







Fully Convolutional Networks for Semantic Segmentation
全卷积网络首现于这篇文章。这篇文章是将CNN结构应用到图像语义分割领域并取得突出结果的开山之作,因而拿到了CVPR 2015年的best paper.
图像语义分割,简而言之就是对一张图片上的所有像素点进行分类

如上图就是一个语义分割的例子,不同的颜色代表不同的类别
下面简单介绍一下论文,重点介绍文中的那几个结构:
一.论文解读
1.Introduction
CNN这几年一直在驱动着图像识别领域的进步。无论是整张图片的分类(ILSVRC),还是物体检测,关键点检测都在CNN的帮助下得到了非常大的发展。但是图像语义分割不同于以上任务,这是个空间密集型的预测任务,换言之,他需要预测一幅图像中所有像素点的类别。
以往的用于语义分割的CNN,每个像素点用包围其的对象或区域类别进行标注,但是这种方法不管是在速度上还是精度上都有很大的缺陷。
本文提出了全卷积网络(FCN)的概念,针对语义分割训练一个端到端,点对点的网络,达到了state-of-the-art。这是第一次训练端到端的FCN,用于像素级的预测;也是第一次用监督预训练的方法训练FCN。
2.Fully Convolutional networks & Architecture
下面我们重点看一下FCN所用到的三种技术:
1.卷积化(convolutionalization)
分类所使用的网络通常会在最后连接全连接层,它会将原来二维的矩阵(图片)压缩成一维的,从而丢失了空间信息,最后训练输出一个标量,这就是我们的分类标签。
而图像语义分割的输出需要是个分割图,且不论尺寸大小,但是至少是二维的。所以,我们丢弃全连接层,换上卷积层,而这就是卷积化了。
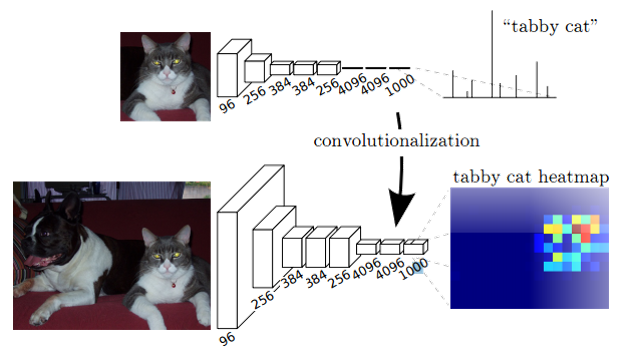
这幅图显示了卷积化的过程,图中显示的是AlexNet的结构,简单来说卷积化就是将其最后三层全连接层全部替换成卷积层
2.上采样(Upsampling)
上采样也就是对应于上图中最后生成heatmap的过程。
在一般的CNN结构中,如AlexNet,VGGNet均是使用池化层来缩小输出图片的size,例如VGG16,五次池化后图片被缩小了32倍;而在ResNet中,某些卷积层也参与到缩小图片size的过程。我们需要得到的是一个与原图像size相同的分割图,因此我们需要对最后一层进行上采样,在caffe中也被称为反卷积(Deconvolution),可能叫做转置卷积(conv_transpose)更为恰当一点。
为理解转置卷积,我们先来看一下Caffe中的卷积操作是怎么进行的
在caffe中计算卷积分为两个步骤:
1)使用im2col操作将图片转换为矩阵
2)调用GEMM计算实际的结果
这里举个简单的例子:4x4的输入,卷积Kernel为3x3, 没有Padding / Stride, 则输出为2x2

