







在文章《聊聊最近很火的混合专家模型(MoE)》中,我们简单介绍了MoE模型的定义和设计,并且比较了MoE和Dense模型的区别,今天我们继续来回顾一下MoE模型发展的历史和最新的发展现状。

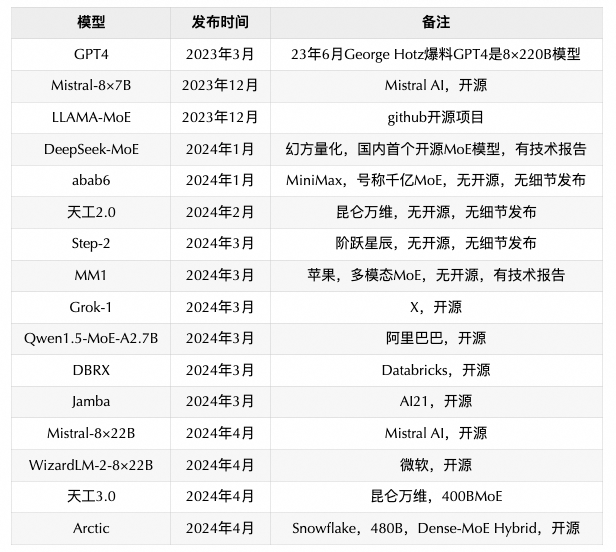
从去年GPT-4发布至今,MoE模型成了当前大语言模型领域的当红炸子鸡,“便宜又好用”让各家大模型公司既兼顾了模型效果又降低了模型成本,可以说MoE模型真正促进了LLM从实验室飞入到寻常百姓家,让中小型创业公司、独立开发者都能够用的起大模型。以下最近一年多发布的MoE模型:
一、发展时间线
1、起源
早在1991年,Geoffrey Hinton和Michael I. Jordan就发表了论文《Adaptive Mixtures of Local Experts》,这篇文章被认为是MoE的奠基之作。
2、RNN时代
20多年后,Google在2017年1月发布了《Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer》,把MoE带进了LSTM,训出了最大137B参数,专家数达到128k的LSTM模型。
3、Transformer时代
- 2020年6月,Google发布《GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding》,把MoE应用在encoder-decoder结构的transformer模型上,每两层将一个FFN层替换成一个MoE层,训出了模型参数量从12.5B到600B的一系列MoE模型,每层最大专家数也达到2048个。
- 2021年1月,Google发布《Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity》 ,在T5(encoder-decoder结构)的基础上,把FFN层替换成MoE层,并简化了routing策略,训出了最大1.6T参数量的switch transformer。Switch Transformers对scaling、蒸馏等做了很多详细的探索,影响深远,是很重要的一个工作。
- 2022年2月,Google发布《ST-MoE: Designing Stable and Transferable Sparse Expert Models》,也是一个基于encoder-decoder结构的MoE模型,最大模型有269B的总参数,32B的激活参数。ST-MoE可以说不仅仅是一个MoE工作,对于模型结构、工程实现、训练策略等都做了很多分析,个人认为其重要程度相比Switch Transformer都有过之而无不及。
