







前言:
学习ComfyUI是一场持久战。当你掌握了ComfyUI的安装和运行之后,会发现大量五花八门的节点。面对各种各样的工作流和复杂的节点种类,可能会让人感到不知所措。在这篇文章中,我们将用通俗易懂的语言对ComfyUI的核心节点进行系统梳理,并详细解释每个参数。希望大家在学习过程中培养自我思考的能力,真正掌握和理解各个节点的用法与功能。在实践中不断提升自己的技术水平。只有通过不断的探索和总结,才能在面对复杂的工作流时游刃有余。祝大家学习顺利,早日成为ComfyUI的高手!
目录:
一、Load Checkpoint节点
二、Load Checkpoint with config节点
三、CLIP Set Last Layer节点
四、CLIP Text Encode (Prompt)节点
五、KSampler节点
六、Empty Latent image节点
七、VAE Decode节点
八、Save image节点
九、文生图示例工作流
一、Load Checkpoint节点
在ComfyUI中,Load Checkpoint节点是一个非常重要的核心节点。其功能是加载checkpoint大模型,常用的大模型有sd1.0、sd1.5、sd2.0、sd3.0、sdXL等。
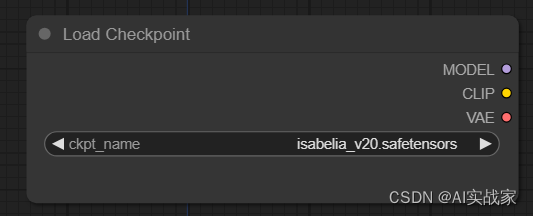
输入
ckpt_name -> 自行选择在模型网站下载好的大模型(在用WebUI时下载了大模型的可以共享路径文件,节省磁盘空间)
输出
MODEL -> 该模型用于对潜空间图片进行去噪
CLIP -> 该模型用于对Prompt进行编码
VAE -> 该模型用于对潜在空间的图像进行编码和解码
注意:·StableDIffusion大模型(checkpoint)内置有CLIP和VAE模型
·另加载大型模型时,可能会耗费较长时间或占用大量内存,确保系统资源充足,避免因资源不足而导致的加载失败。
