







 文章介绍了基于深度学习的实时和高精度立体匹配网络,包括AnyNet和StereoNet的实时解决方案,以及GwcNet和ACVNet的高精度方法。AnyNet和StereoNet侧重于实时性能,而GwcNet和ACVNet通过分组相关和注意力机制提升匹配精度。这些网络在计算机视觉和三维重建中有广泛应用。
文章介绍了基于深度学习的实时和高精度立体匹配网络,包括AnyNet和StereoNet的实时解决方案,以及GwcNet和ACVNet的高精度方法。AnyNet和StereoNet侧重于实时性能,而GwcNet和ACVNet通过分组相关和注意力机制提升匹配精度。这些网络在计算机视觉和三维重建中有广泛应用。
目录
前言
立体匹配是指通过比较两个或多个图像中对应点的像素信息,来确定它们在三维空间中的位置关系。其广泛应用于计算机视觉和三维重建领域,用于从立体图像中确定物体的深度信息,实现场景重建、虚拟现实、机器人导航等应用。
传统的立体匹配方法通常使用手工设计的特征和匹配算法,但这些方法在处理复杂场景或纹理缺失的区域时效果有限。
基于深度学习的立体匹配方法通过深度卷积神经网络(DCNN)来自动地学习图像中的特征表示,从而提高了立体匹配的准确性和鲁棒性。
基于深度学习的立体匹配方法通常包括以下几个步骤:
-
特征提取:将左视图和右视图的图像分别输入网络,通过网络前向传播得到特征图。这些特征图捕捉了图像中的语义和几何信息,有助于后续的立体匹配。
-
成本构建:利用特征图计算左视图中每个像素与右视图中对应像素的匹配成本。成本可以通过像素之间的差异度量(如灰度差、颜色差等)或特征相似度计算得到。
-
成本优化与回归:为了找到最佳的匹配,需要通过优化算法(如动态规划、图割等)来寻找最小的匹配成本并回归计算视差结果。优化过程可以考虑匹配代价的一致性、平滑性等约束。
-
深度估计:通过视差结果计算像素的深度值,从而实现立体图像的三维重建。深度估计可以基于视差(视差是左视图和右视图中对应像素的水平位移)来计算,也可以直接通过网络回归深度值。
一、实时立体匹配网络
1. AnyNet
原文链接:https://arxiv.org/pdf/1810.11408.pdf
源码链接:https://github.com/mileyan/AnyNet
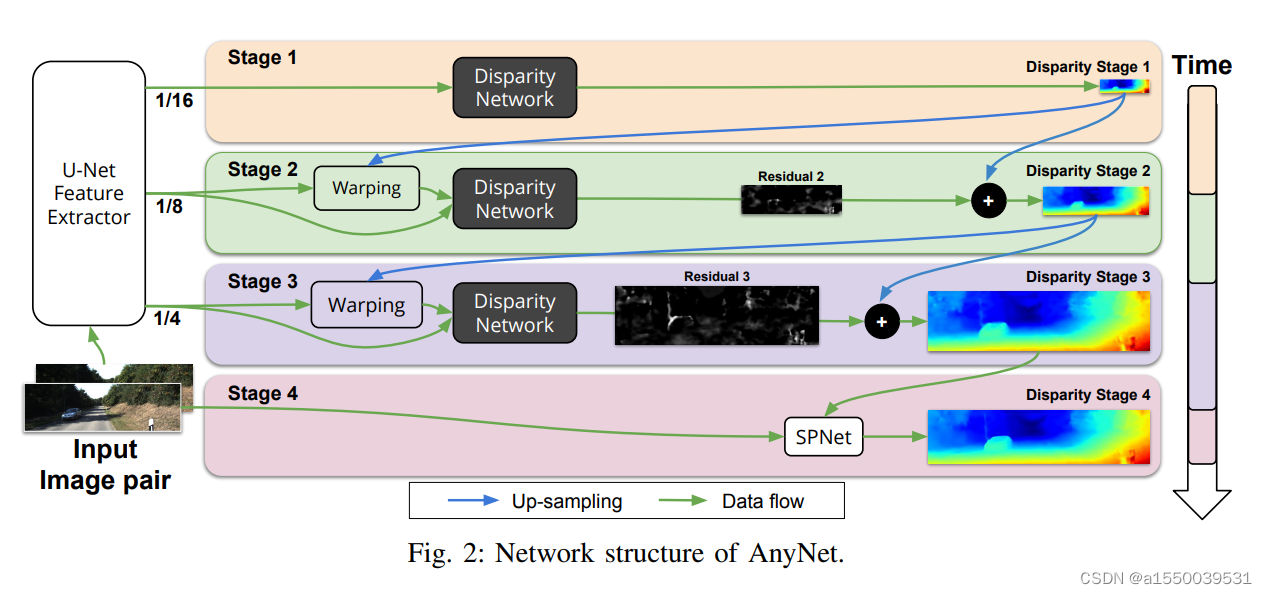
AnyNet是经典的粗到细(Coarse-to-fine)结构的立体匹配网络,可以根据实际应用的需要选取不同阶段的视差图输出,越高阶段的视差图精度越高,推理速度越慢。上图为AnyNet原文提供的网络结构示意图。网络总共分为4个阶段,第一个阶段通过距离/相关尺度度量绝对的视差匹配成本;第二第三阶段通过对前一阶段的视差图进行固定视差偏移结合高分辨率特征图构建视差修正匹配成本;第四阶段则通过SPNet网络做最后的视差图优化。
