







从推理到编程,详细比较DeepSeek 32B、70B、R1实践性能。
微信搜索关注《AI科技论谈》

引言
前段时间,AI 圈被国产黑马 DeepSeek - R1 模型 “霸屏” 了!这匹开源领域的 “潜力新星”,在推理能力上和 OpenAI 的 o1 不相上下,甚至在资源利用上更胜一筹,很 “省资源”。它的横空出世,不仅打破了大众对国产 AI 的固有认知,更是让世界看到了中国 AI 厚积薄发的硬核实力,这波操作简直 “杀疯了” !
DeepSeek 乘胜追击,基于 R1 模型又推出了更具针对性应用的 DeepSeek - R1 - Distill - Qwen - 32B 和 适合大规模数据处理的 DeepSeek - R1 - Distill - Llama - 70B 两款模型,热度直接拉满。
如果你想亲自体验,访问 Ollama 官网(https://ollama.com/library/deepseek-r1)就能下载。安装超简单,用 Pip 安装 Ollama 后,在终端输入 “ollama run deepseek - r1:32b” 就行。要是还想深挖更多信息,去 DeepSeek 官网(deepseek.com),那里全是干货!
话不多说,直接进入测评环节,看看这几款模型在实测中的表现到底有多 “牛”!
1 硬件配置大揭秘
来看看深度求索两款模型(320 亿和 700 亿参数版)的实测硬件配置。测试用 WSL2 系统,搭配英特尔 i7 - 14700KF 3.4GHz 处理器、32GB 内存和英伟达 RTX 4090 显卡。
运行时,320 亿参数模型能直接流畅跑,700 亿参数模型需把内存设为 24GB,可用 psutil 工具监测内存。
测试的问题,部分借鉴了Matthew Berman大佬的测试视频内容,也补充了一些自定义问题。这里 R1 模型测试结果来自其油管视频,不是本地测的。不过要注意,因测试系统不同,不宜将其测试速度与本次测试所需时间进行对比。下面看具体测试结果!
2 模型测评 “大对决”
下面是 320 亿参数模型、700 亿参数模型以及 DeepSeek - R1 模型的测评 “答卷”,直接上 “成绩”:
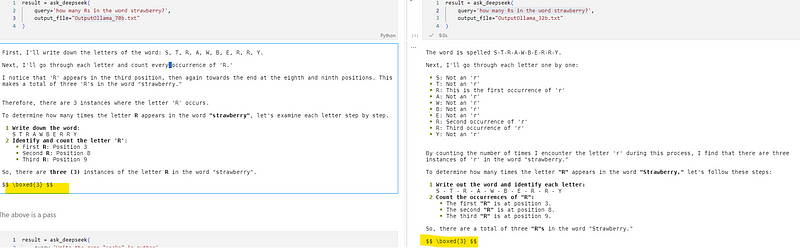
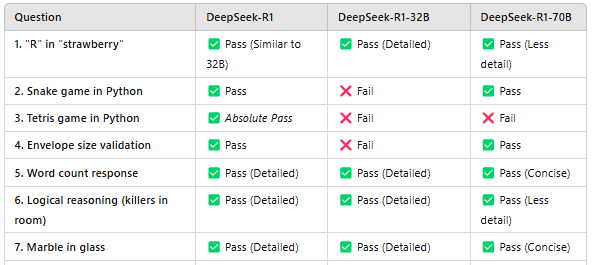
1). 单词找茬:“strawberry” 里有几个 “R”?
