







影像组学入门实践成长营
第一节 组学浅析之通俗理解影像组学的定义
12:30 分享:组学浅析之通俗理解影像组学的定义
16:30 加餐:仅是为了发paper,敢问组学发展路在何方?
Day2 午间分享——组学浅析之通俗理解影像组学的定义 本文出自——知乎(番番杂谈)
基于医学的不断发展,临床医生可借助的信息也越来越全面,治疗决策的制 定往往需要联合多维度的信息(比如影像、病理、基因蛋白等信息)给出。例如 通过人工智能相关的统计建模进行预测,把里面最有用的信息提取出来,结合多 尺度的信息指导临床治疗决策,实现精准医疗的目标。
那既然我们要实现以患者为核心的个体化精准医疗,同时也为医学影像学提 出了新的挑战。
虽然 CT、MRI、PET 等设备越来越先进,医生仍然需要借助图像进行判断, 主要测量一些定性或半定量的指标,但精准医学要求我们回答一些更精准的定量 问题;另一方面是病理信息,主要是作为我们的金标准,但病理对于预后仍然是 具有挑战。基于此,影像组学应运而生。
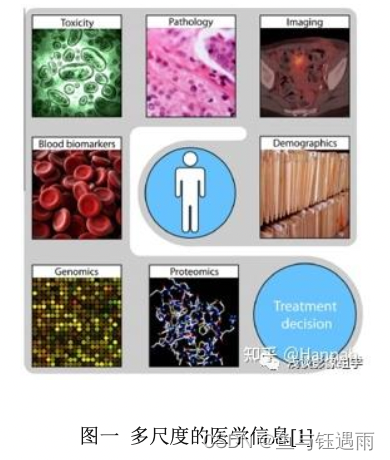
图一 多尺度的医学信息[1]
切入正题,影像组学的出现是顺应放射影像发展衍生的,那我们首先得有一 个清晰的概念认识,影像组学是什么呢?谁提出的呢
随着精准定量医学影像技术的快速发展、图像识别技术和数据算法的不断更 新,医学图像大数据的挖掘和分析得以实现,极大程度扩展了医学图像的信息量。
基于对图像信息进行纹理分析后能够得到高通量的特征的特点,受基因组学 以及肿瘤异质性的启发,2012年荷兰学者Lambin在先前学者工作的基础上提出 了影像组学(Radiomics) 的概念[1]。Lambin 认为“高通量地从医学影像中提取大 量特征,通过自动或半自动分析方法将影像学数据转化为具有高分辨率的可挖掘 数据空间”医学影像可以全面、无创、定量地观察肿瘤的空间和时间异质性。
Kumar 等[3]又对影像组学的定义进行了拓展,影像组学是指从 CT、PET 或 MRI 等医学影像图像中高通量地提取并分析大量高级且定量的影像学特征。这 个理念的提出在随后的七年迅速被越来越多的学者改进与完善。
“影像组学”,一共 4 个常见字。但 4 个字加在一起是啥意思?好吧,拆成“影 像”和“组学”两个词来说。“影像”通常指的就是放射影像,主要包括了 CT、MR 影像,当然,现在也陆续有加入了 PET、US 影像研究。组学(Omics),专门 百度了一下,通俗理解就是把与研究目标相关的所有因素综合在一起作为一个 “系统”来研究。
目前主要包括基因组学(Genomics),蛋白组学 Proteinomics,代谢组学 (Metabolomics),转录组学(transcriptomics),免疫组学(Immunomics),RNA 组学(RNomics),影像组学(Radiomics)等。涓涓细流也能演变成泛滥洪水,过 去 10 年中“组学 omics”成了科学界的流行语,美国加州大学戴维斯分校的进化生 物学家乔纳森.艾森曾称它为语言的寄生虫“language parasite”[2]。
影像组学本质上来说其实是一种分析思路方法,从临床问题出发,最后回到 解决的临床问题。一般分为五个主要处理步骤:
1、标准医学影像数据获取和筛选:数据收集前,首先需要根据明确的研究 方向进行数据筛选,例如做肿瘤分型或肺炎分型的鉴别诊断,所选影像数据是否 有病理或病原学检测金标准进行对照;做影像学疗效评估时,是否具有多期治疗 相应的影像资料匹配等。
2、图像分割:指将图像分成若干个特定、具备独特属性的区域并提取感兴 趣目标的技术和过程。根据研究目的的不同,图像分割的目标可以是病灶、正常 参考组织或是组织解剖结构,可以是三维也可以是二维区域,影像组学随后的分 析研究都围绕这些从图像内分割出来的区域进行。
3、特征提取:影像组学的核心步骤就是提取高通量的特征来定量分析 ROI 的实质属性。基于 Image Biomarker Standardization Initiative (IBSI)标准[4]统计划 分,常将影像组学特征分为形状特征(Shape features)、一阶统计学特征(First order statistics features)、纹理特征 (texture-basedfeatures)、高阶特征(high-order features) 以及基于模型转换的特征。
4、特征选择:上述通过特征提取,提取到的特征数量可能有几百到几万不 等,而并不是每一个特征都与要解决的临床问题相关联;另一方面,在实践中, 由于特征数量相对较多,而样本数量较少,容易导致随后的模型出现过拟合的现 象,从而影响模型的准确率。特征选择是根据某些评估准则,从特征集中直接选 取合适的子集,或者将原有的特征经过线性/非线性组合,生成新的特征集,再 从新特征集中选取合适的子集过程。
5、建立模型与应用:针对医生具体的临床问题,在临床研究问题标签的基 础上建立由上述特征筛选出来的关键特征,或进一步结合影像组学以外的特征 (如临床体征、病理、基因检测数据)组合而成的预测模型。
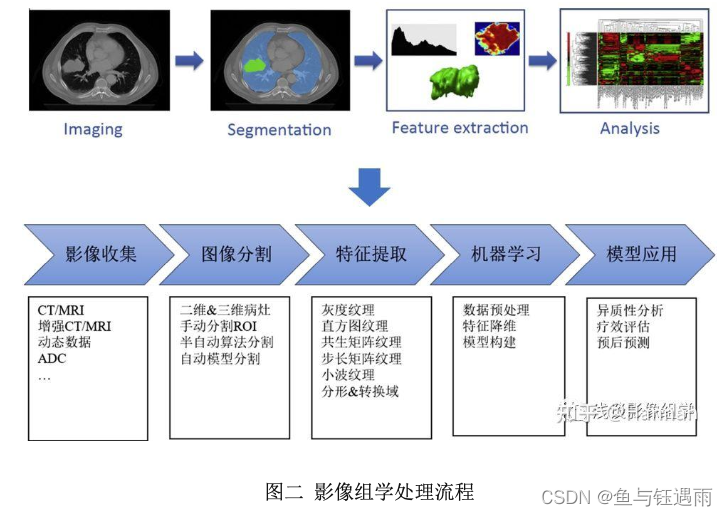
但其实,影像组学研究中的每一个操作流程都需要我们注意处理的规范化及 标准化,这将直接影响我们研究的泛化性,至于影响因素和需要注意的地方后面 也会持续进行总结分享。
近来,在 Pubmed 上搜索了一下近几年来关于“radiomics”(放射组学)的文章,自 2012 年 开始,正式发表第一篇关于组学的文章以来,虽然经过短暂的两年沉寂,2014 年后几乎每年关于影像组学的研究都是以倍数级发表量增长,在刚过去的 2020 年共发表了 1476 篇文章,即使 2021 年仅仅过了两个多月,至 2 月 22 日也已经 发表 326 篇文章。
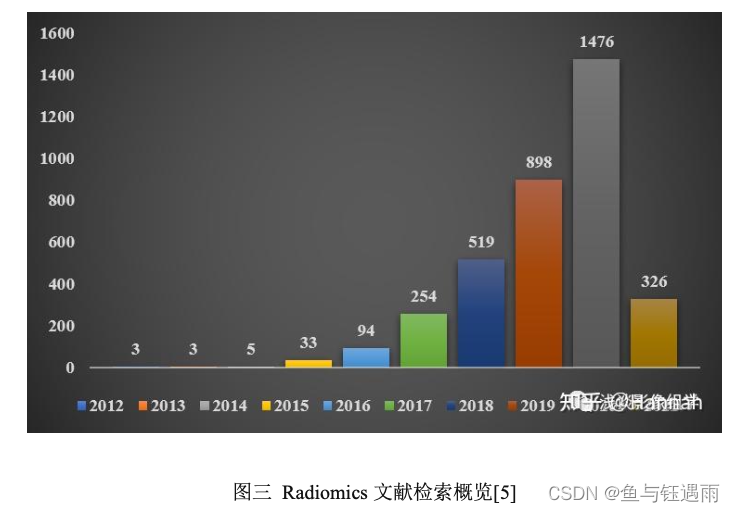
可见,影像组学在未来几年仍然也会是一个比较热门的研究方向。随着研究 者们认识的不断加深,相信研究的工作也会越来越细化,大量研究者们还是可以 有很多方向的工作可以去完善,去探索的.
参考文献:
[1] Lambin P, Rios-Velazquez E, Leijenaar R, et al.Radiomics: extracting more information from medical images using advancedfeature analysis[J].Eur J Cancer, 2012, 48(4):441-446. DOI:10.1016/j.ejca.2011.11.036.
[2]https://baike.baidu.com/item/%E7%BB%84%E5%AD%A6/9110802?fr=aladdin
[3] Kumar V, Gu Y, Basu S, et al. Radiomics: the process andthe challenges[J].Magn Reson Imaging, 2012, 30(9): 1234-1248. DOI:10.1016/j.mri.2012.06.010[4] Zwanenburg, A., Leger, S., Vallières, M., and Löck, S. (2016). Image biomarker standardisation initiative - feature definitions.