AnyNet作为能实现边缘设备实时推理的立体匹配网络,其亮点在于通过构建多个低分辨率成本体积逐阶段优化视差,避免了单一高分辨率成本体积构建与聚合所带来的高内存占用和计算复杂度。同时,其整体网络主干结构比较简单,特征提取选用标准的U-Net结构使用3x3卷积提取特征,成本构建通过距离/相关尺度构建单通道成本体积,聚合则采用线性的3x3x3卷积。
2. StereoNet
原文链接:https://arxiv.org/pdf/1807.08865.pdf
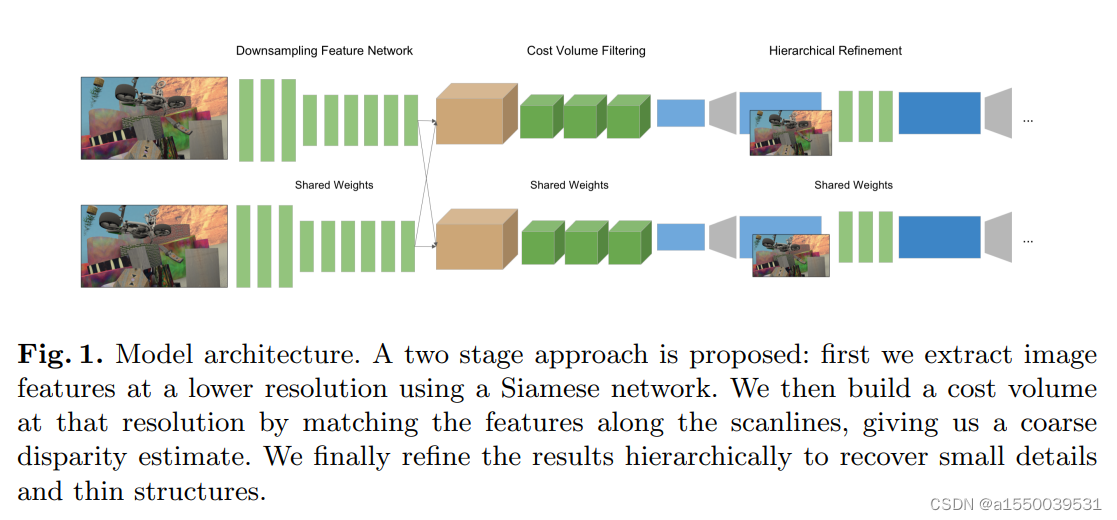
StereoNet是Google团队提出的实时立体匹配网络,可以在Nvidia Titan X平台实现60fps的推理速度。上图为StereoNet原文的结构示意图,StereoNet整体可以分为两个阶段,第一个阶段为标准的“线性”视差预测,特征提取获得特征图,并构建低分辨率成本体积,最后聚合并视差回归得到视差图。第二阶段StereoNet将左图与第一阶段的粗视差图进行拼接,通过空洞卷积网络学习并补充粗视差图上的一些边缘细节。
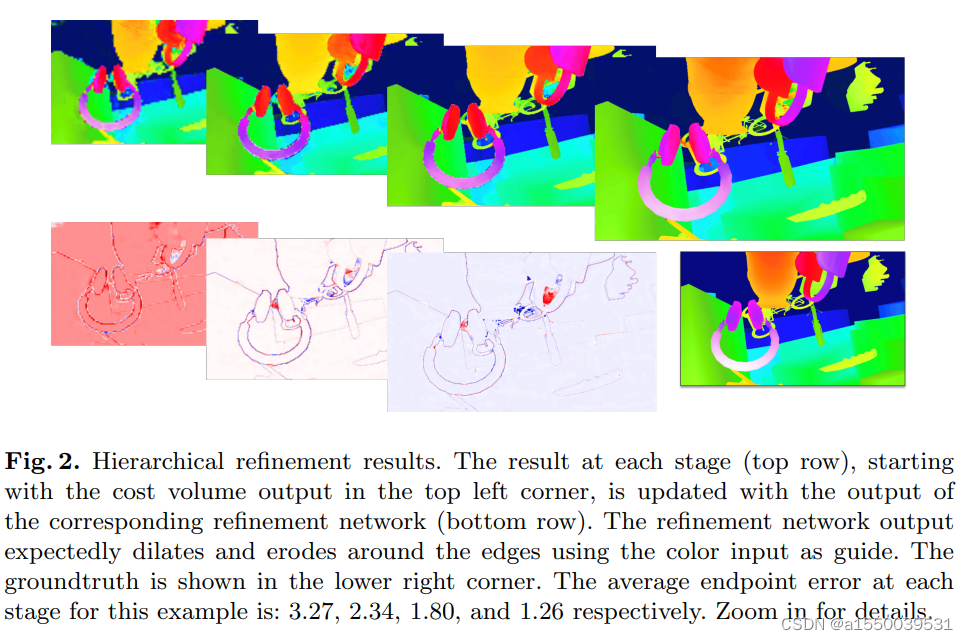
StereoNet的亮点在于其提出的基于空洞卷积的边缘感知上采样(Edge-Aware Upsampling)模块,空洞卷积有利于扩大网络整体的感受野,感知更为鲁棒的边缘细节。从原文所提供的效果图可以看出,经过模块优化后的视差图的边缘更为平滑。
以下是边缘感知上采样模块的pytorch实现示例
class refine(nn.Module):
def __init__(self, channels):
super(refine, self).__init__()
self.refine = nn.Sequential(
nn.Conv2d(4, channels, 3, padding=1),
ResBlock(channels, channels, dilation=1),
ResBlock(channels, channels, dilation=2),
ResBlock(channels, channels, dilation=4),
ResBlock(channels, channels, dilation=2),
ResBlock(channels, channels, dilation=1),
nn.Conv2d(channels, 1, 3, padding=1),
)
def forward(self, x):
return self.refine(x)
class ResBlock(nn.Module):