-
320亿参数模型:✅ 回答正确,与R1模型回答类似。
-
700亿参数模型:✅ 回答正确,但解释简略。
-
DeepSeek - R1模型:✅ 回答正确,且有详细推理过程。
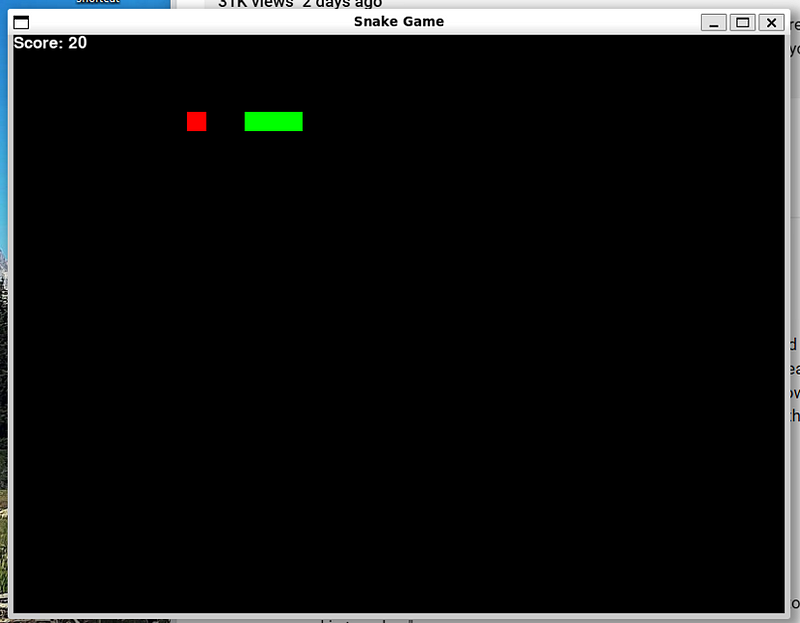
2). 代码实战:用Python写“贪吃蛇”游戏
-
320亿参数模型:❌翻车了,蛇吃不到水果,游戏功能失败。
-
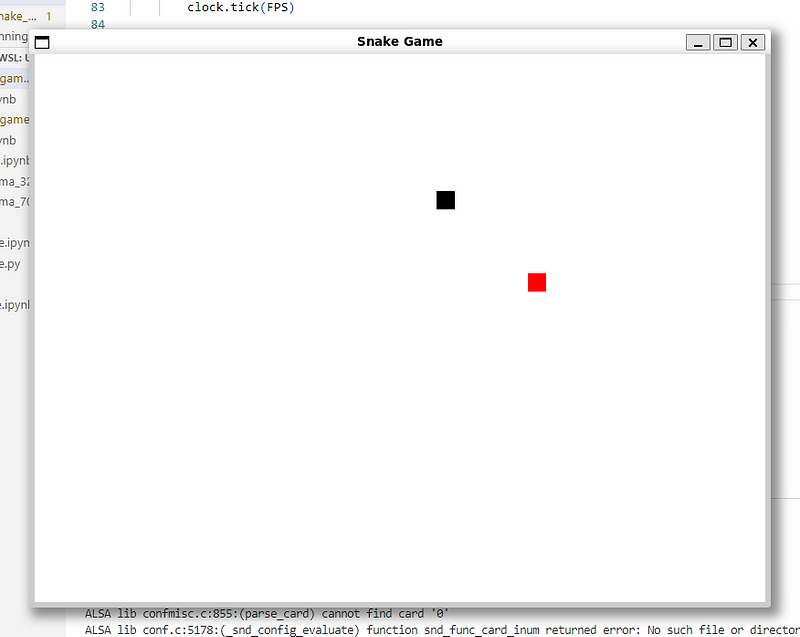
700亿参数模型:✅完美通过,蛇能吃水果、变长,分数正常更新。
-
DeepSeek - R1模型:✅和700亿参数模型表现相似,通过测试。
3). 代码实战:用Python写“俄罗斯方块”游戏
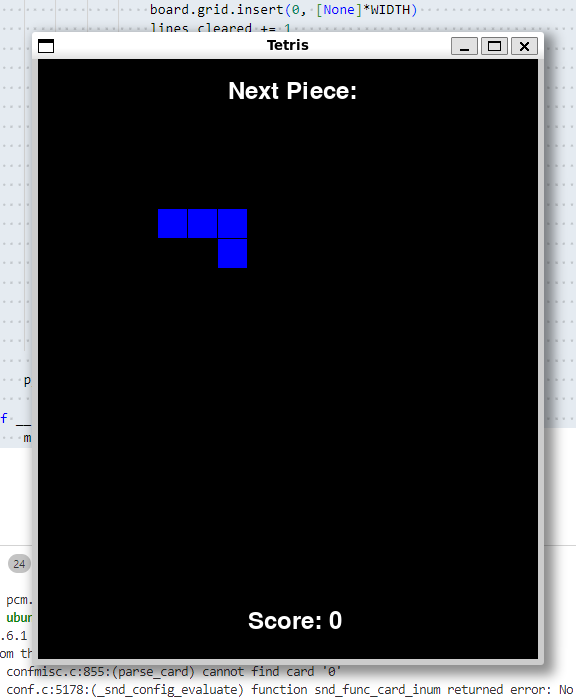
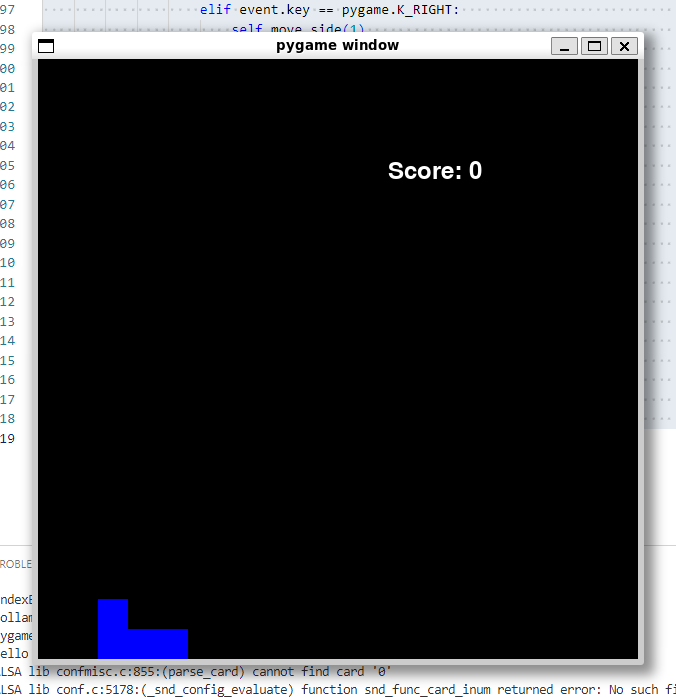
-
320亿参数模型:❌方块不动,游戏无法正常运行。
