







Valeo(法雷奥)公司多个机构(Valeo DAR Kronach, Valeo Vision Systems等)近几年在自动驾驶视觉感知领域成果层出不穷,其中几篇经典文章均出自Varun Ravi Kimar之手,同时还发布了一个自动驾驶多任务环视数据集woodScape。博主对近期阅读的Valeo一系列文章做一个简要总结,同时也对其引用的一些基础论文做简要的介绍,希望与大家多多交流。本文将从鱼眼深度估计模型开始介绍,关于基础的针孔相机深度估计理论可参考博主以往文章:
苹果姐:深度估计自监督模型monodepth2论文总结和源码分析
一、单鱼眼基石之作:FisheyeDistanceNet(2020)
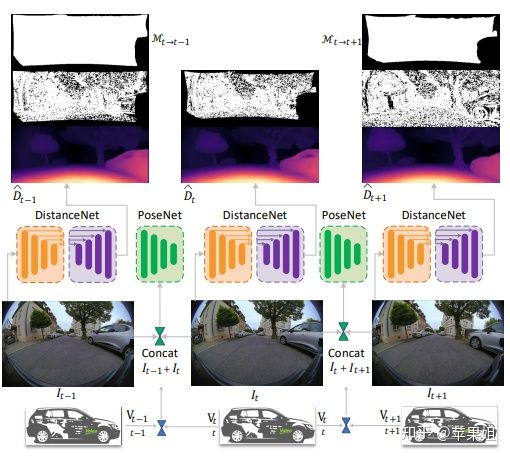
这篇文章首先进行了从针孔深度估计到鱼眼深度估计的尝试。基本理论架构上沿用了针孔深度估计的经典之作sfm-learner:
[2] Unsupervised Learning of Depth and Ego-Motion from Video (CVPR 2017)
和monodepth2:
[3] Digging Into Self-Supervised Monocular Depth Estimation (CVPR 2018)
将针孔投影模型替换为鱼眼投影模型,并做出一系列改进。具体描述如下:
一、将monodepth2的针孔投影模型替换为畸变未校正的鱼眼模型:
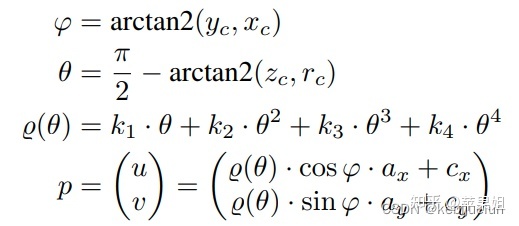
二、通过输入额外的监督信号:自车实时速度作为posnet输出位姿的约束,可以解决monodepth2输出的相对尺度问题,得到绝对的深度尺度,更加有利于落地的实用性。
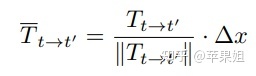
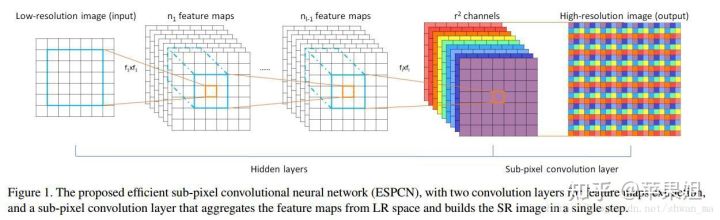
三、在网络结构上使用了超分辨率网络(super-resolution networks)和可变卷积(deformable convolution)结合的网络结构,可以从输入的低分辨率图像中得到高分辨率的深度图,并且边缘清晰。以此代替了转置卷积和最近邻双线性的上采样方法。
1.超分辨率网络来源于以下论文:
主要原理是使用了亚像素卷积层(sub-pixel layer),将输出的特征通道数变为r^2,再将多通道的特征周期性地插入到低分辨率图像中,得到高分辨率图像(此过程称为periodic shuffling,下图最后不同颜色所示)。
2.可变卷积来源于以下论文:
[5] Deformable ConvNets v2: More Deformable, Better Results (CVPR 2018)
其中deformable convolution的概念又源于这篇文章:
[6] Deformable Convolutional Networks(CVPR 2017),基本思想见下图:
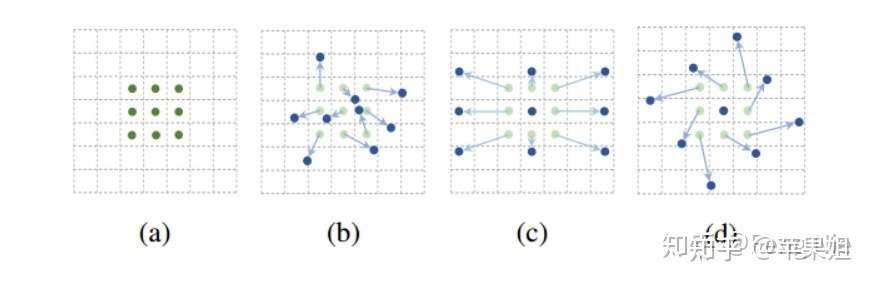
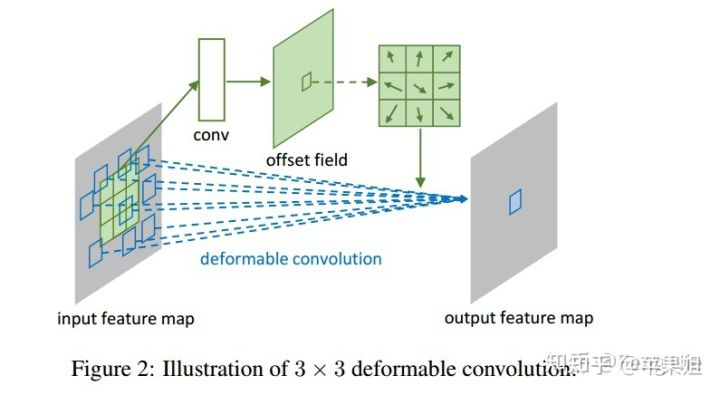
也就是通过带有可学习的offset的卷积核,来学习带有形变的物体。可变卷积的v2版本,也就是本论文中使用的版本,又做了两个改进:一是在特征提取网络中加入了更多的deformable convolution,二是在可变卷积的计算中又加入了权重(modulation),同样是可学习的,可以使可变卷积更好地学到感兴趣区域。这一点对于本文的鱼眼相机拍摄的形变物体的识别非常有帮助。
四、不仅使用了前向warp,即t0帧作为target,t-1和t+1帧作为source,还是用了后向warp,即t0帧作为source,t-1和t+1帧作为target,这个操作提高了计算量,延长了训练时间,但得到了更好的结果。
五、使用了交叉一致性loss,即第t帧输出的深度图与t'帧重构t帧得到的深度图应该趋于一致,反之亦然,用公式表达即:
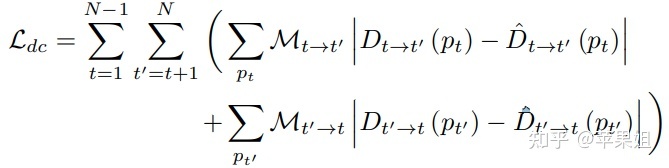
其他处理如动态目标mask、带边缘的平滑处理、多尺度loss等与monodepth2类似。总的损失表示如下:(前两项代表前向和后向warp)
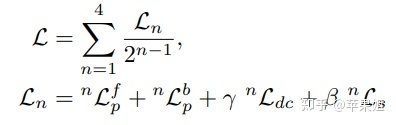
二、推广到畸变广角:UnRectDepthNet(2020)
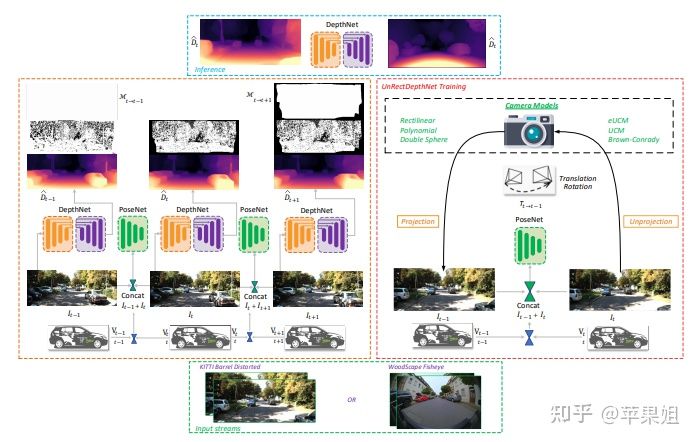
这篇文章旨在将fisheyedistancenet的成果推广到一般相机模型,并做出了一些尝试。作者指出,在自动驾驶实际应用中,所用到的相机大多是带畸变的,包括FOV100°左右的前视广角,和FOV190°左右的鱼眼相机,畸变都非常严重。一个通常的做法是对畸变图像进行校正和裁剪,但校正会带来更多的问题,一是分辨率的损失和FOV的下降,失去了原本使用这些大FOV相机的意义,二是在warp过程中使用的插值方法也会带来误差,三是校正本身要消耗时间和资源,且校正之后非常依赖标定参数,标定参数容易随温度等客观环境变化,很难大规模应用。所以作者希望直接在未校正的原始图像上做深度估计,得到更加实用的结果。但因为各种相机的模型不相同,所以需要设计一个通用的泛化网络支持不同的照相机模型。
作者提到一个最接近的工作是2019年的Cam-Convs,来自于以下论文:
[8] CAM-Convs: Camera-Aware Multi-Scale Convolutions for Single-View Depth (CVPR 2019)
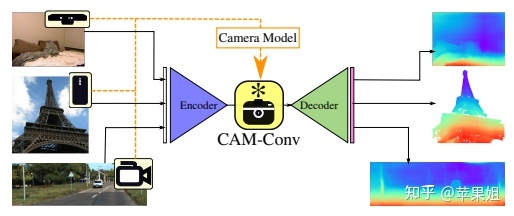
