






CNN-BiGRU、CNN-BiLSTM、CNN-GRU、CNN-LSSVM、CNN-LSTM和CNN-SVM这些模型的结构原理在某些方面有相似之处,但在其他方面又各有其特点。下面我们将分别讨论这些模型的异同点以及它们之间的优劣性对比。
| 代码获取戳此:CNN合集(CNN-BiGRU、CNN-BiLSTM、CNN-GRU、CNN-LSSVM、CNN-LSTM等) |
相同点
- 都结合了CNN:所有这些模型都结合了卷积神经网络(CNN),用于从输入数据中提取局部空间特征。
- 适用于序列数据:除了CNN-LSSVM主要用于时间序列预测外,其他模型都可以用于处理序列数据,如文本、语音等。
异同点
- RNN变体:
- CNN-BiGRU、CNN-BiLSTM、CNN-GRU和CNN-LSTM都结合了RNN的变体来处理序列数据中的长期依赖关系。
- CNN-BiGRU和CNN-BiLSTM使用了双向RNN,可以捕捉双向的上下文信息。
- CNN-GRU使用了门控循环单元(GRU),它是LSTM的一个简化版本,但计算效率更高。
- CNN-LSTM使用了长短时记忆网络(LSTM),它在处理长期依赖方面非常有效。
- 输出层:
- CNN-LSSVM使用了最小二乘支持向量机(LSSVM)作为输出层,用于回归预测。
- CNN-SVM使用了支持向量机(SVM)作为分类器。
- 目的和应用场景:
- CNN-LSSVM更适用于时间序列预测任务。
- CNN-SVM更适用于图像分类和文本分类等分类任务。
- 其他模型则更广泛地适用于各种序列处理任务,如自然语言处理、语音识别等。
优劣性对比
- 模型复杂度:
- CNN-LSSVM和CNN-SVM在模型复杂度上相对较低,因为它们主要依赖于CNN进行特征提取,然后使用简单的分类器或回归器。
- CNN-BiGRU、CNN-BiLSTM、CNN-GRU和CNN-LSTM的复杂度较高,因为它们包含了RNN的变体,这些结构在处理序列数据时需要更多的计算资源。
- 计算效率:
- CNN-LSSVM和CNN-SVM由于模型结构相对简单,计算效率较高。
- CNN-GRU在计算效率上通常优于CNN-LSTM,因为GRU是LSTM的简化版本,具有更少的参数和更快的训练速度。
- CNN-BiGRU和CNN-BiLSTM由于使用了双向RNN,计算效率可能稍低。
- 性能:
- 对于需要捕捉长期依赖和双向上下文信息的任务,CNN-BiGRU、CNN-BiLSTM和CNN-LSTM通常具有更好的性能。
- 对于分类任务,CNN-SVM可能具有更好的分类性能,尤其是在处理高维数据时。
- CNN-LSSVM在处理时间序列预测任务时可能具有更好的性能。
- 适用场景:
- CNN-BiGRU、CNN-BiLSTM、CNN-GRU和CNN-LSTM更适用于自然语言处理、语音识别等需要处理序列数据的任务。
- CNN-LSSVM更适用于时间序列预测任务。
- CNN-SVM更适用于图像分类、文本分类等分类任务。
该作品包含模型:
CNN-BiGRU、CNN-BiLSTM、CNN-GRU、CNN-LSSVM、CNN-LSTM、CNN-SVM
基于风电数据集进行预测效果对比
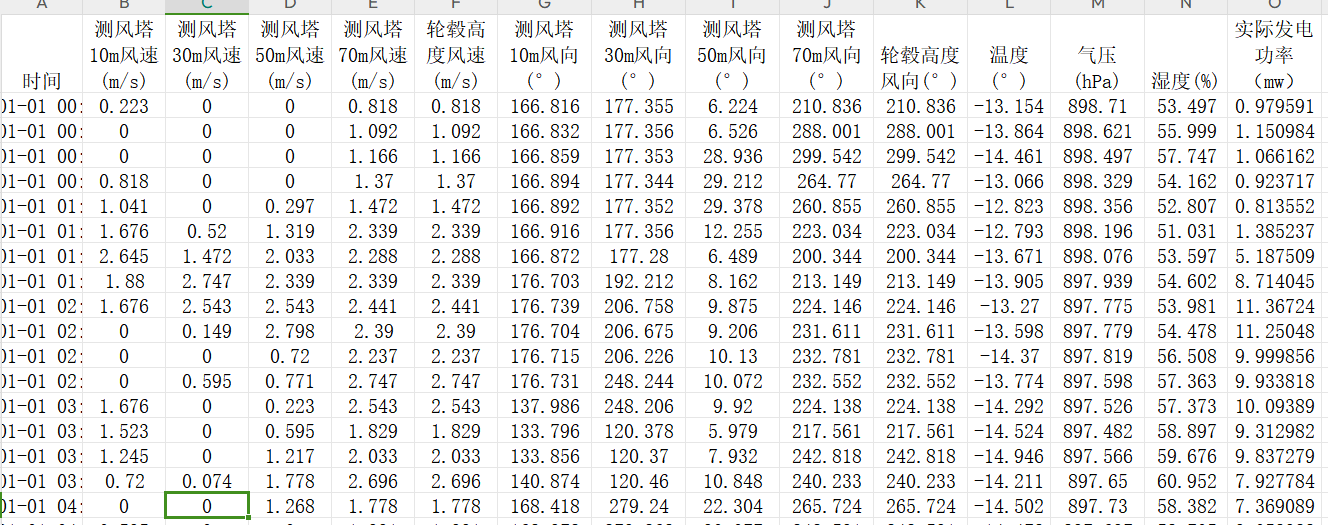
效果对比

