






 文章提出了一种名为掩码视频蒸馏(MVD)的方法,用于视频表示学习。MVD通过两阶段掩码特征建模,利用预训练的图像和视频模型作为教师,提供高级特征目标,从而学习更好的视频表示。发现不同教师在不同视频任务中产生不同属性的表示,图像教师强化空间信息,视频教师强调时间动态。通过时空协同教学策略,MVD在多个视频识别基准上展现出优于现有方法的性能。
文章提出了一种名为掩码视频蒸馏(MVD)的方法,用于视频表示学习。MVD通过两阶段掩码特征建模,利用预训练的图像和视频模型作为教师,提供高级特征目标,从而学习更好的视频表示。发现不同教师在不同视频任务中产生不同属性的表示,图像教师强化空间信息,视频教师强调时间动态。通过时空协同教学策略,MVD在多个视频识别基准上展现出优于现有方法的性能。
Abstract
得益于掩码视觉建模,自监督视频表示学习取得了显著进展。然而,现有的方法侧重于从头开始通过重建低级特征(如原始像素RGB值)来学习表示。在本文中,我们提出了一种简单而有效的用于视频表示学习的两阶段掩码特征建模框架——掩码视频蒸馏(MVD):首先,我们通过恢复掩码patch的低级特征来预训练图像(或视频)模型,然后将得到的特征作为目标进行掩码特征建模。对于教师模型的选择,我们观察到视频教师所教的学生在时间重的视频任务上表现更好,而图像教师在空间重的视频任务上转移了更强的空间表征。可视化分析还表明,不同的教师对学生产生不同的学习模式。基于这一观察结果,为了充分利用不同教师的优势,我们设计了一种MVD的时空协同教学方法。具体来说,我们通过掩码特征建模从视频教师和图像教师中蒸馏学生模型。大量的实验结果表明,使用时空协同教学预训练的视频transformer在大量视频数据集上优于使用单个教师蒸馏的模型。与以前的监督或自监督方法相比,我们的带有原始ViT的MVD在几个具有挑战性的视频下游任务上实现了最先进的性能。例如,使用ViT-Large模型,我们的MVD在Kinetics-400和Something-Something-v2上实现了86.4%和76.7%的Top-1准确率,分别比VideoMAE高1.2%和2.4%。当采用更大的ViT-Huge模型时,MVD在Something-Something-v2上达到了77.3%的Top-1精度,在AVA v2.2上达到了41.1的mAP精度。
1. Introduction
对于自监督视觉表示学习,最近的掩码图像建模(MIM)方法,如MAE[32]、BEiT[2]和PeCo[16]在各种视觉下游任务上使用视觉transformer[18]取得了令人满意的结果。这种预训练范式也适用于视频领域,与几个视频下游任务的监督预训练相比,它明显提高了视频transformer。代表性的掩模视频建模(MVM)作品有BEVT[69]、VideoMAE[63]和ST-MAE[22]。
继MAE[32]和BEiT[2]之后,现有的掩码视频建模方法[22,63,69]通过重建低级特征(如原始像素值或低级VQVAE token)来预训练视频transformer。然而,使用底层特征作为重建目标往往会产生很大的噪声。并且由于视频数据的高冗余性,掩码视频建模容易学习到捷径,从而导致对下游任务的传输性能有限。为了缓解这个问题,掩码视频建模[63]通常使用较大的遮罩比率。
在本文中,我们观察到,通过使用预训练的MIM和MVM模型的高级特征作为掩码预测目标进行掩码特征预测,可以在视频下游任务上获得更好的性能。这可以看作是两阶段的掩码视频建模,第一阶段获得MIM预训练图像模型(即图像教师)或MVM预训练视频模型(即视频教师),第二阶段通过提供高级特征目标进一步充当学生模型的教师。因此,我们称这种方法为掩码视频蒸馏(MVD)。
更有趣的是,我们发现不同教师在MVD中蒸馏的学生模型在不同的视频下游任务中表现出不同的属性。具体而言,从图像教师模型中蒸馏的学生在主要依赖空间线索的视频任务中表现更好,而从视频教师模型中蒸馏的学生在更需要时间动态的视频下游任务中表现更好。我们认为在第一阶段掩码视频建模的预训练过程中,视频教师已经在其高级特征中学习了时空语境。因此,当采用这种高级表征作为掩码特征建模的预测目标时,有助于鼓励学生模型学习更强的时间动态。类比而言,图像教师提供包含更多空间信息的高级特征作为目标,可以帮助学生模型学习更多有空间意义的表征。我们进一步分析图像教师和视频教师提供的特征目标,并计算跨帧特征相似度。这表明视频教师所提供的特征包含了更多的时间动态。
基于上述观察,为了充分发挥视频教师和图像教师的优势,我们提出了一种简单而有效的MVD时空协同教学策略。具体来说,学生模型的设计是用两种不同的解码器对来自图像教师和视频教师的特征进行重建,从而同时学习到更强的空间表征和时间动态性。实验表明,图像教师和视频教师共同教学的MVD在几个具有挑战性的下游任务上明显优于仅使用单个教师的MVD。
尽管简单,但我们的MVD联合教学非常有效,并在多个标准视频识别基准上实现了非常强大的性能。例如,在kinetics -400和Something-Something-v2数据集上,与没有MVD的基线相比,使用相同大小的教师模型进行400次MVD联合教学,在VIT-B上获得1.2%和2.8%的Top-1精度增益。如果使用更大的教师模型ViT-L,则可以获得更显著的绩效提升(即1.9%,4.0%)。当ViTLarge是目标学生模型时,我们的方法在这两个数据集上可以达到86.4%和76.7%的Top-1准确率,分别比现有最先进的方法VideoMAE[63]高出1.2%和2.4%。当采用更大的ViTHuge模型时,MVD在SomethingSomething-v2上达到了77.3%的Top-1精度,在AVA v2.2上达到了41.1 mAP。
我们的贡献可以总结如下:
**1.**我们发现使用MIM预训练图像模型和MVM预训练视频模型作为教师,为持续的掩码特征预测提供高级特征,可以学习到更好的视频表示。用图像教师和视频教师学习的表征在不同的下游视频数据集上表现出不同的属性。
**2.**我们提出了掩码视频蒸馏和简单而有效的协同教学策略,享受图像和视频教师的协同作用。
**3.**我们在多个标准视频识别基准上展示了强大的性能,超越了没有MVD的基线和之前最先进的方法。
2. Related Work
Vision transformers for video understanding.