第2节 影像组学介绍
组学在近几年仍然是研究的热门方向,每一年文献库中的paper都在不断增长,那整个组学的发展历史和未来的研究方向是怎样的呢?我们先把医学成像技术发展时间线拉出来: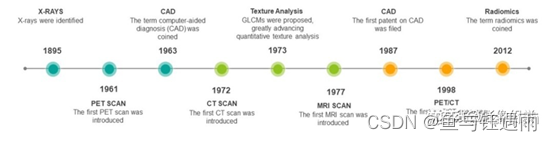
自1895年X-rays被发现,随着医学成像技术的快速发展,126年以来,X-Rays到在现代临床实践中使用CT、MRI及正电子发射断层扫描(PET)等技术,医学成像技术已得到显着扩展。受益于计算机技术及硬件的不断发展,基于影像进行定量分析的纹理分析和 Radiomics也分别在1973年和2012年应运而生。自此,拉开了影像组学发展的序幕。
纵观整个发展时间线,CAD技术的出现到CAD第一次应用于患者经历了大概24年的时间,而纹理分析到组学也经历了30多年;我们有理由相信,在未来的十年,影像组学是有潜力真正应用于临床的,服务于临床的。
也就是说影像技术发展到了一定程度和机器学习的发展,加上组学之热,加速了影像·组学的诞生与发展。直到2012年,影像组学的术语被创造出来,其实早在07、08年,全套定量的纹理分析就已经有不少文章报道了。我们再来看下影像组学发展的时间线,2012年,一位伟大的荷兰科学家Lambin在European Journal of Cancer杂志 (IF:7.275)上率先发表了第一篇关于组学的文章,正式取了个名字,提出了radiomics的概念。明确给出了组学的定义:从医学图像中提取更多信息用于分析。。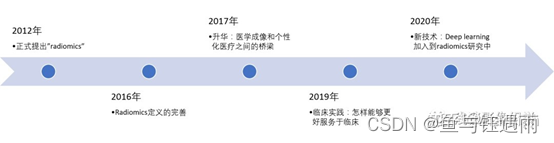

影像组学工作流程:在医学图像上,做图像的分割、特征提取以及临床分析
2016年,Gillies在影像学杂志的顶刊Radiology (IF:7.931)上,对组学的定义进行了完善,慢慢地开始发展壮大,从医学图像延伸到了数据层面,“Images are more than pictures, they are data”.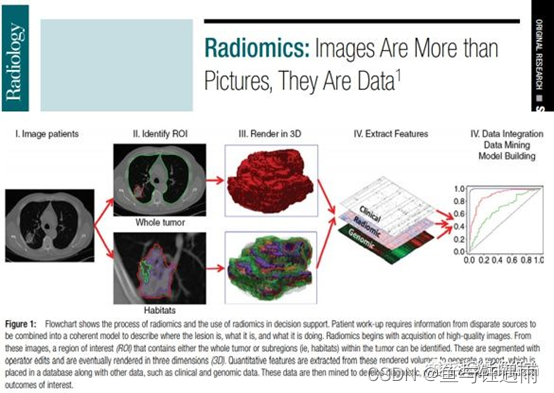
治疗决策的制定需要结合多源的信息,定量特征除了影像特征,也包括临床和基因信息。
017年,时隔五年,这位伟大的科学家Lambin在顶刊Nature Reviews Clinical Oncology(IF: 53.276)再次发表了文章,对组学的定义做了进一步的升华,Radiomics开始引起了临床治疗的关注,它成了医学成像和个性化医疗之间的桥梁,“the bridge between medical imaging and personalized medicine”.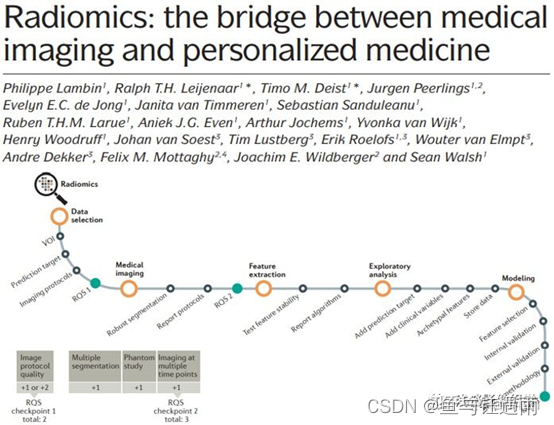
影像组学研究流程中各个环节需要注意的事项,比如预测目的、成像协议、分割的鲁棒性、特征稳定性、临床变量纳入、内部验证、外部验证等,每一环节都直接影响组学研究的质量。
2019年,影像学杂志的顶刊Radiology (IF:7.931)上发表了Steiger等人的一篇paper,让大家开始思考怎样让radiomics在医学影像人和放射科室始终如一地应用起来呢?研究者们开始不满足于仅发几篇paper,想把它真正应用于临床,真正帮助医生、患者。
2020年,又过了三年,Lambin所在的团队在British Journal of Radiology(IF: 2.196) 125周年专刊上又发表了组学的评论文章"Radiomics: from qualitative to quantitative imaging",从定性到定量成像.文中提到了组学特征有"handcrafted and deep"两种形式,手工制作的特征和基于深度学习得到的特征。讨论了两者的优缺点,并讨论了深度学习的应用。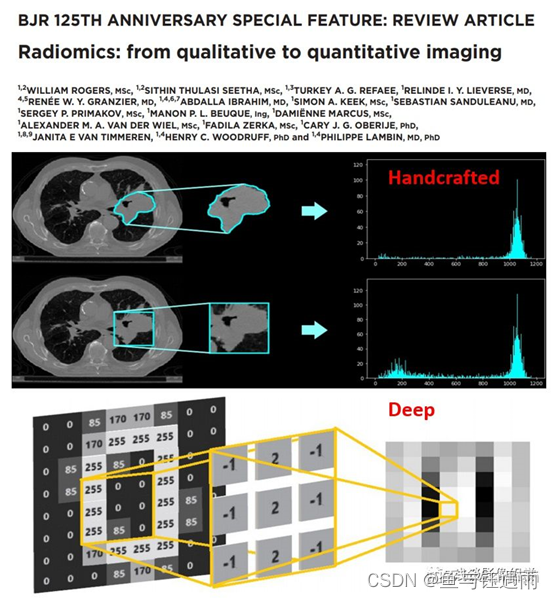
图上方表示传统的组学特征通过标注ROI提取的直方图特征,下方右侧表示通过对原始图像进行卷积得到的图像,综上,我们可以看到,随着组学的发展,临床实践、Deep learning radiomics等也逐渐成为关注的方向,同时,相信研究者们所关心的radiomics features代表的生物学意义也将逐渐探索出来,我们翘首以盼吧~
而说到生物学意义,我不得不提是目前影像组学的热点,
大家可以学习以下这篇文章进行探索,我在8月份的影像组学讲习营也会详细分析这篇文章。
通过近期对文献的阅读,我个人认为可以大体将影像组学的发展总结为5个时代,
萌芽阶段 影像组学1.0 影像学由主观的定性分析转变为定量分析
诞生 影像组学2.0 常规影像组学的诞生;高通量定量提取特征
发展 影像组学3.0 无人工干预自动提取特征;数据量的提升
规范 影像组学 4.0 研究流程的标准化、临床应用
意义 影像组学 5.0 可解释性、生物学意义、生境、临床应用
大家文章时也可以分分类,看看文章做到什么层次
随后我们说下基于Radiomics在各体部临床研究分布
影像组学技术要长期发展,势必还是要服务于临床,基于前期的组学文献检索,小部分老师对检索统计感兴趣,此次也做了一下radiomics在人体各体部研究成果分布的情况: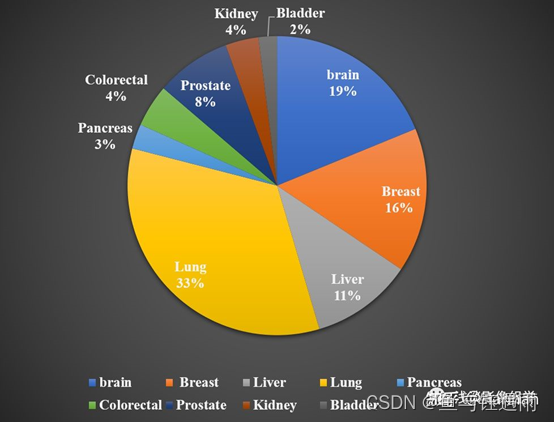
肺部在组学中的研究几乎每一年都是出于瑶瑶领先的地位,位居第一占33%,其次是脑部19%、乳腺16%、肝脏11%等。(注:数据仅供参考,来源于pubmed检索统计)。
对于研究较热门的体部,研究成果多,一般积累数据量也比较高,自然会变得要求越来越高,但是尝试做一些多中心的研究也是非常有意义的,研究成果有更大的机会率先服务于临床;而对于研究较少的体部也可以积累数据量,有更好的机会发表成果。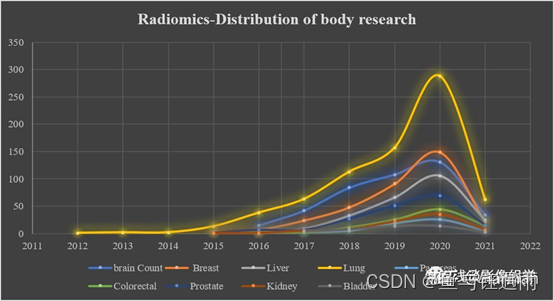
组学在各体部的研究每一年文章发表量都呈上升趋势,其中乳腺在2020年的成果首次高于了脑部研究成果(注:数据仅供参考,来源于pubmed检索统计)。虽然一些研究者说关于影像组学的文章现在拒稿率不断增加,越来越难发表了,方向快做烂了。但纵观各体部组学的研究,2020年发表的成果量其实也没有存在减缓的趋势,相反,还在以加速度增长发表成果,在肺部,乳腺,肝脏等体部均存在这样的表现。而且同一个队列,稍微改变下临床问题,就可以量产文章。靶区勾画都是不变的,变得就是后面的分析,和写作。我今天看同一作者在2020年12月、2021年3月、2021年7月,用基本是同一个队列,发了3篇2区,真的是可以实现量产了。
