







版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
本文链接:https://blog.csdn.net/dss_dssssd/article/details/83892824
本文主要讲述最简单的线性回归函数:
y=wx+b y=wx+b
y=wx+b
在pytorch的实现,主要包括神经网络实现的基本步骤和nn.Linear的源码解读。
1. nn.Linear 源码解读
先看一下Linear类的实现:
源代码网址:https://pytorch.org/docs/stable/_modules/torch/nn/modules/linear.html
Linear继承于nn.Module,内部函数主要有__init__,reset_parameters, forward和extra_repr函数
__init__(self, in_features, out_features, bias=True)
in_features:前一层网络神经元的个数
out_features: 该网络层神经元的个数
以上两者决定了weight的形状[out_features , in_features]
bias: 网络层是否有偏置,默认存在,且维度为[out_features ],若bias=False,则该网络层无偏置。
接下来看一下,输入该网络层的形状(N, *, in_features),其中N为批量处理过成中每批数据的数量,*表示,单个样本数据中间可以包含很多维度,但是单个数据的最后一个维度的形状一定是in_features.
经过该网络输出的形状为(N, *, out_features),其中计算过程为:
[N,∗,in_features]∗[out_features,in_features]T=[N,∗,out_features] [N, *, in\_{features}] * {[out\_{features }, in\_{features}]}^T = [N, *, out\_{features}]
[N,∗,in_features]∗[out_features,in_features]
T
=[N,∗,out_features]
接下来在看一下Linear包含的属性:
从__init__函数中可以看出Linear中包含四个属性
in_features: 上层神经元个数
out_features: 本层神经元个数
weight:权重, 形状[out_features , in_features]
bias: 偏置, 形状[out_features]
reset_parameters(self)
参数初始化函数
在__init__中调用此函数,权重采用Xvaier initialization 初始化方式初始参数。
forward(self, input)
在Module的__call__函数调用此函数,使得类对象具有函数调用的功能,同过此功能实现pytorch的网络结构堆叠。
具体实现方式请看下面两篇博客:
https://blog.csdn.net/dss_dssssd/article/details/83750838
https://blog.csdn.net/dss_dssssd/article/details/82977170
在自己写自己的类结构是,继承于Module,然后主要实现__init__函数和forward函数即可,至于可能的参数初始化方式,在后面的文章中会讲到,在这只是用默认的初始化方式。
2. 结合代码讲解神经网络实现的基本步骤
准备数据
定义网络结构model
定义损失函数
定义优化算法 optimizer
训练
准备好tensor形式的输入数据和标签(可选)
前向传播计算网络输出output和计算损失函数loss
反向传播更新参数
以下三句话一句也不能少:
将上次迭代计算的梯度值清0
optimizer.zero_grad()
反向传播,计算梯度值
loss.backward()
更新权值参数
optimizer.step()
保存训练集上的loss和验证集上的loss以及准确率以及打印训练信息。(可选
图示训练过程中loss和accuracy的变化情况(可选)
在测试集上测试
3. Linear_Regression代码解读
import torch
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt
# Hyper-parameters 定义迭代次数, 学习率以及模型形状的超参数
input_size = 1
output_size = 1
num_epochs = 60
learning_rate = 0.001
# Toy dataset 1. 准备数据集
x_train = np.array([[3.3], [4.4], [5.5], [6.71], [6.93], [4.168],
