







写在前面:
之前笔者也进行了类似的数字人模型部署,可参考文章:基于Video-ReTalking的AI数字人模型部署_livetalking-CSDN博客
Video_Retalking这个模型主要应用于:对视频中人物嘴型进行重编辑,所以输入端最好是视频+音频。因而该模型能够较好实现对视频中人物声音的替换。如果是输入图片+音频,就会导致最终生成的视频仅有人物嘴部在运动,而面部较为僵硬,无法实现自然的数字人效果。
本次涉及的sadtalker模型,其输入端是图片+音频,最终生成的数字人效果较好,整个面部区域均有所运动,更加自然、但该模型在嘴型和文字的匹配度上相较于Video-Retalking模型较差。
环境部署:
虚拟环境的创建等一些列操作就不多说了,注意python需要的是3.8版本的,这里主要讲各种包的安装和注意事项:
进入虚拟环境后,安装pytorch,这里笔者一直比较喜欢采用离线安装的方式。
离线安装包下载地址:download.pytorch.org/whl/cu118
需要下载的版本pytorch相关版本包分别为(针对windows系统):
![]()
![]()
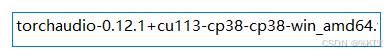
然后到这三个安装包的位置,使用指令:
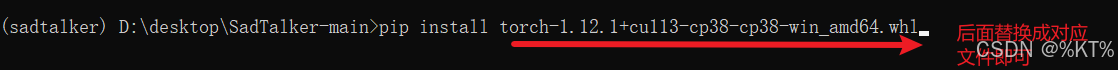
按上面的步骤安装好后,安装requirements里的相关库,可以使用批量自动安装的方法:
pip install -r requirements.txt -i https:pypi.tuna.tsinghua.edu.cn/simple
也可以采用逐步安装每个库的方法,这里其实我是比较推荐这种方法的,前一种方法笔者安装时存在一些问题,没有安装成功,逐个替换需要安装的库名称即可。
例如:
pip install numpy==1.23.4 -i https://pypi.tuna.tsinghua.edu.cn/simple
在安装这些包时存在的一个问题是:basicsr这个库安装不上,问题出在清华镜像源没有tb-nightly先关库,所以安装这个库的时候需要换源安装:
可以从官网,或者豆瓣,或者阿里等都可以试一试,也可以尝试离线安装,找到对应的.whl文件即可。笔者是这样安装成功的:
pip install basicsr==1.4.2 -i https://pypi.org/simple
下载相关模型
这里需要下载两个文件,两个文件还是有点大的,推荐使用谷歌网盘吧,源代码库也有下载链接。
下载预训练模型:
百度网盘 (Password:sadt)
下载GFPGAN离线补丁
百度网盘 (Password:sadt)
下载好后,需要进行如下处理:
1.将下载好的sadtalker.zip解压后重命名为checkpoints,复制到SadTalker项目文件夹下。
2.将gfpgan文件解压后直接移动到SadTalker项目文件夹下。
整个文件夹格式是这样的:
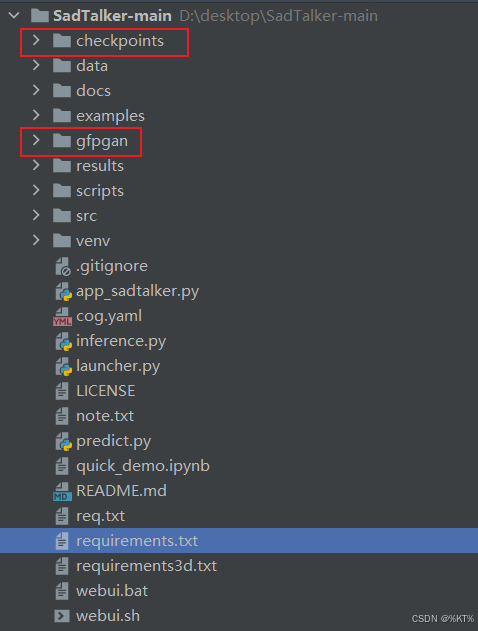
运行代码:
运行指令为:
图片+音频运行指令:
python inference.py --driven_audio data/sample.wav --source_image data/sample.png
视频+音频运行指令:
python inference.py --driven_audio data/sample.wav --source_image data/sample.mp4
效果展示:


左图为Video-Retalking模型的效果,右图为SadTalker模型的效果,可以明显看到,不论是画质还是自然度,SadTalker均有较大提升。

















 5778
5778

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









