






醋酸等生活中常见的羧酸由于具有酸味,因此命名为“酸”。羧酸与醇反应可生成羧酸酯,酯是脂肪的主要官能团,因此将该类物质命名为“酯”。羧酸与羧酸酯的主要官能团较相似,两者可相互转化。羧酸最为重要的反应为酯化反应,其酸性也是重要的性质。羧酸除了酯化反应,其他主要发生的反应有还原反应、脱水等。
羧酸能通过醛的氧化反应制取,因此羧酸在专门的还原剂或一定条件下能被还原为醛,甚至直接还原为醇。
羧酸的活性相比羧酸酯来说会差很多,是一种较难还原的物质。羧酸很难被H2直接还原为醛,通常需使用LAIH4、BH3,等含有较多显负化合价的H 原子的还原剂。
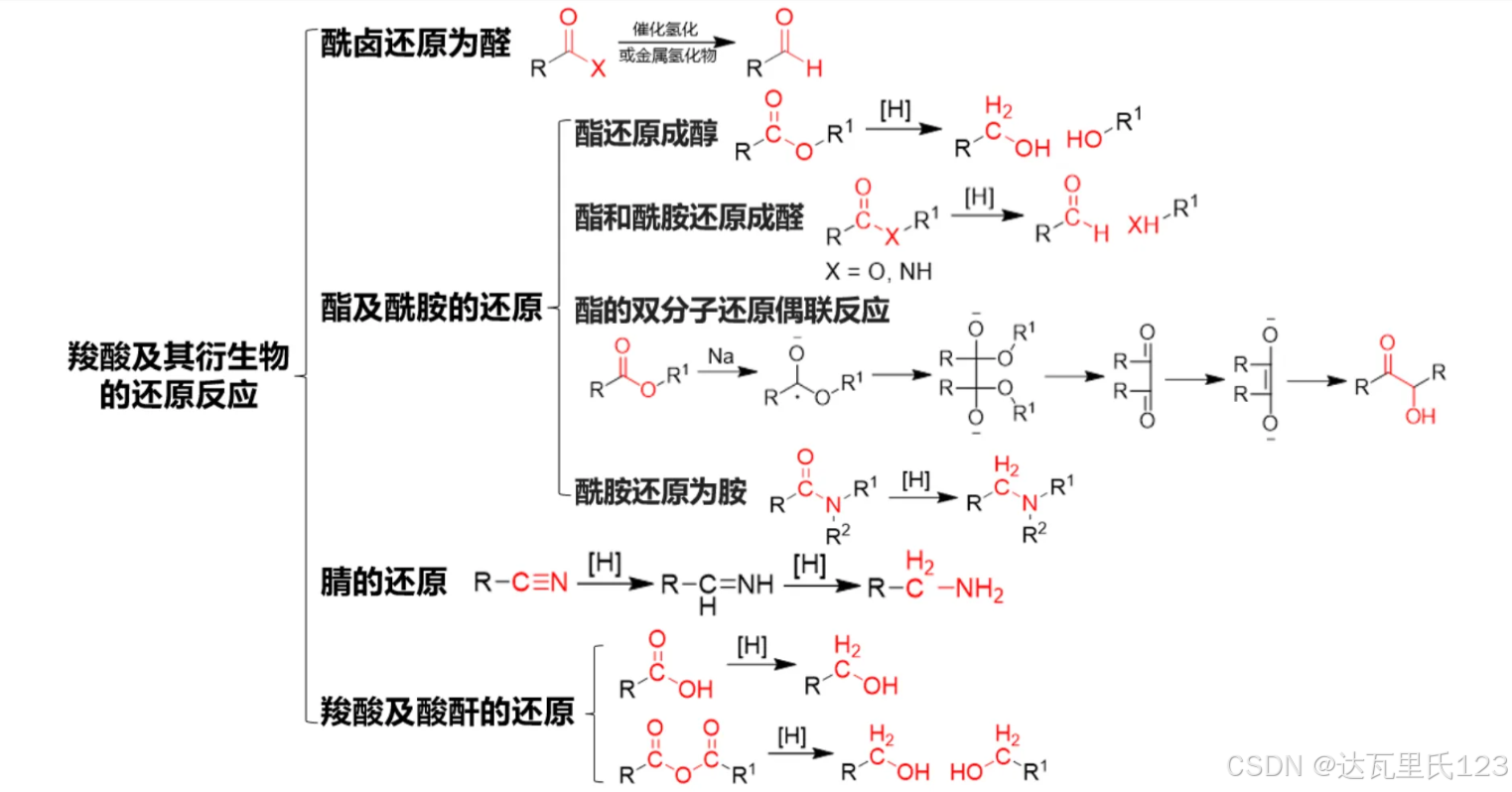
图1.羧酸以及衍生物还原反应总览
一、通过氢化铝锂还原羧酸得到醇
