






YOLO-V3 笔记
0. Reference
yolo实践参考资料
yolo(darknet)官网:https://pjreddie.com/darknet/yolo/
github 源码:https://github.com/pjreddie/darknet
YOLO源码解析(tensorflow):https://zhuanlan.zhihu.com/p/250533
yolo理论参考资料
YOLO 原文链接:https://arxiv.org/pdf/1506.02640.pdf
基于深度学习的目标检测(附有参考文献): https://www.cnblogs.com/gujianhan/p/6035514.html
YOLO - 实时快速目标检测: https://zhuanlan.zhihu.com/p/25045711?refer=shanren7 https://blog.csdn.net/surgewong/article/details/51864859
darknet 源码解析
github 地址:https://github.com/hgpvision/darknet
github 地址(推荐):https://github.com/AlexeyAB/darknet
keras 版本的yolo-v2
GitHub 地址:https://github.com/allanzelener/YAD2K
主要从三个方面来说明,网络的输入、结构、输出。
1. 网络输入
原论文中提到的输入大小320*320,416*416,608*608。这个大小必须是32的整数倍数,yolo_v3有5次下采样,每次采样步长为2,所以网络的最大步幅(步幅指层的输入大小除以输出)为2^5=32。
2. 网络结构
作者首先训练了一个darknet-53,训练这个主要是为了主要有两个目的:
-
这个网路结构能在ImageNet有好的分类结果,从而说明这个网路能学习到好的特征(设计新的网络结构,这个相当于调参,具体参数怎么调,就是炼丹了),
-
为后续检测模型做初始化。
作者在ImageNet上实验发现这个darknet-53,的确很强,相对于ResNet-152和ResNet-101,darknet-53不仅在分类精度上差不多,计算速度还比ResNet-152和ResNet-101强多了,网络层数也比他们少。
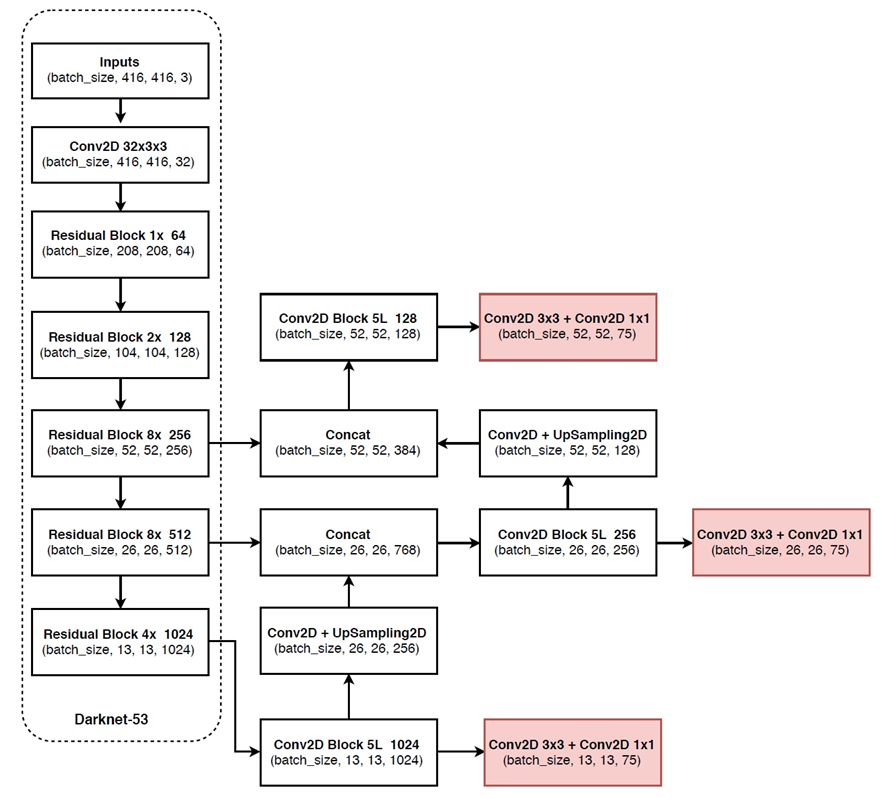
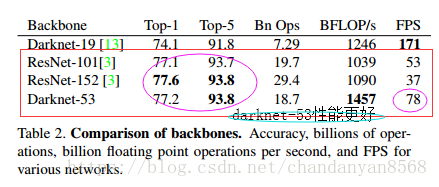
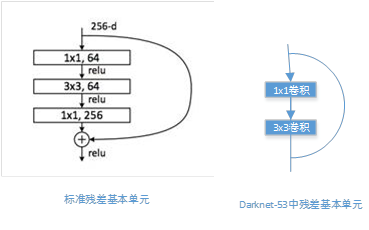
Darknet-53采用了ResNet这种跳层连接方式,性能完全比ResNet-152和ResNet-101这两种深层网络好,这里作者并没有给出原因,可能的原因:
-
网络的基本单元的差异;
-
网络层数越少,参数少。需要的计算量少;
Yolo_v3网路就是使用了darknet-53的前面的52层(没有全连接层),直接拿过来,yolo_v3这个网络是一个全卷积网络,大量使用残差的跳层连接。之前的工作中,采样一般都是使用size为2*2,步长(stride)为2的max-pooling或者average-pooling进行降采样。但在这个网络结构中,使用的是步长为2的卷积来进行降采样。同时,网络中使用了上采样、route操作,还在一个网络结构中进行3次检测(有点盗用SSD的思想).
使用残差的结构的好处
-
深度模型一个关键的点就是能否正常收敛,残差这种结构能保证网络结构在很深的情况下,仍能收敛,模型能训练下去。
-
网络越深,表达的特征越好,分类+检测的效果都会提升。
-
残差中的1*1卷积,使用network in network的想法,大量的减少了每次卷积的channel,一方面减少了参数量(参数量越大,保存的模型越大),另一方面在一定程度上减少了计算量
网路中作者进行了三次检测,分别是在32倍降采样,16倍降采样,8倍降采样时进行检测,这样在多尺度的feature map上检测跟SSD有点像。在网络中使用up-sample(上采样)的原因:网络越深的特征表达效果越好,比如在进行16倍降采样检测,如果直接使用第四次下采样的特征来检测,这样就使用了浅层特征,这样效果一般并不好。如果想使用32倍降采样后的特征,但深层特征的大小太小,因此yolo_v3使用了步长为2的up-sample(上采样),把32倍降采样得到的feature map的大小提升一倍,也就成了16倍降采样。同理8倍采样也是对16倍降采样的特征进行步长为2的上采样,这样就可以使用深层特征进行detection。
Yolo_v3通过上采样的方式很好的使16倍降采样和8倍降采样使用深层特征,但进行4次下采样和3次下采样得到的浅层feature map大小是一样的。Yolo_v3想把这些浅层特征也利用起来,就有了route层。把16倍降采样得到的feature map和四次下采样得到的层拼接在一起,在channel那个维度进行拼接。这样拼接的好处:让网络同时学习深层和浅层特征,表达效果更好。8倍降采样同样也是这样的操作,把三次下采样的feature map拼接在一起。



