






SVR(支持向量回归)是一种用于预测未来数据的强大工具,特别是当数据呈现非线性关系时。以下是使用SVR进行预测的一般步骤:
| 代码获取戳此:SVR/SVM支持向量机预测未来数据 |
-
数据预处理:
- 导入数据集
- 数据清洗:检查并处理缺失值、异常值或重复数据。
- 数据标准化或归一化:通过缩放特征值,使所有特征都在相似的尺度上,这有助于优化算法的性能。
- 分割数据集:将数据集随机分割为训练集和测试集,通常使用80%的数据作为训练集,20%的数据作为测试集。
-
定义SVR模型:
- 设置SVR的参数,如核函数(如线性、多项式、径向基函数等)、正则化参数C、不敏感损失ε等。
-
训练SVR模型:
- 使用训练集的特征和目标变量来训练SVR模型。
- 在训练过程中,SVR会找到一个超平面,该超平面能够最小化训练数据的误差,同时允许一定的误差容限。
-
评估模型性能:
- 使用测试集来评估模型的性能。
- 可以通过计算均方误差(MSE)、均方根误差(RMSE)或其他评估指标来量化模型的预测准确性。
-
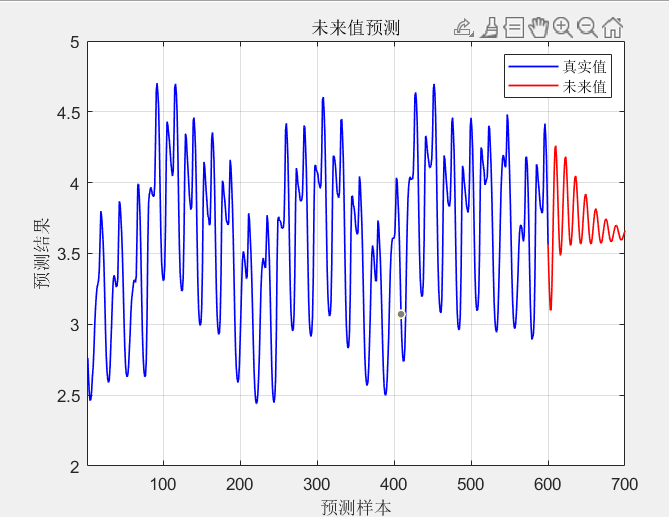
预测未来数据:
- 一旦模型训练完成并通过测试集验证,就可以使用模型来预测未来数据了。
- 将新数据的特征输入到训练好的SVR模型中,模型将输出相应的预测值。
-
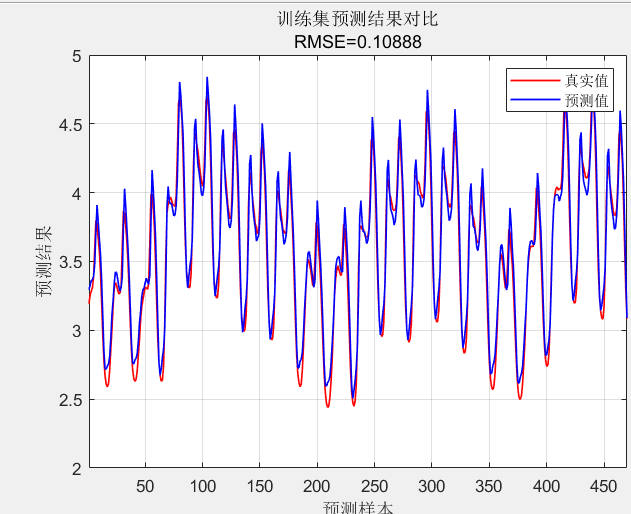
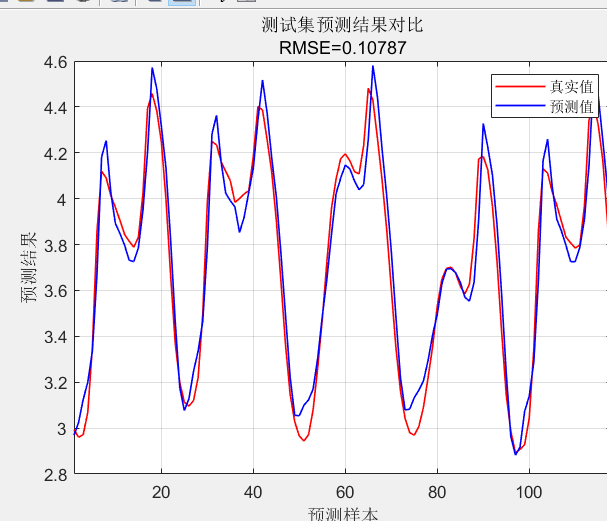
以下是基于时间序列数据集进行的对未知数据预测效果:
-
















 604
604











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