4、GPT时代
- 2021年12月,Google发布了GLaM,《GLaM: Efficient Scaling of Language Models with Mixture-of-Experts》,训出了最大为1.2T参数量的decoder-only模型。(从encoder-decoder到decoder-only,可以看到Google内部在模型结构方向上也有很多不同的尝试)
- 2024年1月,幻方量化发布《DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models》,对在23年12月开源的DeepSeekMoE,给出了一些细节。
- 2024年,Databricks的DBRX、阿里的Qwen1.5-MoE-A2.7B、Mistral AI的Mistral-8x22B等陆续发布。
二、理论基础
以Geoffrey Hinton和Michael I. Jordan的开山之作《Adaptive Mixtures of Local Experts》为例,介绍MoE模型的理论基础。
1、思路
这篇文章大致的思路是这样的:对于比较复杂的任务,一般可以拆分为多个子任务。比如要求计算输入文本中有多少个动词和名词,那就可以拆分为“数动词”和“数名词”这两个子任务。
而一个模型如果要同时学习多个子任务,多个子任务相互之间就会互相影响,模型的学习就会比较缓慢、困难,最终的学习效果也不好。
因此这篇文章提出了一种由多个分开的子网络组成的监督学习方法。这些分开的网络,在训练过程中,分别学习处理整个训练数据集中的一个子集,也就是一个子任务。这个思路就是现代MoE的思路,每个子网络(也就是一个expert)学习处理一部分内容。
文章里把这个MoE的方法应用于vowel discrimination task,即元音辨别任务,验证了MoE设计的有效性。元音辨别指的是语音学中区分不同元音的能力,在语音学中,模型需要学习辨别不同的元音因素,以便准确地理解和识别语音输入。通过让多个子模型分别学习分别学习不同元音(a、e、i、o、u)辨别的子任务,最终效果得到了提升。
2、模型设计
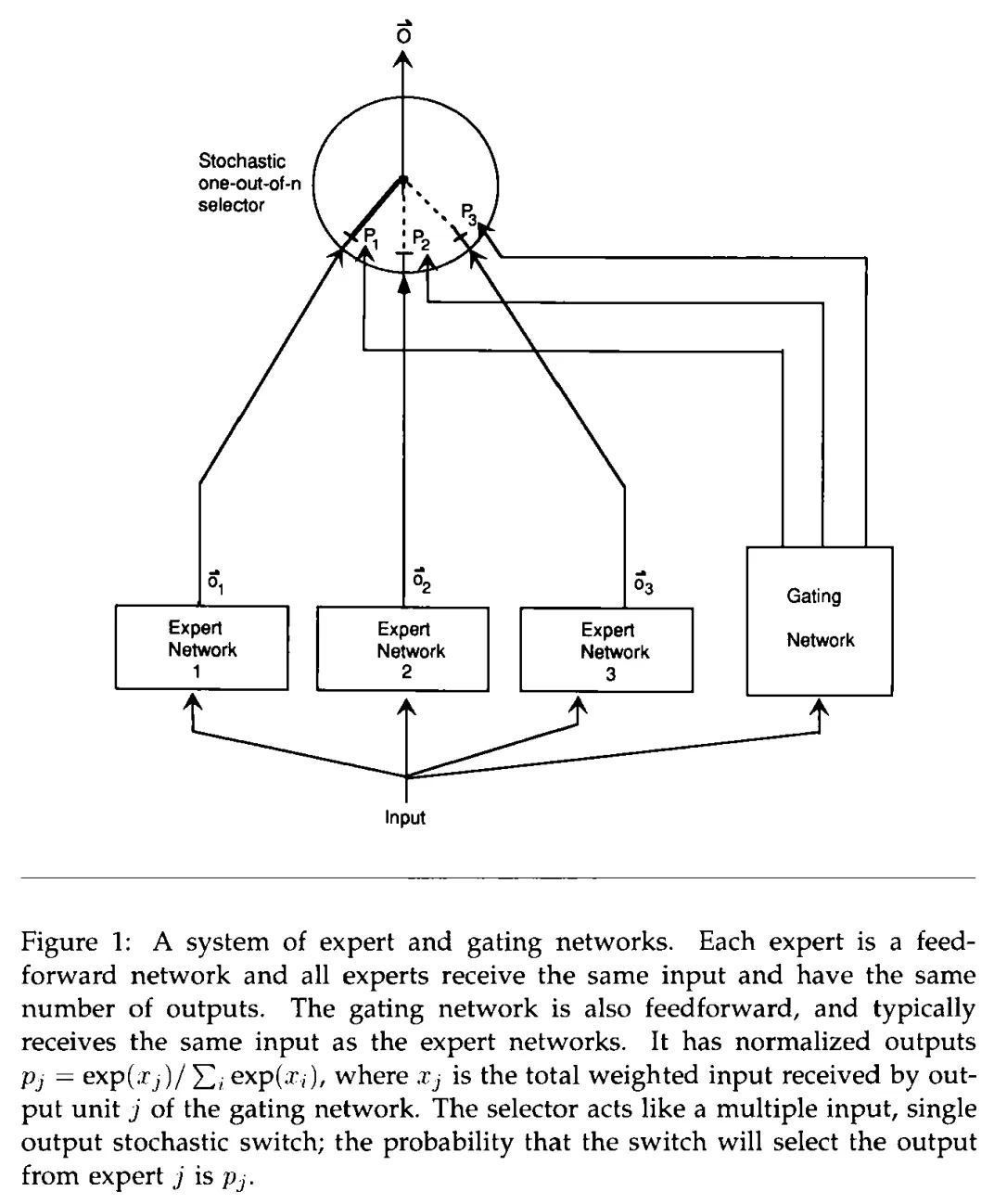
