







目录
2.4.3 Object Detection,instance Segmentation and Keypoint Detection
5.6.1 torchaduio.compliance.kaldi
0 完整章节内容
1 本章简介
恭喜你,经过前面七章内容的学习,你已经逐步熟悉了PyTorch的使用,能够定义和修改自己的模型,学会了常用的训练技巧,并通过可视化辅助PyTorch的使用。
PyTorch的强大并不仅局限于自身的易用性,更在于开源社区围绕PyTorch所产生的一系列工具包(一般是Python package)和程序,这些优秀的工具包极大地方便了PyTorch在特定领域的使用。比如对于计算机视觉,有TorchVision、TorchVideo等用于图片和视频处理;对于自然语言处理,有torchtext;对于图卷积网络,有PyTorch Geometric ······。这里只是举例,每个领域还有很多优秀的工具包供社区使用。这些工具包共同构成了PyTorch的生态(EcoSystem)。
PyTorch生态很大程度助力了PyTorch的推广与成功。在特定领域使用PyTorch生态中的工具包,能够极大地降低入门门槛,方便复现已有的工作。比如我们在讨论模型修改时候就用到了torchvision中预定义的resnet结构,而不需要自己重新编写。同时,PyTorch生态有助于社区力量的加入,共同为社区提供更有价值的内容和程序,这也是开源理念所坚持的价值。
在后面的内容中,我们会逐步介绍PyTorch生态在图像、视频、文本等领域中的发展,针对某个领域我们选择其中有代表性的一个工具包进行详细介绍,主要包括工具包的作者或其所在机构、数据预处理工具(这块可能再引入第三方工具包)、数据扩增、常用模型结构的预定义、预训练模型权重、常用损失函数、常用评测指标、封装好的训练&测试模块,以及可视化工具。这些内容也是我们在使用对应工具包时会用到的。读者可以根据自身需要重点学习,对于自己研究所不涉及的工具包,可以只做了解,需要使用时再来学习。
2 torchvision

官方文档:torchvision — Torchvision 0.20 documentation
PyTorch之所以会在短短的几年时间里发展成为主流的深度学习框架,除去框架本身的优势,还在于PyTorch有着良好的生态圈。在前面的学习和实战中,我们经常会用到torchvision来调用预训练模型,加载数据集,对图片进行数据增强的操作。在本章我们将给大家简单介绍下torchvision以及相关操作。
值得一提的是,受 Transformer 模型影响,一部分用户转向 Hugging Face 的 Vision Transformer,但传统 CNN 模型仍有广泛应用。
经过本节的学习,你将收获:
-
了解torchvision
-
了解torchvision的作用
2.1 torchvision简介
" The torchvision package consists of popular datasets, model architectures, and common image transformations for computer vision. "
torchvision 是一个与 PyTorch 密切相关的库,用于处理计算机视觉(Computer Vision)任务。它是 PyTorch 官方生态的一部分,提供了便捷的工具和功能,专注于图像处理和视觉任务。
正如引言介绍的一样,我们可以知道torchvision包含了在计算机视觉中常常用到的数据集,模型和图像处理的方式,而具体的torchvision则包括了下面这几部分,带 * 的部分是我们经常会使用到的一些库,所以在下面的部分我们对这些库进行一个简单的介绍:
-
torchvision.datasets *
-
torchvision.models *
-
torchvision.tramsforms *
-
torchvision.io
-
torchvision.ops
-
torchvision.utils
2.2 torchvision.datasets
torchvision.datasets主要包含了一些我们在计算机视觉中常见的数据集,在==0.10.0版本==的torchvision下,有以下的数据集:
| Caltech | CelebA | CIFAR | Cityscapes |
|---|---|---|---|
| EMNIST | FakeData | Fashion-MNIST | Flickr |
| ImageNet | Kinetics-400 | KITTI | KMNIST |
| PhotoTour | Places365 | QMNIST | SBD |
| SEMEION | STL10 | SVHN | UCF101 |
| VOC | WIDERFace |
目前已更新到0.20.0,torchvision.datasets中包含了更多的数据集,适用于多种不同的任务

2.3 torchvision.transforms
我们知道在计算机视觉中处理的数据集有很大一部分是图片类型的,如果获取的数据是格式或者大小不一的图片,则需要进行归一化和大小缩放等操作,这些是常用的数据预处理方法。除此之外,当图片数据有限时,我们还需要通过对现有图片数据进行各种变换,如缩小或放大、水平或垂直翻转等,这些是常见的数据增强方法。而torchvision.transforms中就包含了许多这样的操作。在之前第四章的Fashion-mnist实战中对数据的处理时我们就用到了torchvision.transformer:
from torchvision import transforms
data_transform = transforms.Compose([
transforms.ToPILImage(), # 这一步取决于后续的数据读取方式,如果使用内置数据集则不需要
transforms.Resize(image_size),
transforms.ToTensor()
])除了上面提到的几种数据增强操作,在torchvision官方文档里提到了更多的操作,具体使用方法也可以参考本节配套的”transforms.ipynb“,在这个notebook中我们给出了常见的transforms的API及其使用方法,更多数据变换的操作我们可以点击这里进行查看。
2.4 torchvision.models
