






数据集划分,根据多个标签进行训练集和测试集的划分
在模型的训练和测试中,科学的划分训练集和测试对模型的任务目标和效果测量范式至关重要
我们实际中可能看到的样本可能具有多个属性,标签。它既是大的,又是有颜色,对这样的样本进行划分至关重要。
这样做的目的就是在训练集和测试集中,带有标签的样本数量比例一致

比如这里:
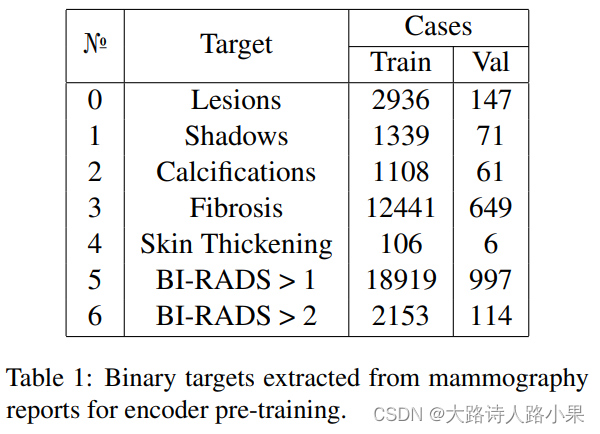
示例代码
import pandas as pd
from skmultilearn.model_selection import IterativeStratification
# 加载数据
df = pd.read_excel("/path/to/filtered_dataset2.xlsx")
# 定义关键字到标签的映射
keywords_to_labels = {
"病变": ["病变", "病检", "恶性", "癌", "结节"],
"影": ["影"],
"钙化": ["钙化"],
"纤维": ["纤维"],
"皮肤": ["皮肤"],
"BI-RADS0-2": ["BI-RADS0","BI-RADS1","BI-RADS2"],
"BI-RADS3-5": ["BI-RADS3","BI-RADS4A","BI-RADS4B","BI-RADS4C","BI-RADS5"],
}
# 新增标签列
df["BI-RADS>1"] = 0
df["BI-RADS>2"] = 0
# 标注数据
for index, row in df.iterrows():
report = f"{row['description']}\n{row['diagnosis']}"
# 计算BI-RADS关键字出现的次数
bi_rads_count = sum(report.count(kw) for kw in ["BI-RADS"])
# 根据出现次数更新新标签
if bi_rads_count > 1:
df.at[index, "BI-RADS>1"] = 1
if bi_rads_count > 2:
df.at[index, "BI-RADS>2"] = 1
for label, keywords in keywords_to_labels.items():
# 检查是否包含任一关键字
if any(keyword in report for keyword in keywords):
df.at[index, label] = 1
# 准备分层抽样
X = df.index.values.reshape(-1, 1) # 特征只是索引
y = df[list(keywords_to_labels.keys()) + ["BI-RADS>1", "BI-RADS>2"]].values
# 进行分层抽样
stratifier = IterativeStratification(n_splits=2, order=1, sample_distribution_per_fold=[0.8, 0.2])
train_indexes, test_indexes = next(stratifier.split(X, y))
# 分割数据集
train_df = df.iloc[train_indexes]
test_df = df.iloc[test_indexes]
# 保存数据集到Excel文件
train_df.to_excel("./train_dataset.xlsx", index=False)
test_df.to_excel("./test_dataset.xlsx", index=False)
# 打印每个标签在训练集和验证集中的数量,包括新的BI-RADS标签
for label in keywords_to_labels.keys():
print(f"{label} - Train: {train_df[label].sum()}, Val: {test_df[label].sum()}")
print(f"BI-RADS>1 - Train: {train_df['BI-RADS>1'].sum()}, Val: {test_df['BI-RADS>1'].sum()}")
print(f"BI-RADS>2 - Train: {train_df['BI-RADS>2'].sum()}, Val: {test_df['BI-RADS>2'].sum()}")















 8667
8667











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