下图展示的就是这个MoE的思路:各个expert network和gating network接收同样的输入,每个expert给出各自的处理结果;而gating network输出每个expert的权重,就像一个开关一样,控制着每个expert对当前输入的打开程度,只是这个开关不是离散的,而是随机的,给出的不是true和false,而是权重。
三、典型MoE模型
1、LSTM MoE
Google在2017年1月发布了《Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer》,把MoE应用到了LSTM上,训出了最大137B的LSTM模型。这样规模的模型哪怕放在7年后的今天,也是巨无霸的存在,需要解决很多工程问题。相比1991年的工作,这里做到了真正的稀疏激活,从而可以在实际计算量较少的情况下,训练巨大的模型。
虽然当时Transformer还没出来,大规模模型的竞赛也还不像今天这么激烈,但是在多个领域中(文本、图像、音频),已经有不少工作反复证实了一件事:模型容量越大,能训出来的效果越好,上限越高。但是模型越大,需要的训练数据也就越多,二者共同作用下,就造成了训练开销基本是随着模型增大,以平方关系在增长。
在这个背景下就出现一些conditional computation,条件计算的工作来解决这个问题。conditional computation就是根据输入,有选择地只激活部分网络模块。那么MoE其实就是一种条件计算的实现。由于不用激活全部参数,训练所需的计算量就大大减小,整体计算成本就不用以平方速度增长。
虽然理论上计算量的成本下来了,不过实操起来还是会遇到几个问题:
- 训练的时候,在MoE结构下,每个expert的batch size比整个模型的batch size小了。
比如模型的batch size是32,一共有16个expert,那实际上一次迭代平均每个expert只能分到2个训练样本。而batch size对训练效率影响是很大的,大的batch size摊小了参数传输和更新的成本。如果直接增大模型的batch size,又会受显存和通讯效率的限制。- 训练数据量不足。
要训大模型就需要大量的数据,让模型参数充分学习。在当时的背景下,大规模的NLP数据是比较缺的。当然如今数据集多了很多,特别是预训练数据,这个问题现在来看没有那么突出了。- 损失函数的设计。
如何使用合适的损失函数来训练模型,提升效果,并且使得模型的负载比较均衡,这是一个不容易解决的问题。- 集群通讯问题。
一个GPU集群的计算能力可能比设备间网络带宽的总和高出数千倍,因此设备间的通讯很可能成为训练效率的瓶颈。为了计算效率,就要使得设备内计算量和所需的通讯量的比值,达到相应的比例。- GPU计算特点。