def __init__(self, in_channel, out_channel, dilation=1):
super(ResBlock, self).__init__()
padding = dilation
self.conv1 = nn.Conv2d(in_channel, out_channel, 3, 1,
padding=padding, dilation=dilation, bias=False)
self.bn1 = nn.BatchNorm2d(out_channel)
self.relu1 = nn.LeakyReLU(0.2, inplace=True)
self.conv2 = nn.Conv2d(out_channel, out_channel, 3, 1,
padding=padding, dilation=dilation, bias=False)
self.bn2 = nn.BatchNorm2d(out_channel)
self.relu2 = nn.LeakyReLU(0.2, inplace=True)
def forward(self, x):
out = self.relu1(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
out += x
return self.relu2(out)二、高精度立体匹配网络
1. GwcNet
原文链接:https://arxiv.org/pdf/1903.04025.pdf
源码链接:https://github.com/xy-guo/GwcNet
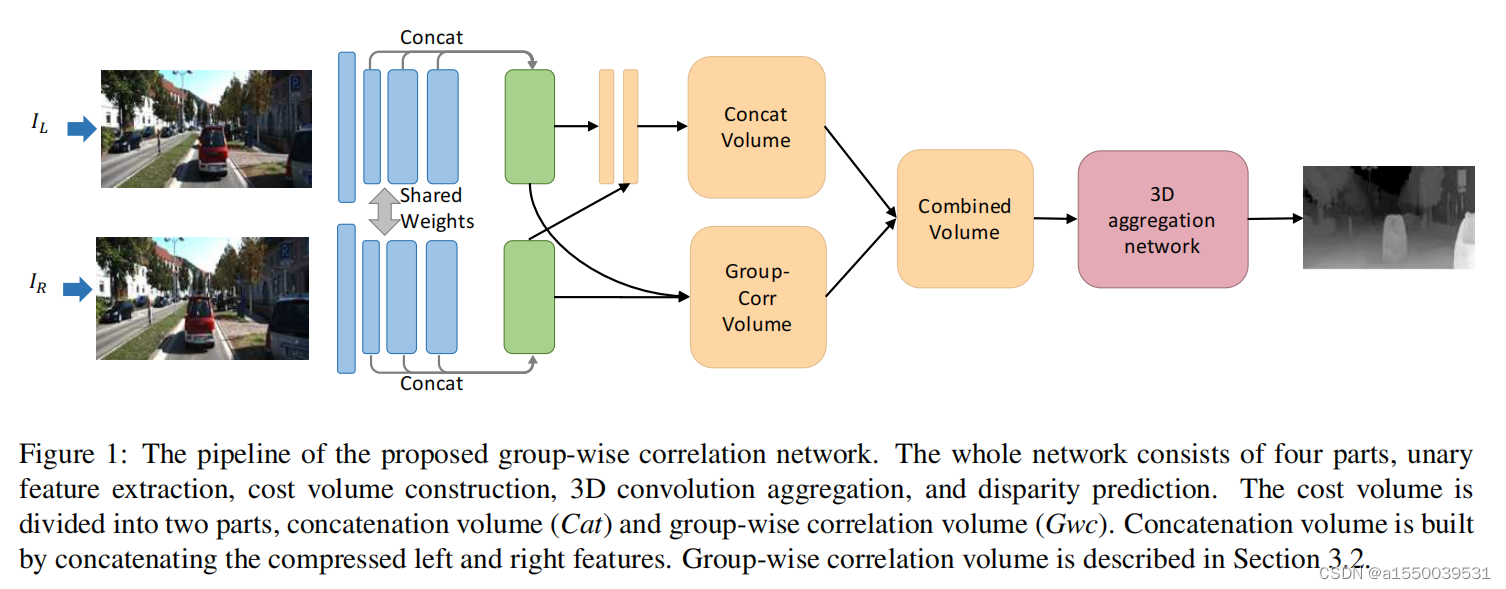
GwcNet是经典的高精度立体匹配网络,其提出的分组相关(group-wise correlation)成本构建方法通过对特征图的通道进行分组构建多组视差候选,有效地解决了单通道成本体积的特征匹配冗余问题。同时,为了更好的利用特征提取得到的特征,其构建了两个不同的成本体积进行级联。

分组相关成本构建的公式如上图,其中为特征图的总通道数,
为分组数,
为分组后的左右特征图,
为所考虑的视差能级偏移。
以下是原文所提供的代码
def groupwise_correlation(fea1, fea2, num_groups):
B, C, H, W = fea1.shape
assert C % num_groups == 0
channels_per_group = C // num_groups
cost = (fea1 * fea2).view([B, num_groups, channels_per_group, H, W]).mean(dim=2)