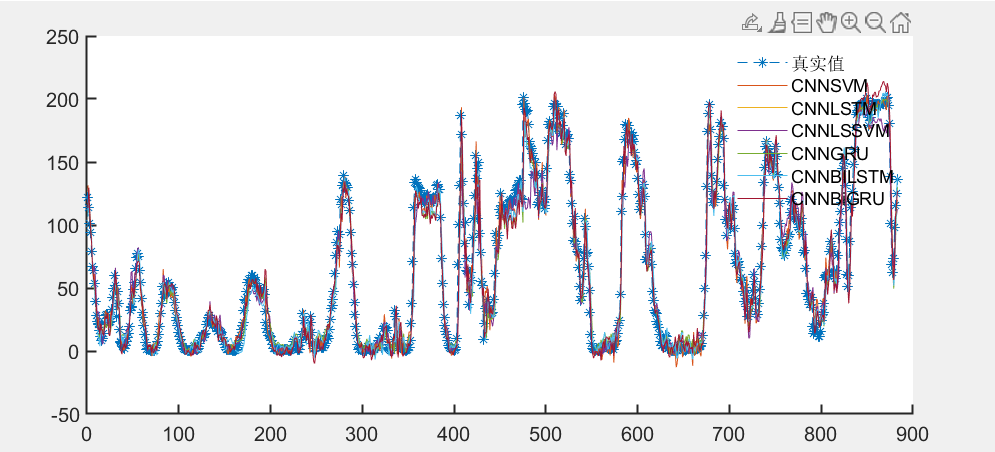
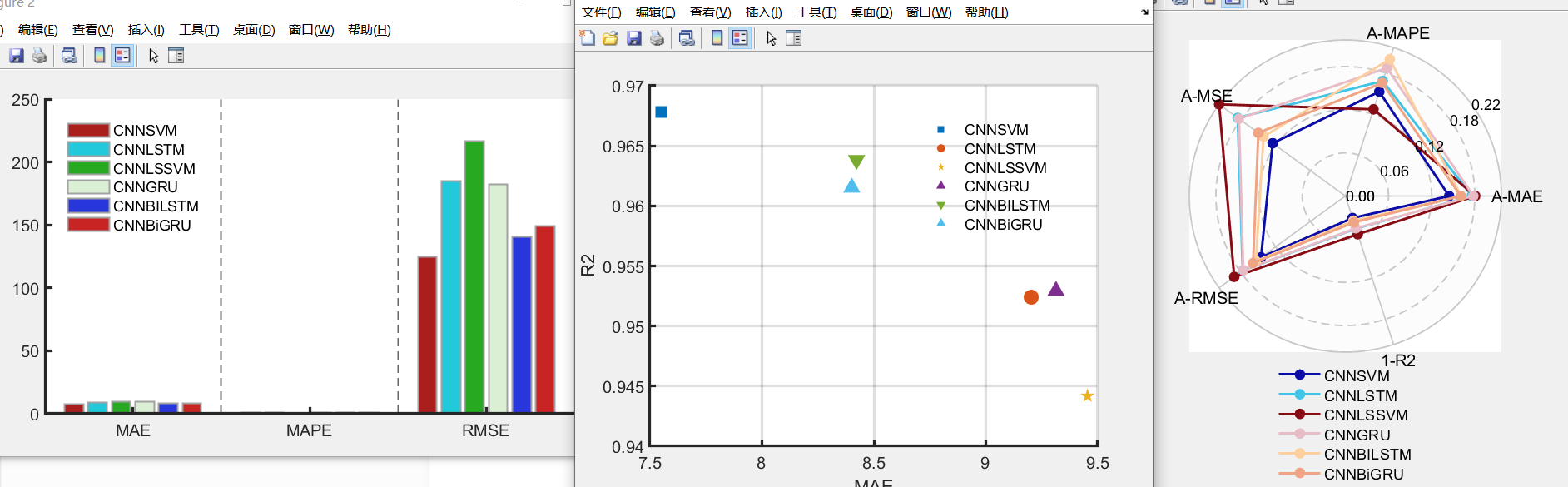
















 354
354











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