为了提高训练效率,减少不必要的重复劳动,PyTorch官方也提供了一些预训练好的模型供我们使用,可以点击这里进行查看现在有哪些预训练模型,下面我们将对如何使用这些模型进行详细介绍。 此处我们以torchvision0.10.0 为例,如果希望获取更多的预训练模型,可以使用使用pretrained-models.pytorch仓库。现有预训练好的模型可以分为以下几类:
2.4.1 Classification
在图像分类里面,PyTorch官方提供了以下模型,并正在不断增多。
| AlexNet | VGG | ResNet | SqueezeNet |
|---|---|---|---|
| DenseNet | Inception v3 | GoogLeNet | ShuffleNet v2 |
| MobileNetV2 | MobileNetV3 | ResNext | Wide ResNet |
| MNASNet | EfficientNet | RegNet | 持续更新 |
这些模型是在ImageNet-1k进行预训练好的,具体的使用我们会在后面进行介绍。除此之外,我们也可以点击这里去查看这些模型在ImageNet-1k的准确率。
2.4.2 Semantic Segmentation
语义分割的预训练模型是在COCO train2017的子集上进行训练的,提供了20个类别,包括background, aeroplane, bicycle, bird, boat, bottle, bus, car, cat, chair, cow, diningtable, dog, horse, motorbike, person, pottedplant, sheep, sofa,train, tvmonitor。
| FCN ResNet50 | FCN ResNet101 | DeepLabV3 ResNet50 | DeepLabV3 ResNet101 |
|---|---|---|---|
| LR-ASPP MobileNetV3-Large | DeepLabV3 MobileNetV3-Large | 未完待续 |
具体我们可以点击这里进行查看预训练的模型的mean IOU和global pixelwise acc
2.4.3 Object Detection,instance Segmentation and Keypoint Detection
物体检测,实例分割和人体关键点检测的模型我们同样是在COCO train2017进行训练的,在下方我们提供了实例分割的类别和人体关键点检测类别:
COCO_INSTANCE_CATEGORY_NAMES = [
'__background__', 'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus','train', 'truck', 'boat', 'traffic light', 'fire hydrant', 'N/A', 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow', 'elephant', 'bear', 'zebra', 'giraffe', 'N/A', 'backpack', 'umbrella', 'N/A', 'N/A','handbag', 'tie', 'suitcase', 'frisbee', 'skis', 'snowboard', 'sports ball','kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard', 'tennis racket','bottle', 'N/A', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl','banana', 'apple', 'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza','donut', 'cake', 'chair', 'couch', 'potted plant', 'bed', 'N/A', 'dining table','N/A', 'N/A', 'toilet', 'N/A', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone','microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'N/A', 'book','clock', 'vase', 'scissors', 'teddy bear', 'hair drier', 'toothbrush']
COCO_PERSON_KEYPOINT_NAMES =['nose','left_eye','right_eye','left_ear','right_ear','left_shoulder','right_shoulder','left_elbow','right_elbow','left_wrist','right_wrist','left_hip','right_hip','left_knee','right_knee','left_ankle','right_ankle']| Faster R-CNN | Mask R-CNN | RetinaNet | SSDlite |
|---|---|---|---|
| SSD | 未完待续 |
同样的,我们可以点击这里查看这些模型在COCO train 2017上的box AP,keypoint AP,mask AP
2.4.4 Video classification
视频分类模型是在 Kinetics-400上进行预训练的
| ResNet 3D 18 | ResNet MC 18 | ResNet (2+1) D |
|---|---|---|
| 未完待续 |
同样我们也可以点击这里查看这些模型的Clip acc@1,Clip acc@5
2.5 torchvision.io
在torchvision.io提供了视频、图片和文件的 IO 操作的功能,它们包括读取、写入、编解码处理操作。随着torchvision的发展,io也增加了更多底层的高效率的API。在使用torchvision.io的过程中,我们需要注意以下几点:
-
不同版本之间,