具体过程是第一步是将羧酸还原为醛。首先羧酸转变成羧酸锂盐,然后氢化铝与羧酸锂盐接近,与羰基氧形成配合物,再将负氢从铝转移到羰基碳上,接着消除LiOAlH2形成醛。第二步,生成的醛与第二分子氢化铝锂反应,然后用稀酸水解得到一级醇。氢化铝锂还原羧酸比较彻底,用量加足基本不会停止在醛的阶段。即使位阻较大的酸,也有较好的收率。
值得注意的是,氢化铝锂还原羧酸时,通常使用无水乙醚或四氢呋喃作为溶剂。反应过程中,虽然经过醛的中间阶段,但由于醛比酸更易被还原,所以无法得到醛的中间产物。氢化铝锂不能还原孤立的碳碳双键,其还原选择性较差,会同时还原羧基和其他官能团。由于羧基的活性较低,在低温下还原速度慢,有时甚至不发生反应,因此通常不通过降低温度来避免还原其他基团。
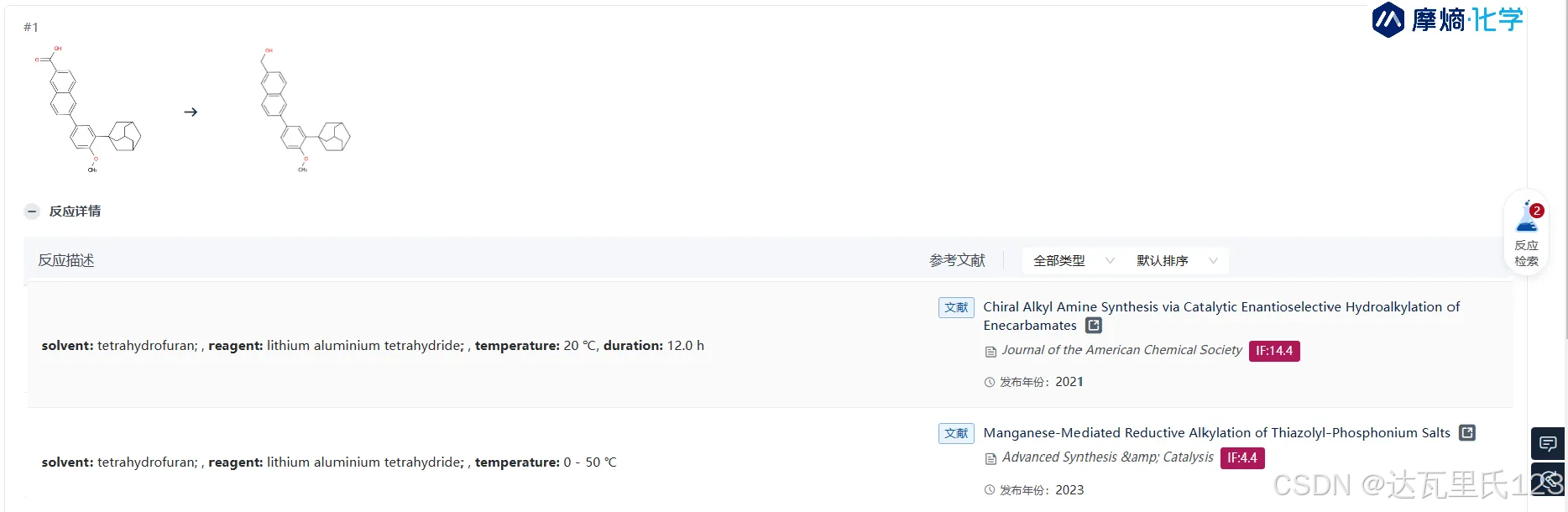
二、通过硼烷还原羧酸得到醇
