







1.成像系统的图像噪声
成像系统在获取画面时,经过传输、处理过程中往往会引入随机性变化或失真。噪声在图像上常表现为引起较强视觉效果的孤立像素点或像素块,像素值与真实场景或理想图像存在不符的随机扰动:

当噪声与原始信号无关时这类噪声称之为加性噪声:它们与信号的关系是相加,不管有没有信号该类噪声一直存在(简单理解为输入场景全黑时也会有噪声)。与原始信号有关的称作乘性噪声,信道不理想时噪声与信号的关系是相乘,即噪声与信号共存亡。
在常见的数码摄影系统中,真实场景画面到呈现在屏幕上的中间过程可以简单表示为:

镜头-传感器-ISP(图像信号处理)
光线首先通过镜头辐射到传感器上,由光电效应产生了电子,再经过传感器和ISP间的模拟电路放大器与模数转换将模拟电压转换为数字信号。不必要的扰乱信息(噪声)就在这个过程中产生,随后ISP与后端的算法处理进一步打乱噪声形态。
成像系统中,图像噪声根据其分布的数学模型和噪声特征主要分为以下几种:
1.1 高斯噪声
高斯噪声是概率密度函数服从高斯分布(即正态分布)的一类噪声,如果信号的幅值服从高斯分布,功率谱密度又是均匀分布的,则称它为高斯白噪声。
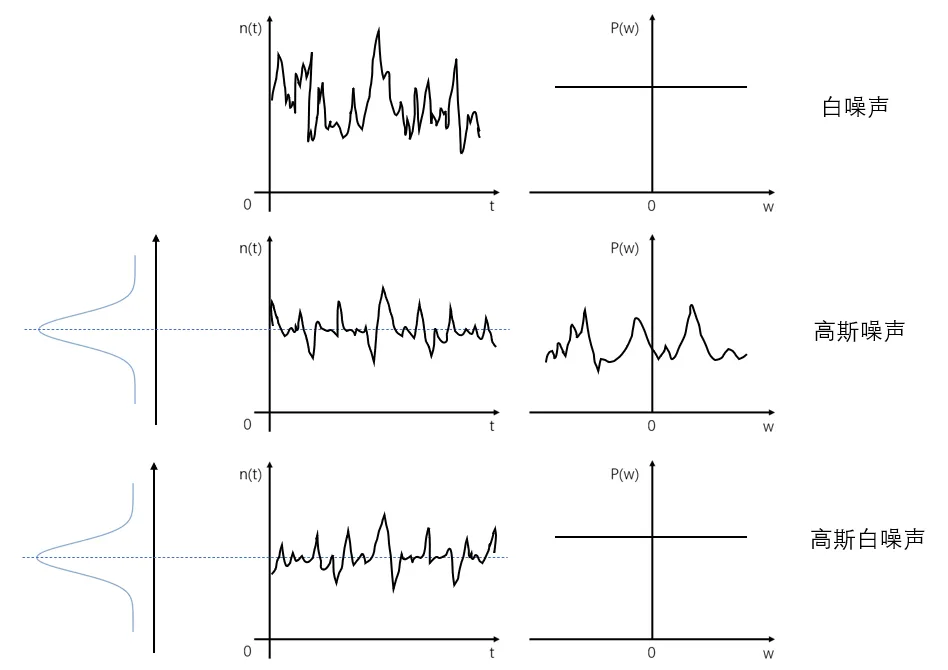
高斯分布:在均值附近的value出现概率更大,更接近真实世界中的随机现象。
产生原因主要有传感器长期工作,热度过高时的热噪声,以及电路各元器件自身噪声和相互影响。
1.2 泊松噪声
泊松噪声就是符合泊松分布的噪声模型,功率谱密度也是均匀分布的,所以也是一种白噪声。由于光的波粒二象性,击中传感器的光子数服从泊松分布,因此产生的电流电压也带有泊松噪声,也称为散粒噪声。除了光电发射过程,暗电流也会产生散粒噪声。
1.3 椒盐噪声
椒盐噪声又称脉冲噪声,是图像传感器传输信道和解码处理等产生的黑白相间的亮暗点噪声。
详细的传感器物理结构与更深入的噪声来源分析参考资料:
图像传感器基本结构及其噪声来源分析 - 知乎 (zhihu.com)
60. 数码相机成像时的噪声模型与标定 - 知乎 (zhihu.com)
2.如何对噪声进行建模
仅仅从已经被噪声污染的图像中恢复出干净图像是一个病态问题,因此提前获取一些关于噪声形态、大小这类先验信息,可以提高去噪任务的效果,帮助我们选择合适的去噪算法以及去噪力度。
| 论文名称 | Github | 期刊 | 发表时间 |
|---|---|---|---|
| Optimal Inversion of the Generalized Anscombe Transformation for Poisson-Gaussian Noise | IEEE | 2012 | |
| Unprocessing Images for Learned Raw Denoising | https://github.com/timothybrooks/unprocessing | CVPR | 2019 |
| Practical Deep Raw Image Denoising on Mobile Devices | https://github.com/MegEngine/PMRID | ECCV | 2020 |
| A Physics-Based Noise Formation Model for Extreme Low-Light Raw Denoising | https://github.com/Vandermode/ELD | CVPR | 2020 |
| Rethinking Noise Synthesis and Modeling in Raw Denoising | https://github.com/zhangyi-3/noise-synthesis | ICCV | 2021 |
| Learnability Enhancement for Low-light Raw Denoising:Where Paired Real Data Meets Noise Modeling | https://github.com/megvii-research/PMN | TPAMI | 2022 |
2.1 Practical Deep Raw Image Denoising on Mobile Devices
(1)建立成像系统的高斯-泊松噪声模型,对sensor的噪声参数进行标定
(2)k-sigma变换抵消ISO(sensor gain成一个系数)对噪声level的影响
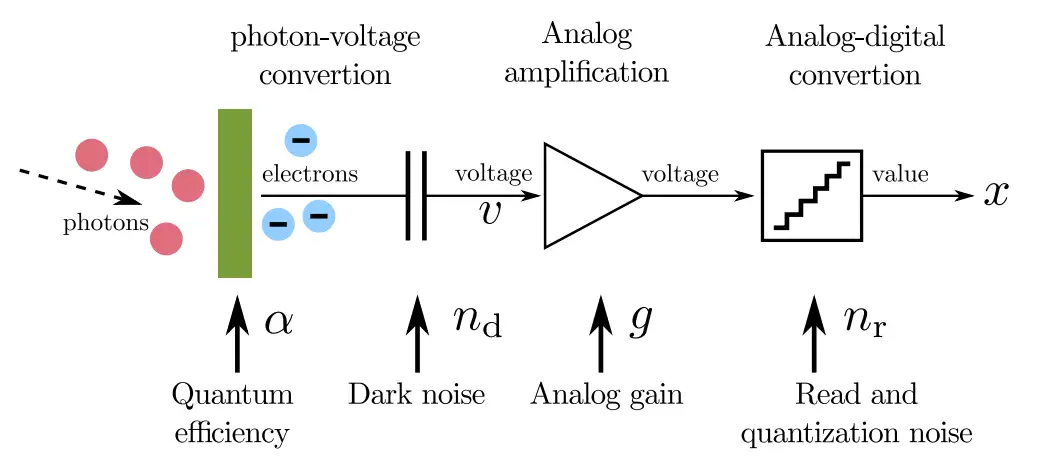
模型中光子数服从泊松分布,暗电流噪声nd和读出噪声nr服从高斯分布
光子数u符合泊松分布,经过光电转换α和sensor模拟增益g放大后,信号变为:

g就是sensor again,x*代表无噪声像素值
而暗电流噪声nd和读出噪声nr服从高斯分布,暗电流噪声会经过模拟增益g放大,加上公式(1)的分量信号变为:

把泊松分布和高斯分布表达式带进来,由此我们完成噪声模型的建立:
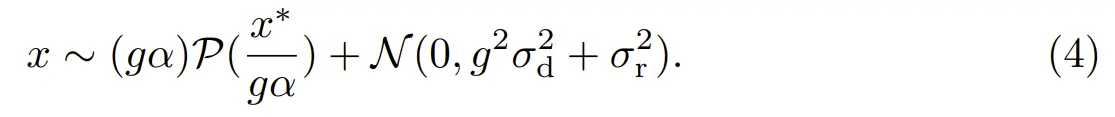
在拍摄不同场景时,sensor again(ISO)本身是会变化的,因此不需要标定g值。我们只需要知道α、σd、σr是多少,这样不同ISO下的噪声方差是什么情况就知道了。
高斯噪声参数标定:由于高斯噪声是加性噪声与信号大小无关并且均值为0,我们用成像系统在全黑情况下拍摄不同sensor again下的图像并计算其方差var,σd、σr就可以拟合出来(泊松噪声是乘性噪声,全黑的时候就等于0,因此就可以把高斯噪声隔离出来单独计算)。
泊松噪声参数标定:光电转换系数α对于一个sensor来说是固定的,那么方差和亮度是一个线性关系。我们取图卡上亮度为同一水平的像素点,将其均值当作理论亮度作为横坐标(拍多帧平均后排除高斯噪声,只存在泊松噪声),求其方差var作为纵坐标画出一条直线,其斜率即为gα。我们可以在不同g值下多次进行上述操作,最后拟合一个准确的α值。