assert cost.shape == (B, num_groups, H, W)
return cost
def build_gwc_volume(refimg_fea, targetimg_fea, maxdisp, num_groups):
B, C, H, W = refimg_fea.shape
volume = refimg_fea.new_zeros([B, num_groups, maxdisp, H, W])
for i in range(maxdisp):
if i > 0:
volume[:, :, i, :, i:] = groupwise_correlation(refimg_fea[:, :, :, i:], targetimg_fea[:, :, :, :-i],
num_groups)
else:
volume[:, :, i, :, :] = groupwise_correlation(refimg_fea, targetimg_fea, num_groups)
volume = volume.contiguous()
return volume2. ACVNet
原文链接:https://arxiv.org/pdf/2203.02146.pdf
源码链接:https://github.com/gangweiX/ACVNet
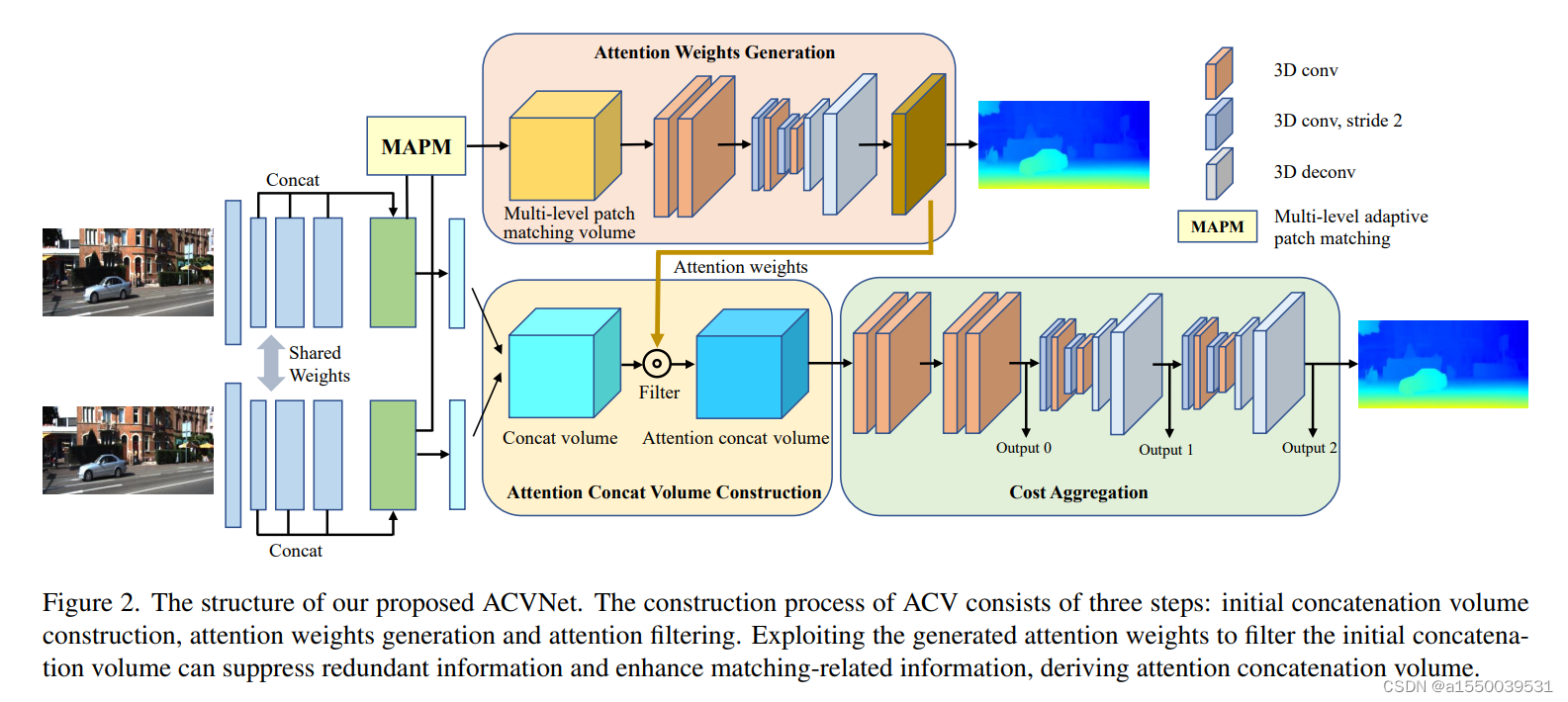
ACVNet在GwcNet的基础上加入了注意力机制,这种注意力机制通过从相关性线索中生成注意力权重来抑制冗余信息并增强与匹配相关的信息在级联体积中的表达。可靠的注意力权重通过其提出的多级自适应补丁匹配方法获得。
ACVNet的亮点在于基于注意力的成本构建方法(Attention Concat Volume Construction),这种构建方法需要构建两个成本体积,分别为gwc volume和concat volume,以下是原文提供的两个成本体积的代码实现
### gwc cost volume
def build_gwc_volume(refimg_fea, targetimg_fea, maxdisp, num_groups):
B, C, H, W = refimg_fea.shape
volume = refimg_fea.new_zeros([B, num_groups, maxdisp, H, W])
for i in range(maxdisp):
if i > 0:
volume[:, :, i, :, i:] = groupwise_correlation(refimg_fea[:, :, :, i:], targetimg_fea[:, :, :, :-i],
num_groups)