学习安排
12:30 分享:影像组学:医学影像学与个性化精准医疗的桥梁
16:30 加餐:影像时间 | 浅谈影像组学与人工智能
影像时间 | 浅谈影像组学与人工智能,总结自知乎,基本上今天得分享都是田捷教授得会议内容,田捷教授也是我国影像组学得大牛,如果想follow国内的大牛可以去看看田捷教授和刘再毅教授得文章。
近些年来,AI研究开展的热火朝天,各个器官疾病的诊断模型都有不同程度的尝试与研究,基于AI的影像组学应用已经覆盖病灶检测、病理诊断、放疗规划和术后预测等临床阶段。那么现在如火如荼的影像组学与人工智能的研究是什么呢?我们的研究进展如何呢?这就带着大家伙儿了解了解!影像组学是什么?(radiomics)在2012年由荷兰学者Lambin等首次提出影像组学的概念,指从医学图像中提取高通量特征(高通量特征即是一次性提取成千上百万的影像特征数据),并进一步采用多样化的统计分析和数据挖掘方法从海量信息中提取和剥离出真正起作用的关键信息,最终用于疾病的辅助诊断、分类或预测。
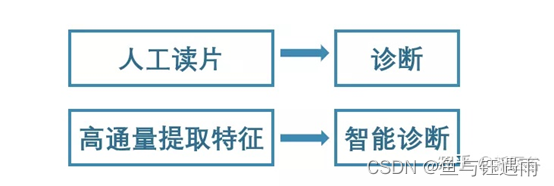
简单来说:就是定性分析转化为高通量提取+定量分析,从而用于辅助诊断。影像组学的分析流程是怎样的?影像组学的分析流程主要由获取影像图像数据、图像分割、特征筛选与降维、构建模型进行预测几大步骤构成。
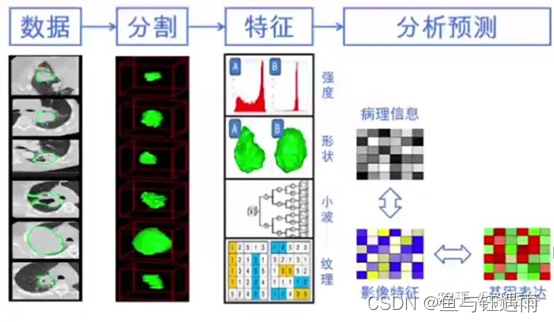
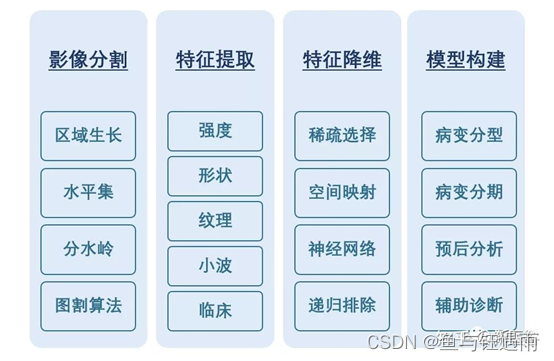
其中特征提取与筛选是很重要的一步!因为影像组学的分析过程中,获取了高通量的特征。
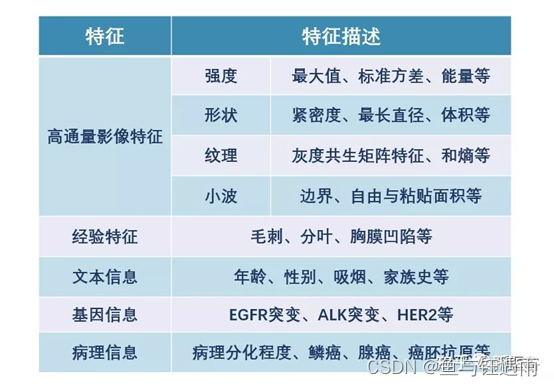
面对大量的特征,我们不可能对其直接进行模型构建,我们需要对数据进行降维,给数据“瘦身”,从成千上万的特征数据中获取最为有价值的特征数据。
影像组学可以做什么?
影像组学作为医工交叉的产物,其应用先进的计算机方法解决临床具体问题,具有智能诊断、智能评估、智能预测等广阔的应用前景。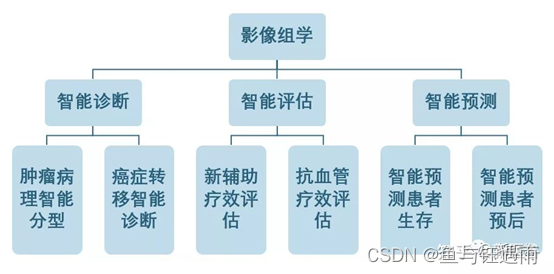
人工智能是什么?(Artificial Intelligence)在1956年的达特茅斯会议首次提出了人工智能的概念(Artificial Intelligence)。研究开发用于模拟、延伸和扩展人的智能的理论、方法、技术及其应用系统。随着医学影像成像技术和计算机技术的进步,促使人工智能在各种医学影像任务如评估、检测、诊断、预后中的潜在应用价值迅速提升。
实现人工智能的方法有哪些呢?在AI影像领域,目前应用较多且热度较大的应该就是机器学习、神经网络与深度学习了。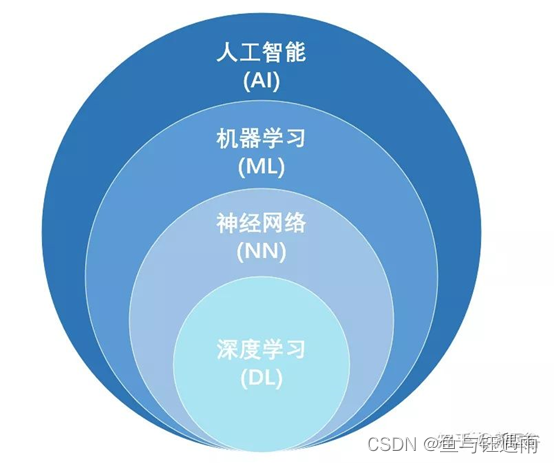
机器学习(Machine Learning)是数据驱动的自动学习算法。即使用计算机作为工具模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善。
神经网络(Neural Network)是有力的机器学习工具。深度学习(Deeping Learning)是包含多重感知层的神经网络。即通过组合低层特征形成更加抽象的高层表示属性类别或特征,以发现数据的分布式特征。
AI在影像组学上的应用 Application
智能应用一——新辅助治疗效果评估

智能应用二——影像预测乙肝纤维化程度
智能应用三——术中淋巴结转移的预测
总结:影像组学的研究内容即为利用分割、提取筛选特征、构建模型的核心关键技术来实现诊断、评估、预测等临床应用。
影像组学的研究内容即为利用分割、提取筛选特征、构建模型的核心关键技术来实现诊断、评估、预测等临床应用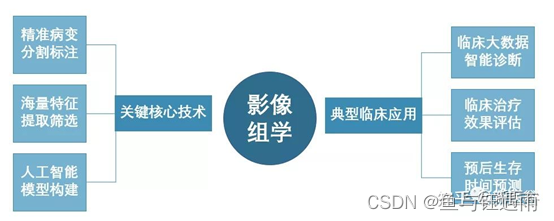
而面对系列临床问题,影像组学可以采用人工智能等方法定量分析医学影像大数据以实现临床辅助决策。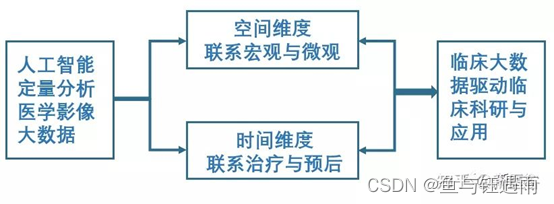
现如今,影像与人工智能的交叉是机遇与挑战并存的。对此,我们应该合理利用机遇,同时也要正确应对挑战。
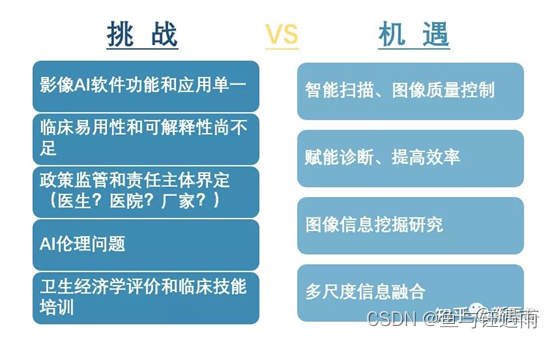
影像组学遇上人工智能就是医工融合的新突破,最终还是需要源于临床找问题、高于临床找方法,回归临床看效果,这样才能实现真正的医工交叉、互利共赢、共同发展!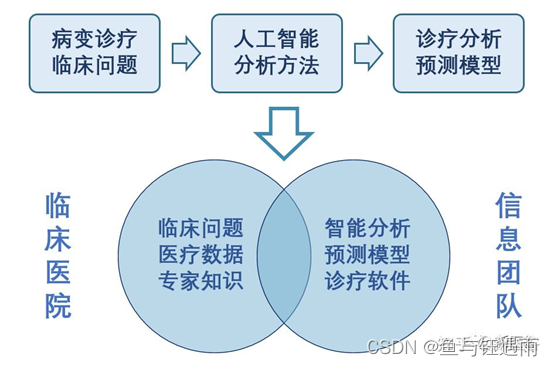
https://www.bilibili.com/video/BV1zy4y1m7YK?spm_id_from=333.337.search-card.all.click&vd_source=939505e5d0b3b448d66383cf3f877f4e
第3节 影像组学文献导读
学习安排
12:30 分享:新鲜出炉!17+影像组学生信文章套路!白嫖SCI的新思路!——知乎(酸菜)
16:30 加餐:英文阅读有障碍?来试试麦子的脱敏疗法——解螺旋
今天的午间分享是新鲜出炉!17+影像组学生信文章套路!白嫖SCI的新思路!——知乎(酸菜)
英语不好的人要去看英文文献实在是一种折磨,麦子当时也经历过这个阶段的:让我干什么都行,千万别让我看英文文献。但是还是被老板一句“搞科研连文献都不会看,还做什么研究?”给逼出了师,硬着头皮上啊,大不了就是撞墙呗。
首先就是一个心态问题:勇敢克服障碍的决心。文献不读不行,所以从现在开始决定一定要跨越这个坎,可不能像麦子本科阶段,因为英语听力不行,就彻底放弃,靠高中的底子过了四、六级,所以如今还是遇到英文交流就犯怵。正面困难,下决定克服困难,有了这个决心一切都是纸老虎了,接下来总能找到合适你的方法。以下是麦子的一点体会,如麦子这般资质的,都能克服英文文献障碍症,聪明如你,又有何惧呢?