硼烷是一种为强亲电性还原剂,在和羰基的反应中首先是羰基氧上的孤电子对缺电子的硼结合然后硼原子的氢,以负氢离子形式转移到羰基碳原子上而使羧酸还原成醇。这个反应的关键在于硼烷与氧的配位,因此,羰基氧的碱性越强,反应越易进行。
硼烷还原羧酸的速度依次为脂肪酸 > 芳香酸,位阻小的羧酸 > 位阻大的羧酸,且对羧酸盐无法还原。硼烷还原脂肪酸酯较慢,对芳香酸酯几乎不起作用,原因是芳环和羰基的共轭效应降低了羰基的电子密度,减少了硼烷的亲电进攻。
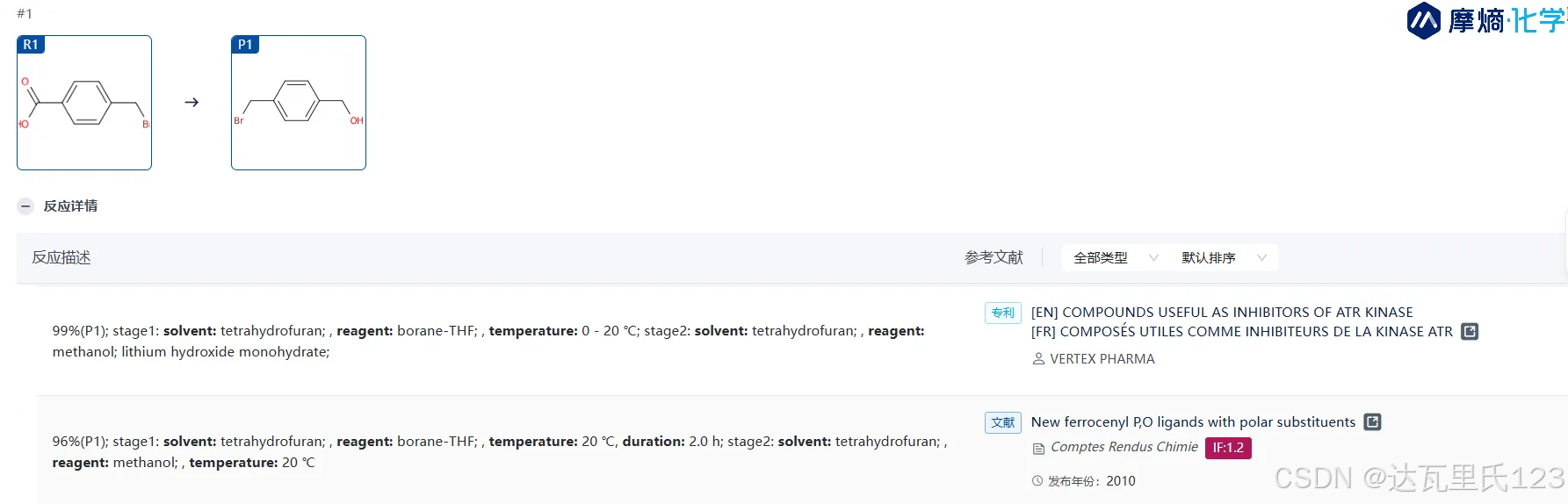
三、通过醇硼烷将羧酸直接还原为醛
想要将羧酸直接还原为醛,往往要控制好条件,避免过度还原。也可以通过原位活化羧酸为酰氯或Weinreb酰胺,再还原为醛基也是比较实用的方法。
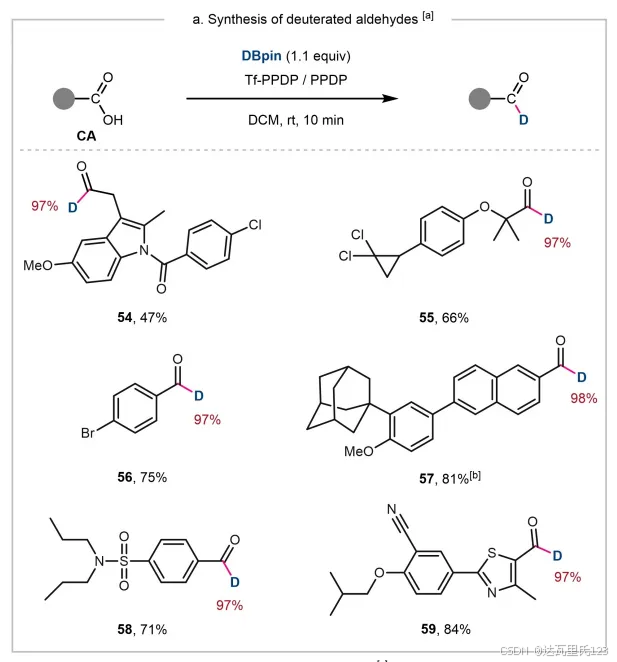
