







单目自监督稠密景深估计
Unsupervised Learning of Depth and Ego-Motion from Video
CVPR 2017:基于非结构化的视频输入,采用无监督学习框架得到了单目景深和相机运动估计。在训练时,景深和相机运动耦合在一起训练;但是在应用时可以单独使用。
文章材料(论文,源码,演示视频)链接:https://people.eecs.berkeley.edu/~tinghuiz/projects/SfMLearner/
算法原理
整个算法的训练输入就是视频的三帧子序列。其中深度估计只基于当前帧作为输入,得到目标图像每个像素点的深度估计。而位姿估计网络,同时基于前后两帧图像来得到前后两帧的空间变换矩阵。而最终的 loss 是基于深度和位姿的估计综合定义的。

监督信号
该算法将相邻图像经过映射之后的差异作为 loss。
![]()

首先基于景深和位姿估计将目标图像上的像素点投影到前后帧上。然后使用双线性插值获取在同一位置前后帧的像素值。
而 pt 到 ps 的变换由下式给出,其中用到了估计的景深和变换矩阵,其中 K 为相机内参。
![]()
模型的局限性
- 场景中不能存在移动的目标
- 在相邻三帧中不存在遮挡
- the surface is Lambertian so that the photo-consistency error is meaningful
为了解决这个问题,同时也提高算法的鲁棒性,论文中提到可以单独训练一个网络来估计每个像素的 mask。原理大致是估计出哪些像素点存在运动目标或遮挡,那么这些像素点将不参与 loss 的计算。
![]()
局部梯度问题
如果待估计像素周围像素值差异不大(缺少纹理)或者估计点远离真实点,此时将阻碍训练的进行。
解决这一问题有两种常用思路:
- 使用一个小 bottleneck 的编码和解码网络,从而隐式的获取全局的平滑结果
- 通过显示的定义多尺度的平滑 loss
文中采用了第二种方式,最后的 loss 定义如下:
![]()
其中最后一项是为了在无监督的情况下,限制 mask 的估计,避免造成 mask 全部估计为零的情况。
网络结构

整个网络结构借鉴了 N. Mayer, E. Ilg, P. Hausser, P. Fischer, D. Cremers, A. Dosovitskiy, and T. Brox. A large dataset to train convolutional networks for disparity, optical flow, and scene flow estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 4040– 4048, 2016. 中的 DispNet。
FisheyeDistanceNet: Self-supervised Scale-Aware Distance Estimation using Monocular Fisheye Camera for autonomous Driving
arXiv 2020:在没有对鱼眼图像进行校正的前提下,仅通过单目鱼眼视频得到了一个能够估计景深和相机运动的尺度自适应网络。
论文地址:https://arxiv.org/abs/1910.04076
效果视频:https://www.youtube.com/watch?v=Sgq1WzoOmXg&feature=youtu.be
本文是在上文的基础上引入了诸如鱼眼镜头的畸变模型等先验信息从而大幅提高了景深估计的精度。
算法细节
鱼眼镜头建模
从 3D 空间上的点 ![]() 到图像上的像素位置 p=
到图像上的像素位置 p=![]() 之间的映射可以通过以下几个公式建模:
之间的映射可以通过以下几个公式建模:
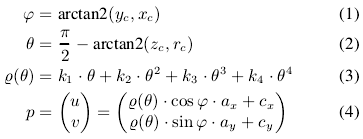
对应反变换也可以直接推导得到。
训练时的尺度模糊问题
由于单目景深估计本质上存在尺度模糊问题(即估计景深为1,但无法确定 1 的单位是米还是厘米),因此论文中使用两个时刻车的速度来解决尺度模糊问题。
静止物体 mask
为解决上一篇文章中提到的运动物体的问题,本文增加了一个静止物体标识 mask 的计算。在网络 forward 阶段,将输出一个 0-1 的二值 mask 用来标识静止物体。同时,只有在经过变换后的像素值误差小于原始图像的像素值误差时,对应位置的 mask 才为 1。
Photometric Loss
基于估计得到的深度,通过上面定义的反投影关系可以得到图像中实际物体的 3D 点云。
![]()
之后再根据投影关系,就可以将 3D 点云重新投影回目标图像。
![]()
其中由于重构像素位置是连续的,因此过程中也需要使用双线性插值。
最后的目标损失函数参考 Z. Wang, A. C. Bovik, H. R. Sheikh, E. P. Simoncelli, et al., “Image quality assessment: from error visibility to structural similarity,” IEEE transactions on image processing, vol. 13, no. 4, pp. 600–612, 2004. 中定义的 Structural Similarity (SSIM)

其中 M 就是上面介绍的静止物体 mask
多次误差计算
为了引入更多约束,论文中不止计算前后帧图像向当前帧的投影误差,同时考虑当前帧向前后帧的投影误差。这增大的计算量和训练时间,但是提高的精度。
边缘平滑损失
为了归一化遮挡和缺少纹理区域的距离并避免发散,因此额外引入几何平滑误差。
这个没太看懂,说是可以借鉴一下三篇文章:
- C. Godard, O. Mac Aodha, and G. J. Brostow, “Unsupervised monocular depth estimation with left-right consistency,” in Cvpr, 2017.
- R. Mahjourian, M. Wicke, and A. Angelova, “Unsupervised learning of depth and ego-motion from monocular video using 3d geometric constraints,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 5667–5675.
- Y. Zou, Z. Luo, and J.-B. Huang, “Df-net: Unsupervised joint learning of depth and flow using cross-task consistency,” in Proceedings of the European Conference on Computer Vision (ECCV), 2018, pp. 36–53.
景深一致性损失
由于不同帧中对应相同静止物体的景深应该具有一致性,因此文中进一步引入了景深一致性损失。本质就是通过上面的公式 6 和 7,统计不同帧上相同静止物体的景深估计差异。

最后的训练误差
式中为了避免收敛于局部最优点,采用了四个不同尺度计算的误差加权和作为最后的训练误差。

网络细节

具体网络结构感觉跟上一篇文章类似。
最后再给一张效果图
















 913
913











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









