







模型 & 价格
下表所列模型价格以“百万 tokens”为单位。Token 是模型用来表示自然语言文本的的最小单位,可以是一个词、一个数字或一个标点符号等。我们将根据模型输入和输出的总 token 数进行计量计费。
模型 & 价格细节
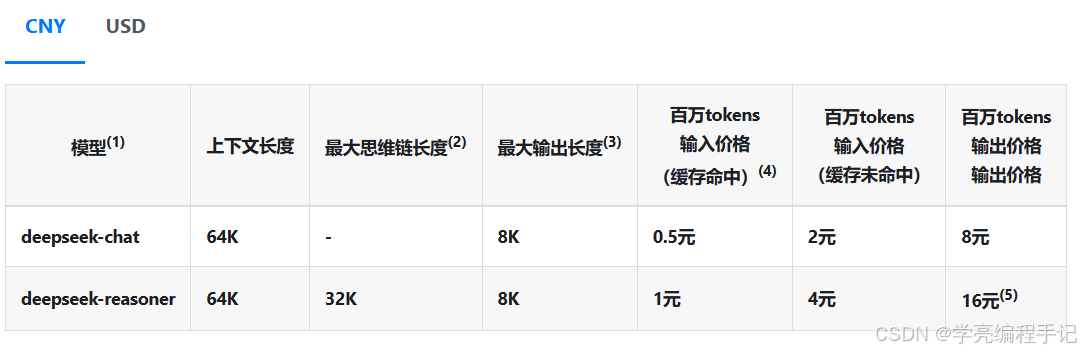
deepseek-chat模型已经升级为 DeepSeek-V3;deepseek-reasoner模型为新模型 DeepSeek-R1。- 思维链为
deepseek-reasoner模型在给出正式回答之前的思考过程,其原理详见推理模型。 - 如未指定
max_tokens,默认最大输出长度为 4K。请调整max_tokens以支持更长的输出。 - 关于上下文缓存的细节,请参考DeepSeek 硬盘缓存。
deepseek-reasoner的输出 token 数包含了思维链和最终答案的所有 token,其计价相同。
扣费规则
扣减费用 = token 消耗量 × 模型单价,对应的费用将直接从充值余额或赠送余额中进行扣减。 当充值余额与赠送余额同时存在时,优先扣减赠送余额。
产品价格可能发生变动,DeepSeek 保留修改价格的权利。请您依据实际用量按需充值,定期查看此页面以获知最新价格信息。
名词解释
token
解释:
- Tokens 是模型处理文本的基本单位,可以是单词、字符或子词。例如,英文中一个单词通常是一个 token,中文中一个字符通常是一个 token。
- 百万 tokens 是指模型处理了 100 万个 tokens 的文本。
理解:
- 模型价格以“百万 tokens”为单位 意味着费用是根据模型处理的 tokens 数量计算的,每 100 万个 tokens 收费一次。
- 每次会话 可能涉及多个 tokens,具体数量取决于会话内容的长度。因此,每次会话的费用取决于实际处理的 tokens 数量,而不是以会话次数为单位。
总结:
模型价格以“百万 tokens”为单位,费用基于实际处理的 tokens 数量,而不是每次会话。
关于中文汉字
在中文中,每个汉字通常被视为一个token。这是因为大多数现代语言模型(如GPT系列)在处理中文时,会将每个汉字作为一个独立的token进行处理。
不过,具体的tokenization(分词)方式可能因模型和使用的tokenizer(分词器)而有所不同。以下是一些需要注意的细节:
-
汉字作为独立token:大多数情况下,每个汉字会被当作一个token。例如,“你好”会被分成两个token:“你”和“好”。
-
特殊字符和标点符号:标点符号(如“,”“。”)通常也会被当作独立的token。
-
罕见字或特殊词汇:某些罕见字或特殊词汇可能会被进一步拆分,具体取决于tokenizer的实现。例如,一些tokenizer可能会将复杂的词汇拆分为子词(subword)或字节对编码(BPE)。
-
模型差异:不同的模型可能使用不同的tokenizer。例如,GPT-3和GPT-4使用的tokenizer对中文的处理方式可能略有不同,但总体上仍然是以单个汉字为基本单位。
示例
- 句子:“我喜欢学习人工智能。”
- Tokenization结果:[“我”, “喜”, “欢”, “学”, “习”, “人”, “工”, “智”, “能”, “。”]
总结
在大多数情况下,每个汉字会被视为一个token,但具体的tokenization结果可能会因模型和tokenizer的实现而有所不同。如果需要精确计算tokens数量,可以使用模型提供的tokenizer工具进行测试。
输入token和输出token
对于 DeepSeek 模型(以及其他大多数按 token 计费的模型),输入和输出的 token 都是单独计费的。这意味着:
- 输入 token:你发送给模型的请求内容(例如问题或提示)会被计算为输入 token。
- 输出 token:模型生成的回复内容会被计算为输出 token。
计费规则