torchvision.io有着较大变化,因此在使用时,需要查看下我们的torchvision版本是否存在你想使用的方法。 -
除了read_video()等方法,torchvision.io为我们提供了一个细粒度的视频API torchvision.io.VideoReader() ,它具有更高的效率并且更加接近底层处理。在使用时,我们需要先安装ffmpeg然后从源码重新编译torchvision,我们才能使用这些方法。
-
在使用Video相关API时,我们最好提前安装好PyAV这个库。
2.6 torchvision.ops
torchvision.ops 为我们提供了许多计算机视觉的特定操作,包括但不仅限于NMS,RoIAlign(MASK R-CNN中应用的一种方法),RoIPool(Fast R-CNN中用到的一种方法)。在合适的时间使用可以大大降低我们的工作量,避免重复的造轮子,想看更多的函数介绍可以点击这里进行细致查看。
2.7 torchvision.utils
torchvision.utils 为我们提供了一些可视化的方法,可以帮助我们将若干张图片拼接在一起、可视化检测和分割的效果。具体方法可以点击这里进行查看。
总的来说,torchvision的出现帮助我们解决了常见的计算机视觉中一些重复且耗时的工作,并在数据集的获取、数据增强、模型预训练等方面大大降低了我们的工作难度,可以让我们更加快速上手一些计算机视觉任务。
3 PyTorchVideo简介

官方文档:PyTorchVideo Documentation — PyTorchVideo documentation
近几年来,随着传播媒介和视频平台的发展,视频正在取代图片成为下一代的主流媒体,这也使得有关视频的深度学习模型正在获得越来越多的关注。然而,有关视频的深度学习模型仍然有着许多缺点:
-
计算资源耗费更多,并且没有高质量的
model zoo,不能像图片一样进行迁移学习和论文复现。 -
数据集处理较麻烦,但没有一个很好的视频处理工具。
-
随着多模态越来越流行,亟需一个工具来处理其他模态。
除此之外,还有部署优化等问题,为了解决这些问题,Meta推出了PyTorchVideo深度学习库(包含组件如Figure 1所示)。PyTorchVideo 是一个专注于视频理解工作的深度学习库。PytorchVideo 提供了加速视频理解研究所需的可重用、模块化和高效的组件。PyTorchVideo 是使用PyTorch开发的,支持不同的深度学习视频组件,如视频模型、视频数据集和视频特定转换。

值得一提的是,Hugging Face 的多模态模型(如 CLIP、FLAVA)开始涉足视频任务,但生态尚未成熟,Pytorchvideo 仍是主力库。
3.1 PyTorchVideo的主要部件和亮点
PytorchVideo 提供了加速视频理解研究所需的模块化和高效的API。它还支持不同的深度学习视频组件,如视频模型、视频数据集和视频特定转换,最重要的是,PytorchVideo也提供了model zoo,使得人们可以使用各种先进的预训练视频模型及其评判基准。PyTorchVideo主要亮点如下:
-
基于 PyTorch:使用 PyTorch 构建。使所有 PyTorch 生态系统组件的使用变得容易。
-
Model Zoo:PyTorchVideo提供了包含I3D、R(2+1)D、SlowFast、X3D、MViT等SOTA模型的高质量model zoo(目前还在快速扩充中,未来会有更多SOTA model),并且PyTorchVideo的model zoo调用与PyTorch Hub做了整合,大大简化模型调用,具体的一些调用方法可以参考下面的【使用 PyTorchVideo model zoo】部分。
-
数据预处理和常见数据,PyTorchVideo支持Kinetics-400, Something-Something V2, Charades, Ava (v2.2), Epic Kitchen, HMDB51, UCF101, Domsev等主流数据集和相应的数据预处理,同时还支持randaug, augmix等数据增强trick。
-
模块化设计:PyTorchVideo的设计类似于torchvision,也是提供许多模块方便用户调用修改,在PyTorchVideo中具体来说包括data, transforms, layer, model, accelerator等模块,方便用户进行调用和读取。
-
支持多模态:PyTorchVideo现在对多模态的支持包括了visual和audio,未来会支持更多模态,为多模态模型的发展提供支持。
-
移动端部署优化:PyTorchVideo支持针对移动端模型的部署优化(使用前述的PyTorchVideo/accelerator模块),模型经过PyTorchVideo优化了最高达7倍的提速,并实现了第一个能实时跑在手机端的X3D模型(实验中可以实时跑在2018年的三星Galaxy S8上,具体请见Android Demo APP)。
3.2 PyTorchVideo的安装
我们可以直接使用pip来安装PyTorchVideo:
pip install pytorchvideo注:
-
安装的虚拟环境的python版本 >= 3.7
-
PyTorch >= 1.8.0,安装的torchvision也需要匹配
-
CUDA >= 10.2
-
ioPath:具体情况
-
fvcore版本 >= 0.1.4:具体情况
3.3 Model zoo 和 benchmark
在下面这部分,我将简单介绍些PyTorchVideo所提供的Model zoo和benchmark
3.3.1 Kinetics-400
Kinetics-400 是一个著名的大规模视频动作识别数据集,广泛应用于计算机视觉领域的视频理解任务,尤其是动作分类和检测任务。它由 DeepMind 团队发布,旨在推动基于深度学习的视频动作识别研究。包含 400 种人类动作类别,例如跑步、跳舞、做饭、打篮球等。动作类别覆盖了日常生活、运动、社交活动等多个领域。视频来源为从 YouTube 收集而来。
| arch | depth | pretrain | frame length x sample rate | top 1 | top 5 | Flops (G) x views | Params (M) | Model |
|---|---|---|---|---|---|---|---|---|