一、读什么,从哪开始?
几十篇文献应该从哪一篇看起,几十页的文献应该重点看哪里;怎么看——怎么能够从几十页的文献中高效快速地提取自己所需要的信息,怎么才能在规定的时间内尽可能地囊括课题相关的文献内容才是问题的所在。
首先我们要解决的是知识面和专业词汇的问题,那么最好的方式就是从教科书式的文献开始。即文献综述或综述类文献开始,概览全局,缩小范围。然后再去有针对性地选择文献。这样的文献的特点是:覆盖面广,时间跨度大,概括性强,指导性强。通过这样的文献综述,我可以锁定我需要特别关注的区域。
接来下就要针对自己的方向,找相近的论文来读,从中理解文章中回答什么问题,通过哪些技术手段来证明,有哪些结论?并从中,了解研究思路,逻辑推论,学习技术方法。那其中最好的牛人文献和高引用的文献。通过本领域牛人或者主要课题组的文献,就可以把握目前的研究重点。那么怎么知道谁是牛人呢?第一是在ISI检索本领域的关键词,不要太多,这样你会查到很多文献,而后利用ISI的refine功能,就可以看到哪位作者发表的论文数量比较多。
还有一个方法,就是首先要了解本领域有哪些比较规模大型的国际会议,而后登陆会议主办者的网站一般都能看到关于会议的invited speaker的名字,一般这些人都是本领域的领头羊了。而高引用次数的文章,一般要么思路比较好,要么材料性能比较好,我们可以从中领悟到一些思路与方法。
当你有了一定背景知识,开始做实验并准备写论文的时候需要看的文献了。首先要明确一点,你所做的实验想解决什么问题?是对原有材料的改进还是创造一种新的材料或者是新的制备方法,还是采用新的表征手段或是计算方法。明确这一点后,就可以有的放矢查找你需要的文献了。而且往往当你找到一篇与你研究方向相近的文章后,通过ISI 的反查,你可以找到引用它的文献和它引用的文献,从而建立一个文献树,更多的获取信息量。
二、阅读一篇文献的流程
文献到底通篇看完呢,还是有重点的看呢,这个每个人的答案不一样。对于英文不太好的菜鸟来说,每个单词都认识读完了却不知他在说什么,这是最大的问题。西方人的文献注重逻辑和推理,从头到尾是非常严格的,就像GRE里面的阅读是一样的,进行的是大量重复、新旧观点的支持和反驳,有严格的提纲,尤其是好的杂志体现得越突出。读每一段落都要找到他的主题,往往是很容易的,大量的无用信息可以一带而过,节约你大量的宝贵时间和精力。
那么哪些部分是关键,是重点呢?完成了对首段(摘要)的阅读,其实已经成功了一半。为什么这样说呢?第一段即摘要(Abstract),统领全文,同时相当于阅读索引,告诉读者主要信息的分布情况,便于读者采撷自己需要的内容。
1、读摘要时,快速浏览一遍,这里主要介绍这篇文章做了些什么。读完思考一下,为什么论文摘要多采取这样的结构?它有什么样的必然性,或者说优越性?假如现在需要你把你的研究成果向一群具备基本常识的门外汉宣讲,你会采取什么样的顺序?想清楚这样一个问题,你就知道你的篇章结构应该怎么安排了。或者说如果是这样一篇文章,如果你来写的话,你会怎么安排结构,像这样把思考和演练带到阅读,一边读一边想,将事半功倍。然后带着你自己的预演桥段以论证的寻找差异的心态去读文献接下来的部分,效率就高了很多。
2、读标题:看完标题以后想想要是让你写你怎么用一句话来表达这个标题,根据标题推测一下作者论文可能是什么内容。有时候一句比较长的标题让你写,你可能还不会表达,下次你写的时候就可以借鉴了。
3、读材料及试验:当你文献看多了以后,这部分内容也很简单了,无非就是介绍试验方法,自己怎么做试验的,很快就能把它看完了吧。
4、试验结果:看结果这部分一定要结合结果中的图和表看,这样看的快。主要看懂试验的结果,体会作者的表达方法(例如作者用不同的句子结构描述一些数字的结果)。有时看完以后再想想:就这么一点结果,别人居然可以大篇幅的写这么多,要是我可能半页就说完了。
5、看分析与讨论:这是一篇文章的重点,需要花些时间,看之前,最好先来思考一下,如果是我得到了这样的结论,我会怎么分析和讨论,然后慢慢看作者的分析与讨论,仔细体会作者观点,为我所用。这样你会发现自己与作者的差距,看得多了,你们差距就越来越小了。
6、看结论:这个时候看结论就一目了然了,作后再反过去看看摘要,其实差不多。
三、提升效率的方式
除了阅读时带入自己的思考外,还有一点,永远不要放弃寻找联系,联系越多越强越复杂,我们捕捉信息的网就越大越密越严谨。不断构建新的联系,更新/更正已有的联系本来就是科学研究的主要内容之一。
阅读文献的时候要不时地带入自己的知识体系,帮助甄别信息的优先级,同时也有助于理解性地记忆文献的大致结构和主要内容。最终达到在合上书本的时候,脑海中画树形图的境界。
总之,万事开头难,麦子老板常常说一句话:“天下大事必做于细,天下难事必做于易”,关键你勇敢地开始了,就没有找不到的办法,还有一句话:“敢问路在何方,路在脚下”,对英语自信的小伙伴们,撸撸袖子,开始干起来吧,一切没有你想像的那么难哦。
首先进入一个新的领域,首先是敢读,其次是不要烂。进入一个全新的领域,尤其是阅读综述,建议花一整个周末的时间从头到尾手动翻译一遍。翻译到第二篇基本上英文阅读阻力就很小了。如果是研究型文章,就是粗略读提取要点,酸菜大大在文献一点通已经讲的很明白了。如果是精读文章,大家一定要边读边做总结,给自己做好规定,例如,introduction我就要用5句话总结,提炼出最关键的信息。还有就是精读research article可以最后读abstract,如果你先读了,容易被作者牵着鼻子走;你可以在整篇文章读好后,看看自己提炼的信息点和作者提炼的一致不。可能作者对自己文章的理解有问题也说不定。带着问题去与作者对话;我的呱啦呱啦就说这些
第4节 python入门及实践
12:30 分享:python入门的60个基础练习
16:30 加餐:35张思维导图,记录纯小白五天速通python的学习笔记!