中科院兰州化学物理研究所刘超教授团队联合武汉大学戚孝天教授团队报道了一步将羧酸还原为醛的方法。在三氟甲磺酰基吡啶鎓盐促进下,室温下利用频哪醇硼烷快速可控的还原羧酸到醛。他们开创性的利用三氟甲磺酰基吡啶鎓盐将羧酸转化为酰基吡啶中间体,利用频哪醇硼烷将酰基吡啶中间体还原为醛。该方法具有条件温和、操作简便、底物范围广的优势并且可以不破坏手性结构。(登录摩熵化学下载原文10.1002/anie.202215168)
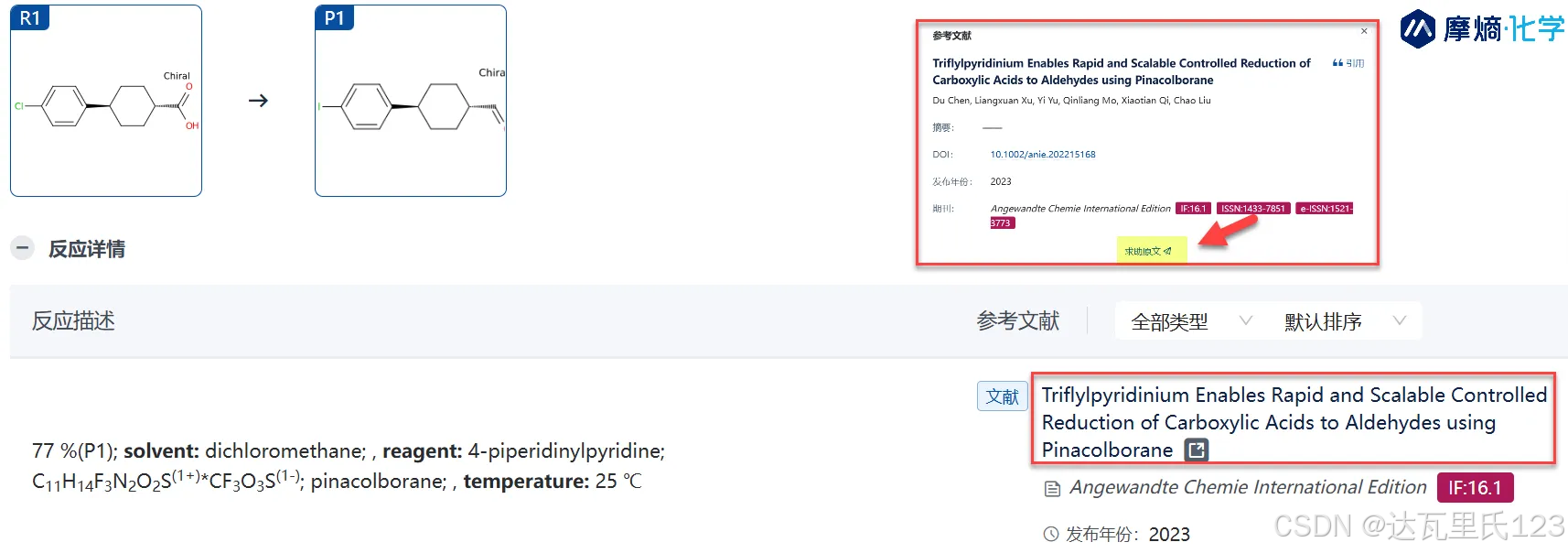
该反应体系可以用于合成氘代醛,以及进行克级规模的羧酸还原为醛的制备。此外,该反应体系还可应用于流体化学体系。

















 5640
5640

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









