







继上次分享了经典统计语言模型,最近公众号中有很多做NLP朋友问到了关于word2vec的相关内容, 本文就在这里整理一下做以分享。 本文分为
- 概括word2vec
- 相关工作
- 模型结构
- Count-based方法 vs. Directly predict
几部分,暂时没有加实验章节,但其实感觉word2vec一文中实验还是做了很多工作的,希望大家有空最好还是看一下~
概括word2vec
要解决的问题: 在神经网络中学习将word映射成连续(高维)向量, 其实就是个词语特征求取。
特点:
1. 不同于之前的计算cooccurrence次数方法,减少计算量
2. 高效
3. 可以轻松将一个新句子/新词加入语料库
主要思想:神经网络语言模型可以用两步进行训练:1. 简单模型求取word vector; 在求取特征向量时,预测每个词周围的词作为cost 2. 在word vector之上搭建N-gram NNLM,以输出词语的概率为输出进行训练。
相关工作
在传统求取word的空间向量表征时, LSA 将词和文档映射到潜在语义空间,从而去除了原始向量空间中的一些“噪音”,但它无法保存词与词之间的linear regularities; LDA 是一个三层贝叶斯概率模型,包含词、主题和文档三层结构。文档到主题服从Dirichlet分布,主题到词服从多项式分布, 但是只要训练数据大了, 计算量就一下飚了。
基于神经网络的词语向量表征方法在[Y. Bengio, R. Ducharme, P. Vincent. A neural probabilistic language model, JMLR 2003]中就有提出, 名为NNLM, 它是一个前向网络, 同时学习词语表征和一个统计语言模型(后面具体讲)。
在Mikolov的硕士论文[1]和他在ICASSP 2009上发表的文章[2]中, 用一个单隐层网络训练词语表征, 然后将这个表征作为NNLM的输入进行训练。 Word2vec是训练词语表征工作的一个拓展。
模型结构
首先回顾NNLM,RNNLM,然后来看Word2Vec中提出的网络——CBOW,skip-gram Model。
1 . NNLM[3]
NNLM的目标是在一个NN里,求第t个词的概率, 即
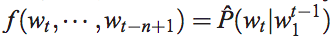
其中f是这个神经网络, 包括 input,projection, hidden和output。将其分解为两个映射:C和g,C是word到word vector的特征映射(通过一个|V|*D的映射矩阵实现),也称作look-up table, g是以word特征为输入,输出|V|个词语概率的映射:
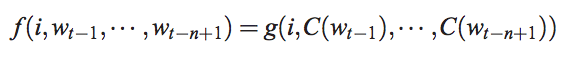
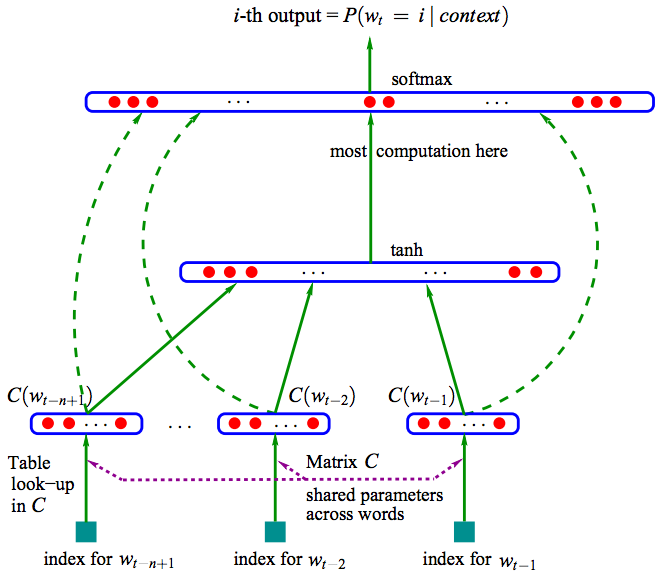
如下图所示:
输入: n个之前的word(其实是他们的在词库V中的index)
映射: 通过|V|*D的矩阵C映射到D维
隐层: 映射层连接大小为H的隐层
输出: 输出层大小为|V|,表示|V|个词语的概率
用parameter个数度量网络复杂度, 则这个网络的复杂度为:
O=N∗D+N∗D∗H+H∗V
其中复杂度最高的部分为H*V, 但通常可以通过hierarchical softmax或binary化词库编码将|V|降至
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 556
556











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









