







第二名方案
解决方案基于修改后的基于retinanet的模型。单模型,集成了4个折叠输出。使用Retinanet,因为与Faster-RCNN之类的模型或SSD相比,它要简单得多,同时具有可比的结果,这使模型的实验和调试/调整变得更加容易。
Retinanet
这里提到了retinanet模型,阅读:https://blog.csdn.net/JNingWei/article/details/80038594
detector主要分为以下两大门派:

类别不平衡:检测算法在早期会生成一大波的bbox。而一幅常规的图片中,顶多就那么几个object。这意味着,绝大多数的bbox属于background。因此就有了类别不平衡。
导致检测精度低的原因:因为bbox数量爆炸。
正是因为bbox中属于background的bbox太多了,所以如果分类器无脑地把所有bbox统一归类为background,accuracy也可以刷得很高。于是乎,分类器的训练就失败了。分类器训练失败,检测精度自然就低了。
对于two-stage系可以避免精度低的原因:因为two-stage系有RPN罩着。
第一个stage的RPN会对anchor进行简单的二分类(只是简单地区分是前景还是背景,并不区别究竟属于哪个细类)。经过该轮初筛,属于background的bbox被大幅砍削。虽然其数量依然远大于前景类bbox,但是至少数量差距已经不像最初生成的anchor那样夸张了。就等于是 从 “类别 极 不平衡” 变成了 “类别 较 不平衡” 。
接着到了第二个stage时,分类器登场,在初筛过后的bbox上进行难度小得多的第二波分类(这次是细分类)。这样一来,分类器得到了较好的训练,最终的检测精度自然就高啦。但是经过这么两个stage一倒腾,操作复杂,检测速度就被严重拖慢了。
one-stage系无法避免该问题原因:
因为one stage系的detector直接在首波生成的“类别极不平衡”的bbox中就进行难度极大的细分类,意图直接输出bbox和标签(分类结果)。而原有交叉熵损失(CE)作为分类任务的损失函数,无法抗衡“类别极不平衡”,容易导致分类器训练失败。因此,one-stage detector虽然保住了检测速度,却丧失了检测精度。
Focal Loss
