







总结
01

BLIP2
论文地址:https://arxiv.org/pdf/2301.12597
发布时间:2023.06.15
模型结构:
-
Vision Encoder:ViT-L/14
-
VL Adapter:Q-Former
-
LLM:OPT (decoder-based),FlanT5(encoder-decoder-based)
Overview of BLIP-2's framework
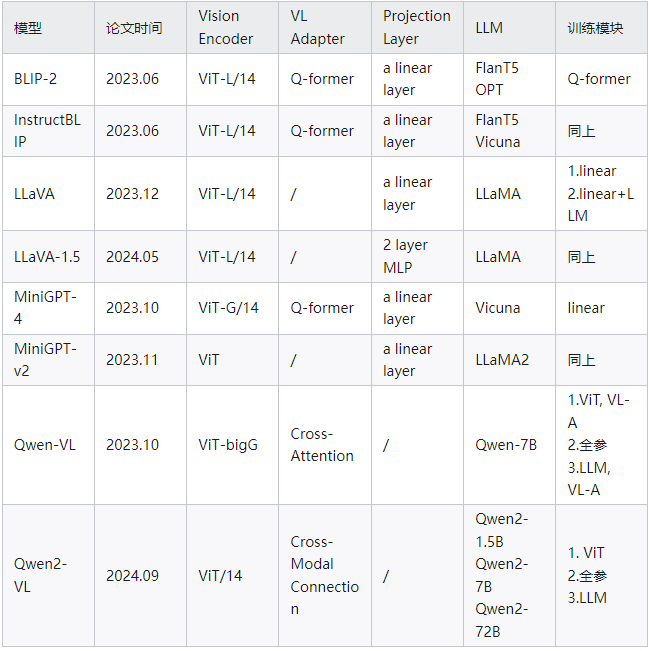
论文主要提出Q-Former(Lightweight Querying Transformer)用于连接模态之间的gap。BLIP-2整体架构包括三个模块:视觉编码器、视觉和LLM的Adapter(Q-Former)、LLM。其中Q-Former是BLIP-2模型训练过程中主要更新的参数,视觉Encoder和大语言模型LLM在训练过程中冻结参数。
BLIP-2的预训练包括两个阶段:
Stage 1)Vision-and-Language Representation Learning. Q-Former与冻结的Image Encoder(ViT-L/14)连接,在和文本交互中学习图文相关性表示(3个预训练任务)。
Stage 2)Vision-to-Language Generative Learning. 第一个阶段训练得到的Q-Former的输出接入一个大语言模型,学习视觉到文本生成(1个预训练任务)。
下面分别介绍两个阶段:
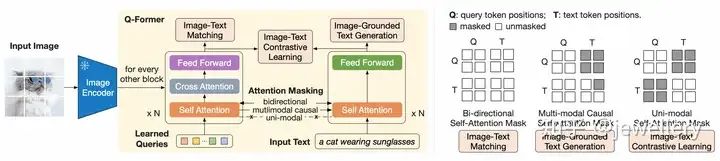
阶段1:左侧为Q-Former的结构以及如何学习视觉文本表征,右侧self-attention masking策略
阶段1:Q-Former的结构如上图所示,包括两个Transformer子模块(共享Self-Attention层),一个image transformer与image encoder交互提取视觉表征(图中黄色区域左侧),一个text transformer既作为text encoder也作为text decoder(图中黄色区域右侧)。首先创建一个可学习的query向量(Learnable query embeddings)作为image transformer的输入,queries通过self-attention层进行自我交互,然后与冻结参数的image features(来自image encoder)通过cross-attention层(插入每隔一个block)进行交互,此外这个query向量还与text通过同一个self-attention进行交互。在不同的预训练任务中,使用不同的self-attention masks来影响查询文本的交互,在这个阶段的预训练中,一共通过三个任务进行学习(类似BLIP),分别为:
ITM:图文匹配任务,使用双向self-attention mask, 不进行掩码,该任务目标是学习细粒度的图文表示对齐。训练过程中queries和text可以完全互相看到,query embeddings的输出Z包含了多模态的信息,将它输入一个2分类linear层得到一个logit,平均来自所有queries的logits作为最终的匹配分数,论文采纳了难负样例挖掘的策略创建更具信息量的负样本对。
ITG:图引导文本生成,使用causal self
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3261
3261

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