GPU做数学计算很快,但是并不擅长做branching(if/else),因此MoE的工作基本上都是用gating network来控制参数的激活。这个严格来说不算是新的挑战了,应该说是根据计算设备沿用下来的设计。
要解决好这些问题,才能训出比较好的模型来。
2、Shard
2018年,随着Bert的发布,transformer结构彻底火了起来。2020年6月,Google发布《GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding》,把MoE用到了encoder-decoder结构的transformer模型上。MoE开始变成我们现在熟悉的样子了。
GShard这个工作做了很多的实验,训了很多规模巨大的MoE模型,最大的达到了600B。训练的一系列模型的参数如下表
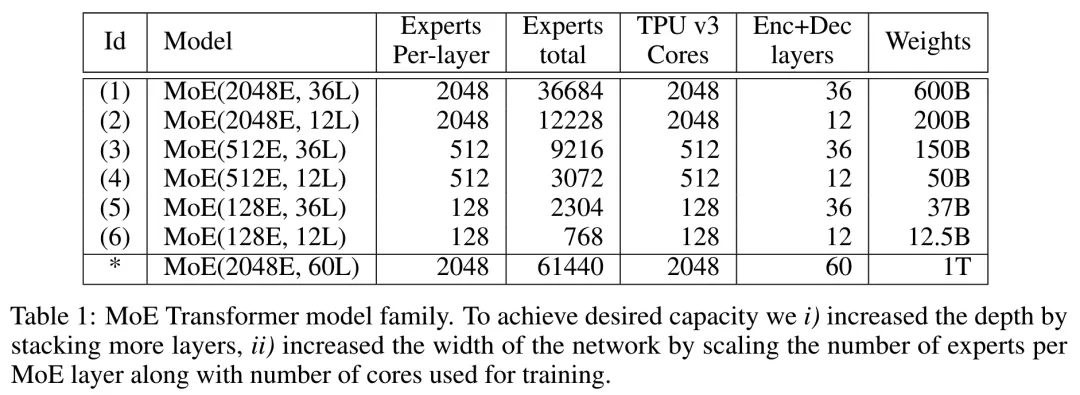
在expert数量的设计上,延续上面LSMT MoE工作的思路 -- expert越多,效果越好。(站在24年这个时间节点来看,太多的expert未必适合;但是也不能说这个思路一定错误,毕竟事物的发展是螺旋式的,就像ChatGPT出来之前大多数人都在魔改各种Bert,而GPT已经坐了几年冷板凳了。)
GShard论文中很大的篇幅在介绍工程实现和优化,这也是MoE模型训练最大的痛点。关于工程框架的内容比较硬核,因此这里不会展开讲太多,而是关注在模型算法层面上。
3、Switch Transformer
2022年4月,距离ChatGPT发布还有半年,Google发布了《Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity》(实际上2021年Google就提出Switch Transformer了)。
Switch Transformer和GShard一样,是encoder-decoder结构,基于T5开发的,具有1.6T的参数,2048个expert。和前面的很多工作一样,Switch Transformer有一个出发点,那就是参数量越大,模型效果越好,并且可以通过稀疏激活来减少总计算量。
但是相比其他工作,Switch Transformer给出了一个更为具体的描述,那就是模型参数量可以是一个独立于总计算量的,单独的缩放轴。也就是说,在改变参数量的同时,(几乎)不改变训练和推理的计算量,就可以带来效果的提升。因此Switch Transformer关注在“同样的FLOPS/token的计算量”下,如何扩大模型,提升效果。