学习安排
12:30 分享:Radiology:图像生物标志物标准化:基于高通量图像表型的标准化定量影像组学
16:30 加餐:常见的医学影像数据格式
常见的医学影像数据格式:
医学影像学Medical Imaging,是研究借助于某种介质(如X射线、电磁场、超声波等)与人体相互作用,把人体内部组织器官结构、密度以影像方式表现出来,供诊断医师根据影像提供的信息进行判断,从而对人体健康状况进行评价的一门科学,包括医学成像系统和医学图像处理两方面相对独立的研究方向。
1、 脑成像数据模态:脑成像数据主要有DTI、FMRI、3D三种模态。其中,DTI,3DT1是三维数据,FMRI是四维数据。
(1)DTI:Diffusion Tensor Imaging,磁共振弥散张量成像。
(2)FMRI:Functional Magnetic Resonance Imaging,功能性磁共振成像。
2、DICOM格式
DICOM(Digital Imaging and Communications in Medicine)即医学数字成像和通信,是医学图像和相关信息的国际标准(ISO 12052)。它定义了质量能满足临床需要的可用于数据交换的医学图像格式。DICOM被广泛应用于放射医疗,心血管成像以及放射诊疗诊断设备(X射线,CT,核磁共振,超声等),并且在眼科和牙科等其它医学领域得到越来越深入广泛的应用。在数以万计的在用医学成像设备中,DICOM是部署最为广泛的医疗信息标准之一。当前大约有百亿级符合DICOM标准的医学图像用于临床使用。
3、 MRI和fMRI
(1)MRI扫的是大脑的结构图像,也叫T1权重图像。它有着很高的空间分辨率,可以从中看到非常清晰的解剖结构,也可以从中区分出各种不同的组织。(2)fMRI往往用于研究大脑的具体功能,扫出来的是功能图像,也叫做T2*权重图像。虽然它的空间分辨率比较低,但是时间分辨率很高,可以在很短的时间内扫出一叠功能图像。这样就可以研究实验操作究竟是如何影响大脑的MRI信号的。 fMRI数据预处理 步骤包括:可视化(Visualization)、去伪影(Artifact removal)、时间配准(Slice time correction)、头动校正(Motion correction)、生理噪音校正(Correction for physiological effect)、结构功能配准(Co-registration)、标准化(Normalization)和时空间滤波(Spatial and temporal filtering)。
4、Analyze格式
储存的每组数据组包含2个文件,一个为数据文件,其扩展名为.img,包含二进制的图像资料;另外一个为头文件,扩展名为.hdr,包含图像的元数据。在fMRI的早期,Analyze格式最常用的格式,但现在逐渐被NIfTI格式所取代。Analyze格式主要不足就是头文件不能真正反映元数据。
5、NIfTI格式
标准NIfTI图像的扩展名是.nii,包含了头文件及图像资料。由于NIfTI格式和Analyze格式的关系,因此NIfTI格式也可使用独立的图像文件(.img)和头文件(.hdr)。单独的.nii格式文件的优势就是可以用标准的压缩软件(如gzip),而且一些分析软件包(比如FSL)可以直接读取和写入压缩的.nii文件(扩展名为.nii.gz)。
本文来自——知乎(阿旋菇凉)
第5节 基于高通量图像表型的标准化定量影像组学/ 影像组学的数据格式
12:30 分享:Radiology:图像生物标志物标准化:基于高通量图像表型的标准化定量影像组学
16:30 加餐:常见的医学影像数据格式
Day6 午间分享——Radiology:图像生物标志物标准化:基于高通量图像表型 的标准化定量影像组学
本文出自——知乎(思影)
一、概述
影像组学特征可以量化医学影像呈现的特点。然而,缺乏标准化定义和有效参考 值限制了临床应用。
材料和方法:影像组学特征分三个阶段进行评估:第一阶段,从 174 个基本特征 集中提取出 487 个衍生的子特征,25 个研究小组使用特定的影像组学软件直接 从数字图像中计算特征值,无需任何额外的图像处理;在第二阶段,15 个小组 使用肺癌患者的 CT 图像和预定义的图像处理配置计算了 1347 个衍生特征的值; 在这两个阶段中,通过测量特征值的频率评估有效参考特征值的一致性,并将其 分类为:少于三次,较弱;三到五次,中等水平;六到九次,很强;10 次或更 多,非常强。在最后阶段(第三阶段),使用来自 51 例软组织肉瘤患者的多模 态图像(CT、18 氟脱氧葡萄糖 PET 和 T1 加权 MRI)的公共数据集评估标准化 特征的再现性。
结果:第一阶段 302 个特征中的 232 个(76.8%)和第二阶段 1075 个特征中的 703 个(65.4%)最初参考值的一致性很弱。在最后一次迭代中,在第一阶段 487 个特征中只有两个(0.4%)和在第二阶段 1347 个特征中的 19 个(1.4%)存在 微弱的一致性。第一阶段 487 个特征中有 463 个(95.1%)和第二阶段 1347 个特 征中有 1220 个(90.6%)获得了强烈或更好的一致性。总体而言,174 个特征中 有 169 个在前两个阶段实现了标准化。在最后的验证阶段(第三阶段),169 个 标准化特征中的大多数都可以很好地再现(166个采用CT;164个采用PET;164 个采用 MRI)。
结论:标准化了一组共 169 个影像组学特征,从而能够验证和校准不同的影像组 学软件。本文发表在 Radiology 杂志。
医学的个性化是由准确诊断疾病和为患者确定合适治疗方法的需要驱动的。医学 成像是生物标记物的潜在来源,因为它提供了感兴趣组织的宏观视图。医学成像 的优点是无创性、临床护理中容易获得且可重复。
影像组学从医学成像中提取特征,以自动化、高通量的方式量化其表型特征。这 种影像组学特征有助于在癌症研究中预测治疗结果和评估组织恶性肿瘤。在神经 科学中,这些特征可能有助于检测阿尔茨海默病和诊断自闭症谱系障碍。
尽管影像组学在临床上越来越受到关注,但已发表的研究很难重现和验证。即使 对于同一个影像,两种不同的软件实现通常也会产生不同的特征值。这是因为缺 乏具有可验证参考值的影像组学特征的标准化定义,并且计算特征所需的图像处 理方案没有一致地实施。报告不够详细,无法再现研究和发现,更加剧了这种情 况。
我们提出了图像生物标志物标准化倡议(IBSI),通过实现以下目标来应对这些 挑战:(a)建立常用影像组学特征的术语和定义;(b)建立一个通用的影像 组学图像处理方案,用于计算影像特征;©为图像处理和特征计算的软件实 现的验证和校准提供数据集和相关参考值;(d)为涉及影像组学分析的研究提 供一套报告指南。
二、材料和方法:
研究设计:我们将当前的工作分为三个阶段(图 1)。前两个阶段侧重于迭代标 准化,然后第三个是验证阶段。在第一阶段,主要目标是在没有任何额外图像处 理的情况下,标准化影像组学特征定义并定义参考值。在第二阶段中,我们定义 了一个通用的影像组学图像处理方案,并获得了不同图像处理配置下特征的参考
值。在第三阶段,我们评估了在前几个阶段进行的标准化特征值是否会在验证数 据集可再现。
研究团队:我们邀请了影像组学研究人员在 IBSI 中进行合作。参与是自愿的, 在研究期间是开放的。如果团队(a)开发了自己的图像处理和特征计算软件, 并且(b)可以参与研究的任何阶段,那么他们是合格的。
图 1,研究概述流程图。
典型的影像组学分析的工作流程始于医学图像的采集和重建。随后,分割图像以 定义感兴趣区域(ROI)。之后,使用影响组学软件处理图像并计算 ROI 特征。 我们专注于标准化图像处理和特征计算步骤。标准化在两个迭代阶段进行。
在第一阶段,我们使用了一个专门设计的数字模型来直接获得影像组学特征的参 考值。
在第二阶段中,使用公开的肺癌患者 CT 图像,以获得标准化常规放射影像处理 方案预定义下特征的参考值。
在第三阶段,通过评估 51 例软组织肉瘤患者的公开多模态患者队列中标准化特 征的再现性,对影像组学软件中图像处理和特征计算步骤的标准化进行了前瞻性 验证。18F-FDG=氟 18-氟脱氧葡萄糖,T1w=T1 加权。
影像组学特征:我们定义了一组 174 个影像组学特征。(表 1)这组特征通常用 于量化三维图像中感兴趣区域(ROI)中的形态特征、一阶统计特征和体素(纹 理)之间的空间关系。为了计算纹理特征,需要额外的特征特定参数。这使计算 特征的数量超过了 174 个。IBSI 参考手册第 3 章提供了所有特征定义。
表 1,所包含影像组学特征概述
通用影像组学图像处理方案:根据以往研究,我们定义了一个通用的影像组学图 像处理方案。该方案包含从重建图像计算特征所需的主要处理步骤,如图 2 所示。 有关这些图像处理步骤的完整说明,请参见 IBSI 参考手册(在线)第 2 章。
数据集:每个阶段使用不同的数据集。在第一阶段,我们设计了一个小的 80 体 素三维数字模型,带有 74 体素 ROI mask,以便于在不涉及图像预处理的情况下 为特征建立参考值。
在第二阶段,我们使用了一名肺癌患者被公开的 CT 图像。同时对肿瘤全脑图像 进行分割作为 ROI。
III 期使用的验证数据集由 51 名软组织肉瘤患者组成,他们接受了肿瘤成像方式 中的多模态成像(包括 CT、18 氟脱氧葡萄糖 PET 和 T1 加权 MRI)。每幅图像 后续都进行了肿瘤组织分割,作为 ROI。PET 和 MRI 集中预处理,以确保标准 化转换和偏倚场校正步骤不会影响验证。