对于视频理解任务,对时空信息进行建模是架构设计中最重要的考虑因素。在视频理解的早期工作中,常见的视频架构,如3D CNN[6、21、23、64、66]和具有时间模块的2D CNN[13、42、58、68、78],都是通过在时间维度上扩展现有的2D CNN模型来设计的。最近,视觉transformer[14,18,44]在几个计算机视觉任务上取得了重大进展。一些作品还将视觉transformer应用于视频领域,与以前基于cnn的架构相比,取得了更好的性能。例如,TimeSformer[4]和ViViT[1]研究了几种时空分解的变体,将普通的ViT架构扩展到视频领域。一些研究[5,52,55]进一步探讨了如何降低时空注意的计算成本。VideoSwin[45]和MViT[19,41]研究了分层结构,并在视频transformer中引入了归纳局域偏置。
Uniformer[39]和Video MobileFormer[70]出于效率考虑,提出将3D cnn与时空自注意机制相结合。为了在视频理解任务中取得令人信服的性能,大多数视频transformer都需要在大规模图像数据集上预训练模型权重。本文对视频transformer的自监督预训练进行了研究,发现预训练策略会显著影响下游性能,且与transformer的结构设计是正交的。
Self-supervised video representation learning.
自监督视频表示学习的早期工作[3,50,72,75]侧重于基于视频的时间结构设计借口任务。最近,对比学习[8,33,40]成为表示学习的新范式,它迫使同一图像样本的不同视图在特征空间中更接近,同时将不同图像的视图推得更远,一些作品[12,24,25,30,31,51,54]通过探索时空增强的有效方法,设计了视频域上的对比学习方法。然而,由于基于对比学习的学习监督应用于全局表示,它不能很好地建模局部关系或学习细粒度的局部表示。
Masked visual modeling.
掩码语言建模[11,43]一直是语言transformer的主要预训练方法之一。随着视觉transformer的成功,掩码视觉建模[2]已被引入到自监督视觉预训练中,并被证明对多模态视觉语言学习也有帮助[17,81]。在BERT[11]预训练之后,BEiT[2]和PeCo[16]通过预测由预训练的VQ-VAE编码的掩码patch的离散视觉标记来预训练ViT。MAE[32]提出了一种用于像素重建的非对称编码器-解码器框架,显著降低了掩码图像建模的计算成本。SimMIM[74]和MaskFeat[73]提出了利用分层ViT来恢复掩码patch的底层特征,如像素或HOG特征。而iBOT[82]、BootMAE[15]和sdAE[9]则采用学生模型的指数移动平均作为在线教师模型,使得目标特征在训练过程中是自举的。在视频领域,一些开创性的工作[22,61,63,69]将掩码图像建模扩展到掩码视频建模。BEVT[69]通过同时使用图像transformer和视频transformer预测离散token,提出了一种双流预训练联合预训练框架。VideoMAE[63]和ST-MAE[22]遵循MAE,以极高的掩码率重建掩码视频patch的像素。与以往大多数掩码视频建模的工作不同,我们的MVD侧重于以高级特征为目标的掩码特征建模,并发现使用图像和视频教师模型的学生模型具有不同的属性并相互补充。
Knowledge distillation.
知识蒸馏[27,34,53]旨在以教师模型的输出为目标,将教师模型的知识转移到学生模型中,对学生模型进行训练。典型的知识蒸馏工作[34,56,57]主要集中在监督学习上,如图像分类。最近,自监督知识蒸馏[20,76,77]也被用于从自监督预训练模型中学习表示。在本文中,我们首次尝试在视频域中使用预训练的图像和视频模型作为掩码特征预测目标。结果表明,自监督MIM预训练模型可以进一步提高掩码视频的预训练效果,并带来显著的性能提升。
3. Method
虽然掩码视频建模在自监督学习方面表现出了良好的性能,但大多数现有方法都以原始像素[63]、HOG[73]和VQVAE令牌[69]等低级特征的形式重建相对低级的信息。在本文中,我们不是重建底层信息,而是在特征层进行掩码视频建模。这是通过两阶段框架MVD来实现的,该框架被优化为预测来自现成的MIM预训练图像模型[32]和MVM预训练视频模型[63]的高级特征,这些模型很容易获得。下面,我们首先在3.1节中概述了掩码特征建模范式,然后在3.2节中介绍了我们提出的MVD。最后,我们将在3.3节中介绍MVD的架构设计。
3.1. The Paradigm of Masked Feature Modeling
掩码特征建模的核心是训练模型来预测掩码输入区域的特征。在本文中,由于其有效性和简单性,我们遵循MAE[32]中的解耦编码器-解码器transformer架构。将输入X(图像
X
i
m
g
∈
R
H
×
W
×
3
X_{img}∈R^{H×W ×3}
Ximg∈RH×W×3或视频
X
v
i
d
∈
R
T
×
H
×
W
×
3
X_{vid}∈R^{T ×H×W ×3}
Xvid∈RT×H×W×3)划分为多个不重叠的patch,然后将每个patch映射到具有线性投影层的视觉token。在向transformer编码器f提供token之前,token的一个子集被屏蔽并从token序列中删除。为了重建掩码token的信息,将来自编码器的可见token和可学习的掩码token组成的token序列输入到浅层transformer解码器g中:
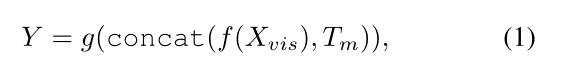
其中
X
v
i
s
X_{vis}
Xvis表示可见的输入token,
T
m
T_m
Tm表示掩码token。解码器输出token的子集对应于输入掩码token,且该子集包含掩码token的重建信息。每个掩码patch
X
(
p
)
X(p)
X(p)的重建目标表示为patch feature
h
(
X
(
p
)
)
h(X(p))
h(X(p))。其中,h表示生成目标特征的函数,例如h生成[22,63]中patch中像素的低级RGB值。然后,为了训练编码器和解码器,定义一个损失函数来测量掩码patch的ground-truth feature与重建patch的ground-truth feature之间的距离D:
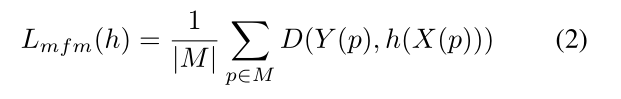
其中p是token索引,M是掩码token集合。对于MAE[32]和VideoMAE[63]中的像素回归,使用L2距离作为距离度量。
Y
(
p
)
Y(p)
Y(p)是掩码patch的ground-truth feature。
3.2. Masked Video Distillation
在本文中,我们提出了掩码视频蒸馏(MVD),它使用高级特征而不是低级像素对视频进行掩码特征建模。特别是,我们简单地使用现成的自监督预训练图像或视频模型生成的输出作为重建目标,这些模型很容易获得。这些高级特征,作为掩码和预测任务的目标,由掩码可视化建模(如MAE或VideoMAE)预训练的教师模型编码。对于视频表示学习,重建目标可以是由图像教师模型编码的空间特征,也可以是由视频教师模型编码的时空特征。更具体地说,图像教师是通过掩码图像建模进行预训练的,视频教师是通过掩码视频建模进行预训练的,这两种方法都是为了重建原始像素。训练完成后,使用图像编码器生成空间目标,使用预训练的视频transformer编码器生成时空目标。有图像教师和视频教师的MVD的损失函数可以分别用 L m f m ( h i m g ) L_{mfm}(h_{img}) Lmfm(himg)和 L m f m ( h v i d ) L_{mfm}(h_{vid}) Lmfm(hvid)表示。
Spatial-temporal Co-teaching.
当与单一教师进行MVD时,我们观察到来自不同教师的学生学习不同的视频表示,并在不同类型的下游视频任务上表现良好。为了提高MVD在不同下游视频任务上的性能,我们提出了时空协同教学,从图像和视频教师中挖掘信息,使学生模型能够更好地处理不同类型的视频。例如,快速变化的人类行为的视频需要更多的时间信息,而相对静态的视频可能需要空间线索。为此,训练MVD来预测图像教师和视频教师同时产生的目标高级特征。这是通过使用两个分离的解码器来重建不同的目标特征来实现的。时空协同教学的MVD最终损失为:
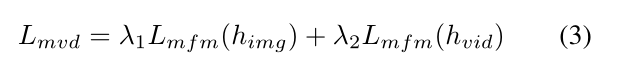
其中λ1和λ2表示平衡图像教师和视频教师权重的超参数。MVD的伪代码如算法1所示。
Algorithm 1 Pseudocode of MVD in PyTorch style.
# f: student encoder
# g_img: decoder for reconstructing spatial features
# g_vid: decoder for reconstructing spatial-temporal
features
# t_m: learnable mask tokens
# h_img: image teacher model
# h_vid: video teacher model
for x, m in loader: # x: video data, m: mask
x_pe = patch_emb(x) # patch embedding of input
x_vis = mask_select(x_pe, 1 - m) # masking tokens
q_vis = f(x_vis) # visible local patch features
# reconstruction of target features
p_img = g_img(concat(q_vis, t_m))
p_vid = g_vid(concat(q_vis, t_m))
# compute target features with teacher models
k_img = h_img(x) # target spatial features
k_vid = h_vid(x) # target spatial-temporal features
# compute reconstruction loss
loss_img = smooth_L1_loss(p_img ? m, k_img ? m)
loss_vid = smooth_L1_loss(p_vid ? m, k_vid ? m)
loss = λ1 * loss_img + λ2 * loss_vid
loss.backward()
optimizer.step() # optimizer update
3.3. Architectural Design
Encoder .
对于MVD,原始transformer骨干被用作编码器。对于视频输入
X
v
i
d
∈
R
T
×
H
×
W
×
3
X_{vid}∈R^{T ×H×W ×3}
Xvid∈RT×H×W×3,我们采用3D patch embedding,patch大小为2 ×16 ×16。经过patch划分和线性embedding,得到T /2 × H/16 × W/16个token。对于掩码特征建模任务,用高掩蔽率掩码token,剩余token被馈送到transformer层。为了对下游任务进行微调,我们将所有token输入到后续层。在每一层中,对整个输入token序列应用联合时空自注意。
Mask strategy.
对于MVD,我们遵循[63],采用管道掩码进行掩码特征建模。首先生成一个二维随机掩码,然后沿着时间维度进行扩展。因此,每个时间片上的空间掩码是相同的,这样可以防止帧之间的信息泄漏。具有高掩码率(例如,90%)的管道掩码激励视频transformer在预训练期间建模高级语义。
Decoder .
对于MVD,浅层解码器由原始transformer层和线性投影层组成。解码器中的transformer层与编码器中的transformer层相同。由于时空协同教学引入了两种不同的掩码特征建模重建目标,因此在编码器的顶部放置了两个具有相同架构但包含不同权重的分离解码器。与掩码patch对应的可学习的掩码token在输入到解码器之前与来自编码器的可见token连接起来。在对时空关系进行联合建模后,transformer层的输出token通过线性投影层映射到最终预测。
Reconstruction targets.