else:
volume[:, :, i, :, :] = groupwise_correlation(refimg_fea, targetimg_fea, num_groups)
volume = volume.contiguous()
return volume
def groupwise_correlation(fea1, fea2, num_groups):
B, C, H, W = fea1.shape
assert C % num_groups == 0
channels_per_group = C // num_groups
cost = (fea1 * fea2).view([B, num_groups, channels_per_group, H, W]).mean(dim=2)
assert cost.shape == (B, num_groups, H, W)
return cost
### concat cost volume
def build_concat_volume(refimg_fea, targetimg_fea, maxdisp):
B, C, H, W = refimg_fea.shape
volume = refimg_fea.new_zeros([B, 2 * C, maxdisp, H, W])
for i in range(maxdisp):
if i > 0:
volume[:, :C, i, :, :] = refimg_fea[:, :, :, :]
volume[:, C:, i, :, i:] = targetimg_fea[:, :, :, :-i]
else:
volume[:, :C, i, :, :] = refimg_fea
volume[:, C:, i, :, :] = targetimg_fea
volume = volume.contiguous()
return volume其中,gwc cost volume 作为MAPM方法的输入生成注意力权重,原文提供的代码实现如下(这里截取代码的片段,主要用于辅助理解)
# input: gwc_volume
gwc_volume = self.patch(gwc_volume)
# self.patch = nn.Conv3d(40, 40, kernel_size=(1, 3, 3), stride=1, dilation=1, groups=40, padding=(0, 1, 1), bias=False)
patch_l1 = self.patch_l1(gwc_volume[:, :8])