Switch Transformer所做的工作还是比较多的,包括:
(1)模型结构简化:简化了Transformer上的MoE架构,提出Switch Transformer架构。
(2)MoE to dense:把训出来的效果较好的MoE模型蒸馏到dense模型,在压缩MoE模型99%的参数的情况下,效果还是比直接训练dense模型好。
(3)训练和微调技术:
- 首次使用bf16成功训练MoE模型
- 更适合MoE结构的模型初始化
- 增加的专家正则化,改善了稀疏模型的微调和多任务训练
(4)训练框架:结合数据、模型和专家并行性,训练了超过1T参数的MoE模型。
(5)多语言:在多语言数据集上训练,发现101种语言效果普遍有提升。
(6)训练效率:在同样的FLOPS/token的计算量下,Switch Transformer模型收敛速度有数倍的提升。
4、GLaM
2021年12月Google发表了《GLaM: Efficient Scaling of Language Models with Mixture-of-Experts》,训练出最大参数量为1.2T,每层包含64个专家,每个token激活参数量为96.6B的MoE模型。
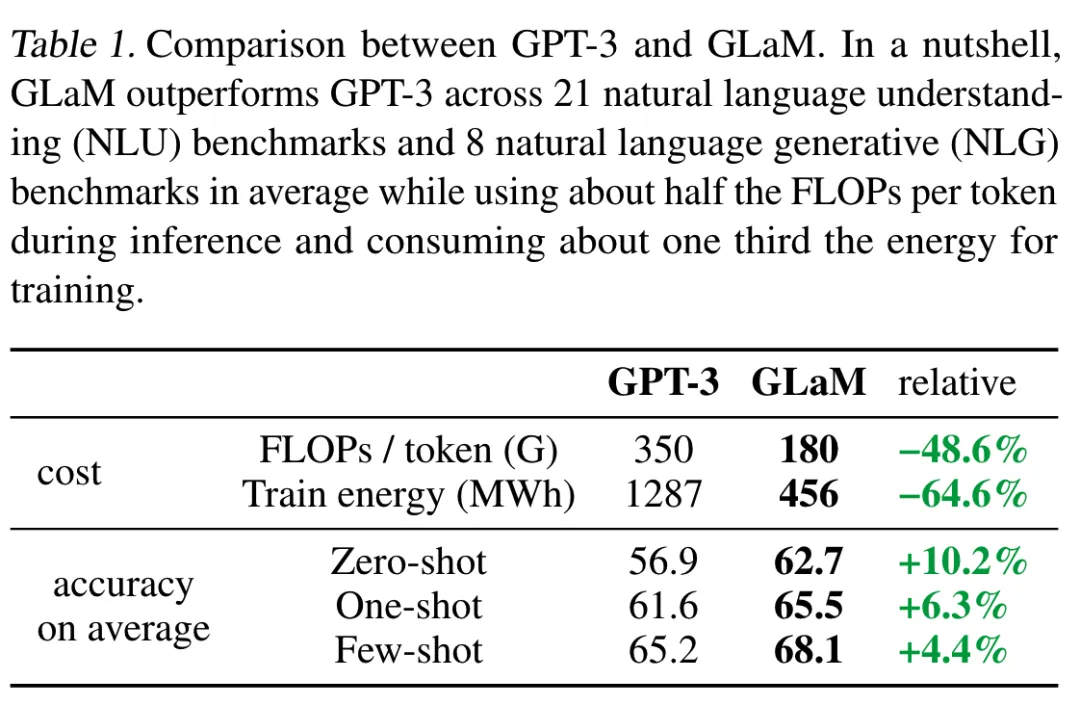
相比Switch Transformer,GLaM的训练数据量要大得多,达到了1.6T token。下表是论文中给出的,当时一些大规模模型的对比。
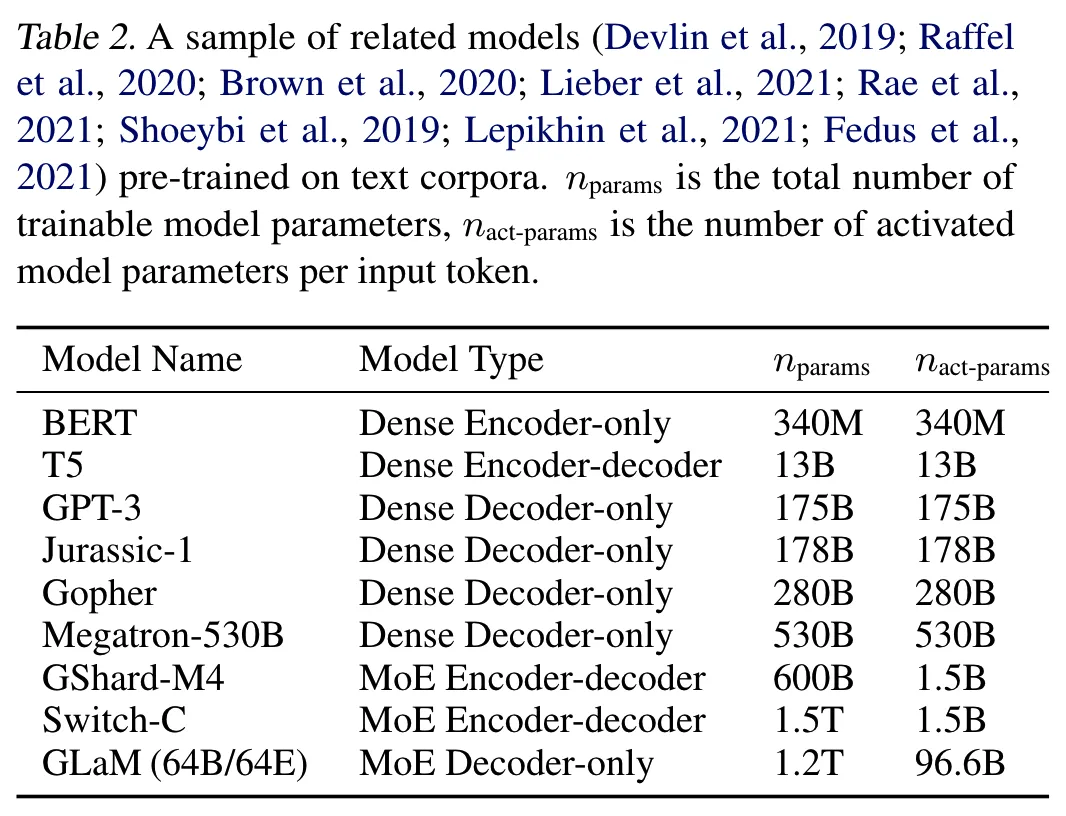
虽然模型总参数量比GPT-3(175B)大很多,但是训练成本却比GPT-3低很多,推理速度也更快,而且在多个NLP任务上的效果都超越了GPT-3,如下所示。
5、T-MoE
2022年2月,Google发表了《ST-MoE: Designing Stable and Transferable Sparse Expert Models》。ST-MoE可以说不仅仅是一个MoE工作,对于模型结构、工程实现、训练策略等都做了很多分析,可以说是MoE的必读论文。
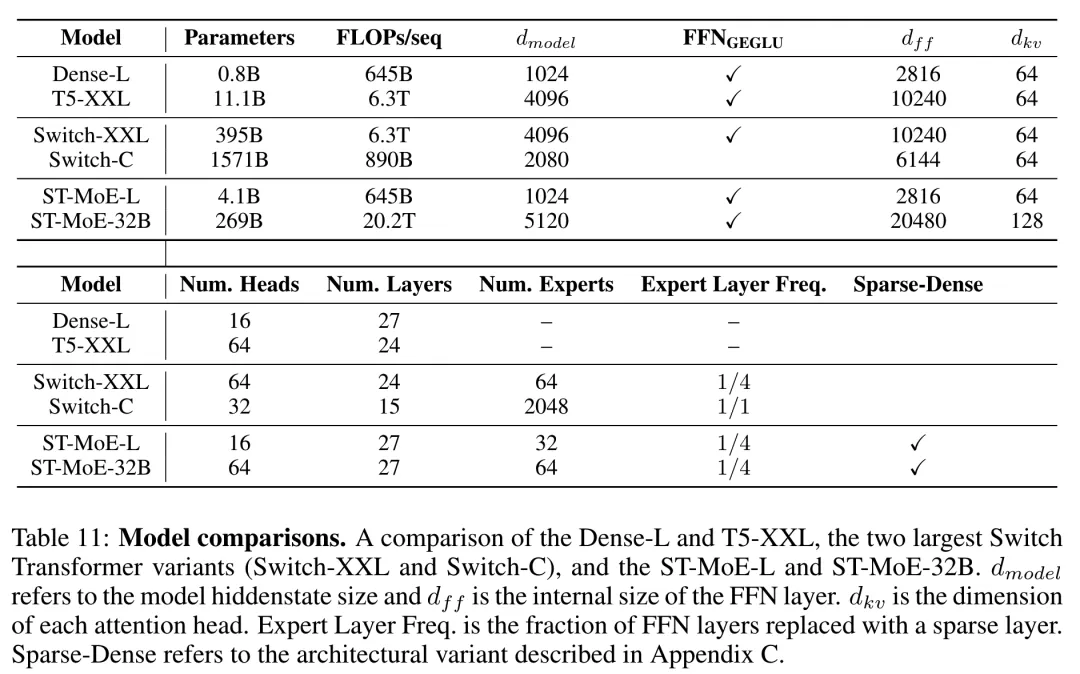