为了生成时空目标特征,与学生模型具有相同架构的视频教师在视频数据集上通过video - MAE[63]的方式进行预训练。对于空间目标的获取,我们采用在图像数据集(例如ImageNet-1K)上经过掩码图像建模[32]预训练的原始图像ViT。值得注意的是,视频transformer的一个3D patch(大小为2 ×16 ×16)对应图像transformer的两个2D patch(大小为16×16)。接下来[22],我们预测单个时间片(即前一个2D patch)的空间特征,从而减小了预测层的大小。
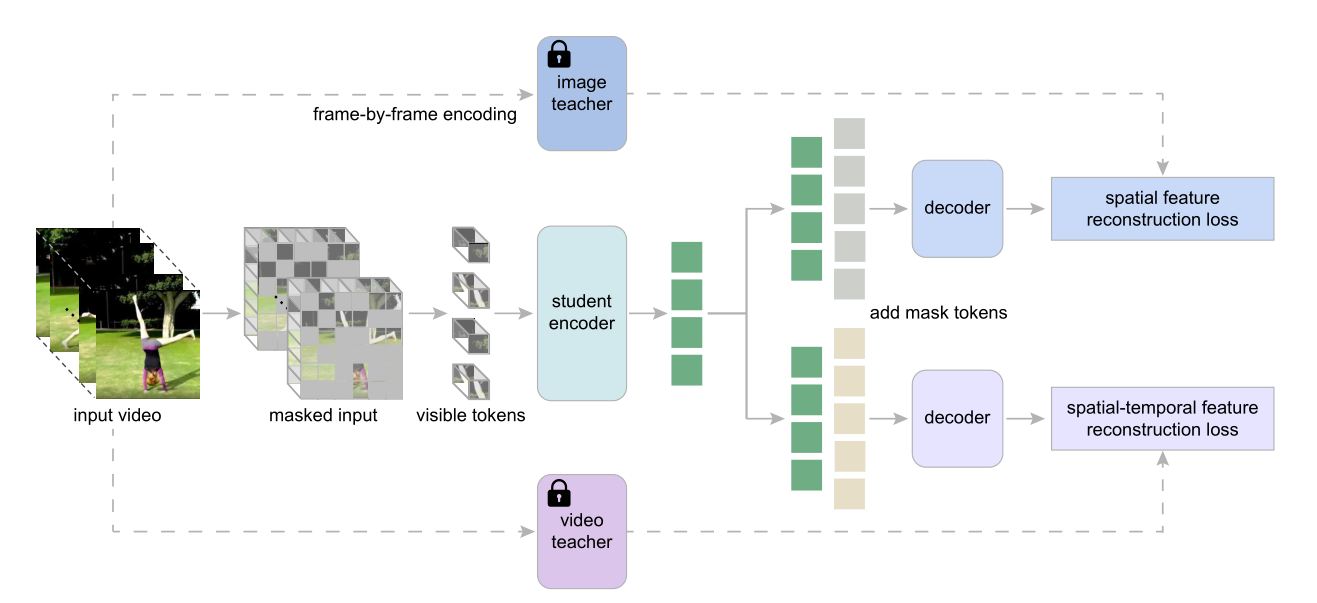
MVD框架概述。首先对图像教师进行掩码图像建模预训练,对视频教师进行掩码视频建模预训练。然后从零开始训练学生模型,预测由图像教师和视频教师编码的目标高级特征。教师模型在蒸馏阶段是固定的。
4.Experiments
在本节中,我们首先介绍4.1节中的实验设置,然后介绍4.2节中的主要结果,然后进行广泛的分析,以验证4.3节中不同组件的有效性。
4.1. Experimental Setup
Dataset.
我们在Kinetics-400上默认使用MVD预训练原始ViT,并在四个视频识别下游任务上评估学习到的模型:
(a) Kinetics400 (K400)[6],由约240K个训练视频和约20K个验证视频组成,平均持续时间为10秒。所有的视频片段被划分为400个类别。
(b) Something-Something V2 (SSv2)[28],其中包含用于训练的~ 160K视频和用于验证的~ 20K视频。SSv2中平均时长为4秒的视频被标记为174个以动作为中心的类别。
( c ) (c) (c) UCF-101[59]是一个相对较小的数据集,由~ 9.5K训练视频和~ 3.5K验证视频组成。
(d) HMDB51[38]也是一个包含约3.5K/1.5K训练/验证视频的小型视频数据集。在UCF101和HMDB51上,我们遵循常用的协议,并在所有3训练/验证分割中评估我们的方法。我们还将预训练模型转移到具有挑战性的时空动作检测数据集AVA[29]。
Implementation details.
我们的MVD是在不同容量的原始VIT上执行的(即,ViT-S, ViT-B, ViT-L)。默认情况下,图像教师模型在ImageNet-1K上预训练1600个epoch,视频教师在K400上预训练1600个epoch。我们分别采用MAE[32]和VideoMAE[22]中对图像教师和视频教师的培训策略。在蒸馏阶段,除非另有说明,否则学生模型首先在K400上从头开始预训练400个epoch。然后对生成的模型进行下游视频任务的微调。视频剪辑长度为16,用于预训练和微调。
我们采用AdamW优化器[48]和Smooth L1 loss对学生模型进行优化。我们在32个NVIDIA V100 gpu上进行了预训练实验,在16个NVIDIA V100 gpu上进行了调优实验。更多的细节包括在补充材料中。
4.2. Main Results
Students distilled from different teachers.