# self.patch_l1 = nn.Conv3d(8, 8, kernel_size=(1, 3, 3), stride=1, dilation=1, groups=8, padding=(0, 1, 1), bias=False)
patch_l2 = self.patch_l2(gwc_volume[:, 8:24])
# self.patch_l2 = nn.Conv3d(16, 16, kernel_size=(1, 3, 3), stride=1, dilation=2, groups=16, padding=(0, 2, 2), bias=False)
patch_l3 = self.patch_l3(gwc_volume[:, 24:40])
# self.patch_l3 = nn.Conv3d(16, 16, kernel_size=(1, 3, 3), stride=1, dilation=3, groups=16, padding=(0, 3, 3), bias=False)
patch_volume = torch.cat((patch_l1, patch_l2, patch_l3), dim=1)
cost_attention = self.dres1_att_(patch_volume)
# self.dres1_att_ = nn.Sequential(convbn_3d(40, 32, 3, 1, 1), nn.ReLU(inplace=True), convbn_3d(32, 32, 3, 1, 1))
cost_attention = self.dres2_att_(cost_attention)
# self.dres2_att_ = hourglass(32)
att_weights = self.classif_att_(cost_attention)
# self.classif_att_ = nn.Sequential(convbn_3d(32, 32, 3, 1, 1), nn.ReLU(inplace=True), nn.Conv3d(32, 1, kernel_size=3, padding=1, stride=1, bias=False))
# output: att_weightsMAPM方法首先使用self.patch方法对输入的成本体积做通道映射,接着将映射后的成本体积按通道顺序分成8、16、16通道的三组,并使用权重不共享的空洞卷积做单独映射,然后将它们沿通道维度拼接后再使用卷积块以及hourglass网络做映射得到注意力权重,注意力权重与concat成本体积做张量乘法得到最终的注意力成本体积。

















 2111
2111

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