| C2D | R50 | - | 8x8 | 71.46 | 89.68 | 25.89 x 3 x 10 | 24.33 | link |
| I3D | R50 | - | 8x8 | 73.27 | 90.70 | 37.53 x 3 x 10 | 28.04 | link |
| Slow | R50 | - | 4x16 | 72.40 | 90.18 | 27.55 x 3 x 10 | 32.45 | link |
| Slow | R50 | - | 8x8 | 74.58 | 91.63 | 54.52 x 3 x 10 | 32.45 | link |
| SlowFast | R50 | - | 4x16 | 75.34 | 91.89 | 36.69 x 3 x 10 | 34.48 | link |
| SlowFast | R50 | - | 8x8 | 76.94 | 92.69 | 65.71 x 3 x 10 | 34.57 | link |
| SlowFast | R101 | - | 8x8 | 77.90 | 93.27 | 127.20 x 3 x 10 | 62.83 | link |
| SlowFast | R101 | - | 16x8 | 78.70 | 93.61 | 215.61 x 3 x 10 | 53.77 | link |
| CSN | R101 | - | 32x2 | 77.00 | 92.90 | 75.62 x 3 x 10 | 22.21 | link |
| R(2+1)D | R50 | - | 16x4 | 76.01 | 92.23 | 76.45 x 3 x 10 | 28.11 | link |
| X3D | XS | - | 4x12 | 69.12 | 88.63 | 0.91 x 3 x 10 | 3.79 | link |
| X3D | S | - | 13x6 | 73.33 | 91.27 | 2.96 x 3 x 10 | 3.79 | link |
| X3D | M | - | 16x5 | 75.94 | 92.72 | 6.72 x 3 x 10 | 3.79 | link |
| X3D | L | - | 16x5 | 77.44 | 93.31 | 26.64 x 3 x 10 | 6.15 | link |
| MViT | B | - | 16x4 | 78.85 | 93.85 | 70.80 x 1 x 5 | 36.61 | link |
| MViT | B | - | 32x3 | 80.30 | 94.69 | 170.37 x 1 x 5 | 36.61 | link |
3.3.2 Something-Something V2
Something-Something V2 是一个广泛用于视频动作识别和理解的高级数据集,由 TwentyBN 公司发布。与 Kinetics 等数据集不同,它专注于捕捉 对象交互的短时动作,并强调动作与上下文的细粒度关系,是一个更具挑战性和灵活性的资源。包含 174 种动作类别,动作描述通常以自然语言形式表示。
| arch | depth | pretrain | frame length x sample rate | top 1 | top 5 | Flops (G) x views | Params (M) | Model |
|---|---|---|---|---|---|---|---|---|
| Slow | R50 | Kinetics 400 | 8x8 | 60.04 | 85.19 | 55.10 x 3 x 1 | 31.96 | link |
| SlowFast | R50 | Kinetics 400 | 8x8 | 61.68 | 86.92 | 66.60 x 3 x 1 | 34.04 | link |
3.3.3 Charades
Charades 是一个广泛应用于 视频动作识别 和 活动理解 任务的数据集,由阿伦·弗南德兹(Allan Jabri)等人发布,主要关注家庭环境中的多模态活动。它为研究视频中 长时间活动的动态性和复杂性 提供了独特的挑战。包括:看书、开门、吃饭、穿衣等。包含 157 种类别,覆盖丰富的日常活动。
| arch | depth | pretrain | frame length x sample rate | MAP | Flops (G) x views | Params (M) | Model |
|---|---|---|---|---|---|---|---|
| Slow | R50 | Kinetics 400 | 8x8 | 34.72 | 55.10 x 3 x 10 | 31.96 | link |
| SlowFast | R50 | Kinetics 400 | 8x8 | 37.24 | 66.60 x 3 x 10 | 34.00 | link |
3.3.4 AVA (V2.2)
AVA (Atomic Visual Actions) 数据集 V2.2 是一个专注于 视频动作检测 和 时空动作理解 的高质量数据集,由 Google Research 团队发布。它旨在推动计算机视觉领域 时间和空间的联合建模,特别是在复杂视频场景中的细粒度动作识别。每个动作在视频中的空间(bounding box)和时间(帧)维度均有标注。
| arch | depth | pretrain | frame length x sample rate | MAP | Params (M) | Model |
|---|---|---|---|---|---|---|
| Slow | R50 | Kinetics 400 | 4x16 | 19.5 | 31.78 | link |
| SlowFast | R50 | Kinetics 400 | 8x8 | 24.67 | 33.82 | link |
3.4 使用 PyTorchVideo model zoo
PyTorchVideo提供了三种使用方法,并且给每一种都配备了tutorial
-
TorchHub,这些模型都已经在TorchHub存在。我们可以根据实际情况来选择需不需要使用预训练模型。除此之外,官方也给出了TorchHub使用的 tutorial 。
-
PySlowFast,使用 PySlowFast workflow 去训练或测试PyTorchVideo models/datasets.