二、Load Checkpoint with config节点
该节点是一个高级的节点,用于加载checkpoint大模型并同时应用config文件中指定的设置。
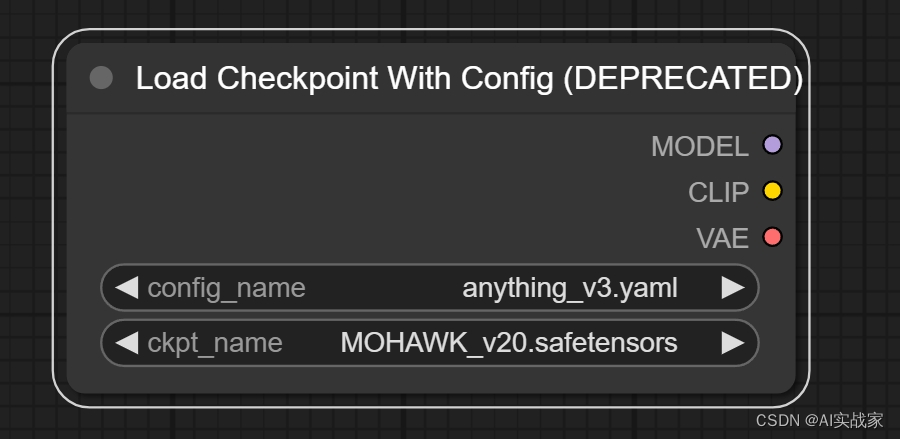
输入:
Config_name -> 指定要加载的检查点文件的路径
Ckpt_name -> 自行选择在模型网站下载好的大模型
输出:
MODEL -> 该模型用于对潜空间图片进行去噪
CLIP -> 该模型用于对Prompt进行编码
VAE -> 该模型用于对潜在空间的图像进行编码和解码
注意:确保checkpoint文件和config文件与当前使用的ComfyUI版本兼容
三、CLIP Set Last Layer节点
对CLIP进行微调并调整最后一层(Set Last Layer)。该节点用来设置选择CLIP模型在第几层的输出数据,提高模型在目标任务上的表现。
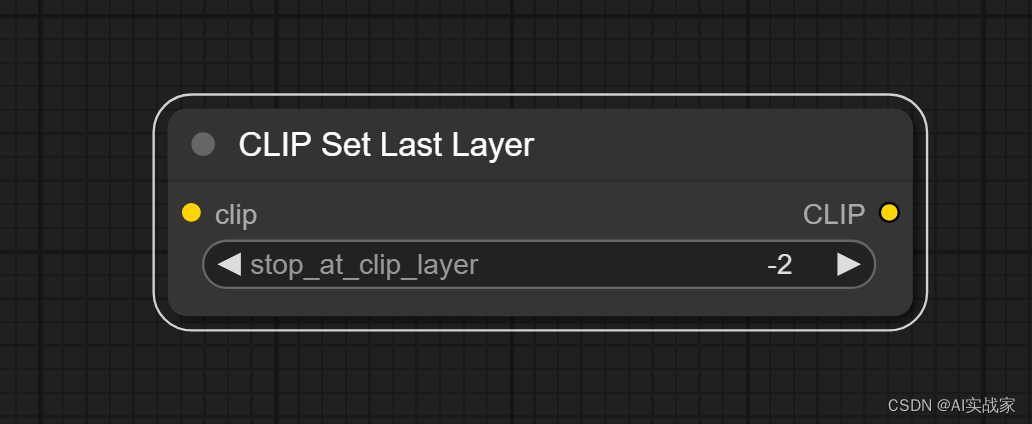
输入:
clip -> 接收用于对prompt进行编码的CLIP模型
输出:
CLIP -> 具有新设置的输出层的CLIP模型。
参数:
stop_at_clip_layer -> 设置CLIP模型在第几层进行数据输出
注意:CLIP模型对prompt进行编码的过程中,可以理解为对原始文本进行层层编码,该参数就是选择我们需要的一层编码信息,去引导模型扩散。
四、CLIP Text Encode (Prompt)节点
该节点用来输入正反向提示词,也就是“文生图”,“文生视频”中“文”的输入位置
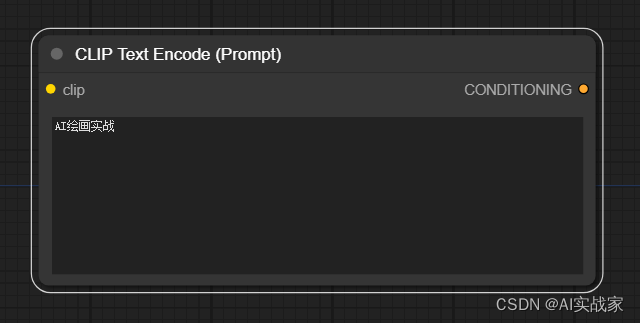
输入:
clip -> 接收用于对prompt进行编码的CLIP模型
输出:
CONDITIONING -> 将文本信息通过CLIP模型编码,形成引导模型扩散的条件信息
参数:
文本输入框 -> 输入需要模型生成的文本信息,正向提示词及反向提示词