泊松噪声标定图卡
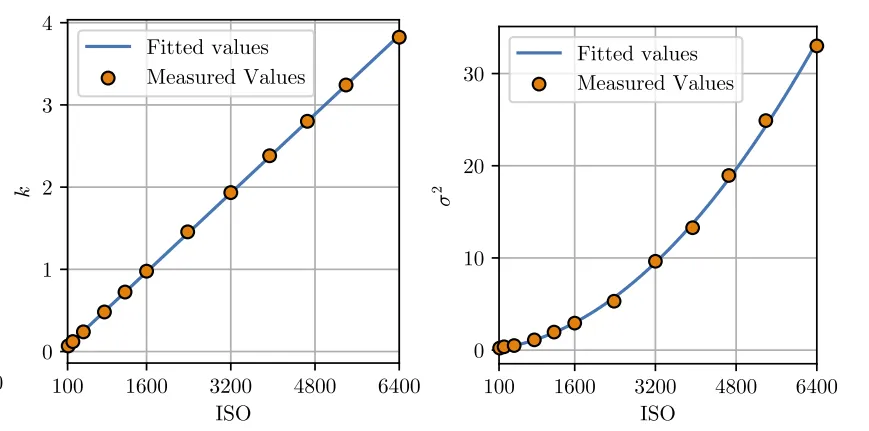
泊松与高斯标定的拟合曲线,这里k=αg,σ²包含暗电流噪声nd和读出噪声nr的方差
可以看到在不同的ISO(sensor again)下,噪声的方差水平是不同的。那一个成像系统在不同ISO下产生的噪声图像,自然要分别用不同降噪力度的算法进行处理。为了去掉ISO这个变量的约束,文中提出了k-sigma变换:
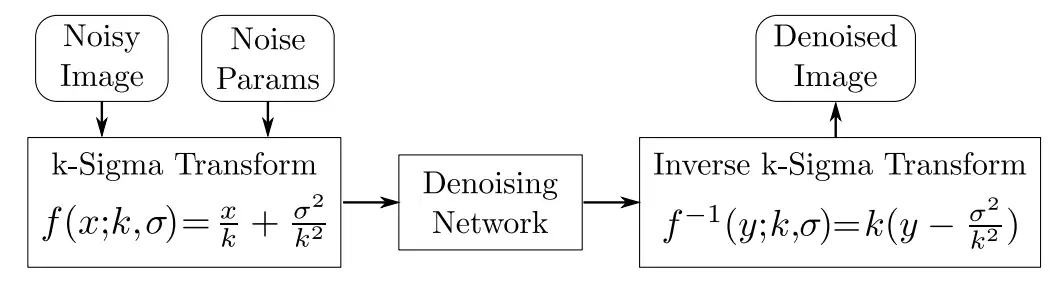
其实是将图像从ISO-dependent转成ISO-independent,最后不同ISO下图像噪声水平都是一样的
这里定义了一个线性模型(7),把噪声模型(5)带入(7)得到(8):
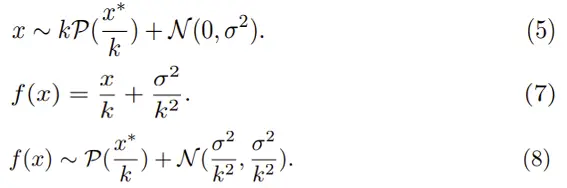
泊松分布近似成了一个高斯分布,这样每个ISO下的k和σ转换成了f(x):符合f(x*)的高斯分布。
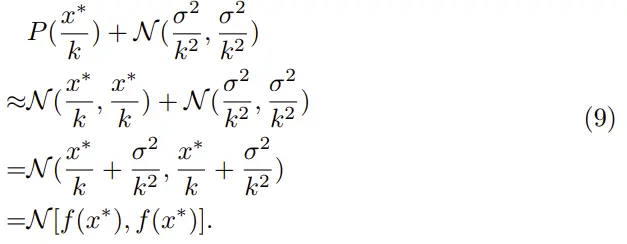
x对应于带有噪声的噪声数据,x*对应于没有噪声的干净数据,两者通过f()转换后,噪声图像值是符合干净图像值的高斯分布,两者与k、σ和ISO没有任何关系。通过一个统一的模型在变换域维度训练好参数后,输出再进行k-sigma逆变换得到干净的数据就行了。
k-sigma变换简化了不同ISO下要用不同降噪力度算法的繁琐,当然在不同ISO下的噪声标定自然还是要做的,逆变换仍然需要不同ISO下的k、σ值进行还原。
2.2 A Physics-Based Noise Formation Model for Extreme Low-Light Raw Denoising
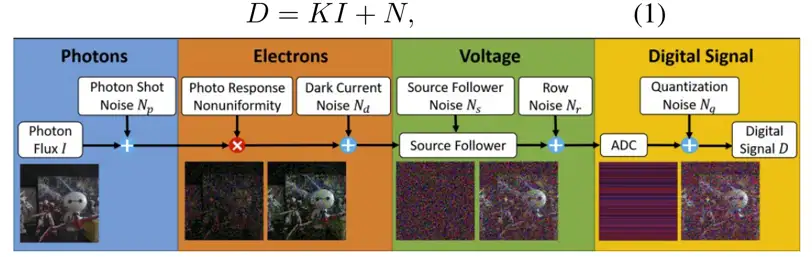
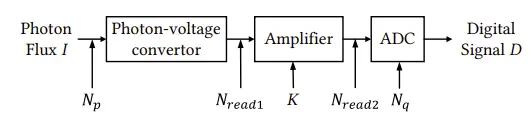
首先建立了干净图像到噪声图像的模型,光子数I经过sensor增益(again和dgain)放大,加上系统的所有噪声源N得到噪声模型表达式:
文中认为的噪声产生管线
详细来说,光子到电子的转换中考虑散粒噪声Np的影响,可以表示为泊松分布(2)。在电子到电压转换的阶段,光不均匀响应可以忽略,暗电流带来的噪声Nd与热噪声Nt以及源跟随噪声Ns一起作为读噪声Nread(3)。读噪声一般来说会用高斯分布表示,但实际数据有较严重的长尾分布,这里采用了TL(统计)分布来描述读噪声(4)。最后考虑了带状噪声,相关双采样基本可以消除列噪声,这里就只需要用高斯分布来模拟行噪声。在电压到数字信号转换阶段,ADC对信号的离散化带来的量化噪声Nq符合均匀分布(5),最终的噪声N表达式可以描述为(6)。
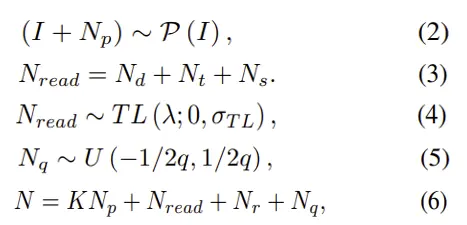
K:sensor gain、Np:散粒噪声、Nread:读噪声、Nr:行噪声、Nq:量化噪声
接下来就是参数的标定过程,主要会通过拍摄Flat-field帧和bias帧分别去标定乘性噪声Np和加性噪声(Nread、Nr、Nq)。
光子散粒噪声参数标定:
与2.1泊松参数标定思想类似,在不同曝光时间下,通过拍摄Flat-field明场图像(纯白图卡),计算两张图像的均值和方差,两点拟合出全局系统增益K。当计算得到了增益K值要模拟加散粒噪声得过程时,根据公式(1)和(2)将D除以增益K还原回光子场I,施加泊松分布模拟噪声后再乘以K回到数字信号,这就从干净图像模拟出来了带光子散粒噪声的数字图像了。
读噪声参数标定:
bias帧是在无光环境下采用最短曝光时间拍摄的图像,通常在暗室中进行拍摄并且将相机镜头盖住,这样就可以去采集信号无关的噪声了。由于高斯分布无法模拟真实信号的长尾分布,这里采用零均值的Tukey lambda分布模拟读噪声(R代表相关程度,越大拟合越好):
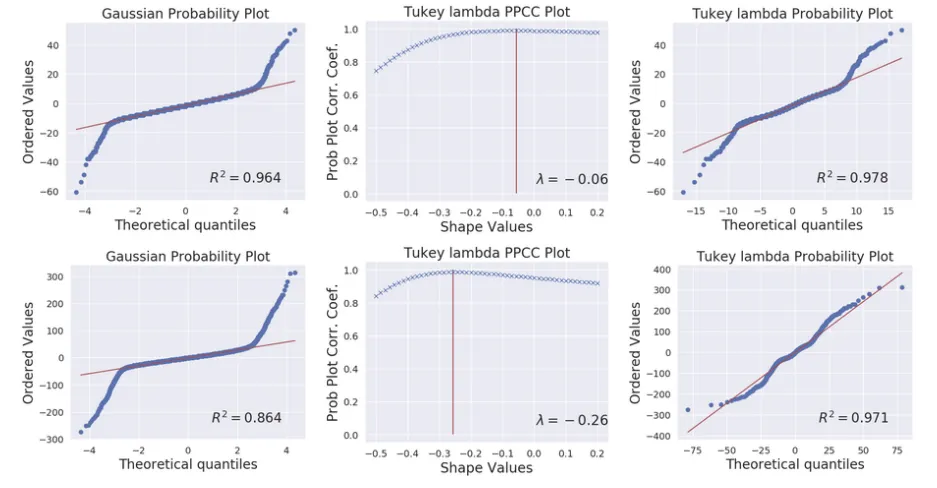
两行分别为sony和nikon相机的读噪声拟合曲线:高斯分布拟合、PPCC搜索TL最佳参数λ、TL分布拟合
模型中的加性噪声源都是零均值性质,行噪声可以从bias帧中提取每一行的均值,估算方差参数。量化噪声符合均匀分布,就没有什么好说的了。