虽然这篇文章没有用到,但是后文的一个重要基础,在此也介绍一下。基本思想是使用与照相机参数相关的卷积层(这些信息相当于照相机的“元数据”,通过将元数据构造成与输入格式一致的伪图像来学习其特征),通过多尺度的连接,实现泛化到一般照相机模型的通用深度估计网络。cam-convs的前身来自于CoordConv:
主要思想是在输入中额外加入两个通道--分别代表图像的横、纵坐标(也可以根据需要加入其他位置信息),如下图所示:

普通卷积的一个基本特性是平移不变性,卷积核并不能感知自身的位置,而加入坐标信息以后,既可以保留平移不变性(学习到的坐标channel权重为0的情况),又可以学习到平移依赖性(学习到的坐标channel权重不为0的情况),对于具有平移依赖性的下游任务有较好的作用,也能解决普通卷积在坐标映射任务中的缺陷。
Cam-convs中则加入了六个通道:
中心化的x、y坐标通道(照相机的光轴中心坐标点为原点):
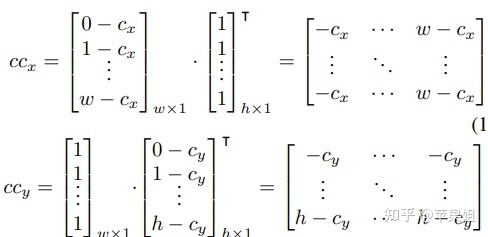
FOV maps(视场图,分为x、y通道,可以通过相机焦距计算出每个像素的方位角和仰角):
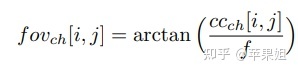
还有归一化的x、y坐标通道,这相当于学习到了相机内参中的几个要素:焦距和光心偏移。然后通过多尺度的连接、监督的损失(包括depth损失、法向量损失、梯度损失、置信度损失等)进行训练。此方法在本文第五部分(SVDistNet)中有进一步的扩展应用。
回到UnRectDepthNet,作者指出cam-convs不能处理非线性的畸变,同时也是一个监督的方法。所以作者还是采用了经典的投影模型来处理不同的相机。
针对适度 FOV 的一般广角相机透镜模型(FOV<120°)一般使用 Brown–Conrady 模型,因为该模型同时建模了径向畸变和切向畸变:
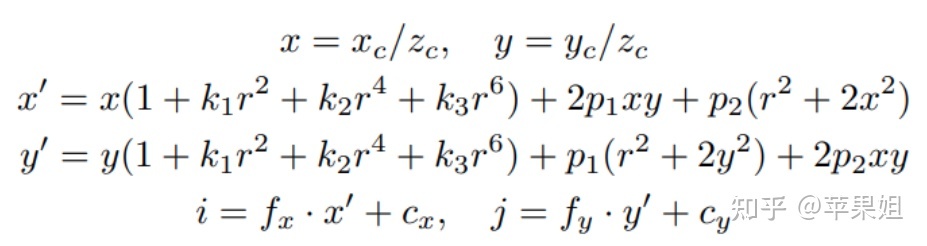
Brown–Conrady投影模型
鱼眼相机的透镜模型(FOV>=180°)需要一个径向分量 r(θ),主要模型如下:
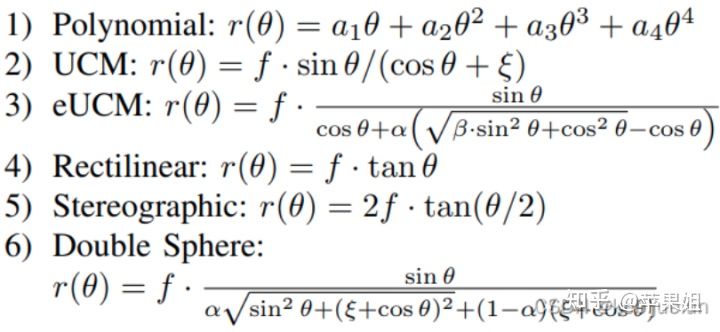
其他用的图片重构、损失函数、尺度恢复等都和FisheyeDistanceNet类似,但可以同时支持多种相机模型,在KITTI和WoodScape上都有较好的测试结果。但目前一次训练只能支持一个数据集的输入,作者指出未来的方向是将训练框架扩展为同时支持多路相机的输入,然后输出一个通用的推理模型。
三、FisheyeDistanceNet增强版:FisheyeDistanceNet++(2021)

FisheyeDistanceNet++从名字上看就是对FisheyeDistanceNet的增强,并允许四路鱼眼相机的输入,训练同一个模型。主要体现在以下四个方面:
一、鲁棒损失(robust loss function)的引入
鲁棒损失的概念来源于以下论文:
[11] A general and adaptive robust loss function (CVPR 2019)
对于L1,L2以及各种损失函数,文中提出了一种广义的损失函数形式:
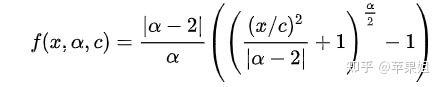
其中α控制损失函数的鲁棒性。c可以看作是一个尺度参数,在x=0附近控制弯曲的尺度。对于α的不同值,损失函数表现如下:

广义损失函数的概率密度表达形式:
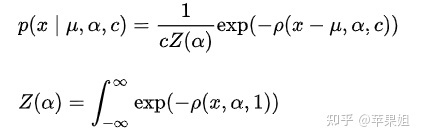
将该广义损失函数的负对数形式(NLL)作为损失函数,允许将视作一个参数,进而使得网络自己去学习到合适的。而且该损失函数具有单调性、平滑性、一阶二阶梯度有界性。实验证明NLL的使用对于精度提升有促进作用。
二、使用stand-alone self-attention模块作为encoder
stand-alone self-attention出自以下论文:
[12] stand-alone self-attention in vision models (CVPR 2019) (CVPR 2019)
从attention机制的原始论文:attention is all you need 中我们知道,attention机制相比卷积神经网络可以更好地使用全局信息,增大感受野。一般形式如下:
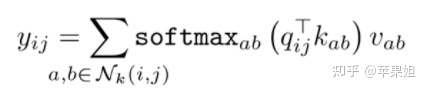
而stand-alone self-attention进一步证明了attention机制可以完全替代CNN,在视觉任务中达到理想的效果。同时这篇文章中用嵌入向量(r)来表示相对位置,保留了像素之间的相对位置信息,形式如下:
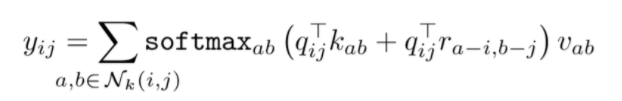
实验证明,该机制的引入也对结果的提升作用明显。
三、在encoder head中使用了instance normalization,保留了decoder中的batch normalization,进一步提高了准确度。
一般使用的batch normalization是一个batch内所有图片的同一通道一起做normalization,而instance normalization是指单张图片的单个通道独立做normalization。通过对比试验验证了instance normalization层的有效性。
四、用多个相机数据训练出一个通用的模型。但文中未提及多个相机之间的关联性。
后文请继续阅读下篇:
从鱼眼到环视到多任务王炸——盘点Valeo视觉深度估计经典文章(从FisheyeDistanceNet到OmniDet)(下))














 2895
2895











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