解决类别不平衡:只要通过将原先训练 分类任务 惯用的 交叉熵误差改为 FL (focal loss) 即可。
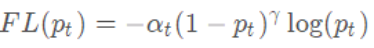
本质是:在原本的 交叉熵误差前面乘上了(1−pt)γ 这一权重。
也就是说,一旦乘上了该权重,量大的类别所贡献的loss被大幅砍削,量少的类别所贡献的loss几乎没有多少降低。虽然整体的loss总量减少了,但是训练过程中量少的类别拥有了更大的话语权,更加被model所关心了。
因此该网络模型诞生了:RetinaNet
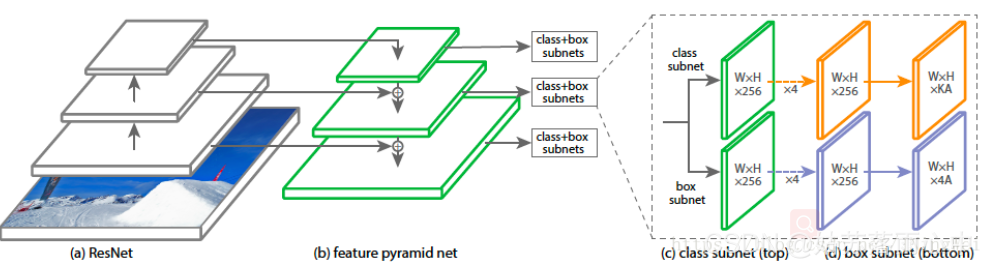
RetinaNet = FPN + sub-network + FL
说明
这里他用到了pyTorch框架
先将原始图像缩放到512x512分辨率,在256分辨率的情况下,结果是下降的,使用全分辨率对于较重的基础模型是不实用的。
然后对原始pytorch-retinanet实现进行了修改:
- 测试了不同的基本模型,se-resnext101效果最好,se-resnext50稍差
- 为较小的锚点(2级金字塔层)添加了额外的输出以处理较小的盒子
- 添加了另一个分类输出,可预测整个图像的类别(“无肺部不透明度/不正常”,“正常”,“肺部不透明度”)。没有使用输出,但是甚至使模型预测其他相关功能也改善了结果。
- 原来的pytorch-retinanet实现忽略了没有框的图像,我对其进行了更改以计算它们的损失。
- 与锚点位置/大小回归输出相比,分类输出过拟合快得多,因此我为锚点和整个图像类输出添加了失活率。除了额外的正则化,它还有助于在同一时期实现最佳的分类和回归结果。
论文
论文地址:https://arxiv.org/abs/2005.13899
在数据集中有三类:
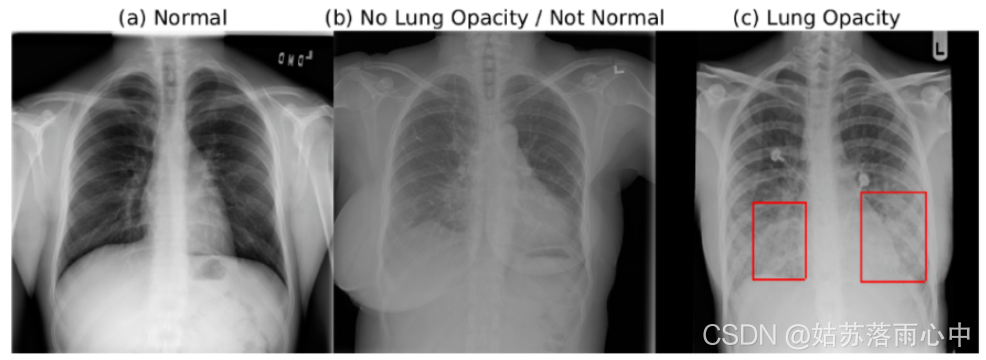
文章提出了一个基于单个模型的解决方案,该模型集成了多个checkpoints。该模型使用了在ImageNet 上经过预训练的SE-ResNext101作为主干网络,整体网络框架使用的是 RetinaNet SSD。