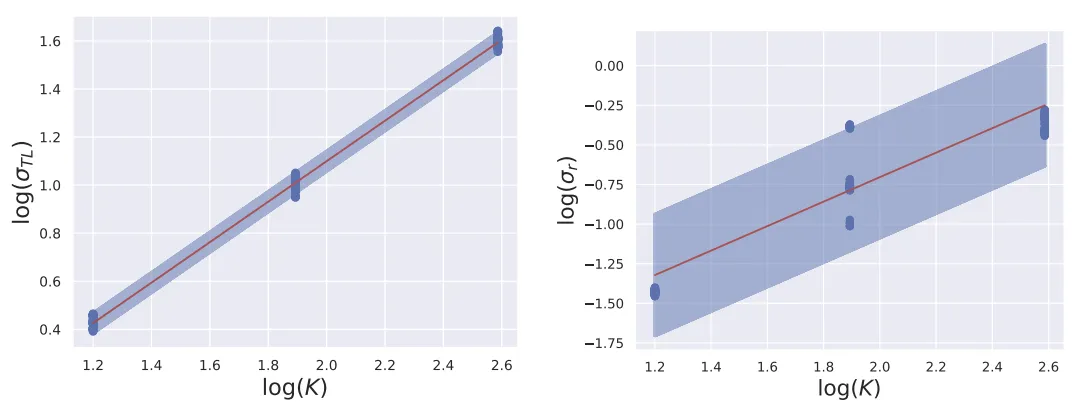
整体来说标定得到了参数K、σtl和σr,通过拟合一个联合分布,就可以适用所有ISO下的噪声建模:
2.3 Rethinking Noise Synthesis and Modeling in Raw Denoising
噪声建模和2.2 ELD基本差不多,K被细化为模拟和数字增益Ka、Kd,Np和Nq依然代表散粒和量化噪声。不同的是这里把增益间乱七八糟的一众噪声直接集合为N1和N2表示。
![]()
最终带噪的数字信号被分成了信号有关和信号无关的噪声:
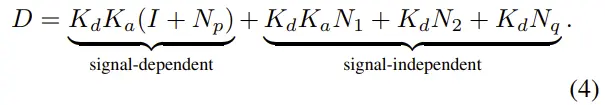
信号有关的泊松噪声标定还是与之前的方案一样(将D除以增益K还原回光子场I,施加泊松分布模拟噪声后再乘以K回到数字信号),而信号无关的噪声标定直接从不同ISO拍摄下的黑帧采样(每个ISO下10帧),非常的简洁:
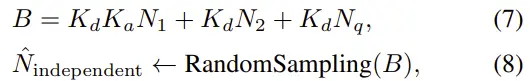
信号有关噪声依赖噪声建模,可以看成合成数据,而信号无关的噪声可以看成真实数据
但信号无关的噪音在低光场景中占主导,低光环境存在如下问题:
(1) 简单的独立信号噪声采样破坏了如行噪声、固定模式噪声(FPN)的空间相关性。
(2)暗帧被量化为低比特位(如10bit或14bit图像,低光环境增益很大,量化后噪声的精度就大幅下降了),破坏了自然的独立信号噪声分布。
本文的创新点就在下面的方案以提高低光环境噪声建模的准确性:
排布对齐块采样(pattern-aligned patch sampling)
采用了块采样方法,从构建的暗帧数据中采样出块图像来合成信号无关噪声,这样就保留了空间相关的噪声分布。另外bayer阵列的排布也需要考虑,所以提出了一个排布对齐的操作。
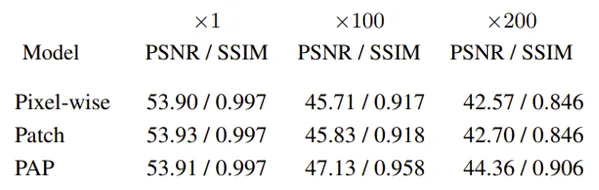
乘的越多约暗,可以看到在低光场景像素采样/块采样/排布对齐块采样效果逐步提升
高比特重建
理论上可以在传感器流程中的量化操作之前保存暗帧,或者存储如32比特位的暗帧以保留实际的信号,然而大多数CMOS传感器制造商不允许研究人员访问此类原始数据。本文提出了一种高比特重建方法,首先反向执行量化操作,然后合成高比特值来实现噪声精细化重建。
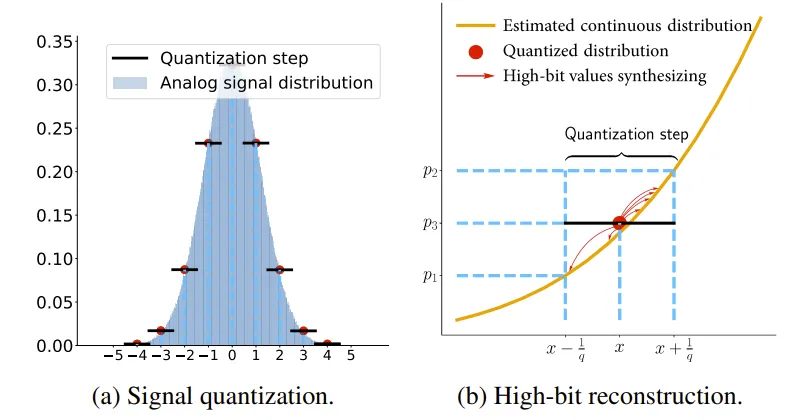
图a展示了每个量化步长内的具体情况。量化过程将一组位于[x-1/q, x+1/q]区间内的连续数值映射到单个数值x,压缩后收集到的暗帧具有较低的比特数。为了重构高比特暗帧,首先估算来自暗帧的低比特噪声的连续分布。如图b所示,根据估算出的连续分布,我们在每个量化步长[x-1/q, x+1/q]内为每一个低比特离散值x采样一个高比特值(32比特),并将采样的高比特值替换暗帧中的x。
2.4 Learnability Enhancement for Low-light Raw Denoising:Where Paired Real Data Meets Noise Modeling
这篇文章主要致力于在数据构造层面上提高数据映射的拟合和降低dark shading的干扰:
Shot Noise Augmentation (SNA)
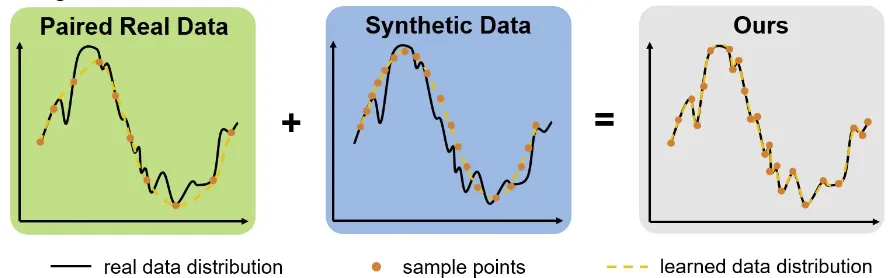
噪声建模理想化、真实数据数量少、FPN全局空间分布不一致等数据问题都会降低模型拟合效果,联合真实数据和噪声建模的合成数据可以构造泛化性更好的数据对,首先干净数据Dc经过噪声模型F得到噪声数据Dn:
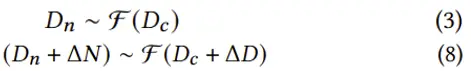
如果说我们想增加合成数据的数量在Dc上加些干净信号增量ΔD,由于信号有关的噪声分量只有泊松噪声并且泊松分布是有可加性的,最终的噪声信号也是会加一个噪声信号增量ΔN,带入噪声模型推导如下:
以上数据增广的方式应用的主要问题就是干净增量ΔD怎么设置,具体细节可以配合论文查看:

Dark Shading Correction (DSC)
另外作者发现对read noise复杂度影响很大的dark shading可以被稳定地分离,可以通过DSC降低模型复杂度并且减轻降噪后的偏色现象。
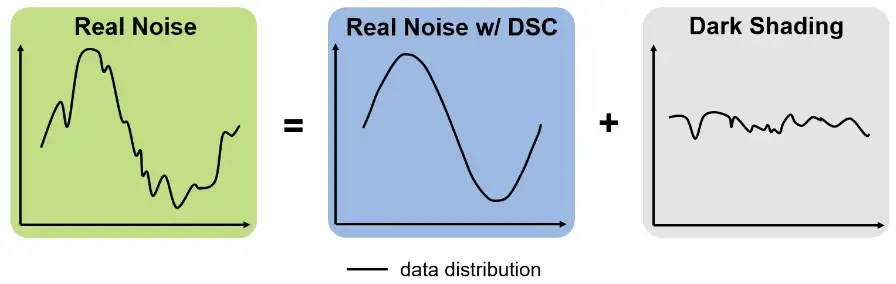
dark shading受到温度、暗电流等影响,代表raw数据上的不均匀分量(FPN和黑电平error)。实验表明由于dark shading值是比较稳定的,所以可以通过标定的方式进行建模:
![]()
dark shading模型中FPN设计成了K*ISO+B的形式,方便拟合全ISO段的数据也比较减轻工作量
Dds设计称了线性模型,是因为FPN可分为Dark Current FPN和Offset FPN,是存在可解释性的。通过不同ISO的多帧黑图平均,就可以标定出这个模型的系数:
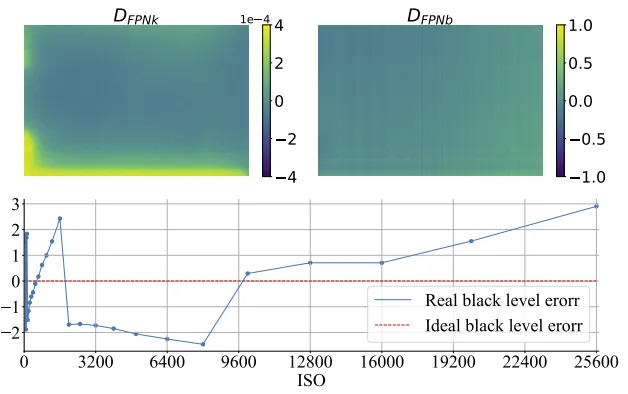
标定结果示例,Dfpn系数与ISO无关,Dblc与ISO有关
根据文中的实验结果,在SNA和DSC共同作用下,清晰度细节提升很明显:

2.5 Unprocessing Images for Learned Raw Denoising
前面的方案集中在传感器得到的raw数据噪声建模中,但通常我们并不能从成像系统中间节点取出raw数据,而只能得到经过ISP处理后的最后sRGB输出。raw域的噪声形态,经过ISP管线中大量的图像非线性操作后,在sRGB域就很难去建立合适的噪声模型了。为了解决这个问题, 这篇文章提出反转图像处理管线的每个步骤, 回归到raw域上进行噪声建模和去噪。

在这篇文章中raw域的噪声模型同样被分为散粒噪声和读噪声,分别符合泊松和高斯分布:
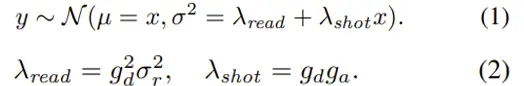
ga和gd分别为sensor 模拟增益again和数字增益dgain,这里把两种噪声统一到一个高斯分布下
ISP inverse的具体步骤这里不多做介绍,在raw域完成降噪后在正向回到sRGB域得到最终结果。
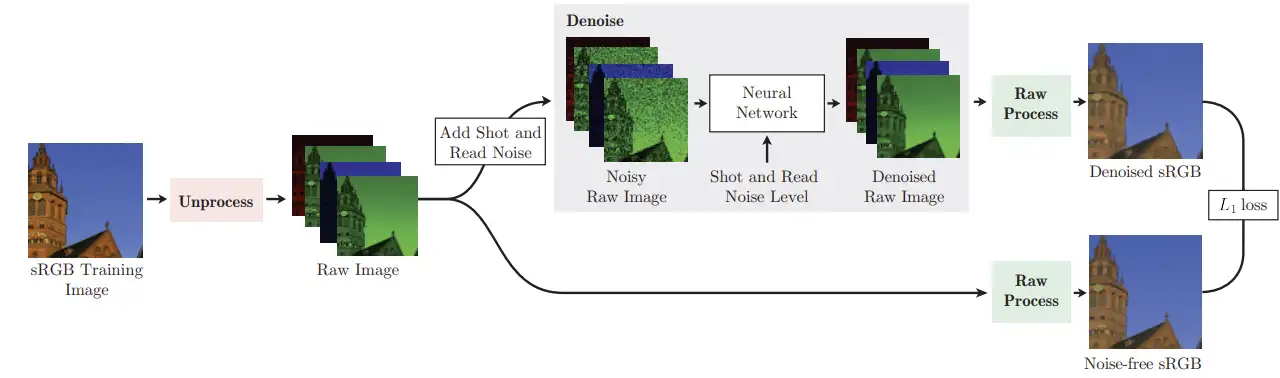
数据构造与降噪整体管线
文章整体思路是希望在计算Loss这一步让模型可以适应ISP的图像非线性操作,但实际应用中ISP模块模拟参数的准确性对最终效果应该影响还是很大,不同相机需要针对性设计不同ISP模块和参数,比较不稳定且难以落地。
3.图像去噪方法
与所有low level的图像画质任务一样,图像去噪分为传统和深度学习方法,这里仅简单进行介绍与罗列。
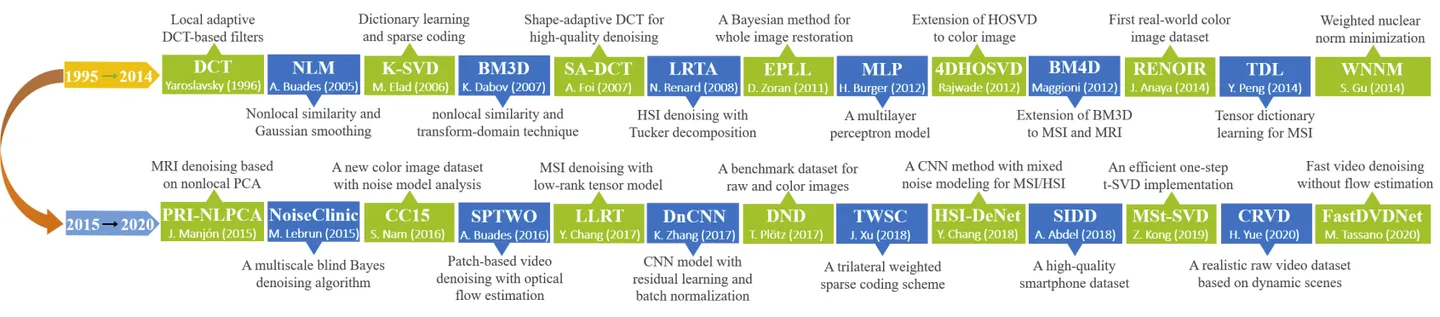
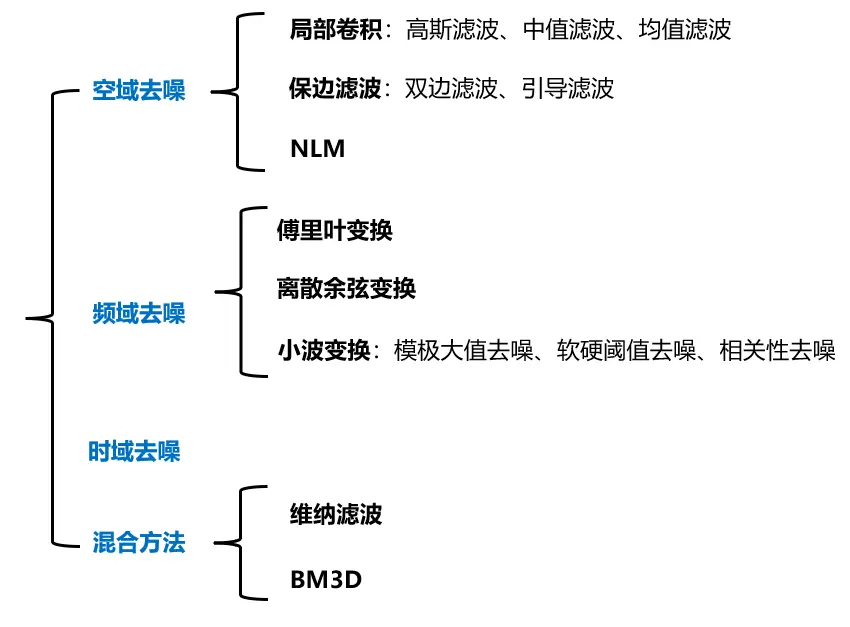
3.1 经典传统方法
空域降噪是在图像的像素维度进行处理,通过分析像素与其周围邻域的关系,尽可能地保留图像的细节和边缘信息的同时,让局部像素分布更加平滑。另外如Non-Local Means(NLM)算法利用图像长程相关性这种冗余信息(图像中远离彼此的像素之间可能存在某种统计上的相关性,即使这些像素在空间上并不相邻),以图像块为单位在邻域寻找相似块去除噪声,空域降噪这类算法往往都会要设置滤波半径r。
