预测值
















 3178
3178











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