-
700亿参数模型:❌方块能下落,但无法正常放置。
-
DeepSeek - R1模型:✅完美通过,代码可正常运行游戏。
4). 尺寸计算:信封尺寸合规吗?
邮局规定信封最小14厘米×9厘米 ,最大32.4厘米×22.9厘米,现有个200毫米×275毫米的信封,它符合标准吗?
-
320亿参数模型:❌答错,回答“否”。
-
700亿参数模型:✅答对,正确换算单位并给出推理。
-
DeepSeek - R1模型:✅答对,同样换算正确且推理合理。
5). 文字计数:回答里有多少单词?
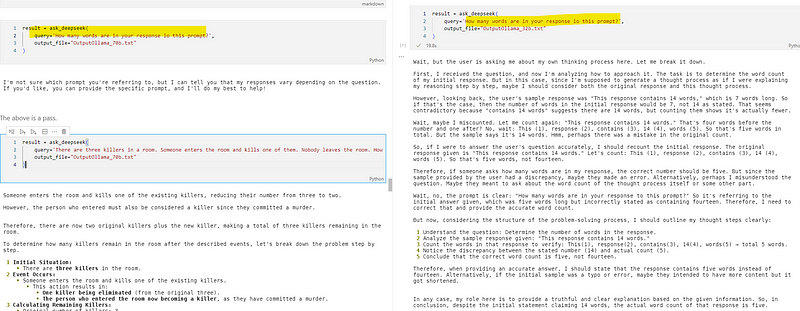
-
320亿参数模型:✅通过,推理和R1模型类似。
-
700亿参数模型:✅答对,回答简洁。
-
DeepSeek - R1模型:✅通过,推理过程细致。
6). 逻辑推理:房间里还剩几个杀手?
房间有三个杀手,有人进去杀了一个且没人离开,还剩几个杀手?