频域降噪将图像变换到频域,将不同频率的信号分离,根据噪声的频率特性进行一定的过滤就可以减少噪声。
时域降噪方法认为真实信号的连续帧之间通常存在着时间和空间上的关联,利用这种内在的相关性,通过比较前后帧的变化,可以识别并移除那些不属于真实信号变化的噪声部分。
混合方法即会在空域滤波也会在频域做处理,如维纳滤波和BM3D,他们有效地降低了噪声的同时保持了图像的细节。
图像降噪:频域与混合域去噪 - 知乎 (zhihu.com)
3.2 先验模型方法
这类方法会根据噪声或真实场景的特性,去设计一个先验的模型假设,通过建立约束进行优化得到干净的图像。
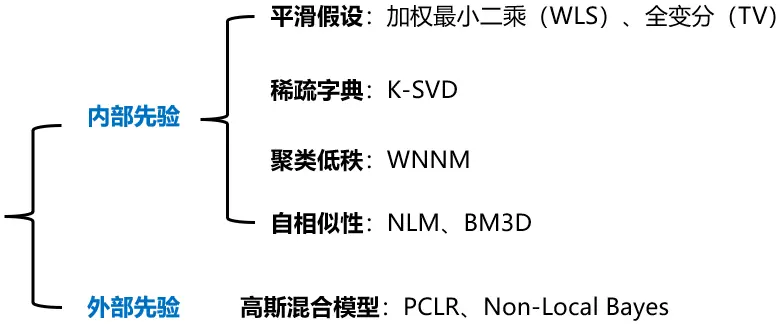
内部先验方法主要依赖于如低秩、稀疏、自相似等图像内部特征,噪声由于没有这类性质自然就可以从信号中过滤出去。稀疏表达方法认为自然图片总会在某一个模型下存在稀疏表达,将图像信号表示为一个过完备字典基向量的稀疏组合,通过优化问题寻找最优稀疏解来实现去噪的目的。从降噪的本质上来讲,稀疏表达的稀疏性和低秩聚类是具有一定相关性的,自然图像中非局部相似块形成的矩阵具有低秩性,并且具有稀疏的奇异值。内部先验类的算法通常需要复杂的优化方法,手动设置很多参数,泛化性并不理想。
外部先验方法没有从如何寻找特性区分干净图像和噪声角度思考,而是从干净的图像中寻找规律,通过学习外部干净图像数据集的信息指导噪声图像进行去噪,如高斯混合模型和概率论等方法,外部先验学习到的图像性质应用在噪声图像存在适应性不足问题。
图像降噪:几种最优化建模方案盘点 - 知乎 (zhihu.com)
3.3 深度学习方法
从开山鼻祖DnCNN开始,深度学习去噪领域从开始的魔改网络结构,逐渐变成如何根据噪声的属性设计不同网络结构,构造更符合真实场景的数据集。传统方法中的自相似性、局部全局信息组合、多尺度等思想,也会被纳入网络设计思考。