定义特征参考值有效性的标准:在前两个阶段,研究团队直接从相关图像数据集 中的 ROI 计算特征值(第一阶段),并且根据预定义的图像处理参数计算特征 值(第二阶段)。收集每个团队提交的所有最新值,并限制为三个有效数字。然 后,我们使用每个特征提取值作为暂定参考值。
我们使用两种方法对每个特征的暂定参考值的有效性的一致性水平进行量化:(a) 提取的值与允许范围内的暂定参考值相匹配的研究团队的数量;(b)之前的数字 除以提交值的。
图 2,用于计算影像组学特征的一般处理方法的流程图。
图像处理从重建图像开始。这些图像通过几个可选步骤进行处理:数据转换(例 如,转换为标准值)、图像采集后处理(例如,图像去噪)和图像插值。在分割 步骤中自动创建感兴趣区域(ROI),或者检索现有的 ROI。然后对 ROI 进行插 值,并将强度和形态掩膜创建为副本。可根据强度值对强度掩模进行重新划分, 以提高队列中强度范围的可比性。然后,根据 ROI 及其邻近区域(局部强度特
征)或 ROI 本身(所有其他特征)掩膜的图像计算影像组学特征。此外,在计 算根据强度直方图(IH)、强度体积直方图(IVH)、灰度共生矩阵(GLCM)、 灰度游程长度矩阵(GLRLM)、灰度大小区域矩阵(GLSZM)、灰度距离区域 矩阵(GLDZM)、邻域灰度差矩阵(NGTDM)特征之前,对图像强度进行离 散化,以及邻接灰度相关矩阵(NGLDM)族。本研究评估了从图像插值到影像 组学特征计算的所有处理步骤。
研究团队总数。根据第一个一致性度量,分配了四个一致性级别,如下所示:少 于三个,弱;三到五个,中等;六到九个,强;10 个或更多,非常强。第二步 的方法评估了一致的稳定性。我们认为一个特征的暂定参考值只有在它至少有适 度的一致性并且它被贡献研究团队的绝对多数(超过 50%)使用时才有效。
迭代标准化过程:在前两个阶段中,我们反复完善了关于特征参考值有效的一致 性。该迭代过程同时用于标准化特征定义和一般的影像图像预处理方法。在迭代 过程开始时,我们提供了初始定义的特征(第一阶段)和一般影像组学图像预处 理方法(第二阶段)。对于第一阶段,我们手动计算除形态学特征外所有特征的 精确参考值,以验证研究团队得出的值。对于第二阶段,我们定义了五种不同的 图像处理方法(方法 A–E),涵盖了影像组学研究中常用的一系列图像处理参数 和方法。
在最初的总结之后,我们要求研究团队根据项目中的数字图像的 ROI 计算特征 值(第一阶段);根据不同的预定义图像处理方法,对处理后的肺癌 CT 图像中 的 ROI 提取特征值(第二阶段)。收集并处理特征值,以分析关于暂定参考值 有效的一致性。然后,平均每 4 周提供一次结果。研究负责人还将在将其提交的 特征值与数学上精确的值(仅第一阶段)以及与其他团队获得的特征值(第一阶 段和第二阶段)进行比较后,与团队联系并提供反馈。研究小组以问题和建议的 形式提供反馈,涉及影像组学特征的说明和影像组学软件的标准化。因此,反馈 结果的工作文件定期更新。然后,团队将根据分析结果和研究负责人的反馈对其 软件进行更改。
这两个迭代阶段是交错的,以便更容易地将与特征计算相关的差异和错误与与图 像处理相关的差异和错误分开。2016 年 9 月对第一阶段的初始贡献进行了分析。 在对至少 70%的特征的参考值的有效性达成中等或更好的一致后,即时间点 6 (2017 年 1 月),我们启动了第二阶段。在时间点 10(2017 年 4 月)对第二阶 段的初始结果进行了分析。之后,第一阶段和第二阶段同时进行。我们在时间点 25(2019 年 3 月)就第一阶段和第二阶段 90%以上的特征的参考值的有效性达 成强烈或更好的共识后,停止了迭代标准化过程。
验证:标准化过程完成后,我们要求研究团队计算肿瘤区的 174 个特征,使用预 定义的图像处理配置,对软组织肉瘤验证队列中的每个图像进行体积分析。计算 出的特征值集中收集和处理,如下所示。首先,对于每个团队,我们删除了他们 的软件没有标准化的任何特征。为此,我们将各个特征的参考值与研究小组在图 像处理配置 C、D 和 E(如 II 期)下从肺癌患者的 CT 图像中获得的值进行了比 较。如果某个值与其参考值不匹配,则不使用该特征。随后使用双向、随机效应、 单评分、绝对一致性
组内相关系数(ICC):评估剩余标准化特征的再现性。根据 Koo 和 Li 的建议, 使用 ICC 值 95%置信区间的下限,将每个特征的再现性分配给以下类别之一: 较差,下限值小于 0.50;中等,下限值大于或等于 0.50 并小于 0.75;良好:下限值 大于 0.75 且小于 0.90;非常好,下限值大于 0.90。
三、结果
参与研究团队的特点:共有 25 支团队。15 个团队参与了两个标准化阶段,9 个 团队参与了验证阶段。一个团队退出了,因为他们转而使用另一个团队开发的软 件。五个团队实现了 95%或更多的已定义功能。在第二阶段,九个团队能够计算 所有图像处理配置的特征。
图 3,条形图描述了研究团队的参与情况和影像组学特征覆盖范围。
A、图表显示了迭代标准化过程两个阶段中每个分析时间点的研究团队数量。团 队在没有事先图像处理(第一阶段)和图像处理(第二阶段)的情况下计算特征, 目的是找到特征的参考值。在每个时间点评估参考值有效的一致性,时间间隔是 可变的。
B、图中显示了每个团队在第一阶段实施的影像组学功能的最终覆盖范围,以及 团队重现参考值的能力。
格罗宁根大学医学中心和法国国家卫生与医学研究所各提供了三组和两组研究 人员。这并不影响对特征参考值有效性的共识。关于参考值有效性的中等、强烈 或非常强烈的共识分别基于至少三个、五个和八个不同顶级机构的团队。Matlab (n=10)、C++(n=7)和 Python(n=5)是最流行的编程语言。未发现语言依赖
性;所有特性在其参考值的有效性方面具有中等或更好的一致性,这是基于多种 编程语言的。
关于特征参考值有效性的共识:如图 4 和表 2 所示,在研究过程中,对特征参考 值有效性的共识有所改善。最初,对于大多数特征只有微弱的一致性:第一阶段 和第二阶段的 302 个特征中有 232 个(76.8%)和 1075 个特征中有 703 个(65.4%)。
在最终分析时间点,一致性较弱的特征数量在第一阶段减少到 487 个特征中的两 个(0.4%),在第二阶段减少到 1347 个特征中的 19 个(1.4%)。对其(暂定) 参考值的有效性缺乏一致意见的其余特征是定向最小边界框和最小体积封闭椭 球体的面积和体积密度。我们无法标准化计算定向最小包围盒和最小体积包围椭 球体所需的复杂算法。因此,之前的特征不应被视为标准化。
如表 2 所示,在第一阶段和第二阶段,487 个特征中的 463 个(95.1%)和 1347 个特征中的 1220 个(90.6%)可以建立强有力或更好的共识。这些特征中没有 一个是不稳定的。在第二阶段,108 个(1.9%)具有中度一致性的特征中有两个 不稳定。两者都源自相同的特征:强度-体积直方图曲线下的面积。因此,我们 不认为这个特性是标准化的。最常用的实现特征是平均值、偏度、过度峰度和基 于强度的统计族的最小值。在 24 个研究小组中,有 23 个小组实施了这些方法。
图 4,条形图描述了关于影像组学特征参考值有效性的共识的迭代发展。
我们试图在一个迭代的标准化过程中找到影像组学特征的可靠参考值。在第一阶 段,特征是在没有事先进行图像处理的情况下计算的,而在第二阶段,特征是在 使用五种预定义配置下(配置 A-E;)进行图像处理后进行评估的。根据图像处 理配置,A,在第一阶段和第二阶段(暂定)参考值在有效性方面达成一致性的 总体发展,B,在第二阶段达成一致的发展。关于参考值有效的一致性是基于为 特征产生相同值的研究团队的数量(弱: 三;中等:三到五;强壮:六到九; 非常强壮:十).我们分析了每个分析时间点的一致性,时间间隔是可变的。在时 间点 5 和 22 加入了新的特征,导致共识明显减少。对于第二阶段,我们首先在 时间点 10 分析一致性。图像处理配置 C 和 D 在时间点 16 后改变。在时间点 22 修改重新分段处理步骤之后,配置 E 被改变。
表 2,在第一阶段和第二阶段的初始和最终分析时间点,就影像组学特征参考值 的有效性达成共识。
图 5,条形图显示了标准化影像组学特征的再现性。
我们根据研究团队计算的特征值,使用多模式成像(CT、18 氟脱氧葡萄糖 PET 和 T1 加权 MRI;图示为 CT、PET 和 MRI)评估了 51 例软组织肉瘤患者验证队 列中 169 个标准化特征的可重复性。我们根据双向随机效应 95%置信区间的下边 界,将每个特征分配给一个再现性类别,单一评分者,特征的绝对一致性组内相 关系数(差:0.50;中等:0.50–0.75;好:0.75–0.90;优秀:大于 0. 90)。在本 研究中,有五个特征无法标准化。在验证期间,不到两个团队计算了两个具有未 知再现性的特征。
标准化特征的再现性:我们能够找到 174 个特征中 169 个具有中等或更好一致性 的稳定参考值。在验证阶段,可以很好地再现这些特征。CT、PET 和 MRI 的 174
个特征中的 166 个、174 个特征中的 164 个和 174 个特征中的 164 个具有良好的 再现性。174 个(CT)特征中的一个和 174 个(PET 和 MRI)特征中的三个具 有良好的再现性。对于每种模态,174 个特征中有两个具有未知的再现性,这表 明它们在验证期间由少于两个团队计算。这些特征是 Moran 的 I 指数和 Geary 的 C 度量。虽然它们是标准化的,但计算起来很麻烦。174 个特征中的其余 5 个在 前两个阶段无法标准化,在验证期间未进行评估。