- 输入和输出 token 的总和 会被计入费用。例如,如果你的输入是 100 个 token,模型的输出是 150 个 token,那么本次请求的总 token 数为 250,费用会基于 250 个 token 计算。
- 按实际使用量计费:DeepSeek 的计费通常是按“百万 token”为单位,因此费用会根据实际使用的 token 数量累加。
示例
假设你向 DeepSeek 提出以下问题:
- 输入内容:“请解释一下人工智能的发展历程。”(假设这句话有 20 个 token)
- 模型回复:“人工智能的发展经历了以下几个阶段……”(假设回复有 80 个 token)
那么,本次请求的总 token 数为 20(输入) + 80(输出) = 100 个 token,费用会基于这 100 个 token 计算。
注意事项
- 输入和输出的 token 都会被计费,因此在设计请求时,尽量保持输入简洁,避免不必要的冗余内容。
- 输出长度控制:如果需要控制费用,可以通过设置参数(如
max_tokens)限制模型生成的最大 token 数量。 - token 计算工具:如果你需要精确计算 token 数量,可以使用 DeepSeek 提供的 tokenizer 工具或 API 来测试输入和输出的 token 数量。
总结
对于 DeepSeek,输入和输出的 token 都是单独计费的,费用基于两者之和计算。合理设计输入内容和控制输出长度,可以有效优化成本。
长度单位
上下文长度 64k 中的 k 并不是指字节单位,而是指 token 的数量。具体来说:
- 64k 表示 64,000 个 tokens。
- 上下文长度 是指模型在一次请求中能够处理的 输入和输出的 tokens 总数。
详细解释
-
上下文长度(Context Length):
- 这是指模型能够处理的 最大 tokens 数量,包括输入(用户发送的请求)和输出(模型生成的回复)。
- 例如,如果上下文长度是 64k,那么输入和输出的 tokens 总数不能超过 64,000。
-
k 的含义:
- 在计算机科学中,k 通常表示 千(kilo),即 1,000。
- 因此,64k 表示 64,000 个 tokens,而不是 64,000 字节。
-
token 与字节的区别:
- token 是模型处理文本的基本单位,通常是一个单词、一个字符或一个子词。
- 字节(Byte) 是计算机存储的基本单位,1 个字节通常可以存储一个英文字符(UTF-8 编码下),而中文字符通常需要 2-4 个字节。
- 因此,64k tokens 并不等同于 64k 字节,而是指 64,000 个 tokens。
示例
假设你向模型发送以下请求:
- 输入内容:“请解释一下人工智能的发展历程。”(假设这句话有 20 个 tokens)
- 模型回复:“人工智能的发展经历了以下几个阶段……”(假设回复有 80 个 tokens)
那么,本次请求的 上下文长度 使用了 20(输入) + 80(输出) = 100 个 tokens,远低于 64k 的限制。
注意事项
-
上下文长度的限制:
- 如果输入和输出的 tokens 总数超过 64k,模型将无法处理完整的请求。
- 如果需要处理更长的文本,可以将文本分段发送,或者使用支持更长上下文长度的模型。
-
token 与字节的换算:
- 虽然 token 和字节没有直接的换算关系,但通常来说,1 个英文 token 大约等于 1-4 个字节,1 个中文 token(一个汉字)大约等于 2-4 个字节。
总结
上下文长度 64k 指的是模型能够处理的 最大 tokens 数量,即 64,000 个 tokens,而不是 64,000 字节。理解这一点有助于更好地设计请求,避免超出模型的上下文长度限制。
links



















 142
142

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