-
PyTorch Lightning建立一个工作流进行处理,点击查看官方 tutorial。
-
如果想查看更多的使用教程,可以点击 这里 进行尝试
总的来说,PyTorchVideo的使用与torchvision的使用方法类似,在有了前面的学习基础上,我们可以很快上手PyTorchVideo,具体的我们可以通过查看官方提供的文档和一些例程来了解使用方法:官方网址
4 torchtext简介
据悉,TorchText在于2024年4月发布其最终稳定版0.18后将停止维护和更新,个人感觉是传统NLP已经走到尽头了,目前主流NLP用的都是transformers这个更强大的库。所以如果你基本用不到传统NLP任务的话,这块了解即可。
当然如果你对transformers如何使用感兴趣,我之前也做过这方面的笔记,比较详细,参见:
手把手带你实战Transformers(学习笔记)_transformers学习笔记-CSDN博客

官方文档:torchtext — Torchtext 0.18.0 documentation
本节我们来介绍PyTorch官方用于自然语言处理(NLP)的工具包torchtext。自然语言处理也是深度学习的一大应用场景,近年来随着大规模预训练模型的应用,深度学习在人机对话、机器翻译等领域的取得了非常好的效果,也使得NLP相关的深度学习模型获得了越来越多的关注。
由于NLP和CV在数据预处理中的不同,因此NLP的工具包torchtext和torchvision等CV相关工具包也有一些功能上的差异,如:
-
数据集(dataset)定义方式不同
-
数据预处理工具
-
没有琳琅满目的model zoo
本节介绍参考了atnlp的Github,在此致谢!
4.1 torchtext的主要组成部分
torchtext可以方便的对文本进行预处理,例如截断补长、构建词表等。torchtext主要包含了以下的主要组成部分:
-
数据处理工具 torchtext.data.functional、torchtext.data.utils
-
数据集 torchtext.data.datasets
-
词表工具 torchtext.vocab
-
评测指标 torchtext.metrics
4.2 torchtext的安装
torchtext可以直接使用pip进行安装:
pip install torchtext4.3 构建数据集
4.3.1 Field及其使用
Field是torchtext中定义数据类型以及转换为张量的指令。torchtext 认为一个样本是由多个字段(文本字段,标签字段)组成,不同的字段可能会有不同的处理方式,所以才会有 Field 抽象。定义Field对象是为了明确如何处理不同类型的数据,但具体的处理则是在Dataset中完成的。下面我们通过一个例子来简要说明一下Field的使用:
tokenize = lambda x: x.split()
TEXT = data.Field(sequential=True, tokenize=tokenize, lower=True, fix_length=200)
LABEL = data.Field(sequential=False, use_vocab=False)其中:
sequential设置数据是否是顺序表示的;
tokenize用于设置将字符串标记为顺序实例的函数
lower设置是否将字符串全部转为小写;
fix_length设置此字段所有实例都将填充到一个固定的长度,方便后续处理;
use_vocab设置是否引入Vocab object,如果为False,则需要保证之后输入field中的data都是numerical的
构建Field完成后就可以进一步构建dataset了:
from torchtext import data
def get_dataset(csv_data, text_field, label_field, test=False):
fields = [("id", None), # we won't be needing the id, so we pass in None as the field
("comment_text", text_field), ("toxic", label_field)]
examples = []
if test:
# 如果为测试集,则不加载label
for text in tqdm(csv_data['comment_text']):
examples.append(data.Example.fromlist([None, text, None], fields))
else:
for text, label in tqdm(zip(csv_data['comment_text'], csv_data['toxic'])):
examples.append(data.Example.fromlist([None, text, label], fields))
return examples, fields这里使用数据csv_data中有"comment_text"和"toxic"两列,分别对应text和label。
train_data = pd.read_csv('train_toxic_comments.csv')
valid_data = pd.read_csv('valid_toxic_comments.csv')
test_data = pd.read_csv("test_toxic_comments.csv")
TEXT = data.Field(sequential=True, tokenize=tokenize, lower=True)
LABEL = data.Field(sequential=False, use_vocab=False)
# 得到构建Dataset所需的examples和fields
train_examples, train_fields = get_dataset(train_data, TEXT, LABEL)
