



摘要
Transformer 由于其强大的表征能力以及长序列的建模能力,已经成为 NLP 领域最通用的 back-bone, 而近期transfomer 在视觉领域也取得了十分可喜的进展,自 vit,deit,detr 等工作提出以来,各种视觉 transformer 层出不穷,成功提升了各种视觉任务的性能。视频分类(动作识别)在视频表征学习领域是十分通用的下游任务,本文重点关注针对视频分类的视觉 transfomer,列举总结了不同的方法以及它们的区别与联系。本文首先简要介绍一下视觉 transformer 和视频分类的背景,然后介绍几种针对视频分类的视觉 transformer。
一、Vision Transformer
在视觉领域中,基于 CNN 的网络一直是主流的,其中 Resnet 是最通用的架构之一。但从目前视觉 transformer 的研究进展来看,transformer 对于视觉的表征学习也有巨大的潜力。一个经典的视觉transfomer 模型是 ViT,它将一个纯的 transformer 直接应用于图像 patch 序列, 在图像分类任务上达到SOTA 性能。除了基本的图像分类任务,transformer 还被用于解决各种其他计算机视觉的任务,包括目标检测,语义分割,图像处理和视频理解等。由于其卓越的性能,越来越多的视觉 transformer 被提出,以改善更多的视觉任务。如何针对不同的任务以及 transformer 的特点设计出更好的视觉 transformer 是现在的研究热点。比如,transfomer 不同于 CNN 的一点是,CNN 引入了针对图像的归纳偏置(inductivebias),故有许多工作试图在 transformer 中也引入归纳偏置,如 swin transfomer 引入 shift window 来增加局部性。同时,由于 transformer 里面的自注意力机制是平方量级的计算量,也有许多视觉 transfomer的工作针对于计算量的问题,提出更高效的 transformer 架构。
二、Video Classification
视频分类一般指的是视频的动作识别任务,最传统的方法是用手工设计的特征将视频数据转换为可通过浅层线性模型进行分析的表征,这些特征包括 SIFT-3D,HOG3D,IDT 等。深度神经网络流行起来后,基于视频的动作识任务的标准解决方案是基于 CNN 的。可以大致分为两类: 基于 2D 和基于 3D 的方法。基于 2D 的方法独立处理每一帧,提取每帧的特征,然后在网络末端进行某种时间建模(例如 temporal pooling) 来实现时间维度的融合,这里面有一些很经典的工作,比如 TSN,使用双流模型,分别融合图像维度和时间维度的信息。将视频均匀分成多个片段,每个片段会输出一个分类得分,然后将所有片段的得分进行融合得到最终的结果。虽然基于 2D 的方法取得了不错的效果,但是它们的时空建模是分离的,使这类方法有一定的局限性。因此基于 3D 卷积的方法更受欢迎,因为 3D 卷积可以进行联合的时空建模。但相比于 2D 卷积,3D 卷积有更高的计算成本以及更大的参数量。于是有许多工作试图针对这个问题进行改进,如通过时间空间分解来降低计算量的 R(2+1)D,P3D 等。从头开始训练 3D 卷积网络是很困难的,于是 I3D 提出通过膨胀来从用 2D 网络的权重来初始化 3D 卷积网络的权重。之后还有许多针对 3D 卷积网络的改进如:non-local, 可分离卷积等(Video Classificationwith Channel-Separated Convolutional Networks)。基于卷积的方法虽然已经占据主流地位很久了,但是它也有自己的局限性,如卷积算子较小的感受野限制了长距离建模能力,而 transformer 中的自我注意机制拓宽了感受野,可以提高视频识别的性能。而且鉴于视觉 transformer 在图像领域的成功,将其拓展到视频领域是很自然的想法,于是有许多针对视频分类的 transformer 被提出。接下来挑选一些典型的进行介绍。