[9.779], [6.182], [7.59], [2.167], [7.042],
[10.791], [5.313], [7.997], [3.1]], dtype=np.float32)
y_train = np.array([[1.7], [2.76], [2.09], [3.19], [1.694], [1.573],
[3.366], [2.596], [2.53], [1.221], [2.827],
[3.465], [1.65], [2.904], [1.3]], dtype=np.float32)
# Linear regression model 2. 定义网络结构 y=w*x+b 其中w的size [1,1], b的size[1,]
model = nn.Linear(input_size, output_size)
# Loss and optimizer 3.定义损失函数, 使用的是最小平方误差函数
criterion = nn.MSELoss()
# 4.定义迭代优化算法, 使用的是随机梯度下降算法
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
loss_dict = []
# Train the model 5. 迭代训练
for epoch in range(num_epochs):
# Convert numpy arrays to torch tensors 5.1 准备tensor的训练数据和标签
inputs = torch.from_numpy(x_train)
targets = torch.from_numpy(y_train)
# Forward pass 5.2 前向传播计算网络结构的输出结果
outputs = model(inputs)
# 5.3 计算损失函数
loss = criterion(outputs, targets)
# Backward and optimize 5.4 反向传播更新参数
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 可选 5.5 打印训练信息和保存loss
loss_dict.append(loss.item())
if (epoch+1) % 5 == 0:
print ('Epoch [{}/{}], Loss: {:.4f}'.format(epoch+1, num_epochs, loss.item()))
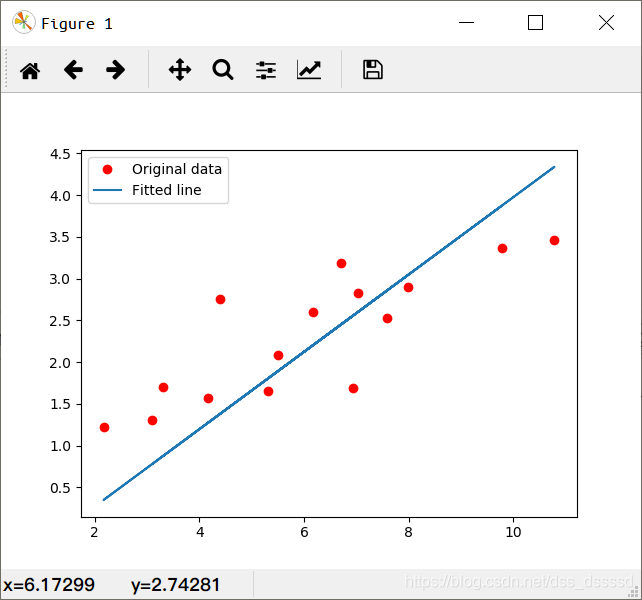
# Plot the graph 画出原y与x的曲线与网络结构拟合后的曲线
predicted = model(torch.from_numpy(x_train)).detach().numpy()
plt.plot(x_train, y_train, 'ro', label='Original data')
plt.plot(x_train, predicted, label='Fitted line')
plt.legend()
plt.show()
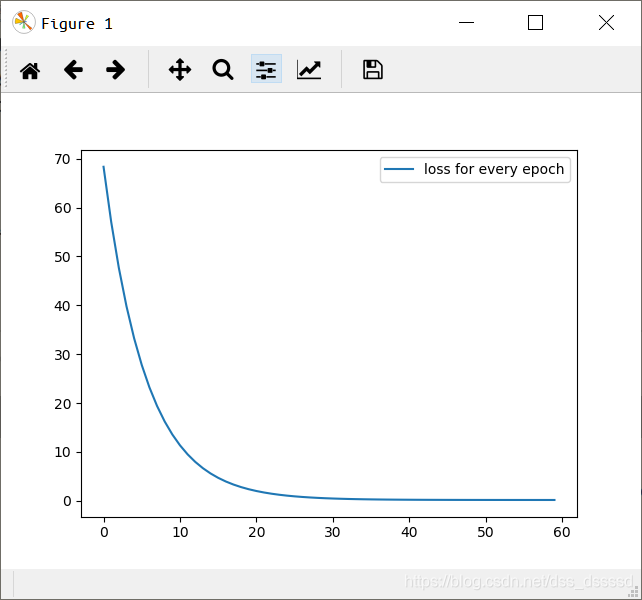
# 画loss在迭代过程中的变化情况
plt.plot(loss_dict, label='loss for every epoch')
plt.legend()
plt.show()
训练结果:
每次迭代的损失函数
Epoch [5/60], Loss: 1.8269
Epoch [10/60], Loss: 0.9979
Epoch [15/60], Loss: 0.6616
Epoch [20/60], Loss: 0.5250
Epoch [25/60], Loss: 0.4693
Epoch [30/60], Loss: 0.4463
Epoch [35/60], Loss: 0.4366
Epoch [40/60], Loss: 0.4322
Epoch [45/60], Loss: 0.4301
Epoch [50/60], Loss: 0.4288
Epoch [55/60], Loss: 0.4279
Epoch [60/60], Loss: 0.4271
————————————————
版权声明:本文为CSDN博主「墨氲」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/dss_dssssd/article/details/83892824














 11万+
11万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