valid_examples, valid_fields = get_dataset(valid_data, TEXT, LABEL)
test_examples, test_fields = get_dataset(test_data, TEXT, None, test=True)
# 构建Dataset数据集
train = data.Dataset(train_examples, train_fields)
valid = data.Dataset(valid_examples, valid_fields)
test = data.Dataset(test_examples, test_fields)可以看到,定义Field对象完成后,通过get_dataset函数可以读入数据的文本和标签,将二者(examples)连同field一起送到torchtext.data.Dataset类中,即可完成数据集的构建。使用以下命令可以看下读入的数据情况:
# 检查keys是否正确
print(train[0].__dict__.keys())
print(test[0].__dict__.keys())
# 抽查内容是否正确
print(train[0].comment_text)4.3.2 词汇表(vocab)
在NLP中,将字符串形式的词语(word)转变为数字形式的向量表示(embedding)是非常重要的一步,被称为Word Embedding。这一步的基本思想是收集一个比较大的语料库(尽量与所做的任务相关),在语料库中使用word2vec之类的方法构建词语到向量(或数字)的映射关系,之后将这一映射关系应用于当前的任务,将句子中的词语转为向量表示。
在torchtext中可以使用Field自带的build_vocab函数完成词汇表构建。
TEXT.build_vocab(train)4.3.3 数据迭代器
其实就是torchtext中的DataLoader,看下代码就明白了:
from torchtext.data import Iterator, BucketIterator
# 若只针对训练集构造迭代器
# train_iter = data.BucketIterator(dataset=train, batch_size=8, shuffle=True, sort_within_batch=False, repeat=False)
# 同时对训练集和验证集进行迭代器的构建
train_iter, val_iter = BucketIterator.splits(
(train, valid), # 构建数据集所需的数据集
batch_sizes=(8, 8),
device=-1, # 如果使用gpu,此处将-1更换为GPU的编号
sort_key=lambda x: len(x.comment_text), # the BucketIterator needs to be told what function it should use to group the data.
sort_within_batch=False
)
test_iter = Iterator(test, batch_size=8, device=-1, sort=False, sort_within_batch=False)torchtext支持只对一个dataset和同时对多个dataset构建数据迭代器。
4.3.4 使用自带数据集
与torchvision类似,torchtext也提供若干常用的数据集方便快速进行算法测试。可以查看官方文档寻找想要使用的数据集。
4.4 评测指标(metric)
NLP中部分任务的评测不是通过准确率等指标完成的,比如机器翻译任务常用BLEU (bilingual evaluation understudy) score来评价预测文本和标签文本之间的相似程度。torchtext中可以直接调用torchtext.data.metrics.bleu_score来快速实现BLEU,下面是一个官方文档中的一个例子:
from torchtext.data.metrics import bleu_score
candidate_corpus = [['My', 'full', 'pytorch', 'test'], ['Another', 'Sentence']]
references_corpus = [[['My', 'full', 'pytorch', 'test'], ['Completely', 'Different']], [['No', 'Match']]]
bleu_score(candidate_corpus, references_corpus)0.8408964276313782
4.5 其他
值得注意的是,由于NLP常用的网络结构比较固定,torchtext并不像torchvision那样提供一系列常用的网络结构。模型主要通过torch.nn中的模块来实现,比如torch.nn.LSTM、torch.nn.RNN等。
备注:
对于文本研究而言,当下Transformer已经成为了绝对的主流,因此PyTorch生态中的HuggingFace等工具包也受到了越来越广泛的关注。这里强烈建议读者自行探索相关内容,可以写下自己对于HuggingFace的笔记,如果总结全面的话欢迎pull request,充实我们的课程内容。
4.6 本节参考
5 torchaudio简介

官方文档:Torchaudio Documentation — Torchaudio 2.5.0 documentation
本节我们来介绍PyTorch官方用于语音处理的工具包torchaduio。语音的处理也是深度学习的一大应用场景,包括说话人识别(Speaker Identification),说话人分离(Speaker Diarization),音素识别(Phoneme Recognition),语音识别(Automatic Speech Recognition),语音分离(Speech Separation),文本转语音(TTS)等任务。