与掩码图像建模不同,视频数据的掩码特征建模对重建目标有更多的选择。除了空间特征外,为了在重建目标中包含时间动态,我们还可以采用预训练视频模型编码的时空特征。在表1中,我们比较了图像教师和视频教师培养的学生在主要依赖空间线索的下游任务K400和时间较重的下游任务SSv2上的表现。我们的观察结果如下:
(a)以高级特征为目标的掩码特征建模在下游视频任务上取得了令人信服的表现,并且显著优于VideoMAE基线(与表2中的基线结果相比)。特别是,当图像和视频教师都使用VIT-S作为主干时,MVD在K400(80.6%对79.0%)和SSV2(70.7%对66.4%)上都取得了优于VideoMAE的一致收益。
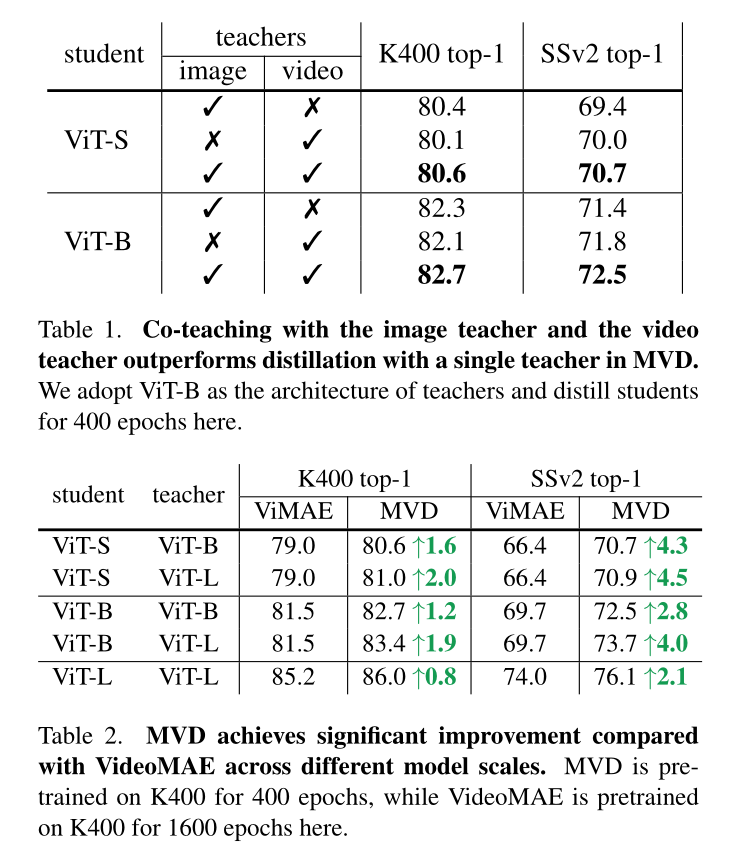
(b)图像老师培养出来的学生在K400上的top-1准确率更高,而视频老师培养出来的学生在SSv2上的top-1准确率更高。例如,在K400和SSv2上使用图像教师,VIT-S的准确率分别达到80.4%和69.4%。另一方面,如果有视频老师,ViT-S的top-1准确率分别为80.1%和70.0%。研究表明,与SSv2相比,K400中的视频对时间建模的敏感性较低,结果表明学生从图像教师那里学习到更强的空间表征,而视频教师向学生传递了更多关于时间动态的知识。
Co-teaching outperforms distilling with a single teacher .
为了提高MVD在不同下游视频任务上的性能,我们在MVD中引入了时空协同教学,以解耦的方式训练模型预测掩码patch的空间特征和时空特征。表1的结果表明,时空协同教学培养出来的学生在空间重任务和时间重任务上的表现都优于单一教师培养出来的学生。
MVD outperforms VideoMAE baseline significantly.
表2将时空协同教学的MVD与在K400上预训练的VideoMAE进行比较。当教师模型的大小与学生模型的大小相同时,MVD在K400和SSv2上的表现都明显优于VideoMAE。更大的模型作为教师可以进一步提高MVD的性能。值得一提的是,我们的MVD不仅对相对较小的模型特别有效,而且还提高了像ViT-L这样的大视觉模型的性能。例如,以VIT-L模型作为学生模型,MVD在K400和SSv2上分别达到86.0%和76.1%,分别超过VideoMAE模型0.8%和2.1%。
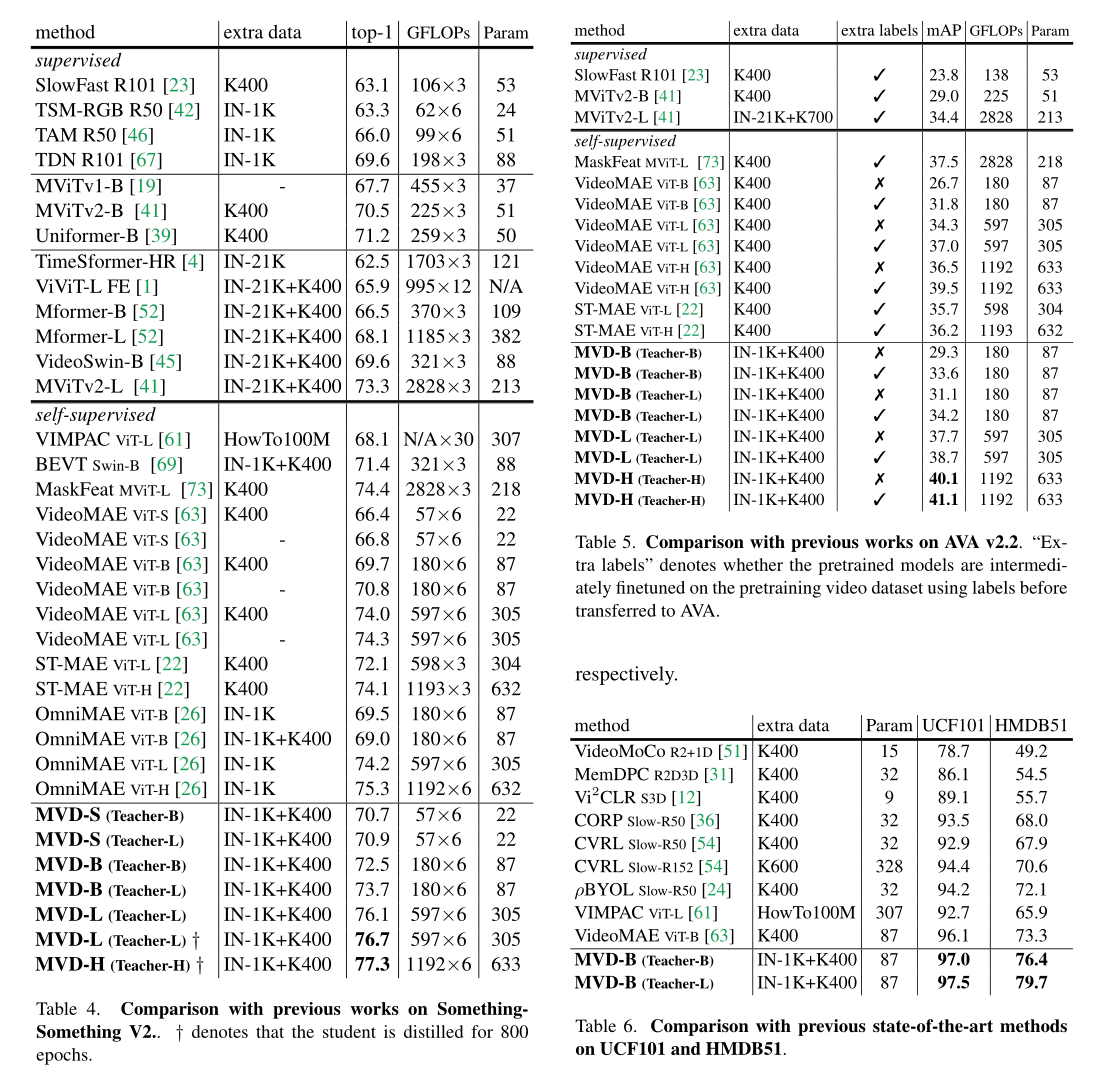
Comparison with state-of-the-art.