RetinaNet的框架整体是ResNet+FPN+FCN,它使用ResNet作为backbone来提取图像特征,然后从中抽取5层特征层来构建特征金字塔网络(FPN: feature pyramid network),最后接两个独立的**全卷积网络(FCN: full convolution network)**分别得到物体的类别信息和位置框信息。
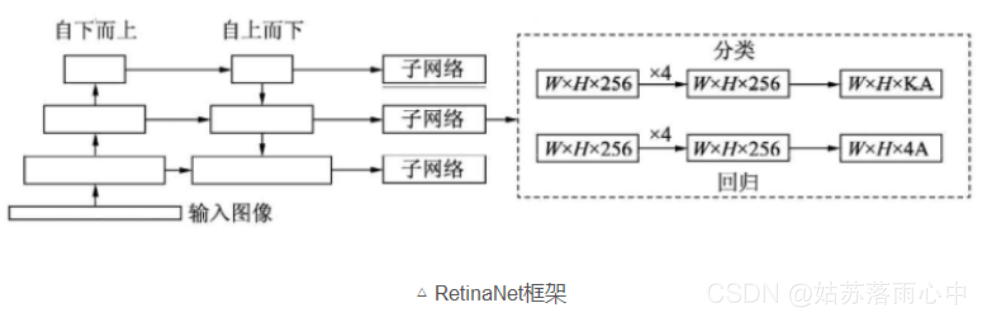
对于RetinaNet的网络结构,有以下5个细节:
- 在Backbone部分,RetinaNet利用ResNet与FPN构建了一个多尺度特征的特征金字塔。
- RetinaNet使用了类似于Anchor的预选框,在每一个金字塔层,使用了9个大小不同的预选框。
- 分类子网络:分类子网络为每一个预选框预测其类别,因此其输出特征大小为KA×W×H, A默认为9, K代表类别数。中间使用全卷积网络与ReLU激活函数,最后利用Sigmoid函数输出预测值。
- 回归子网络:回归子网络与分类子网络平行,预测每一个预选框的偏移量,最终输出特征大小为4A×W×W。与当前主流工作不同的是,两个子网络没有权重的共享。
- Focal Loss:与OHEM等方法不同,Focal Loss在训练时作用到所有的预选框上。对于两个超参数,通常来讲,当γ增大时,α应当适当减小。实验中γ取2、α取0.25时效果最好。
基础模型: 采用retinaNet,并做出了一下改进:
- 带空目标框box的图像被添加到模型中,并有助于损失函数的计算和优化(原始的Pytorch RetinaNet实现忽略了没有目标框box的图像)。
- 对于小的anchors的额外的输出添加到CNN网络中,以便处理较小的目标框
- 使用以下类别之一(“无肺不透明/不正常”,“正常”,“肺不透明”)对全局图像进行分类的额外输出添加到模型中。因此,总损失由该全局分类输出与回归损失和单个框分类损失合并而成。
- 在全局分类输出中添加了dropout ,以减少过度拟合。除了额外的正则化,它还有助于在同一epoch中实现最佳的分类和回归结果。
训练超参数
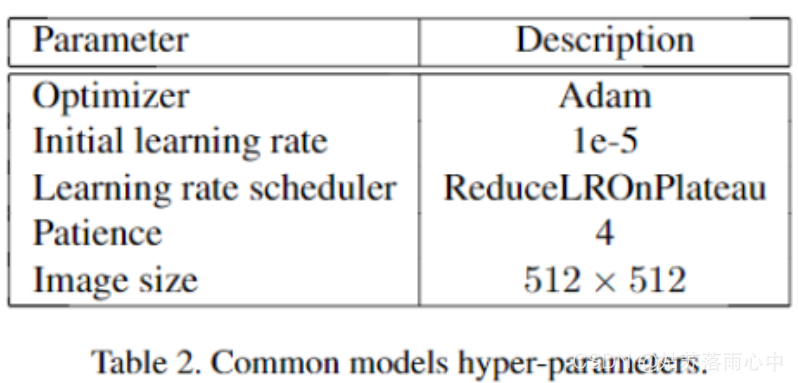
主干网络选取