CV有torchvision,NLP有torchtext,人们希望语音领域中也能有一个工具包。而语音的处理工具包就是torchaudio。由于语音任务本身的特性,导致其与NLP和CV在数据处理、模型构建、模型验证有许多不同,因此语音的工具包torchaudio和torchvision等CV相关工具包也有一些功能上的差异。
通过本章的学习,你将收获:
-
语音数据的I/O
-
语音数据的预处理
-
语音领域的数据集
-
语音领域的模型
值得一提的是,语音任务逐渐被 Transformer 模型主导(如 Wav2Vec, Whisper)。Hugging Face 的 transformers 已支持主流语音模型,但 Torchaudio 在底层处理和优化上更强,仍被广泛使用。
5.1 torchaduio的主要组成部分
torchaduio主要包括以下几个部分:
-
torchaudio.io:有关音频的I/O
-
torchaudio.backend:提供了音频处理的后端,包括:sox,soundfile等
-
torchaudio.functional:包含了常用的语音数据处理方法,如:spectrogram,create_fb_matrix等
-
torchaudio.transforms:包含了常用的语音数据预处理方法,如:MFCC,MelScale,AmplitudeToDB等
-
torchaudio.datasets:包含了常用的语音数据集,如:VCTK,LibriSpeech,yesno等
-
torchaudio.models:包含了常用的语音模型,如:Wav2Letter,DeepSpeech等
-
torchaudio.models.decoder:包含了常用的语音解码器,如:GreedyDecoder,BeamSearchDecoder等
-
torchaudio.pipelines:包含了常用的语音处理流水线,如:SpeechRecognitionPipeline,SpeakerRecognitionPipeline等
-
torchaudio.sox_effects:包含了常用的语音处理方法,如:apply_effects_tensor,apply_effects_file等
-
torchaudio.compliance.kaldi:包含了与Kaldi工具兼容的方法,如:load_kaldi_fst,load_kaldi_ark等
-
torchaudio.kalid_io:包含了与Kaldi工具兼容的方法,如:read_vec_flt_scp,read_vec_int_scp等
-
torchaudio.utils:包含了常用的语音工具方法,如:get_audio_backend,set_audio_backend等
5.2 torchaduio的安装
一般在安装torch的同时,也会安装torchaudio。假如我们的环境中没有torchaudio,我们可以使用pip或者conda去安装它。只需要执行以下命令即可:
pip install torchaudio # conda install torchaudio在安装的时候,我们一定要根据自己的PyTorch版本和Python版本选择对应的torchaudio的版本,具体我们可以查看torchaudio Compatibility Matrix
5.3 datasets的构建
torchaudio中对于一些公共数据集,我们可以主要通过torchaudio.datasets来实现。对于私有数据集,我们也可以通过继承torch.utils.data.Dataset来构建自己的数据集。数据集的读取和处理,我们可以通过torch.utils.data.DataLoader来实现。
import torchaudio
import torch
# 公共数据集的构建
yesno_data = torchaudio.datasets.YESNO('.', download=True)
data_loader = torch.utils.data.DataLoader(
yesno_data,
batch_size=1,
shuffle=True,
num_workers=4)torchaudio提供了许多常用的语音数据集,包括CMUARCTIC,CMUDict,COMMONVOICE,DR_VCTK,FluentSpeechCommands,GTZAN,IEMOCAP,LIBRISPEECH,LIBRITTS,LJSPEECH,LibriLightLimited,LibriMix,MUSDB_HQ,QUESST14,SPEECHCOMMANDS,Snips,TEDLIUM,VCTK_092,VoxCeleb1Identification,VoxCeleb1Verification,YESNO等。具体的我们可以通过以下命令来查看:
import torchaudio
dir(torchaudio.datasets)'CMUARCTIC','CMUDict','COMMONVOICE','DR_VCTK','FluentSpeechCommands',
'GTZAN','IEMOCAP','LIBRISPEECH','LIBRITTS','LJSPEECH','LibriLightLimited',
'LibriMix','MUSDB_HQ','QUESST14','SPEECHCOMMANDS','Snips','TEDLIUM',
'VCTK_092','VoxCeleb1Identification','VoxCeleb1Verification','YESNO']
5.4 model和pipeline的构建
torchaudio.models包含了常见语音任务的模型的定义,包括:Wav2Letter,DeepSpeech,HuBERTPretrainModel等。torchaudio.pipelines则是将预训练模型和其对应的任务组合在一起,构成了一个完整的语音处理流水线。torchaudio.pipeline相较于torchvision这种视觉库而言,是torchaudio的精华部分。我们在此也不进行过多的阐述,对于进一步的学习,我们可以参考官方给出的Pipeline Tutorials和torchaudio.pipelines docs。