ST-MoE最大模型包含269B总参数量,和与32B dense模型相当的激活计算量。论文中把模型称为称为Stable Transferable Mixture-of-Experts,或者ST-MoE-32B。在MoE层的使用上,ST-MoE比Switch Transformer更“节省”一点,每四层才替换1个MoE层。论文中主要训了两个规模的ST-MoE模型,分别有4B和269B的总参数量。ST-MoE以及其他用于对比的模型参数如下表。
6、DeepseekMoE
2024年1月,幻方量化(旗下的深度求索)开源了DeepseekMoE,是国内首个开源的MoE大模型。幻方还发布了论文《DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models》,给出了一些DeepSeekMoE的细节内容,颇为实在了。
DeepSeekMoE在其他MoE工作的基础上,进一步给出了2个模型设计的主要思路:
(1)对expert的粒度进行细分,以提供更多样的expert激活组合;
(2)对expert的类型进行区分,从所有expert中保留一部分作为shared expert共享专家,这部分专家对所有输入都保持激活。
这样的做法可以帮助每个expert达到更高程度的专业化(specialization)的水平,更好地学习不同的专业知识。
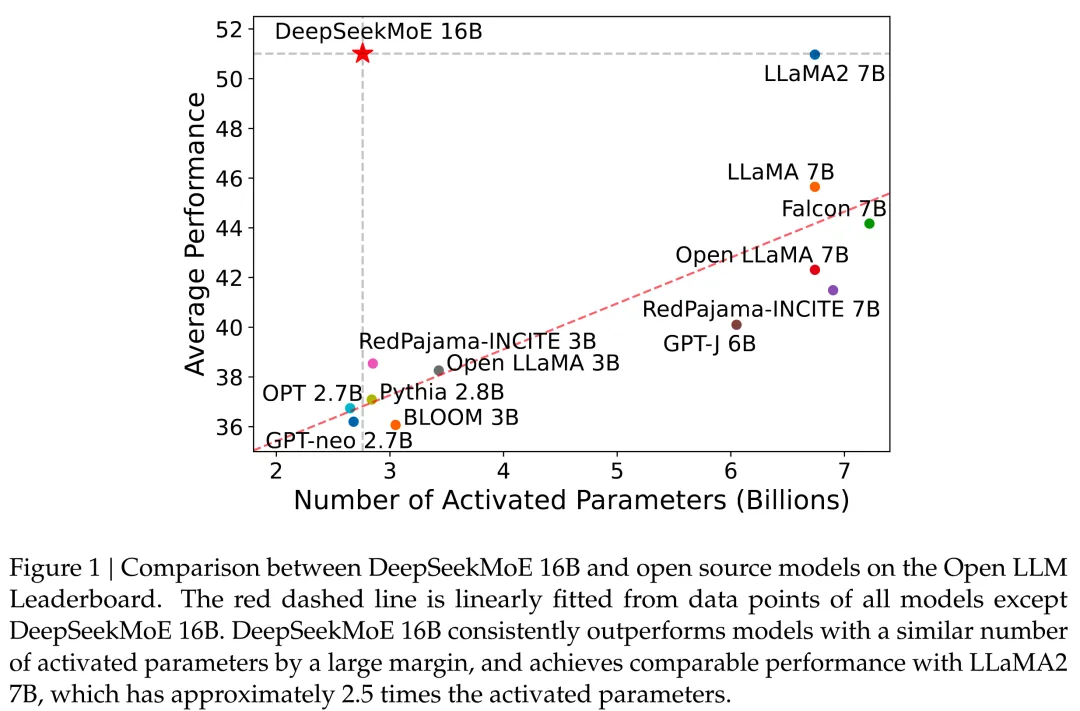
DeepSeekMoE先在2B的较小MoE模型上进行了充分的实验,然后把方案应用到16B参数的MoE模型上,并获得了较好的效果。其中DeepSeekMoE-16B不需要量化就可以在40GB显存的设备上运行。DeepSeekMoE-2B模型具有和稠密2B模型相当的性能,而DeepSeekMoE-16B则具有和7B稠密模型相当的性能,且计算量仅为稠密模型的40%。
DeepSeekMoE-16B的参数效率相比稠密模型有明显的优势,如下图所示,并且DeepSeekMoE-2B和16B模型都开源了。
在前面实验的基础上,幻方还训练了DeepSeekMoE-145B的超大MoE模型,具有和稠密的DeepSeek-67B模型相当的表现,但计算量更小。这个后续也有机会放出来。
7、DBRX
2024年3月27日,Databricks开源了DBRX,一个拥有有132B参数,激活参数为36B的MoE模型。
结构上,DBRX使用了RoPE、GLU、GQA,采用了fine-grained expert的设计,每层有16个专家,每个token激活其中4个。相比Mixtral和Grok-1在8个专家中激活2个,DBRX有更多的专家组合方式。
