






import time
import warnings
from itertools import cycle, islice
import matplotlib.pyplot as plt
import numpy as np
from sklearn import cluster, datasets
from sklearn.preprocessing import StandardScaler
n_samples = 1500
# 生成圆形数据集(含有噪声)
noisy_circles = datasets.make_circles(n_samples=n_samples, factor=0.5, noise=0.05, random_state=170)
# 生成月亮数据集(含有噪声)
noisy_moons = datasets.make_moons(n_samples=n_samples, noise=0.05, random_state=170)
# 生成高斯分布的数据集
blobs = datasets.make_blobs(n_samples=n_samples, random_state=170)
# 生成均匀分布的数据集
rng = np.random.RandomState(170)
no_structure = rng.rand(n_samples, 2), None
# 异方差分布的数据集
X, y = datasets.make_blobs(n_samples=n_samples, random_state=170)
transformation = [[0.6, -0.6], [-0.4, 0.8]]
X_aniso = np.dot(X, transformation)
aniso = (X_aniso, y)
# 方差不同的聚类数据集
varied = datasets.make_blobs(n_samples=n_samples, cluster_std=[1.0, 2.5, 0.5], random_state=170)
# 设置绘图参数
plt.figure(figsize=(9 * 1.3 + 2, 14.5))
plt.subplots_adjust(left=0.02, right=0.98, bottom=0.001, top=0.96, wspace=0.05, hspace=0.01)
plot_num = 1
default_base = {"n_neighbors": 10, "n_clusters": 3}
datasets = [
(noisy_circles, {"n_clusters": 2}),
(noisy_moons, {"n_clusters": 2}),
(varied, {"n_neighbors": 2}),
(aniso, {"n_neighbors": 2}),
(blobs, {}),
(no_structure, {}),
]
# 对每个数据集进行聚类
for i_dataset, (dataset, algo_params) in enumerate(datasets):
# 更新参数为数据集特定的值
params = default_base.copy()
params.update(algo_params)
X, y = dataset
# 对数据集进行标准化处理,以便于参数选择
X = StandardScaler().fit_transform(X)
# 创建聚类对象
ward = cluster.AgglomerativeClustering(n_clusters=params["n_clusters"], linkage="ward")
complete = cluster.AgglomerativeClustering(n_clusters=params["n_clusters"], linkage="complete")
average = cluster.AgglomerativeClustering(n_clusters=params["n_clusters"], linkage="average")
single = cluster.AgglomerativeClustering(n_clusters=params["n_clusters"], linkage="single")
clustering_algorithms = (
("Single Linkage", single),
("Average Linkage", average),
("Complete Linkage", complete),
("Ward Linkage", ward),
)
for name, algorithm in clustering_algorithms:
t0 = time.time()
# 捕捉与kneighbors_graph相关的警告
with warnings.catch_warnings():
warnings.filterwarnings("ignore",
message="the number of connected components of the "
+ "connectivity matrix is [0-9]{1,2}"
+ " > 1. Completing it to avoid stopping the tree early.",
category=UserWarning)
algorithm.fit(X)
t1 = time.time()
if hasattr(algorithm, "labels_"):
# 获取聚类样本的标签,转换为int类型
y_pred = algorithm.labels_.astype(int)
else:
y_pred = algorithm.predict(X)
# 绘图
plt.subplot(len(datasets), len(clustering_algorithms), plot_num)
if i_dataset == 0:
plt.title(name, size=18)
# 设置颜色
colors = np.array(list(
islice(
cycle(["#377eb8", "#ff7f00", "#4daf4a", "#f781bf", "#a65628", "#984ea3", "#999999", "#e41a1c", "#dede00"]),
int(max(y_pred) + 1)
)
))
# 绘制散点图 color=colors[y_pred]根据y_pred中的聚类标签值,将散点的颜色设置为对应的颜色值。
plt.scatter(X[:, 0], X[:, 1], s=10, color=colors[y_pred])
plt.xlim(-2.5, 2.5)
plt.ylim(-2.5, 2.5)
plt.xticks(())
plt.yticks(())
plt.text(0.99, 0.01, ("%.2fs" % (t1 - t0)).lstrip("0"), transform=plt.gca().transAxes,
size=15, horizontalalignment="right")
plot_num += 1
plt.show()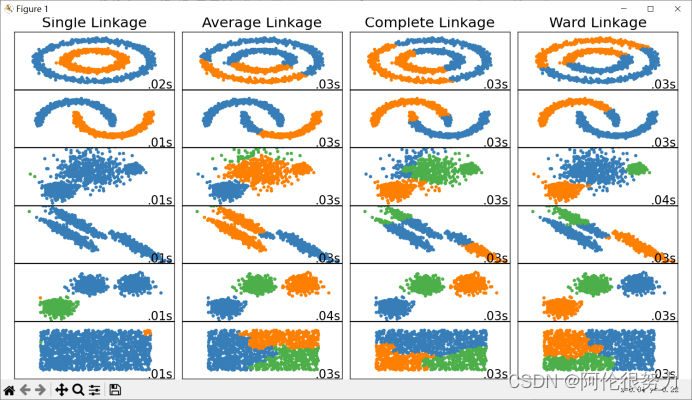
心得:
1.首先解释下这个结果:从左往右,分类算法依次是:Single Linkage(单链接法),Average Linkage(平均链接法),Complete Linkage(完全链接法),Ward Linkage(沃德链接法),从上往下数据类型依次是:环形数据,月亮形数据,方差不同的聚类数据,异方差分布的数据,高斯分布的数据,均匀分布的数据。
2.从分类结果可以看出,对于环形数据,月亮形数据,single linkage表现最好,方差不同的聚类数据,异方差分布的数据,ward linkage 表现比其他算法来得好,按高斯分布的数据除了single linkage外,表现都不错。
3.From what have mentioned above,对于不同的数据集合,往往需要采用不同的聚类算法,具体采用哪种呢?那就都试试,哪种表现好就用哪种。
4.Q:为什么algorithm.fit(X)要放在异常捕获里面
在实际的使用中,由于数据集的特征、规模、分布等因素的多样性,可能会导致聚类算法在某些情况下出现不可避免的异常情况或错误。
例如,在使用KMeans聚类算法时,如果数据集中包含异常值、数据规模较大或者数据分布不均匀等情况,可能会导致算法出现警告或错误,并产生异常行为或不合理的结果。因此,为了避免这种情况的发生,我们通常会将算法的fit方法放在警告捕捉或异常捕捉的语句块中,以避免算法错误或意外程序中断。
5.模型的评价很重要的一点是时间问题,结果图中右下角是所用时间,可以通过导入库time来辅助实现时间的记录。
6.以下是上述各种聚类算法简单介绍,来源ChatGpt:
Single Linkage(单链接法)是一种聚类算法,它根据数据点之间的最小距离来进行聚类的过程。它的基本思想是将距离最近的两个数据点归为一类,然后逐步合并其他数据点,直到满足停止聚类的条件。
Average Linkage(平均链接法)是一种基于距离的聚类算法,它根据数据点之间的平均距离来进行聚类。它的核心思想是计算两个聚类之间所有数据点的平均距离,选择平均距离最小的两个聚类进行合并。
Complete Linkage(完全链接法)是一种基于距离的聚类算法,它根据数据点之间的最大距离来进行聚类。它的核心思想是计算两个聚类之间的最大距离,选择最大距离最小的两个聚类进行合并。
Ward Linkage(沃德链接法)是一种基于方差的聚类算法,它将数据点间的方差作为合并聚类的依据。它的核心思想是选择合并两个聚类后,使得聚类内部的方差增加最小。















 1374
1374











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