5.5 transforms和functional的使用
torchaudio.transforms模块包含常见的音频处理和特征提取。torchaudio.functional则包括了一些常见的音频操作的函数。关于torchaudio.transforms,官方提供了一个流程图供我们参考学习:
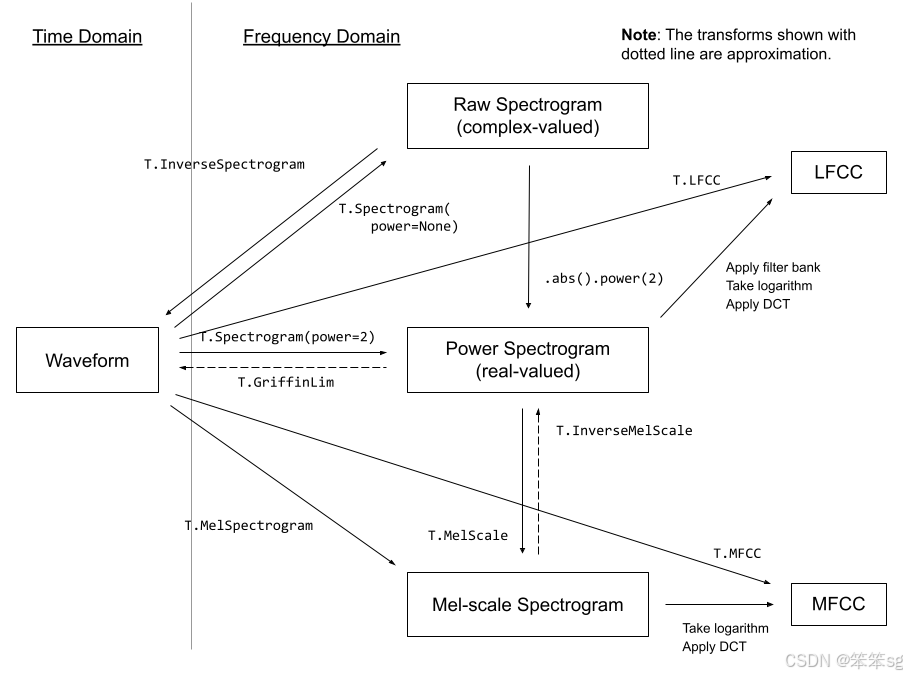
torchaudio.transforms继承于torch.nn.Module,但是不同于torchvision.transforms,torchaudio没有compose方法将多个transform组合起来。因此torchaudio构建transform pipeline的常见方法是自定义模块类或使用torch.nn.Sequential将他们在一起。然后将其移动到目标设备和数据类型。我们可以参考官方所给出的例子:
# Define custom feature extraction pipeline.
#
# 1. Resample audio
# 2. Convert to power spectrogram
# 3. Apply augmentations
# 4. Convert to mel-scale
#
class MyPipeline(torch.nn.Module):
def __init__(
self,
input_freq=16000,
resample_freq=8000,
n_fft=1024,
n_mel=256,
stretch_factor=0.8,
):
super().__init__()
self.resample = Resample(orig_freq=input_freq, new_freq=resample_freq)
self.spec = Spectrogram(n_fft=n_fft, power=2)
self.spec_aug = torch.nn.Sequential(
TimeStretch(stretch_factor, fixed_rate=True),
FrequencyMasking(freq_mask_param=80),
TimeMasking(time_mask_param=80),
)
self.mel_scale = MelScale(
n_mels=n_mel, sample_rate=resample_freq, n_stft=n_fft // 2 + 1)
def forward(self, waveform: torch.Tensor) -> torch.Tensor:
# Resample the input
resampled = self.resample(waveform)
# Convert to power spectrogram
spec = self.spec(resampled)
# Apply SpecAugment
spec = self.spec_aug(spec)
# Convert to mel-scale
mel = self.mel_scale(spec)
return meltorchaudio.transforms的使用,我们可以参考torchaudio.transforms进一步了解。
torchaudio.functional支持了许多语音的处理方法,关于torchaudio.functional的使用,我们可以参考torchaudio.functional进一步了解。
5.6 compliance和kaldi_io的使用
Kaldi是一个用于语音识别研究的工具箱,由CMU开发,开源免费。它包含了构建语音识别系统所需的全部组件,是语音识别领域最流行和影响力最大的开源工具之一。torchaudio中提供了一些与Kaldi工具兼容的方法,这些方法分别属于torchaduio.compliance.kaldi,torchaduio.kaldi_io。
5.6.1 torchaduio.compliance.kaldi
在torchaudio.compliance.kaldi中,torchaudio提供了以下三种方法:
-
torchaudio.compliance.kaldi.spectrogram:从语音信号中提取Spectrogram特征
-
torchaudio.compliance.kaldi.fbank:从语音信号中提取FBank特征
-
torchaduio.compliance.kaldi.mfcc:从语音信号中提取MFCC特征
5.6.2 torchaduio.kaldi_io
torchaudio.kaldi_io是一个torchaudio的子模块,用于读取和写入Kaldi的数据集格式。当我们要使用torchaudio.kaldi_io时,我们需要先确保kalid_io已经安装。
具体来说,主要接口包括:
-
torchaudio.kaldi_io.read_vec_int_ark:从Kaldi的scp文件中读取float类型的数据
-
torchaudio.kaldi_io.read_vec_flt_scp
-
torchaudio.kaldi_io.read_vec_flt_ark
-
torchaudio.kaldi_io.read_mat_scp
-
torchaudio.kaldi_io.read_mat_ark
具体的使用方法,我们可以参考torchaudio.kaldi_io进一步了解。
5.6 总结
本节我们主要介绍了torchaudio的基本使用方法和常用的模块,如果想要进一步学习,可以参考torchaudio官方文档。


















 693
693

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