我们将MVD与先前在四种视频识别任务上的研究进行了比较。K400试验结果如表3所示。我们的MVD以相似或更少的计算成本优于以前的自监督方法。即使与在ImageNet-21K上预训练的视频transformer相比,MVD也取得了更优越的性能。特别是,MVD-H在K400上的准确率达到87.2%,明显优于之前表现最好的方法。表4给出了与SSv2上最先进方法的比较。

我们观察到,对于依赖于时间关系建模的下游任务,基于掩码视频建模的自监督方法比监督方法取得了更好的性能(参见。表4中间组的结果与顶部组的结果)。再一次,我们的MVD在大型模型下产生76.1%的准确率,明显优于监督方法和自监督方法。随着训练次数的增加(即800次),与VideoMAE相比,ViT-L的MVD实现了更显著的性能提升(即在K400和SSv2上分别提高1.2%和2.4%)。当使用大型模型时,性能仍然可以提高,MVD在SSv2上达到77.3%的top-1准确率。
我们还在两个相对较小的数据集(UCF101和HMDB51)上评估了MVD的迁移学习能力。
如表6所示,基于精心设计的借口任务、对比学习和掩码视频建模方法,ViT-B的MVD比之前的作品获得了更高的准确率。特别是与原来的VideoMAE [63] ViT-B教师模型相比,我们在这两个数据集上的得分分别提高了0.9%和3.1%。此外,当教师规模较大时,MVD的迁移学习绩效更强。
当转移到更复杂的动作检测任务(AVA v2.2)时,与之前的方法相比,MVD仍然有显著的改进,如表5所示。
例如,在没有K400附加标签的情况下,带VIT-L的MVD比VideoMAE高出3.4,达到37.7 mAP。
当我们在K400上对预训练模型进行中间微调时,与VideoMAE相比,使用vitl的MVD也取得了显着的性能提升(即1.7 mAP)。最后,在ViT-Huge模型下,MVD达到了41.1 mAP,比之前最先进的方法提高了1.6。
4.3. Analysis and Discussion
在本节中,我们将深入分析MVD中不同组件的有效性。
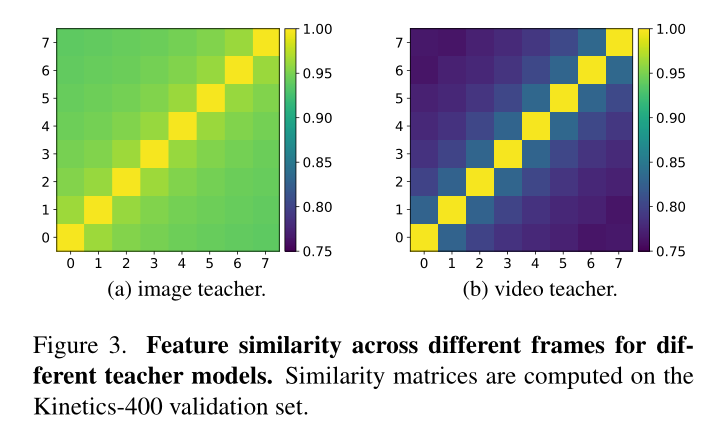
Analysis of features encoded by different teachers.
不同教师产生的目标特征的性质可能会影响学生在不同下游任务上的表现。为了量化教师模型从输入视频中捕获的时间动态,我们通过余弦相似性研究了每个输入视频剪辑的不同帧之间特征映射的相似性。如图3所示的相似矩阵,对于图像教师来说,不同帧的特征映射几乎是相同的。但对于视频教师来说,不同帧的特征差异较大。这表明视频教师捕捉到更多的时间差异。因此,从视频教师中培养出来的学生可以学习到更强的时间动态,并在时间繁重的下游任务中表现得更好。
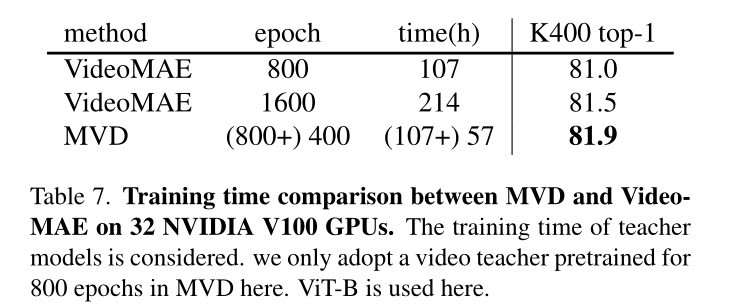
Training time comparison.