DBRX训练的上下文长度为32k,并使用了12T文本和代码token进行训练。DBRX在3072个H100上完成预训练,加上post-training、效果评估、red-team优化,整个过程耗费3个月时间。
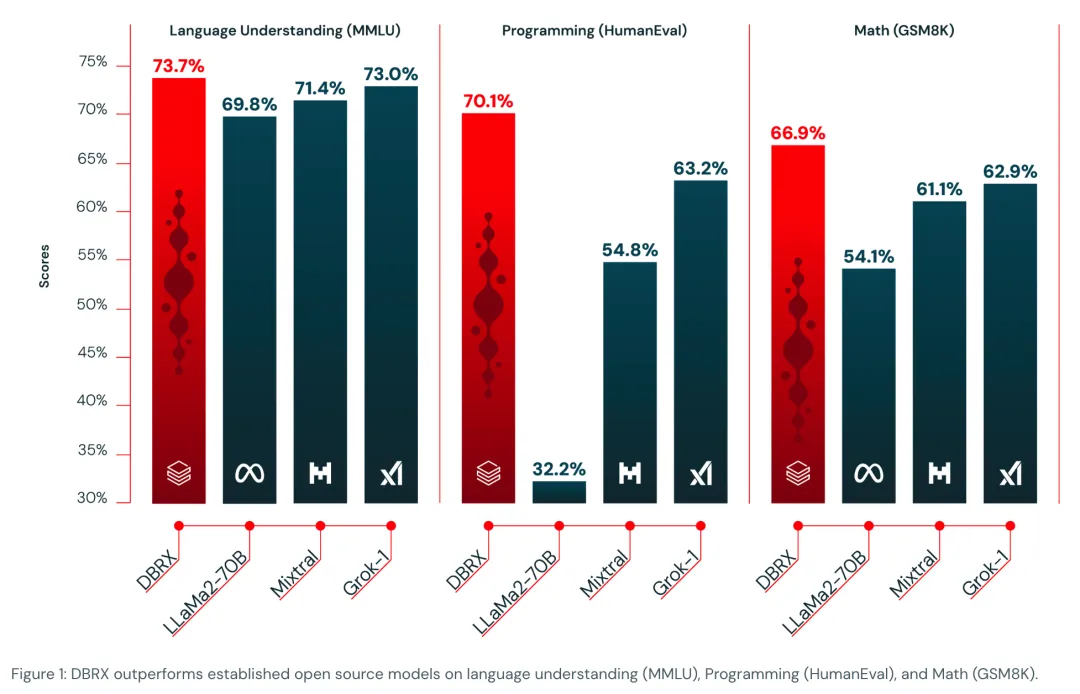
DBRX整体效果超过GPT-3.5,与Gemini 1.0 Pro相当,并且具有比较强的代码能力,甚至超过了在代码上专门优化过的模型,如CodeLLaMA-70B,如下图所示。
推理效率效率上,DBRX也领先于其他模型。
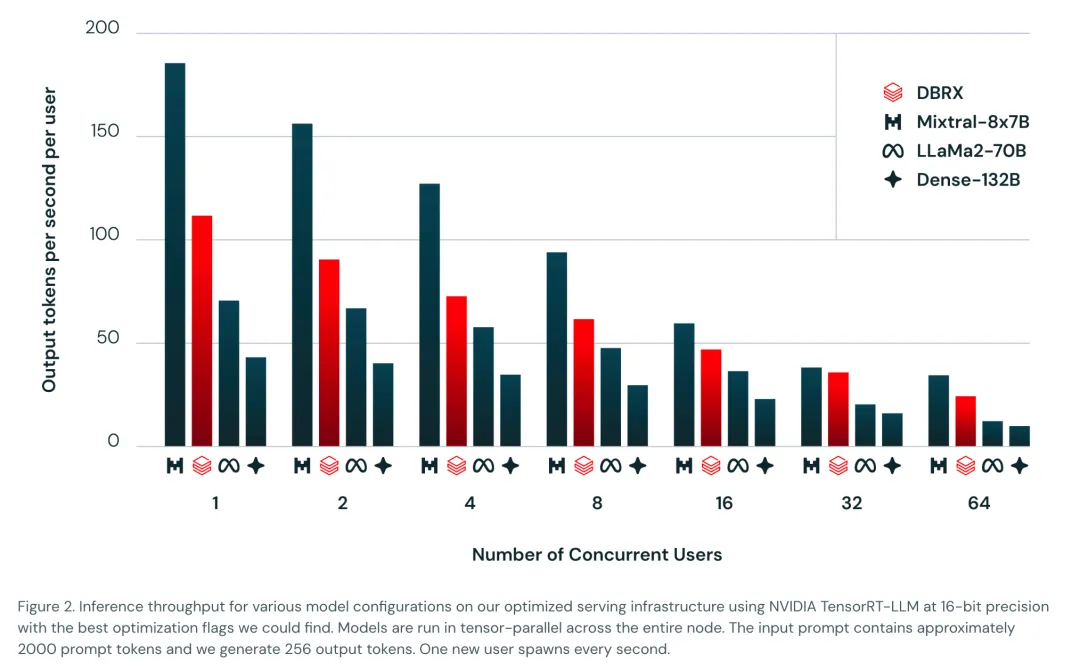
8、Qwen1.5-MoE
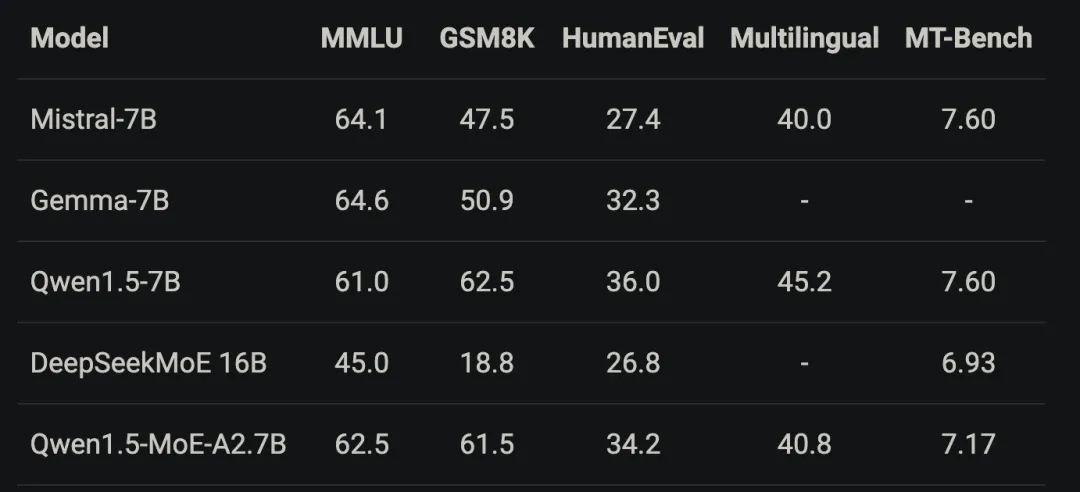
2024年3月28日,阿里放出了Qwen1.5-MoE-A2.7B,以2.7B的模型参数,达到了Qwen1.5-7B模型的相近效果。Qwen1.5-MoE-A2.7B参考了DeepSeekMoE和DBRX的工作,采用了fine-grained expert的做法,总共有64个专家,每个token激活8个专家,其中有4个为共享专家。
Qwen1.5-MoE-A2.7B使用Qwen-1.8B进行初始化,并在初始化阶段引入随机性,这样可以显著加快收敛速度,并得到更好的收敛结果。Qwen1.5-MoE-A2.7B和其他模型效果对比如下。
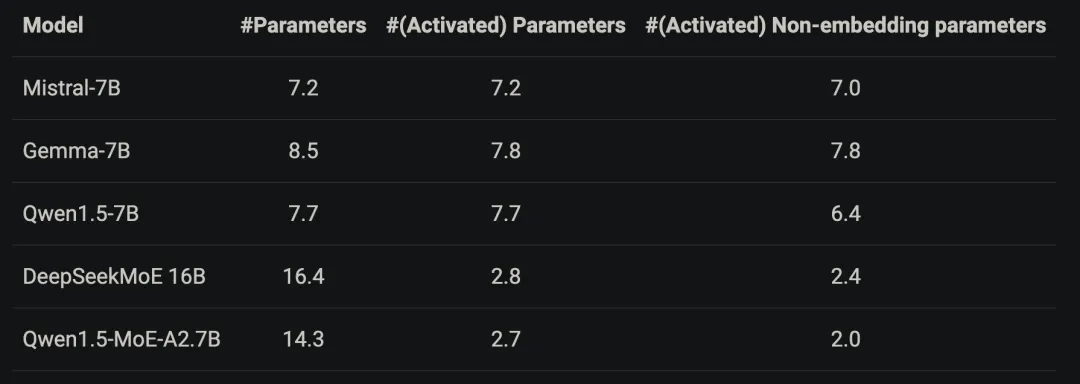
虽然Qwen1.5-MoE-A2.7B总参数量较大,但激活的non-embedding参数量远小于7B模型,如下表所示
实践中,Qwen1.5-MoE-A2.7B相比于Qwen1.5-7B,训练成本降低了75%。
推理性能上,在A100-80G用vLLM部署Qwen1.5-7B和Qwen1.5-MoE-A2.7B模型进行了性能测试。
输入/输出token数都设置为1000,输出token数设置为1000,TPS和throughput如下。
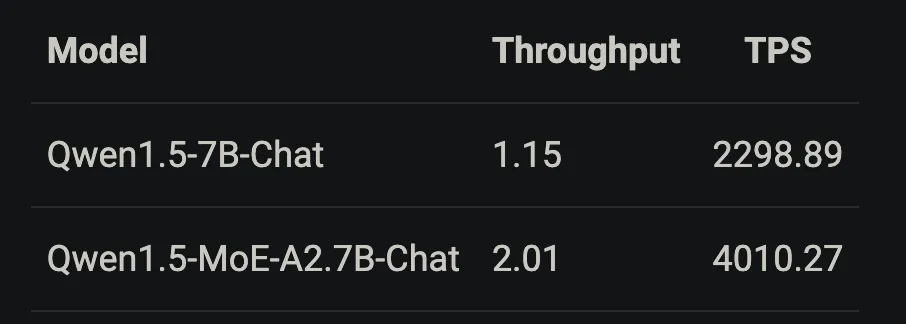
虽然MoE模型对内存需求更大,但是由于稀疏激活以及共享专家的设计,但是在速度和吞吐量上都比dense模型更好。Qwen1.5-MoE-A2.7B与Qwen1.5-7B相比,速度提高了约1.74倍。
9、Mistral
Mistral 8x7B
2023年12月11日,Mistral AI开源Mistral-8x7B,每个token激活8个专家中的2个。