- res 残差层
- route 路由层——多个层拼接才一起
- upsample 上采样
箭头没画好,箭头从up-sample指向detection,代表把feature map的大小上升一倍)
3. 网络输出
3.1 首先先确定网络输出特征层的大小。
比如输入为320*320时,则输出为320/32=10,因此输出为10*10大小的特征层(feature map),此时有10*10=100个cell;同理当输入为416*416时输出的特征层为13*13大小的特征层,13*13=169个cell;输入为608*608时,输出的feature map大小为19*19,cell有19*19=361个。进行每进行一次up-sample时,输出特征层扩大一倍。
3.2 Anchor box的确定
这个先验框不同于之前Faster-Rcnn和SSD那样人工设定,在yolo_v2和yolo_v3中,都采用了对图像中的object采用k-means聚类。在yolo_v3中作者是这样描述的:We still use k-means clustering to determine our bounding box priors. We just sort of chose 9 clusters and 3 scales arbitrarily and then divide up the clusters evenly across scales. On the COCO dataset the 9 clusters were:(10,13); (16,30); (33,23); (30,61); (62,45); (59,119); (116 ,90); (156 ,198); (373 ,326). 这个地方,作者有一个地方没有说清楚,这个框的大小是在什么输入大小的图像下确定的,比如你在608*608作为输入图像中object的大小和在320*320大小图像中的object大小肯定不同,对这两种输入聚类的结果肯定不同。但查看作者提供的yolo_v3网络配置文件,这个聚类结果应该是在416*416大小的图像下聚类得到的结果。

3.3 bounding box
feature map中的每一个cell都会预测3个边界框(bounding box) ,每个bounding box都会预测三个东西:
-
每个框的位置(4个值,中心坐标tx和ty,,框的高度bh和宽度bw);
-
一个objectness prediction;
-
N个类别,coco数据集80类,voc20类。因此对于coco数据集,在网络输入为416*416时,网络的输出大小为13*13(3*(4+1+80))=43095

对于上图的几点说明:
-
中心坐标(tx和ty)
Yolo_v3使用 sigmoid 函数进行中心坐标预测。这使得输出值在 0 和 1 之间。正常情况下,YOLO 不会预测边界框中心的确切坐标。
它预测的是:与预测目标的网格单元左上角相关的偏移;并且使用feature map中的cell大小进行归一化。
当输入图像为416*416,如果中心的预测是 (0.4, 0.7),则第二个cell在 13 x 13 特征图上的相对坐标是 (1.4, 1.7),具体的位置x坐标还需要1.4乘以cell的宽,y坐标为1.7乘以cell的高。
-
Bounding box的宽度bw和高度bh
Yolo_v3得出的预测 bw 和bh 使用图像的高和宽进行归一化,框的预测 bx 和 by 是 (0.3, 0.8),那么 13 x 13 特征图的实际宽和高是 (13 x 0.3, 13 x 0.8)。
3.4 三次检测,每次对应的感受野不同
32倍降采样的感受野最大,适合检测大的目标,所以在输入为416*416时,每个cell的三个anchor box为(116 ,90); (156 ,198); (373 ,326)。
16倍适合一般大小的物体,anchor box为(30,61); (62,45); (59,119)。
8倍的感受野最小,适合检测小目标,因此 anchor box 为(10,13); (16,30); (33,23)。
所以当输入为416*416时,实际总共有(52*52+26*26+13*13)*3=10647个proposal box。
















 824
824

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