我们研究了MVD是否能够比VideoMAE更好地平衡精度和效率。为了公平比较,教师模型的训练时间也计入MVD的总训练时间。结果如表7所示。我们看到,MVD可以通过164小时的训练达到更好的准确率(即81.9%),比1600次训练的VideoMAE(产生81.5%的准确率)少50小时。
Reconstruction signals in MVD.
在MVD中,我们首先通过MAE的方式恢复掩码patch的像素对教师模型进行预训练,然后将教师模型产生的特征作为掩码特征建模的目标。在表8中,我们研究了是否在蒸馏阶段包含一个额外的解码器分支来重建掩码patch的像素。实验结果表明,无论是单教师模式还是时空协同教学模式,底层特征目标的重建都会降低下游任务的性能。因此,我们只在MVD的蒸馏阶段重建掩码patch的高级特征。

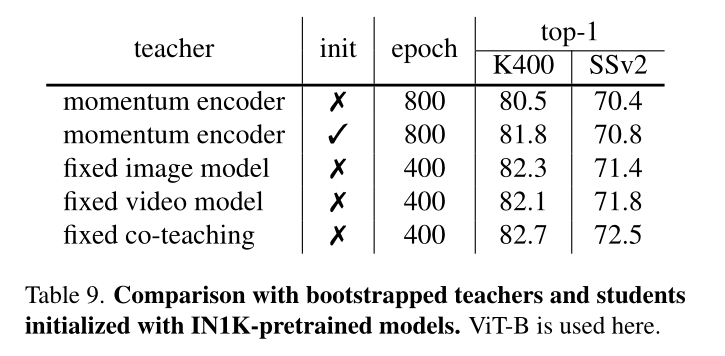
Comparison with bootstrapped teachers.
最近的一些图像表示学习方法[9,15,17,82]采用动量编码器的特征作为掩码图像建模的目标,而我们在MVD中使用冻结的教师模型。在表9中,我们比较了固定教师和自引导教师,自引导教师在预训练期间通过在线编码器的指数移动平均更新。根据一种掩码图像建模方法[15],构建了两条自举教师的强基线,用于视频表示学习:(a)用掩码特征建模从头训练学生模型,通过动量编码器生成目标特征。(b)首先在IN-1K上对自举教师框架进行800次epoch的预训练,然后利用预训练好的权值初始化视频预训练。如表9所示,在下游视频任务中,即使仅使用单个教师,使用冻结教师的MVD方法也优于使用自引导教师的方法。
Comparison with feature distillation.
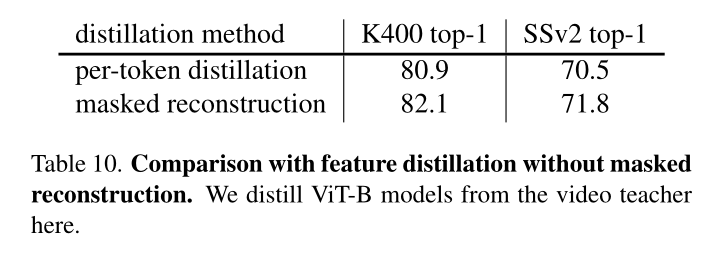
在之前的自监督特征蒸馏工作[20,27,77]中,蒸馏损失是直接根据教师和学生之间的完整特征映射计算的。因此,我们构建了一个名为每个token蒸馏的基线方法。具体来说,学生的输出特征是由一个MLP来预测的,然后在每个标记处以平滑L1损失来模仿老师的特征。如表10所示,我们的MVD中的掩码特征重建在K400和SSv2上都优于每个token蒸馏。