四、讨论
在这项研究中,图像生物标志物标准化倡议(IBSI)产生并验证了一组基于一致 性的影像组学特征参考值。二十五个研究团队能够标准化 174 个特征中的 169 个,这些特征随后在验证数据集中被证明具有良好到极好的再现性。随着当前工 作的完成,可以检查任何影像组学软件是否符合 IBSI 标准,如下所示:首先, 使用软件基于数字图像计算特征。将结果值与 IBSI 参考手册和为此目的创建的 合规性检查电子表格中的参考值进行比较。分析出现的任何差异性。
随后,解决或解释这些差异性。然后,基于本研究中使用的 CT 数据集和第二阶 段中使用的一个或多个图像处理配置重复上述步骤。对于许多特征的参考值的有 效性,最初的一致性很弱,这意味着团队对同一特征获得了不同的值。这与其他 地方报道的结果相似。偏差的几个显著原因如下:例如,插值差异、ROI 的形态 表示和命名差异(随后得到解决)。实际上,我们交叉验证了影像组学软件结果。
大多数影像组学研究的结果尚未转化为临床实践,需要在临床试验中进行外部回 顾性和前瞻性验证。除了所介绍的研究工作之外,IBSI 还定义了报告指南,指 出了为促进这一过程而应报告的要素。然而,出于几个原因,我们没有就如何进 行良好的影像组学分析提出全面的建议。首先,这类建议将需要针对具体的方式, 并可能针对具体的实体。关于特定影响的相关参数,例如,插值算法的选择,远 远还未实现。其次,关于影像组学分析的建议或指南已在其他地方全面涵盖,例 如,对个体预后的多变量预测模型的报告或诊断和预后模型的诊断声明。当然, 在第二阶段中使用的图像处理方法并非用于一般用途,因为它们的主要目的是涵 盖一系列不同的方法。
我们的研究有几个局限性。首先,我们的目的是为影像组学特征的标准化计算打 下基础。为此,我们试图将 174 个常用特征标准化,并使用影像组学研究人员最 常用的图像处理方法获得参考值。为了保持范围可控,许多其他特性比如分形和 图像滤波器没有进行评估,未对重要的模态特定图像处理步骤进行基准测试,也 未对不常见的图像处理方法进行调查。这是一个严重的局限性,也是 IBSI 目前 正在解决的问题。
尽管标准化特征计算是实现影像组学可再现性的重要一步,但仍需要与图像采集 重建和分割相关的标准化进行协调,因为这些是构成影像组学研究的额外可变性 来源。由于这种可变性,在多中心或多扫描设置下,可使用标准化影像组学软件 从同一图像复制的特征可能仍然缺乏再现性。我们没有在这里讨论这些问题,因 为它们的全面一致性是其他团队和专业协会持续关注的焦点。我们还提出了其他 方法来解决这些问题,例如使用统计方法减少对影像组学特征的队列效应,把人 工智能应用在 CT 图像重建和转换中。
总之,图像生物标记物标准化倡议能够产生和验证影像组学特征的参考值。这些 参考值能够验证影像组学软件,这将提高放射组学研究的再现性,并促进影像 组学的临床应用。
常见的医学影像数据格式
医学影像学Medical Imaging,是研究借助于某种介质(如X射线、电磁场、超声波等)与人体相互作用,把人体内部组织器官结构、密度以影像方式表现出来,供诊断医师根据影像提供的信息进行判断,从而对人体健康状况进行评价的一门科学,包括医学成像系统和医学图像处理两方面相对独立的研究方向。
1、 脑成像数据模态:脑成像数据主要有DTI、FMRI、3D三种模态。其中,DTI,3DT1是三维数据,FMRI是四维数据。
(1)DTI:Diffusion Tensor Imaging,磁共振弥散张量成像。
(2)FMRI:Functional Magnetic Resonance Imaging,功能性磁共振成像。
2、DICOM格式
DICOM(Digital Imaging and Communications in Medicine)即医学数字成像和通信,是医学图像和相关信息的国际标准(ISO 12052)。它定义了质量能满足临床需要的可用于数据交换的医学图像格式。DICOM被广泛应用于放射医疗,心血管成像以及放射诊疗诊断设备(X射线,CT,核磁共振,超声等),并且在眼科和牙科等其它医学领域得到越来越深入广泛的应。在数以万计的在用医学成像设备中,DICOM是部署最为广泛的医疗信息标准之一。当前大约有百亿级符合DICOM标准的医学图像用于临床使用。
3、 MRI和fMRI
(1)MRI磁共振成像(magnetic resonance imaging)扫的是大脑的结构图像,也叫T1权重图像。它有着很高的空间分辨率,可以从中看到非常清晰的解剖结构,也可以从中区分出各种不同的组织。
(2)fMRI功能性磁共振成像(Functional magnetic resonance imaging)往往用于研究大脑的具体功能,扫出来的是功能图像,也叫做T2*权重图像。虽然它的空间分辨率比较低,但是时间分辨率很高,可以在很短的时间内扫出一叠功能图像。这样就可以研究实验操作究竟是如何影响大脑的MRI信号的。 fMRI数据预处理 步骤包括:可视化(Visualization)、去伪影(Artifact removal)、时间配准(Slice time correction)、头动校正(Motion correction)、生理噪音校正(Correction for physiological effect)、结构功能配准(Co-registration)、标准化(Normalization)和时空间滤波(Spatial and temporal filtering);
4、Analyze格式
储存的每组数据组包含2个文件,一个为数据文件,其扩展名为.img,包含二进制的图像资料;另外一个为头文件,扩展名为.hdr,包含图像的元数据。在fMRI的早期,Analyze格式最常用的格式,但现在逐渐被NIfTI格式所取代。Analyze格式主要不足就是头文件不能真正反映元数据。
5、NIfTI格式
标准NIfTI图像的扩展名是.nii,包含了头文件及图像资料。由于NIfTI格式和Analyze格式的关系,因此NIfTI格式也可使用独立的图像文件(.img)和头文件(.hdr)。单独的.nii格式文件的优势就是可以用标准的压缩软件(如gzip),而且一些分析软件包(比如FSL)可以直接读取和写入压缩的.nii文件(扩展名为.nii.gz)。
第6节 配准及基于atlas感兴趣区提取
12:30 分享:影像组学分析流程梳理
16:30 加餐:关于胶质母细胞瘤的影像组学和影像基因组学
本文来自——CSDN(思影)但是分享GBM综述的目的就是,各个癌种的影像组学综述还是不少的,大家可以找找自己研究的癌种的高质量综述,来看看目前解决了什么问题,技术发展到哪一步,以及有什么问题没被解决。还要看他的参考文献,会得到不少启发;
第7节 影像组学特征提取
12:30 分享:使用3D Slicer软件提取影像组学特征
16:30 加餐:基于2D超声影像的影像组学特征提取
一篇GBM的影像组学和影像基因组学综述
在当今的现代成像时代,准确无创地预测胶质瘤的级别/类型、生存率和治疗反应仍然具有挑战性。虽然立体定向活检具有侵入性且成本高昂,但仍然是组织学和遗传学分类的参考标准;然而,在7%-15%的患者中,病理诊断可能仍然不确定。这就需要成像标志物来描述肿瘤的异质性。最近,多项研究表明,多参数磁共振成像(MRI)的形态学特征与生存率之间存在密切联系。同样地,功能成像技术如灌注加权MRI和磁共振波谱(MRS)与形态学特征一起使用时,已被证明是有效的,但成功率和再现性有限。当前成像技术的局限性为更复杂的亚视觉特征分析提供了机会,以增强形态学特征和当前功能成像的能力。
影像组学是指通过计算机从影像图像中提取可量化数据,其形式为通常为亚视觉的影像图像特征。这些提取的数据在影像学图像中创建了可挖掘的数据库,可用于诊断、预后特征描述,以及评估或预测对某些疗法的反应。基因突变通常决定肿瘤的侵袭性,并已被证明与病变的生长模式和治疗反应有关。影像特征已被证明可以识别肿瘤DNA和RNA中的基因组改变。对来自影像学和基因组的数据的综合研究被称为影像基因组学。在这篇综述中,我们从神经影像学家、神经外科医生和神经肿瘤学家的角度描述了影像组学和影像基因组学的应用。具体来说,我们回顾了一些工作,这些工作强调了在诊断和预测不同类型脑肿瘤患者预后方面不断发展的重要性。此外,我们还讨论了将这些方法集成到影像工作流程中以改善患者护理和预后的潜力和重要性。
影像组学是一个新兴的领域,涉及以高通量方式将影像影像图像转换为高维的可挖掘的数据。这个多步骤过程包括:(a)图像采集和重建,(b)图像预处理,(c)感兴趣区域的分割,(d)特征提取和量化,(e)特征选择,以及(f)使用机器学习建立预测和预测模型(图1)。
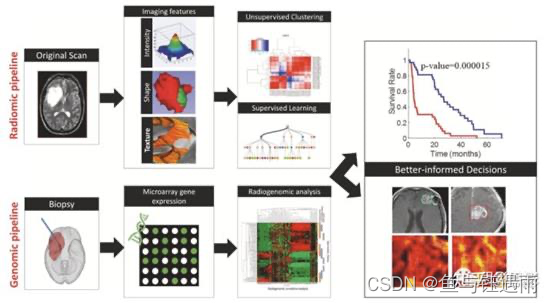
为了解释MRI强度的不均匀性、不同中心扫描仪的可变性,特征提取前需要进行图像预处理方法(例如强度归一化、体素强度校准和偏置场校正)。感兴趣区域(ROI)的分割可以通过手动、半自动或全自动方法实现。然后从已分割的ROI中提取影像组学特征。常见特征可分为以下几组:形态特征、纹理特征和功能特征。在特征提取之后,使用不同的统计方法来选择与预期结果相关的显著特征子集。常用的特征选择算法包括:最小冗余最大相关(mRMR)算法和排序特征选择方法。进行特征选择是为了减少与高维特征集相关的潜在模型过度拟合。一旦确定了显著特征,机器学习分类器和其他统计方法(如Cox比例风险建模技术)将用于建立预测和预后模型。“影像组学质量评分”工具,用于评估与肿瘤生物学相关的影像组学研究的质量;然而,这些分数结果的可解释性仍然值得怀疑。