三、Vision Transformer for Video Classification
1. VTN
这篇文章首先使用 2D CNN 获取每帧的特征,然后对每帧的特征应用 Transformer 来学习时间维度的关系。VTN 使用的是 Longformer 来处理时间维度,可以处理长序列的 token, 相比于卷积,这种全局 attention 的机制可以对于输入的所有 token 进行信息融合。该框架还有一个好处就是其 2D 特征提取的模块可以随意替换,即可以基于不同的空间特征提取器建立模型。这样也解决了 3D 网络空间参数初始化的问题。
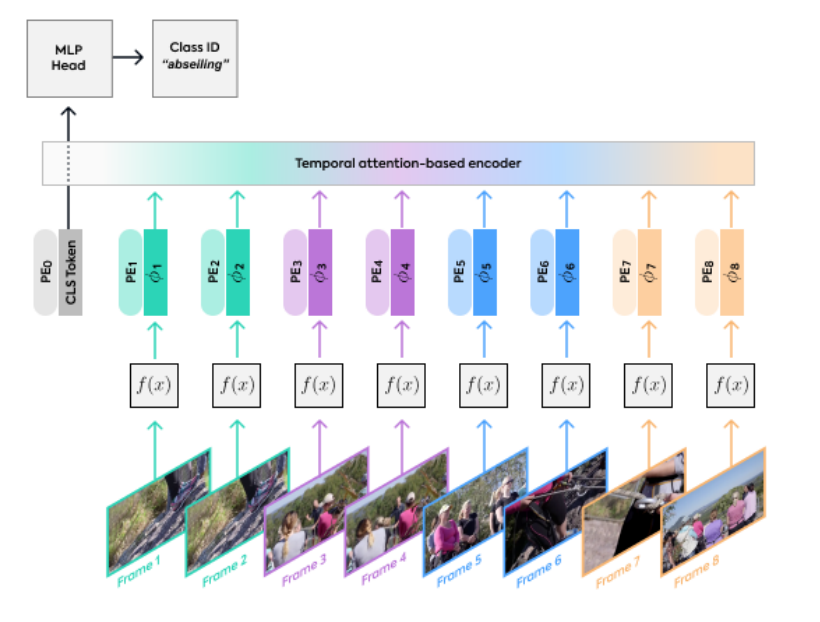
2. Vivit
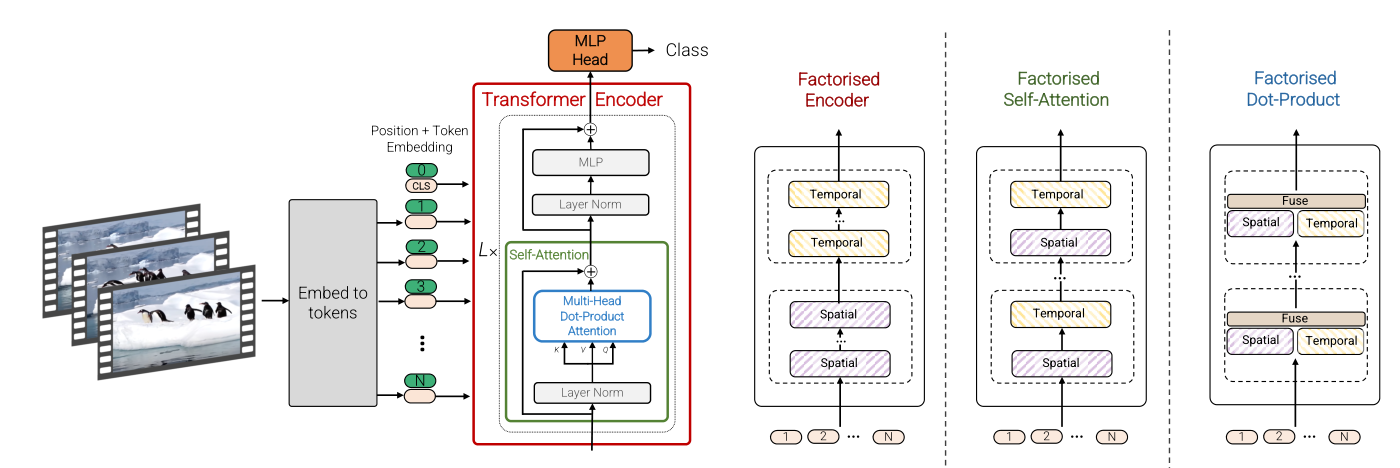
本文有两种输入方式,一种是最直接的方式:在输入的clip中均匀采样n帧然后将每帧按照vit中的方式划分成一个个patch输入embbedding网络生成patch embbedding再concatenate在一起。另一种输入方式是:时空同时采样取出一个cube,然后把这个3D cube经过投影网络映射为patch embedding.这样的方式能够更好地把时空信息融合在一起。对于网络结构的设计有以下四种:
-
spatial-temporal attention这种方式和vit的设置一样,把视频采样得到的时空token一起输入transformer encoder,即时间空间维度上的token会一起联合做self-attetion。这样能够最大程度上地融合时间信息,但是计算量会很大。
-
Factorised encoder这种方式把encoder划分成了两个部分,前一个部分是对同一帧图像内的token进行空间上的融合,后一部分encoder是对不同帧进行时间上的融合,这种”late-fusion”的方式大大减小了计算量
-
Factorised self-attention这个是在encoder内部进行时空划分,多头自注意力机制被分解为时间注意力+空间注意力,先后顺序没有关系。
-
Factorised dot-product attention最后这类2,3两种有一样计算复杂度,但是分解操作在MSA中操作。
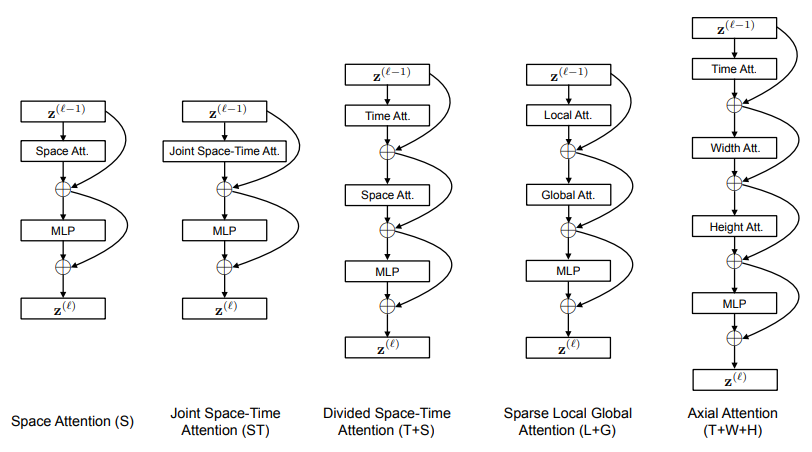
3. Timesformer
本文中实验了五种不同的 attention 机制:space attention,joint space-time attention,divided space-time attention,sparse local global attention ,axial attention. 最终发现的 divided space-time attention机制表现最佳。time attention 指:每个图像 patch 仅和其余帧在对应位置提取出的图像 patch 进行attention 操作。space attention 指:这个图像 patch 仅和同一帧的提取出的图像 patch 进行 attention操作
- Space Attention 只考虑帧内计算自注意力
- Joint Space-Time Attention 几帧联合计算注意力
- divided space-time attention 中,分别计算 space attetion 和 temporal attention
- Sparse Local Global Attention 不同于前面,它在空间上限制了只和相邻几个 patch 计算注意力
(引入了局部性和稀疏性) - Axial Attention 即把 space attention 进一步划分成了横向和纵向的 attention。