注意:当前prompt仅支持英文的输入,但可通过安装插件实现中文实时翻译
五、KSampler节点
该节点专门用于逐步减少潜在空间图像中的噪声,改善图像质量和清晰度。
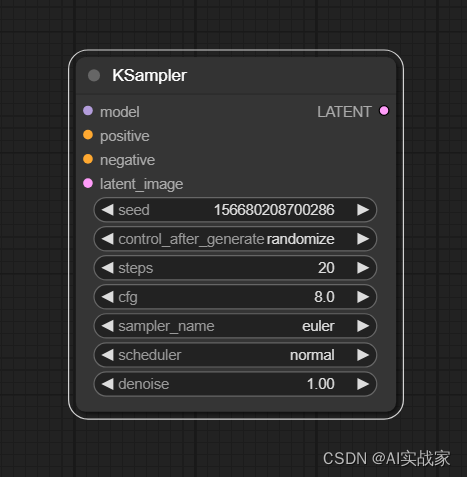
输入:
model -> 接收来自大模型的数据流
positive -> 接收经过clip编码后的正向提示词的条件信息(CONDITIONING)
negative -> 接收经过clip编码后的反向提示词的条件信息(CONDITIONING)
latent_image -> 接收潜空间图像信息
输出:
LATENT -> 经过KSampler采样器进行去噪后的潜空间图像
参数:
seed -> 在去除图像噪声过程中使用的随机数种子。种子数有限,影响噪声生成的结果
control_after_generate -> 指定种子生成后的控制方式
fixed代表固定种子,保持不变
increment代表每次增加1
decrement代表每次减少1
randomize代表随机选择种子
steps -> 对潜在空间图像进行去噪的步数。步数越多,去除噪声的效果可能越显著
cfg -> 提示词引导系数,表示提示词对最终结果的影响程度。过高的值可能会产生不良影响。
sampler_name -> 选择的采样器名称,不同的采样器类型可以影响生成图像的效果,大家可以根据需求进行选择和实验
scheduler -> 选择的调度器名称,影响生成过程中的采样和控制策略,推荐配置可提供更好的结果
denoise -> 去噪或重绘的幅度,数值越大,图像变化和影响越显著。在高清修复等任务中,通常使用较小的值以保持图像细节和质量
六、Empty Latent image节点
该节点用来控制纯噪声的潜空间图像及比例。
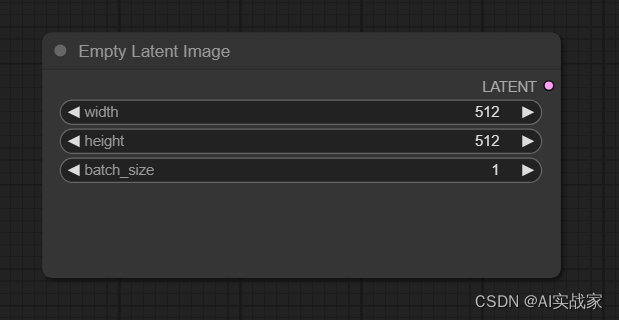
输出:
LATENT -> 输出指定形状和数量的潜空间图像
