







在Web应用发展的初始阶段,关系型数据库被很多企业应用,因为那时候的Web站点访问和并发不高、交互也较少。随着互联网时代的发展,访问量的提升,使用关系型数据库的Web站点都在性能上出现了弊端。到如今云计算、大数据盛行的时代,对性能有了更多的需求,NoSQL应运而生,它同时具备了高性能、可扩展性强、高可用等优点,备受大众青睐。
Redis是现在最受欢迎的NoSQL数据库之一,Redis是一个使用C语言编写的开源、包含多种数据结构、支持网络、基于内存、可选持久性的键值对(key-value)存储数据库。
1整体介绍
Redis可以作为缓存来缓解DB压力,数据结构丰富,可以应对多种场景;并且支持持久化,可以通过RDB以及AOF的方式来做故障恢复;Redis还可以用来做分布式锁等等。
1.1应用场景
缓存:毫无疑问这是Redis当今最为人熟知的使用场景,在提升服务器性能方面非常有效。
排行榜:使用传统的关系型数据库(mysqloracle等)来做这个功能,非常麻烦,而利用Redis的SortSet(有序集合)数据结构能够简单地搞定;
计算器/限速器:利用Redis中原子性的自增操作,我们可以统计类似用户点赞数、用户访问数等;限速器比较典型的使用场景是限制某个用户访问某个API的频率,常用的有抢购时,防止用户疯狂点击带来不必要的压力;
好友关系:利用集合的一些命令,比如求交集、并集、差集等。方便搞定一些共同好友、共同爱好之类的功能;
简单消息队列:除了Redis自身的发布/订阅模式,我们也可以利用List来实现一个队列机制,比如:到货通知、邮件发送之类的需求,不需要高可靠,但是会带来非常大的DB压力,完全可以用List来完成异步解耦;
Session共享:以PHP为例,默认Session是保存在服务器的文件中,如果是集群服务,同一个用户过来可能落在不同机器上,就会导致用户频繁登陆;采用Redis保存Session后,无论用户落在哪台机器上都能获取对应的Session信息。
一些频繁被访问的数据如果放在关系型数据库,每次查询的开销都会很大,而放在redis中,因为redis是放在内存中的可以很高效的访问。
1.2数据类型
String:是一个二进制安全的字符串,意味着它不仅能够存储字符串、还能存储图片、视频等多种类型,最大长度支持512M。
Hash:是由field和关联的value组成的map。其中,field和value都是字符串类型的。
List:是一个插入顺序排序的字符串元素集合,基于双链表实现。
Set:是一种无序集合,它和List类型最大的区别是:集合中的元素没有顺序,且元素是唯一的,底层是通过哈希表实现的。
ZSet:是一种有序集合,每个元素都会关联一个double类型的分数权值,通过这个权值来为集合中的成员进行从小到大的排序,底层也是通过哈希表实现的。
1.3优势特点
支持数据持久化,可以将内存中的数据保存在磁盘中,重启可再次加载使用。
支持简单的Key-Value类型的数据,同时还提供List、Set、Zset、Hash等数据结构的存储。
支持数据的备份,即Master-Slave模式的数据备份。
2安装配置
下面介绍在linux系统环境中,安装配置Redis的具体步骤和验证说明。
2.1环境准备
1.更新linux自带的gcc与make:


2.如果wget提示无此命令,需要安装wget:
1)检查wget是否安装:

如下显示则已经安装:

2)如果没有显示则表示没有安装,需要通过以下命令安装:

Redis是通过ruby来启动集群的,因此要先安装ruby环境。以便后续启动集群:

安装结果如下:

2.2安装步骤
1.进入/usr/local目录:

2.下载redis压缩包:

3.解压:

4.进入对应解压出来的文件夹中进行编译安装:

至此Redis就编译安装完毕了,如果在第二台或多台服务器上进行集群部署,可以通过以上方式依次进行。
2.3配置调整
修改redis.conf文件:




2.4执行启动
启动命令:


3集群配置
下面介绍在linux系统环境中,安装配置Redis集群的具体步骤和验证说明。
3.1安装步骤
1.在第一台机器上/usr/local/redis-5.0.4目录下创建redis_cluster目录:

2.在redis_cluster目录下,创建名为7000、7001的目录,并将redis.conf拷贝到这两个目录中:

3.分别修改这两个配置文件,修改如下内容,注意备份:

4.接着在另外两台机器上重复以上三步,只是把目录改为7002、7003、7004、7005对应的修改配置文件中的IP和端口配置即可。
3.2执行启动
1.在第一台机器上执行,启用Redis节点,以下命令:

在其它两台机器上执行相同命令,启用Redis节点。
2.第一台机器 首先验证:

如下图显示:

3.监听redis端口 :

一个实例两个端口,比如:7000,17000,如下图显示:

简要的证明了redis已经启动成功。
3.3启动集群
1.Redis是通过ruby来启动集群的,在前置条件中已经安装完毕ruby,直接执行以下命令:

如果提示:

则意思是通过yum安装的ruby的版本不对,通过以下命令安装rvm--ruby的版本管理器,安装替换相应版本:
2.通过gpg命令生成一个可信任的证书,证书的ID从官网上获取:

3.通过curl方式按装rvm,在最后,rvm提示,“想要开始使用rvm运行以下命令…”:

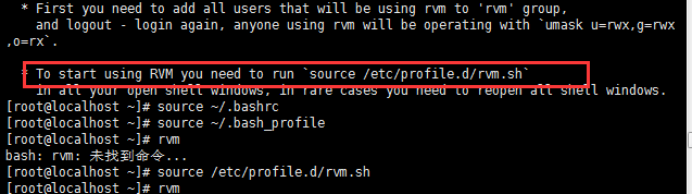
在相关环境生效时,rvm并不可用,只有在运行了提示中的内容,才会真正好用:

4.接着通过rvm先列举出已知的ruby版本,[ ]中代表这个版本的最高支持数量:


5.据上面的提示,需要安装2.2.2版本,直接安装2.2.2版本:


6.回到命令行,即成功安装了ruby的2.2.2版本,可以通过rvm检验是否安装:


7.提示说,方才安装的2.2.2版本是默认版本也是当前版本,如果不是执行:

则将2.2.2作为默认版本使用。这样再执行上方gem安装命令即可实现:
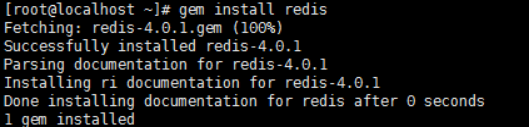
8.两台机器均要通过ruby进行安装redis:
在server1上执行:

其中,前三个ip:port为第一台机器的节点,后三个为第二台机器。
回显界面类似下图:

输入yes,然后出现如下内容,说明安装成功。

3.4测试验证
1.server1执行:

之后左侧变成“192.168.1.241:7000>”表示进入了redis的节点之后:

回显显示设置值成功:

2.在server2执行

查看redis中的信息798。

回显显示能够获取值,也证明集群是成功的。

查看集群信息:


查看节点信息:


3.如果集群报错,可以通过在每个节点下做以下两个命令;然后重新创建集群。

4心得体会
通过撰写本篇文档意识到了在实际项目工作过程中随手记录的重要性,在记录过后也需要相应的把记录内容整理到工作文档内,不断迭代完善自身能力,现从知识获取、意识形态、工作总结方面总结如下。
4.1知识收获
相比于其他数据库类型,Redis具备的特点是:C/S通讯模型、单进程单线程模型、丰富的数据类型、操作具有原子性、持久化、高并发读写、支持lua脚本。同时Redis克服了很多问题,例如:低延迟的读写速度,应用快速地反应能极大地提升用户的满意度;支撑海量的数据和流量,对于搜索这样大型应用而言,需要利用PB级别的数据和能应对百万级的流量;大规模集群的管理,系统管理员希望分布式应用能更简单的部署和管理;庞大运营成本的考量,IT部门希望在硬件成本、软件成本和人力成本能够有大幅度地降低。
4.2意识形态
伴随着自身专业知识的不断积累,对知识的认知也不断的提高。回过头来看自己之前记录的工作文档,会发现有很多漏点存在,这时就需要再次完善工作文档了。在这个完善的过程中,把初学时的理解和当下做了一个比较,可以了解到当时的自己有哪些不足,思维逻辑有了怎样改善。技术、认知在不断的更新,工作文档也在不断的更新,在这个不断迭代更新的过程中,使自己的知识点不知不觉连成了线。
4.3工作总结
在工作学习过程中通过不断地记录文档,可以从多方面提升自身的综合能力。一方面可以感觉到自己的逻辑思维有了显著地提升,尤其是在记录教程类的文档时,例如某些系统的使用手册。可以重新捋一遍系统的技术要点,通过对系统梳理,过程中可以不断提高自己的逻辑思维。一方面在有了一个清晰的逻辑思维后,对自己的技术能力和水平都有了系统的提升。同时撰写文档也是一个总结、反思的过程,能够帮助个人促进深入思考的能力。
通过实际参与项目,在服务器上安装配置Redis/Redis集群,不仅能提高对Redis/Redis集群安装部署的经验,也能加深对Redis知识的理解,后续也会继续整理相关的技术文档,迭代提升自身的工作能力,为后续的职业生涯奠定扎实的基础。
















 1170
1170











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