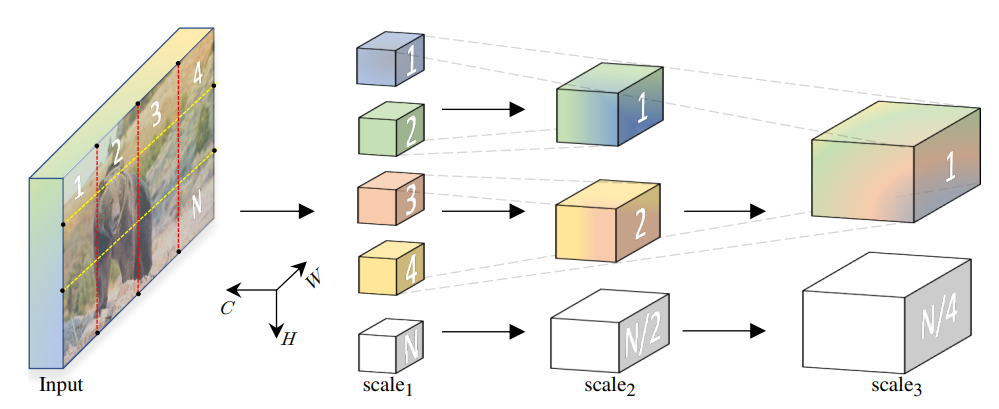
4. MVit
本文提出了用于视频和图像识别的多尺度视觉 Transformer,多尺度 Transformer 具有几个通道分辨率尺度阶段。从输入分辨率和较小的通道尺寸开始,这些阶段会在降低空间分辨率的同时分层扩展通道容量。这将创建一个多尺度的特征金字塔,其中早期的图层以高空间分辨率运行以对简单的低层视觉信息进行建模,而较深的图层则以空间粗糙但复杂的高维要素进行建模。
5. Video Swin Transformer
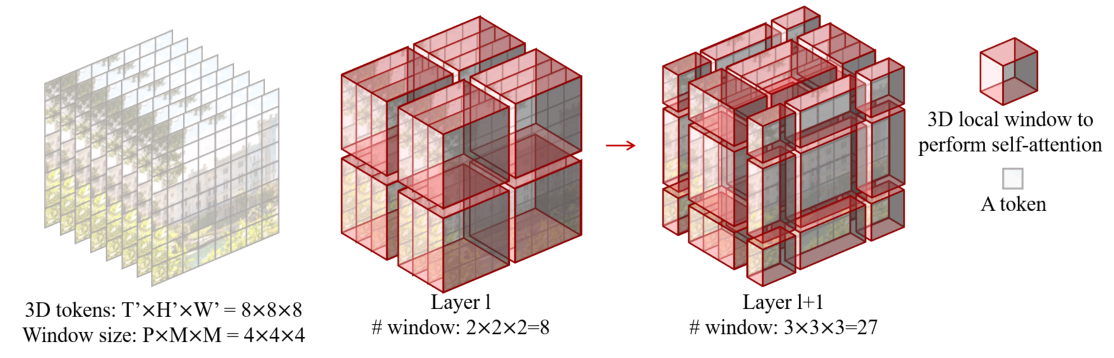
在本文中提出在视频 Transformer 中引入局部性的归纳偏置,这能使 Transformer 在速度和精度上达到更好的 trade-off,这在以前的那些基于捕获时空域上全局关系的 Transformer 上是做不到的,通过调整图像 Swin Transformer 来实现,这样可以使用强大的图像预训练模型。

四、总结
本文总结了几种典型的视频 transformer, 可以发现这些方法区别在于不同的网络架构设计以及自注意力机制的设计,可以发现在设计的同时精度与复杂度的 trade-off 是需要考虑的一个重要因素。现有的方法也有许多不足的地方,比如对于时空建模不够具有区分性,因为时空不是对称的,所以在两者的处理方面可以考虑更 specific 的设计。

















 2501
2501

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