参数:
width -> 要生成潜空间图像的宽度
height -> 要生成潜空间图像的高度
batch_size -> 需要生成多少张潜空间图像
注意:sd1.0、sd1.5等模型来说最佳尺寸为512*512
sd2.0、sd3.0等模型来说最佳尺寸为1024*1024
七、VAE Decode节点
该节点用来将潜空间图像解码到像素级的图像。
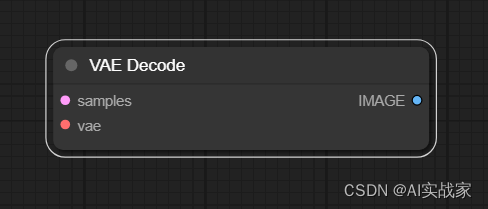
输入:
samples -> 接收经过 KSampler 采样器处理后的潜在空间图像, 用于后续的处理或展示
vae -> 接收用于解码潜在空间图像的 VAE 模型, 大部分情况下,模型的检查点(checkpoint)会包含 VAE,当然也可以单独加载一个VAE模型
输出:
IMAGE -> 输出经过 VAE 解码后可直接查看的图像
八、Save image节点
该节点用来保存image图像
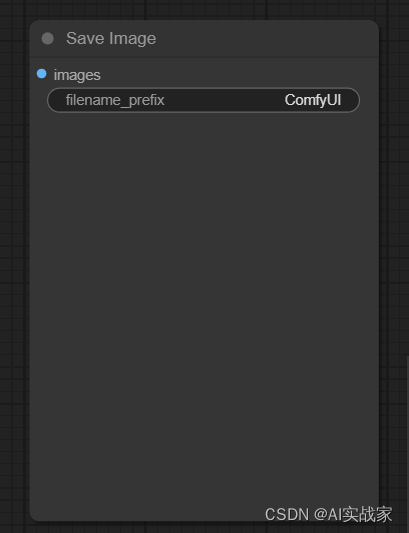
输入:
images -> 保存图像
Tips:一般保存的图像会在你的ComfyUI文件夹中(eg:安装盘:\Comfyui\ComfyUI\output )
九、文生图示例工作流
熟悉以上所有节点之后,你就可以搭建第一个“文生图”工作流了
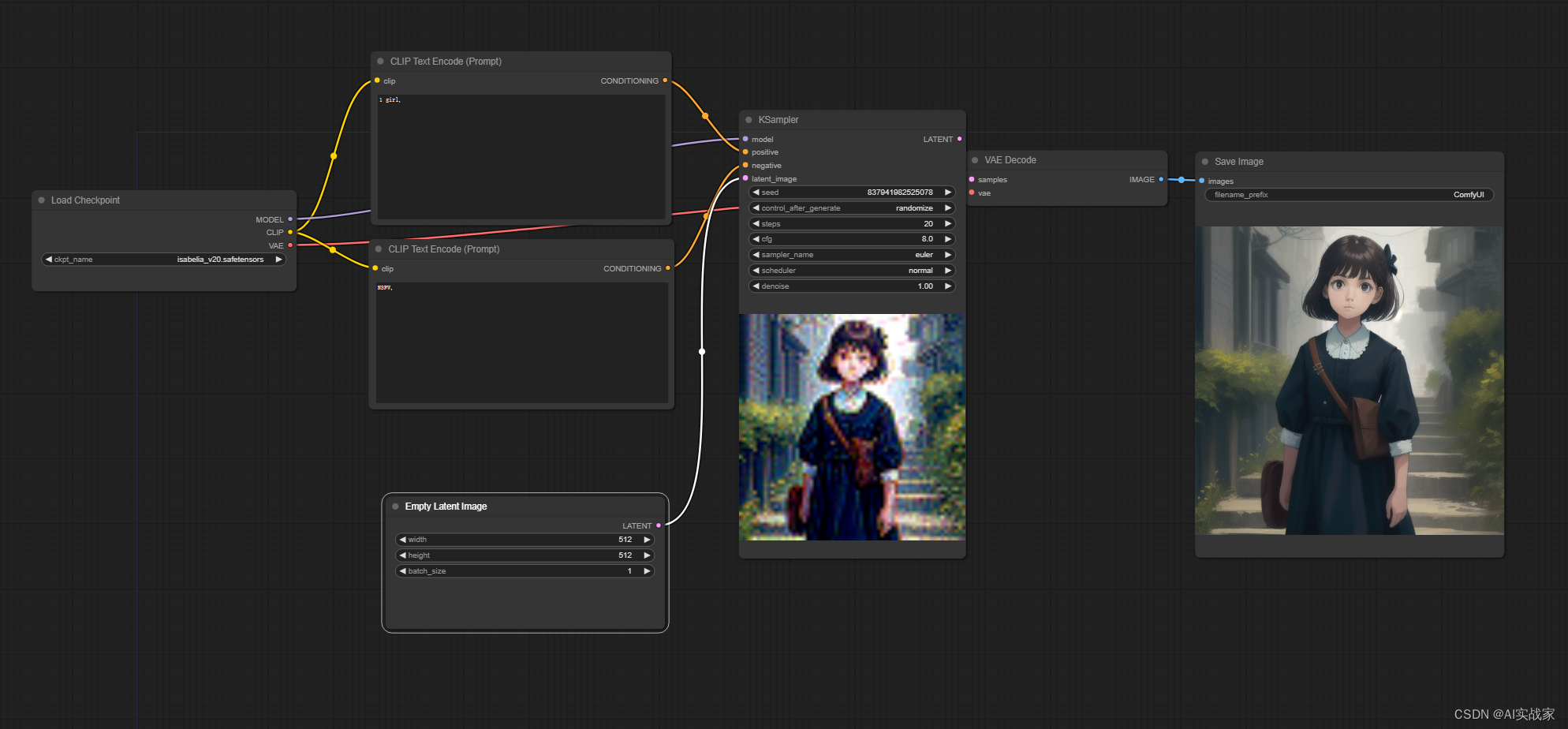
这里使用了sd1.5的大模型,所以latent图像设置512*512,正向提示词输入1 girl,反向提示词输入NSFW避免出现不能播的内容,采样器KSampler使用默认设置,最终出图如下:

孜孜以求,方能超越自我。坚持不懈,乃是成功关键。















 2782
2782











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