Mistral-8x7B支持32k推理窗口和多语言,并且代码能力较好。和LLAM2-70B以及GPT-3.5的对比如下。
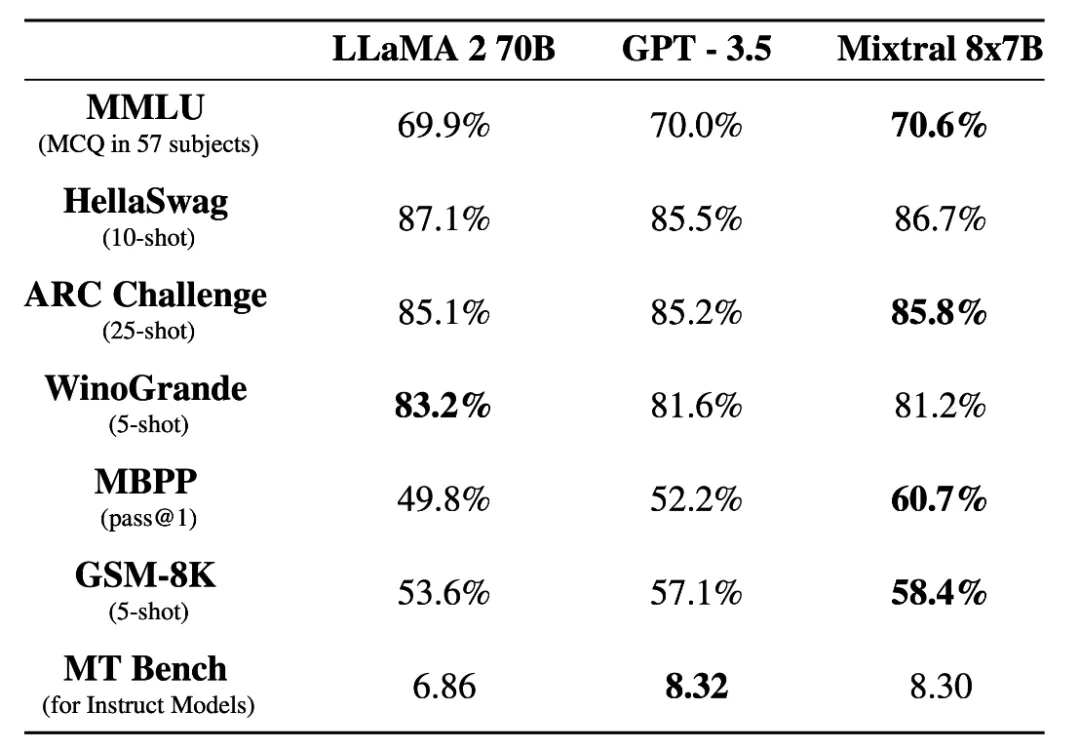
Mistral-8x7B在大多数任务表现优于LLAM2-70B,且推理速度提高了6倍。
而和激活参数量相近的LLAM2-13B比,优势更为明显。
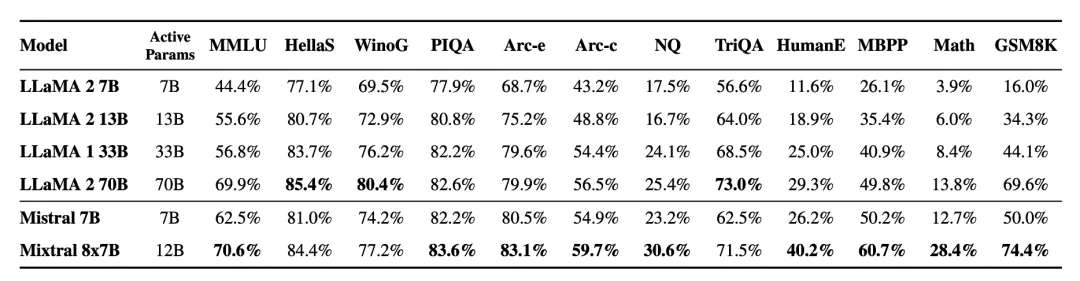
Mistral 8x22B
2024年4月17日,Mistral AI开源Mistral-8x22B模型,一个总参数为141B,激活参数为39B的超大MoE模型。
Mistral-8x22B支持多语言,并且具有较强的数学和代码能力。此外,推理窗口长度也从Mistral-8x7B的32k增加到64k。Mistral-8x22B还具备function call的能力。在各个维度的评测结果如下。


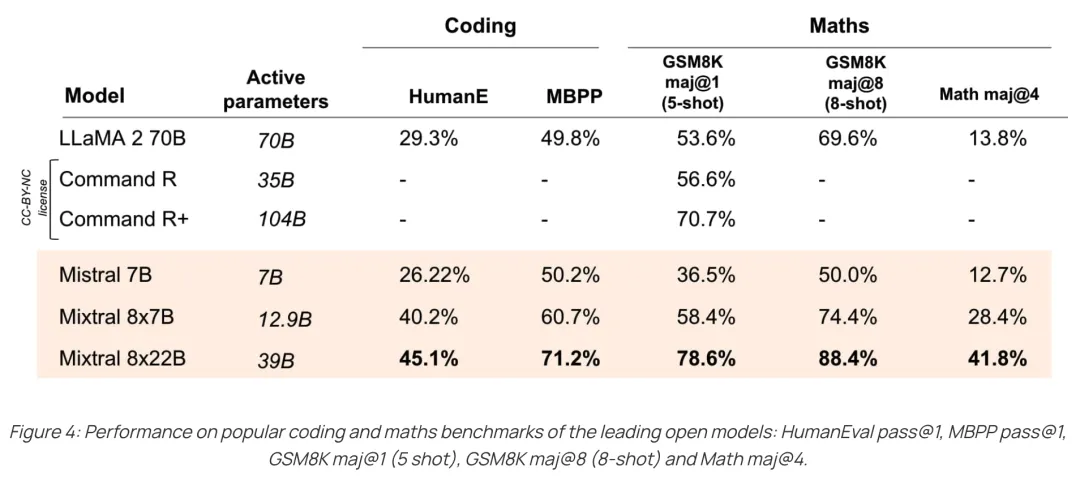
四、总结
- 现有的工作都表明,MoE模型相比dense模型具有更高的参数效率,即同样的计算量下,MoE模型普遍能有更优的效果。
- 因此MoE不仅能支持更大规模模型的训练,在较小规模模型上使用MoE架构也有很大收益。
- 但是相比dense模型,MoE模型的训练也需要考虑更多内容,包括专家数量、激活数量和专家容量的设计,负载均衡的问题,如何在多设备上的并行等,训练难度更大。
- 结构上,共享专家和细粒度专家目前被验证效果较好。
- 负载均衡上,GShard和Switch Transformer的负载均衡损失被广泛采用。
- 推理时需要对底层框架进行优化以适配MoE机制,否则难以发挥MoE的性能优势。
【推广时间】
AI的三大基石是算法、数据和算力,其中数据和算法都可以直接从国内外最优秀的开源模型如Llama 3、Qwen 2获得,但是算力(或者叫做GPU)由于某些众所周知的原因,限制了大部分独立开发者或者中小型企业自建基座模型,因此可以说AI发展最大的阻碍在于算力。
给大家推荐一个性价比超高的GPU算力平台:UCloud云计算旗下的Compshare算力共享平台,目前注册送20元测试金,可以畅享7小时4090算力,预装了主流的大模型和环境的镜像,开箱即用,非常方便。



















 6287
6287

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











