







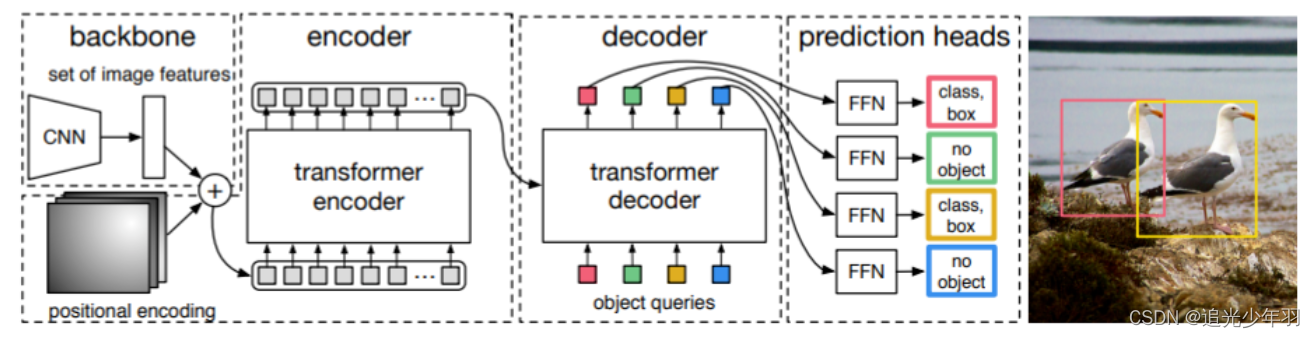
1. 将一个batch的图片输入backone获得feature。
(2,c,w,h)先输入resnet50中,得到(2,2048,w,h)。虽然这里channel不是256,但是在输入encoder之前会经过1x1卷积层,修改维度为256。
2. 计算位置编码。
当前batch图片经过归一化处理后,选取的是高和宽的最大值,所以边缘都用0填充。进行行累加和列累加,找出当前像素对应的X位置和y位置。对于其中每一个像素而言,前128维使用x位置进行编码,后128维使用y位置进行编码。 比如说一个像素的x、y位置信息为(15,16),那么前128维的分母设置与在128维的某个位置有关,分子设置即为当前x位置。后128维的分母设置与在128维的某个位置有关,分子设置即为当前y位置。
3. 输入transformer结构获得输出向量,用于计算分类概率和边界框回归参数。
将backbone得到的feature经过1x1卷积层,修改维度为256得到src。当前数据格式为(2,w * h,256)。
1. 对于Encoder,q和k设置为src + pos,v设置为src。每一层的输出src作为下一层的输入,pos保持不变。最后得到输出memory。
2. 对于Decoder,对于第一个自注意力层,输入为可学习的位置编码query(2,100,256)和全0矩阵tgt(2,100,256)。q和k设置为tgt + query,v设置为tgt。输出tgt。对于第二个注意力层,需要用到编码器的输出memory。q设置为tgt + query,k设置为memory + pos,v设置为memory。每一层的输出tgt (保存下来) 作为下一层的输入,query保持不变。最后输出hs(6,2,100,256)。
4. 计算分类概率和边界框回归参数,与GT进行匈牙利匹配,计算损失。
如果使用aux_loss,则对Decoder每一层的输出计算损失。首先得到分类概率(6,2,100,92)和边界框回归参数(6,2,100,4)。然后对将Decoder最后一层的输出和其他分开,分别计算。
1. 匈牙利匹配 对于(2,100,92)和(2,100,4)来说,变成(200,92)和(200,4),而对应的GT变成(20,)和(20,4),其中第一张图片3个box,第二张图片17个box。cost_class部分,选取对应GT的位置,取负号,这样降低损失才能保证预测概率最大。
cost_bbox和cost_giou部分,直接计算得到(200,20),可以认为每一个anchor与每一个GT都计算了。最后匈牙利匹配,得到indices为(tensor(( 1, 40, 59)), tensor((0, 2, 1]))和另外部分 (包含17个anchor与GT的索引)。
2. 计算损失
loss_labels部分,我们已经有了分类概率(2,100,92),需要对所有anchor(正、负样本)都要计算这部分损失,每一个anchor要获得真正的GT。 首先,我们通过indices获得正样本anchor索引:tensor((0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1))、tensor(( 1, 40, 59, 4, 12, 23, 26, 36, 40, 53, 55, 56, 60, 61, 70, 79, 81, 86, 94, 98)),这样就可以在(2,100)这个维度中找到正样本anchor。然后,我们通过indices获得GT索引,对于batch中每一张图片求得真实label (20,)。最后,构建真实label矩阵(2,100),初始值为91,对应正样本anchor索引处赋值为真实label。通过分类概率的softmax (2,100,92) 和真实label矩阵 (2,100) 的one_hot计算损失。
loss_boxes部分,我们已经有了边界框回归参数(2,100,4),仅对有对应GT的anchor(正样本)计算这部分损失,仅正样本anchor要获得真正的GT。 首先,获得正样本anchor索引。然后,获得GT索引,对于batch中每一张图片求得真实box (20,4)。最后,我们选出对应正样本anchor索引处边界框回归参数 (20,4),与真实box计算L1损失和GIoU损失。
5. 预测时,计算每个框最大的分类概率,通过阈值筛选。
针对分类概率(2,100,92),首先在最后一个维度做softmax,然后选择最大值(score),最大值对应的索引(label)。针对边界框回归参数(2,100,4),首先根据target选取图片真实的W(2,)、H(2,),将(W,H,W,H)调整维度到(2,1,4),然后与边界框回归参数相乘后返回。最后选取一个阈值(0.7),筛选一下每张图片的100个框。














 3045
3045











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