输入矩阵可展开为16维向量,记作x
输出矩阵可展开为4维向量,记作y
卷积运算可表示为y=Cx
不难想象C
其实就是如下的稀疏阵:
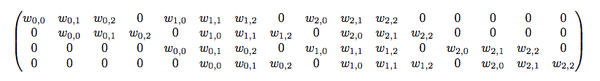
平时神经网络中的正向传播就是转换成了如上矩阵运算。
那么当反向传播时又会如何呢?首先我们已经有从更深层的网络中得到的.
根据矩阵微分公式,可推得
Caffe中的卷积操作简单来说就是这样,那转置卷积呢?
其实转置卷积相对于卷积在神经网络结构的正向和反向传播中做相反的运算。
所以所谓的转置卷积其实就是正向时左乘C^T,而反向时左乘(C^T)^T
,即C
的运算。
注:以上示例来自这个回答:如何理解深度学习中的deconvolution networks?
虽然转置卷积层和卷积层一样,也是可以train参数的,但是实际实验过程中,作者发现,让转置卷积层可学习,并没有带来performance的提升,所以实验中的转置卷积层的lr全部被置零了
注意:在代码中可以看出,为了得到和原图像size一模一样的分割图,FCN中还使用了crop_layer来配合deconvolution层
3.跳跃结构(Skip Architecture)
其实直接使用前两种结构就已经可以得到结果了,但是直接将全卷积后的结果上采样后得到的结果通常是很粗糙的。所以这一结构主要是用来优化最终结果的,思路就是将不同池化层的结果进行上采样,然后结合这些结果来优化输出,具体结构如下:
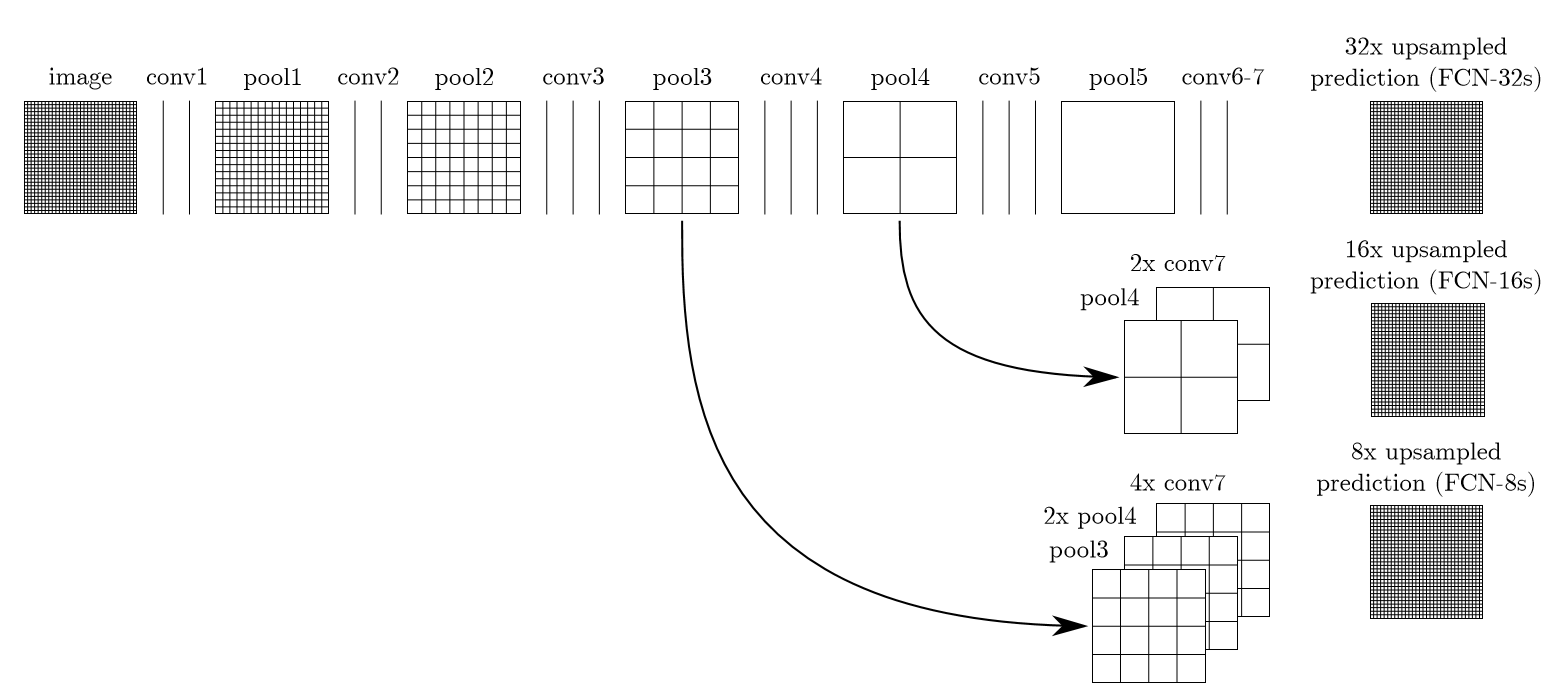
而不同的结构产生的结果对比如下:

二.实践
作者在github上开源了代码:Fully Convolutional Networks
git clone https://github.com/shelhamer/fcn.berkeleyvision.org.git
我们首先将项目克隆到本地
项目文件结构很清晰,如果想train自己的model,只需要修改一些文件路径设置即可,这里我们应用已经train好的model来测试一下自己的图片:
我们下载voc-fcn32s,voc-fcn16s以及voc-fcn8s的caffemodel(根据提供好的caffemodel-url),fcn-16s和fcn32s都是缺少deploy.prototxt的,我们根据train.prototxt稍加修改即可
略微修改infer.py,就可以测试我们自己的图片了
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
import caffe
# load image, switch to BGR, subtract mean, and make dims C x H x W for Caffe
im = Image.open('data/pascal/VOCdevkit/VOC2012/JPEGImages/2007_000129.jpg')
in_ = np.array(im, dtype=np.float32)
in_ = in_[:,:,::-1]
in_ -= np.array((104.00698793,116.66876762,122.67891434))
in_ = in_.transpose((2,0,1))
# load net
net = caffe.Net('voc-fcn8s/deploy.prototxt', 'voc-fcn8s/fcn8s-heavy-pascal.caffemodel', caffe.TEST)
# shape for input (data blob is N x C x H x W), set data
net.blobs['data'].reshape(1, *in_.shape)
net.blobs['data'].data[...] = in_
# run net and take argmax for prediction
net.forward()
out = net.blobs['score'].data[0].argmax(axis=0)
plt.imshow(out,cmap='gray');plt.axis('off')
plt.savefig('test.png')
plt.show()接下来,只需要修改script中的图片路径和model的路径,就可以测试自己的图片了:
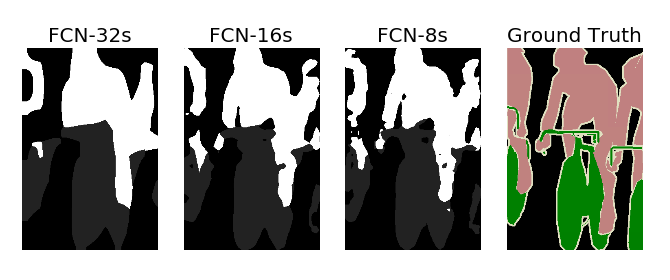
这是我跑出来的最终结果,可以看出skip architecture对最终的结果却是有优化作用。
这里没有对最终结果上色,按照VOC的颜色设置之后,就可以得到和论文中一模一样的结果了
下面是我测试自己图片的结果:

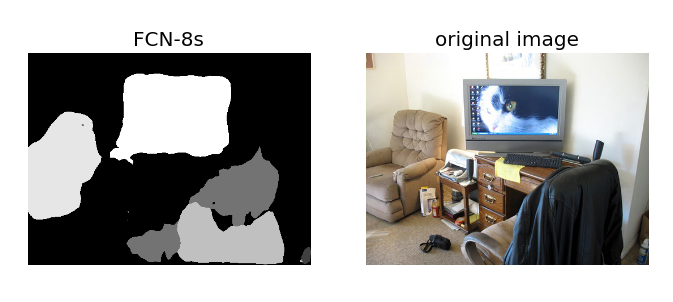
三.总结
图像语义分割可能是自动驾驶技术下一步发展的一个重要突破点,而且本身也特别有意思!借此机会也学习了一下Caffe计算卷积和转置卷积的过程,对语义分割也有了一个初步的了解,收获颇丰!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