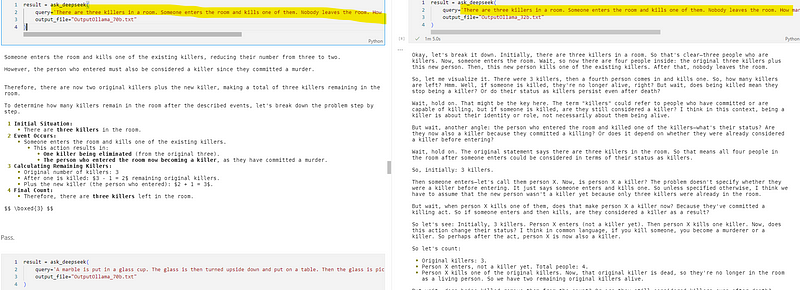
-
320亿参数模型:✅答对,推理与R1模型相似。
-
700亿参数模型:✅答对,但推理没那么详细。
-
DeepSeek - R1模型:✅答对,推理超详细。
7). 空间推理:弹珠在哪里?
把弹珠放玻璃杯,杯子倒过来放桌上,再拿起放微波炉,弹珠在哪?
-
320亿参数模型:✅通过,推理和R1模型差不多。
-
700亿参数模型:✅通过,推理合理。
-
DeepSeek - R1模型:✅通过,推理全面。
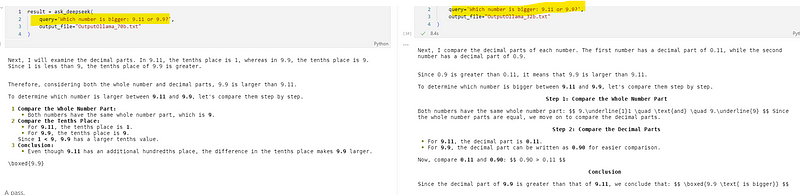
8). 数字比较:9.11和9.9谁大?
-
320亿参数模型:✅通过,推理详细。
-
700亿参数模型:✅答对,回答简洁。
-
DeepSeek - R1模型:✅通过,推理细致。
9). 模型揭秘:说出模型名的第二和第三个字母
-
320亿参数模型:✅通过,还透露基于GPT - 4。
-
700亿参数模型:✅通过。
-
DeepSeek - R1模型:没被问到这个问题。
3 最终 “胜负” 揭晓
经过这么多轮测试,结果已经很明显啦:
-
DeepSeek - R1(原版):在 “俄罗斯方块”“贪吃蛇” 编码和推理任务中表现超棒,实力碾压。
-
320亿参数模型:推理和原版 R1 一样详细,可能是因为基于通义千问。但功能性编码任务欠佳,如“信封尺寸验证”答错。不过在本地设备上运行速度很快。
-
700亿参数模型:编码和答案准确性强于320亿参数模型,答对题数与R1相近,仅“俄罗斯方块”答错。可速度太慢,RTX 4090设备上每题要等几分钟,“俄罗斯方块”题等了 2143 秒还答错。
追求速度的话(速度数据在70B和32B文件),320亿参数模型是个好选择。综合表现,R1 模型最强。700亿参数模型答对多,但速度拖后腿。
大家可以根据自己的需求,选择最适合自己的模型!
推荐书单
《大模型应用开发 动手做AI Agent》
人工智能时代一种全新的技术——Agent正在崛起。这是一种能够理解自然语言并生成对应回复以及执行具体行动的人工智能体。它不仅是内容生成工具,而且是连接复杂任务的关键纽带。本书将探索Agent的奥秘,内容包括从技术框架到开发工具,从实操项目到前沿进展,通过带着读者动手做7个功能强大的Agent,全方位解析Agent的设计与实现。本书最后展望了Agent的发展前景和未来趋势。
本书适合对Agent技术感兴趣或致力于该领域的研究人员、开发人员、产品经理、企业负责人,以及高等院校相关专业师生等阅读。读者将跟随咖哥和小雪的脚步,踏上饶有趣味的Agent开发之旅,零距离接触GPT-4模型、OpenAI Assistants API、LangChain、LlamaIndex和MetaGPT等尖端技术,见证Agent在办公自动化、智能调度、知识整合以及检索增强生成(RAG)等领域的非凡表现,携手开启人工智能时代的无限可能,在人机协作的星空中共同探寻那颗最闪亮的Agent之星!
购买链接:https://item.jd.com/14600442.html

精彩回顾
DeepSeek R1与Qwen大模型,构建Agentic RAG全攻略

















 907
907

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