最近影像基因组学的出现也加速了多组学数据的整合,以实现准确诊断和改进个性化癌症治疗。神经肿瘤学影像基因组学的第一步(图1)是通过新鲜冷冻石蜡包埋(FFPE)样本或从脑肿瘤内立体定向脑活检获得的组织微阵列(TMA)样本获取基因组材料。其次,测序等生物信息学技术可以检测单基因突变。例如,表皮生长因子受体(EGFR)扩增、O6甲基鸟嘌呤甲基转移酶(MGMT)甲基化可以通过免疫组织化学(IHC)分析和下一代测序(NGS)技术(如mRNA测序)来检测蛋白质。mRNA测序、全外显子组测序和全基因组测序有助于检测多基因表达异常。影像基因组分析的决定性目标是将基因突变和通路与不同的影像学表型直接联系起来。
影像组学特征形态学特征
形态学影像学特征用于量化增生边界引起的病变浸润。这些特征可以进一步分为全局形态特征和局部形态特征。全局特征通过提取测量值(如圆度、周长、长轴和短轴直径以及延伸系数)来描述病变轮廓。局部形态特征表征了从等值面导出的曲面曲率属性。这些包括定量测量,如曲率(弯曲度)和锐度。
纹理特征结构纹理特征分析
结构方法通过识别结构特点及其排列规则来描述纹理。Gabor滤波器等多尺度、多分辨率可控带通滤波器是应用最广泛的基于方向的结构描述符。通过将原始图像分解为多个频率和方向的正弦波的滤波器响应,对Gabor描述符进行建模,以模拟人类视觉系统解码对象外观的方式。正如Doyle等人所证明的那样,Gabor过滤器可以在组织学样本上区分病理学特征。
统计纹理特征分析
统计方法通过计算每个图像点的局部特征,并从局部特征的分布中导出一组统计数据,来分析灰度值的空间分布。用于识别基于形状的对象类的一种常用统计技术是方向梯度直方图(HOG)。传统上,HOG的适用性已被证明适用于检测杂乱图像中的人体形态。多坐标HOG可以在高分辨率断层图像中区分不同类别的肺组织。它通过计算局部强度梯度的分布来描述局部对象的外观和形状。灰度共生矩阵(GLCM)功能通常被称为Haralick功能,最初设计用于航空摄影,利用距离和角度值进行灰度组合。结构和统计结合进行纹理特征分析 局部二元模式(LBP)是一种纹理算子,它将统计和结构方法结合在外观分类中。LBP对于因患者运动伪影而影响的图像具有鲁棒性。该特征将纹理信息表示为中心像素及其相邻像素强度的联合分布。Li等人展示了LBP和神经网络在内窥镜图像分类中的应用。结合统计和结构技术的另一个特征是局部各向异性梯度方向(CoLlAGe)描述符,该描述符试图捕获和利用体素水平梯度方向中的局部各向异性差异来区分相似的表现型。
功能影像组学
传统影像特征临床应用的一个关键障碍是其生物学解释性低。作为生物标志物,属性不仅应该是可测量和可复制的,而且还应该反映潜在的解剖或生理学意义。迫切需要发现与生物学相关的影像特征。功能性影像标记物是一类新的标记物,通过模拟直接捕捉血管生成等潜在生理特性的特征,专门针对“可解释性”问题。为病变供血的血管的特性(如卷曲度、密度)在药物的最终反应中起着重要作用。最近,基于扭曲度的特征捕捉血管网络排列中的局部和全局紊乱已被证明在诊断和治疗反应评估中是有效的。形变描述符是另一类功能性影像组学标记物,旨在测量由于质量效应而导致的脑实质组织变形。这些特征提供了对可见手术边缘外微环境的洞察。
血管构筑成像(VAI)MRI是一种无创测量参数以描述脑微血管结构异质性的技术。根据血管的结构和生理特性,不同的梯度回波(GE)和自旋回波(SE)图像在MRI读数中产生明显不同的变化。Stadlbauer等人使用血管构筑图(VAM)评估了胶质瘤(n=60)。他们引入了三种新的VAM生物标记物:(i)微血管类型指示物(MTI),(ii)血管诱导的团注峰值时间偏移(VIPS),以及(iii)曲率(Curv)和适应已知参数、微血管半径(RU)和密度(NU)。MTI和VIPS参数有助于检测新生血管,尤其是HGGs(高级别神经胶质瘤)肿瘤核心的新生血管,而曲率显示瘤周血管源性水肿,与HGG肿瘤核心的新生血管相关。这些生物标记物可以深入了解胶质瘤血管变化的复杂性和异质性,从而区分HGG和LGG。此外,将多参数定量血氧水平依赖性方法(qBOLD)与VAM参数相结合,有助于区分LGGs和HGGs,并以更高的灵敏度识别异柠檬酸脱氢酶(IDH)突变状态。Stadlbauer等人还结合VAM生物标记物对血管滞后环(VHLs)进行了分析,以评估胶质母细胞瘤对抗血管生成治疗的反应。MTI被发现有助于预测有反应区域和无反应区域,而Curv更适合评估血管源性水肿的严重程度。Price等人使用弥散张量成像(DTI)结合MR灌注和MRS成像来确定胶质母细胞瘤侵袭性和非侵袭性边缘的变化,以更好地预测治疗效果和总体生存率。
语义特征语义特征,如肿瘤位置、形状和结构MRI上的几何特征,是神经影像学家用来描述肿瘤环境的定性特征。
以往的研究发现,语义特征与脑肿瘤的遗传表型有关。TCIA的视觉可访问伦勃朗图像(VASARI)项目建立了一个特征集,以便使用一组定义的视觉特征和受控词汇对胶质瘤进行一致的描述。研究表明,这些特征具有高度的可重复性,为胶质母细胞瘤的治疗提供了有意义的指导。语义特征对图像采集参数和噪声的变化也具有鲁棒性,可以与机器学习环境中更复杂的影像特征一起使用。
诊断应用基于纹理特征的不同肿瘤
许多研究表明,织构分析可用于区分HGG和LGG。Skogen等人。应用过滤直方图技术描述肿瘤异质性。在95名患者(27名II级、34名III级和34名IV级)的队列中,通过使用精细结构量表的标准差(SD),他们能够区分LGG和HGG,其敏感性和特异性分别为93%和81%(AUC 0.91,P<0.0001)。Tian59等人对153名患者的多参数MRI进行了纹理分析,并报告使用SVM分类器对LGG和HGG进行分类的准确率为96.8%,对III级和IV级进行分类的准确率为98.1%。Xie等人评估了42例胶质瘤患者动态增强磁共振((DCE)-MRI)的五种GLCM特征。他们报告说,熵(AUC=0.885)和IDM(AUC=0.901)分别能够区分III级和IV级胶质瘤,以及II级和III级胶质瘤。
局限性
限制影像量的一个主要特征是,由于缺乏标准化采集参数和研究方法,可变性和缺少一致性导致的再现性差。在不同的数据集上测试时,辐射特征的准确性通常会有所不同。已有多项研究探讨了不同采集参数对纹理分析的影响。磁强度、翻转角度、不同的空间/矩阵大小、T1WI和T2WI中的TR/TE变化以及不同的扫描仪平台都会影响纹理特征。Molina等人发现,在动态范围变化下,没有纹理度量是稳健的,在空间分辨率变化下,熵是唯一稳健的特征。Buch等人得出结论,一些特征更为稳健,一些特征更容易受到不同采集参数的影响,因此需要使用标准化的MRI技术进行纹理分析。此外,纹理分析软件可用性的变化增加了标准化和再现性的复杂性。多个研究使用了不同算法的软件,使得这些研究的再现性和可重复性几乎不可能。需要进一步的研究来评估不同类型软件结果的准确性,以帮助标准化。
缺乏针对特定临床领域的带注释的影像学研究的公开数据库,限制了研究人员进行大样本研究的能力。小样本量和大量预测变量通常会导致过度拟合,这是机器学习模型的一个主要限制。为防止过度拟合,建议样本量比分析变量大6-10倍,或仅使用几个预选的稳健变量进行分析。研究型大学之间需要合作,为更大的队列研究创建专业注释的标准化数据集,这些数据集可以分为训练、测试和验证数据集,以避免过度拟合。这也将允许研究人员在外部队列上测试他们的算法,并验证他们的解决方案的稳健性。实现这一目标的一个最新进展是使用联邦学习,这有助于多机构验证机器学习模型,而无需使用分布式框架显式共享数据。 为特征提取选择适当感兴趣区域的可变性可能会影响某些影像组学属性,例如基于形状的度量。目前没有针对影像科医生报告定量成像特征的指南,这使得现有的大型图像存储库无法用于治疗。为了生成具有分段和注释的适当感兴趣区域的高质量数据,影像科医生需要成为数据量化和整理的组成部分。缺乏常规获取的基因表达谱和组织取样误差限制了基因表达谱的应用。单个研究所很难创建一个包含辅助数据的大型影像数据库,如基因组图谱、人口统计学、治疗信息及其结果。癌症基因组图谱(TCGA)公开了癌症数据集,并提供了全面的基因组图谱目录,以解决这一问题。影像基因组学的临床翻译也受到特定脑肿瘤内空间和时间异质性的阻碍。然而,影像组学对完整肿瘤进行分析的能力可能会解决这一局限性。
局限性
限制影像量的一个主要特征是,由于缺乏标准化采集参数和研究方法,可变性和缺少一致性导致的再现性差。在不同的数据集上测试时,辐射特征的准确性通常会有所不同。已有多项研究探讨了不同采集参数对纹理分析的影响。磁强度、翻转角度、不同的空间/矩阵大小、T1WI和T2WI中的TR/TE变化以及不同的扫描仪平台都会影响纹理特征。Molina等人发现,在动态范围变化下,没有纹理度量是稳健的,在空间分辨率变化下,熵是唯一稳健的特征。Buch等人得出结论,一些特征更为稳健,一些特征更容易受到不同采集参数的影响,因此需要使用标准化的MRI技术进行纹理分析。此外,纹理分析软件可用性的变化增加了标准化和再现性的复杂性。多个研究使用了不同算法的软件,使得这些研究的再现性和可重复性几乎不可能。需要进一步的研究来评估不同类型软件结果的准确性,以帮助标准化。















 1044
1044











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