为了实现合理的快速实验和规范化,同时考虑了在精度与复杂度/参数数量和因此之间取得良好折衷的架构。图中显示了在RetinaNet SSD中使用的各种编码器训练期间的验证损失。SE-ResNext体系结构取得了该数据集的最佳性能,并且在准确性和复杂性之间取得了良好的折衷。

图像数据预处理与图像增强
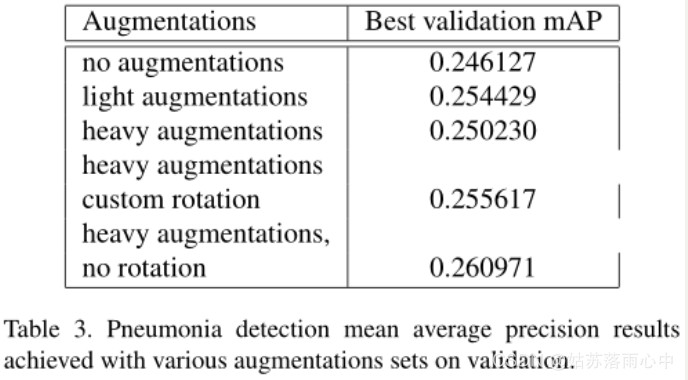
原始图像按比例缩放为512×512像素分辨率,由于原始的挑战数据集不是很大,因此采用了以下图像增强来减少过拟合:轻微旋转(最多6度);移位,缩放,剪切;水平翻转;对于某些图像,模糊处理,添加噪声,进行伽玛值随机变化;有限提高亮度/伽玛增强量等。
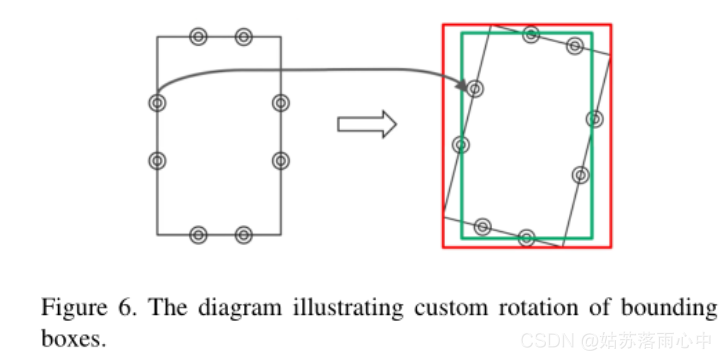
针对训练集和测试集标记方法不同的后处理方法
在训练和测试所提供数据集的标记过程方面有所不同。训练集由唯一的专家标记,而测试台由三名独立的放射线医师标记,他们的标记的交集用于标签真值。这样可以产生较小的标记边界框大小,尤其是在复杂情况下。
可以使用4倍的输出和/或多个检查点的预测来模拟此过程。使用20个百分位数代替锚点大小的平均输出,然后根据单个模型的80个百分位数和20个百分位数之间的差异按比例减少更多(以1.6的比例作为超参数进行了优化)。
由于标记过程不同,训练和测试集的最大抑制(NMS)算法也有所不同。NMS阈值对mAP指标值产生了巨大影响。图8显示了针对不同训练时期和NMS阈值的验证mAP指标变化。验证集的最佳NMS阈值在各个时期之间存在显着差异,取决于模型,其最佳范围在0.45和1之间。
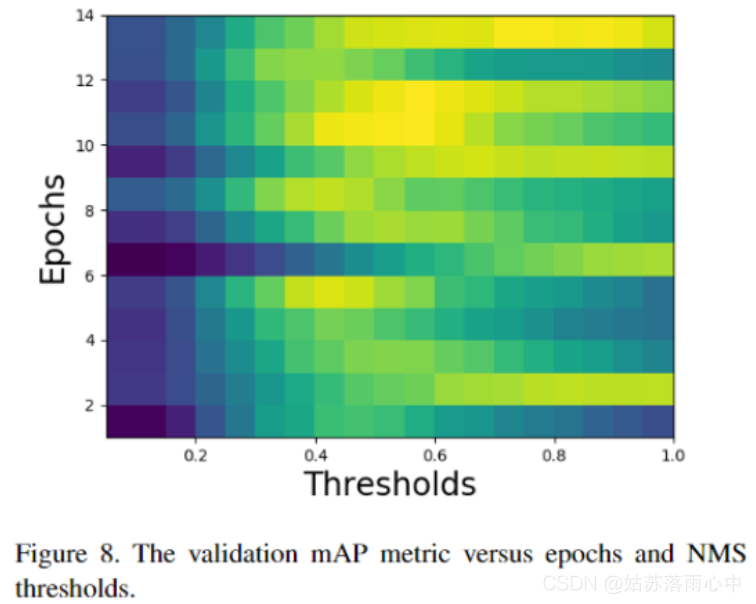
另一种方法是**将测试集的预测的目标框box大小重新缩放为原始大小的87.5%,以反映测试和训练集标签过程之间的差异。**选择87.5%的系数以使尺寸与以前的方法大致匹配。
结果优化
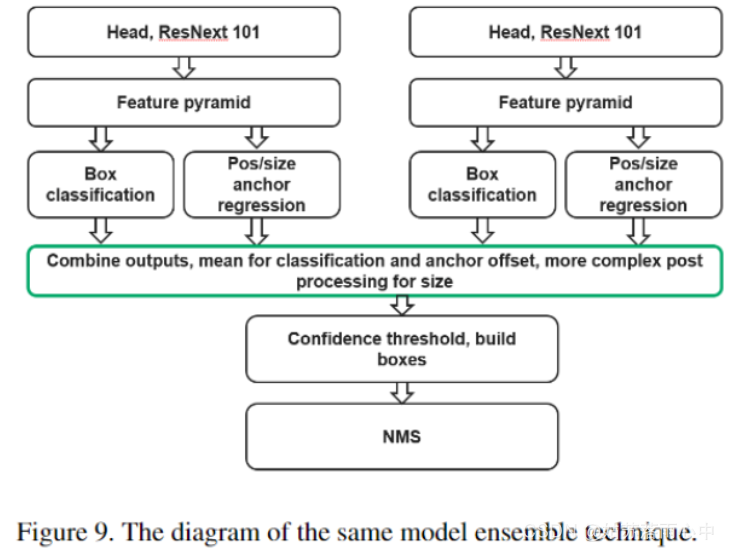
检测模型的结果可能在各个epoch之间发生显着变化,并且很大程度上取决于阈值。在应用NMS算法和优化阈值之前,将相同模型的4折交叉验证的输出合并。

















 1572
1572

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