早期图像降噪任务训练使用的合成数据集,一般会在干净图像上加高斯白噪声构造图像对进行训练。为了能适应实际任务的噪声状况,通过噪声建模和噪声标定可以构造更符合特定成像系统的训练数据。
另外为了更符合真实世界图像去噪,也有相当多关于生成真实数据集的工作如:PolyU、SIDD等。

深度学习的去噪方法,目前在如何减少涂抹感、保留更多细节、减少artifact以及性能内存等问题上,依然会有一个很大的发展空间。
参考资料:
图像去噪开源数据集资源汇总 - 知乎 (zhihu.com)
[1912.13171] Deep Learning on Image Denoising: An overview (arxiv.org)
[2011.03462] A Comprehensive Comparison of Multi-Dimensional Image Denoising Methods (arxiv.org)
4.评价指标
从审美的角度来说,当拍摄一张照片或者对一张图片做了后期处理,我们并不知道原始理想的图像究竟应该长什么样子。因此只能主观上通过肉眼观察图像的噪声好坏,很难通过一个量化的指标去评价图像画质。在相机以及图像处理软件公司中,通常也会有图像评测工程师去衡量图像质量。
而学术上任务上评价一个去噪算法的好坏,由于有很多开源的真实图像-噪声图像数据集,而且我们也可以根据实际系统噪声情况设计自己的数据对,通过比较原始的真实图像信号和对加噪声图像去噪后的图像,就可以用客观指标去评价去噪后的图像与真实图像的接近程度了。
Mean Square Error(MSE)
MSE逐像素的比较两张图像的差异,值越小代表去噪后的图像与理想图像越接近:
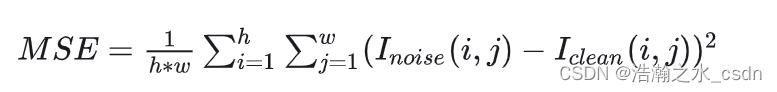
这里h和w代表图像的长和宽,即遍历了每个像素的差异。
Peak Signal to Noise Ratio(PSNR)
峰值信噪比是峰值信号的能量MAXi与噪声的平均能量MSE之比,PSNR的单位是分贝(dB),其值越高说明处理后图像与原始图像的差异越小,图像质量越好。

尽管PSNR提供了一种数学上的精确度量,但它并不能完美地模拟人类视觉系统的感知。尤其是在处理诸如纹理细节、颜色过渡和高频成分时,PSNR往往不能全面地反映出图像质量的主观感受。
Structural Similarity Index(SSIM)
SSIM特别关注图像的结构信息保持程度,而非简单地比较像素间的差异。图像的相似性不仅取决于像素级别的亮度差异,还取决于图像的对比度和结构信息的一致性。具体而言SSIM计算基于以下几个基本要素:
亮度(Luminance/Luminosity):通过比较两幅图像x和y局部的平均灰度值u来评估亮度一致性。

对比度(Contrast):通过比较两幅图像x和y的局部方差σ来评估图像的对比度保持程度。

结构(Structure):通过计算两幅图像x和y的协方差来反映图像纹理和形状信息的一致性。
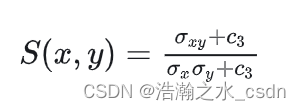
SSIM的计算涉及到归一化处理,最终得到的SSIM值是一个介于-1到1之间的数值,其中1表示即两幅图像完全相同,接近1则表示相似度高,越接近-1表示相似度越低。
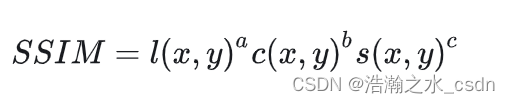
根据实际任务情况,我们可以手动调整三个指标a、b、c的比例。
其他指标
另外还有一些指标如Edge Noise Ratio(ENL)、Efficient Perceptual Image Blur Assessor(EPI)、Naturalness Image Quality Evaluator(NIQE),这里不多做定义上的赘述。


















 1833
1833

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