5. Conclusion
本文研究了基于MIM预训练图像或视频转换器的掩膜视频蒸馏。我们有三个有趣的发现:
1)使用MIM预训练图像transformer或MVM预训练视频transformer作为教师监督掩码特征预测可以显著提高视频下游任务的微调性能;
2)图像和视频教师蒸馏出来的表示具有不同的属性,即图像教师更有利于重空间的视频任务,而视频教师更有利于重时间的视频任务;
3)将图像与视频相结合,教师可以享受到协同效应,从而产生更高的绩效。尽管所提出的掩码视频蒸馏看起来非常简单,但我们希望这些有趣的发现能够激发人们对呀那么视频预训练的更多思考。
Visualization
在本文中,为了量化模型从输入视频中捕获的时间动态,我们通过余弦相似度研究了每个输入视频片段不同帧之间特征映射的相似性。网格中的数字是两个帧特征之间的余弦相似度的值。
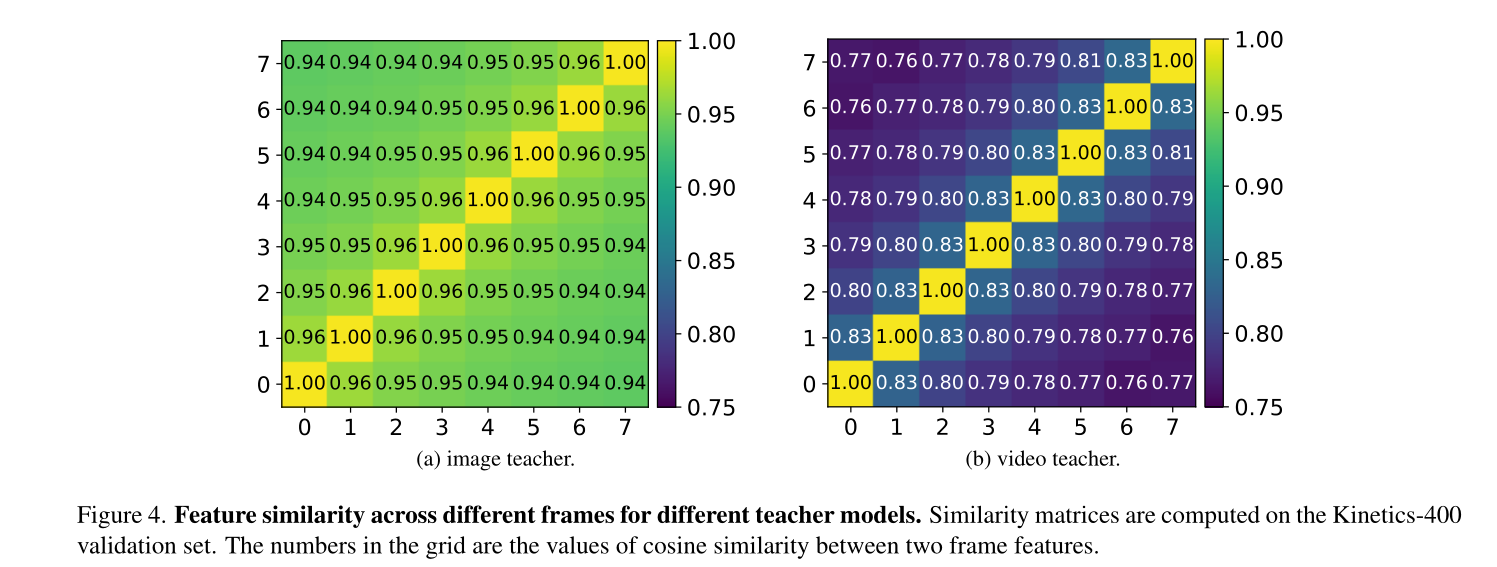
**不同教师编码特征分析。**不同教师产生的目标特征的性质可能会影响学生在不同下游任务上的表现。如图4所示的相似矩阵,对于图像教师来说,不同帧的特征映射几乎是相同的。但对于视频教师来说,不同帧的特征差异较大。这表明视频教师捕捉到更多的时间差异。因此,从视频教师中培养出来的学生可以学习到更强的时间动态,并在时间繁重的下游任务中表现得更好。
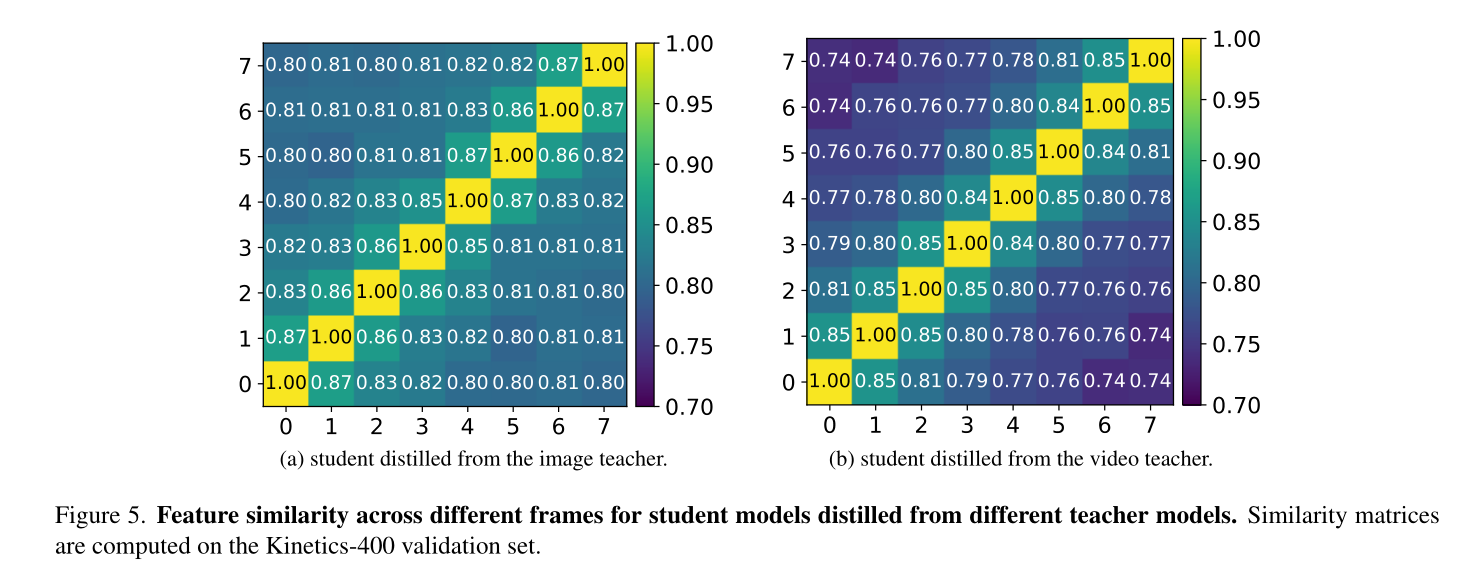
从不同教师身上提炼出的学生编码特征分析。为了研究学生从不同的老师那里学到了什么,我们可视化了学生模型在不同框架中的特征相似性。如图5所示,我们观察到(a)对于从图像教师中蒸馏的学生,不同帧的特征与图像教师编码的特征相比差异更大。这表明学生可以从视频中空间特征的掩码重建中学习时间动态。(b)对于从视频教师中提取的学生,不同帧的特征与从图像教师中蒸馏的学生编码的特征相比有较大的差异。这表明学生从视频教师那里学到了更强的时间动态。

















 2645
2645

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









