










IJCAI-20
0. Abstract
对于单通道语音增强,基于时域的方法和基于时频域的方法各有优劣,本文提出了一种跨域框架,TFT-Net,该模型以时频谱作为输入,以时域波形信号作为输出。该方法利用了我们所掌握的关于频谱的知识,避免了T-F域方法存在的缺点。在TFT-Net中,我们设计了一个双路注意力块(DAB),以充分利用沿时间和频率轴的相关性。本文进一步发现,独立于样本的DAB(SDAB)在提高与语音质量和复杂性之间实现了良好的权衡。消融实验的结果表明,跨域设计和SDAB块对模型性能的提升帮助很大。
1. Introduction
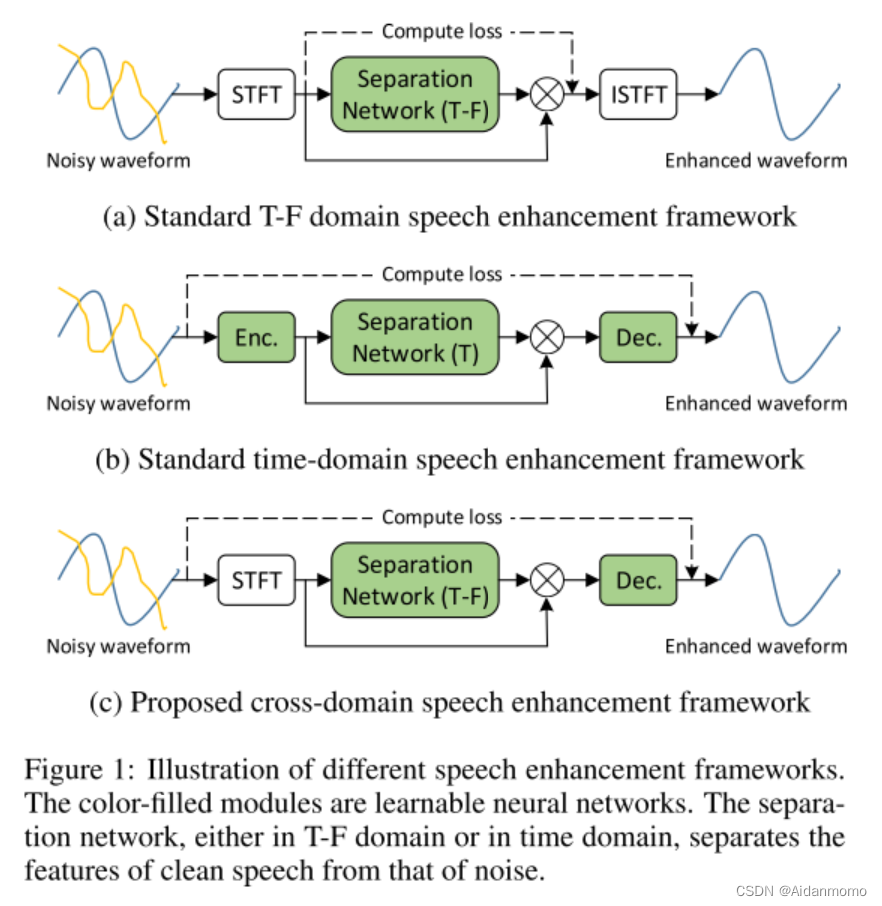
典型的时频域方法如图1(a)所示,网络的输入特征是经过STFT变换后的二维时频谱,网络模型经过训练,预测一个时频掩码,最后通过iSTFT将时频谱变换回时域信号。T-F分析的理论基础是听觉模式,如频率和时间上的接近度,谐波性,以及常见的幅度和频率调制,这些都会在T-F谱图上显示出来。此类方法的局限性:(1)相位的估计问题(2)度量不匹配问题:在有监督的深度学习方法中,计算T-F谱图的MSE损失可能不会令输出语音的SDR最大化。
时域方法的提出是为了解决上述两个问题,典型的模型框架如图1(b)所示。此类方法存在的问题是:时域方法的分离网络部分无法利用到T-F谱图上已知的听觉模式。
本文提出的跨域模型框架如图1(c)所示,在TFT-Net中,时域信号首先经过STFT变换,转换为时频谱,然后利用时频域分离网络学习谱图中的听觉模式,获得谱图掩码后,通过可学习解码器恢复谱图。设计网络模型的过程中,我们发现T-F频谱的长期依赖关系对于提升降噪性能至关重要,为了解决高复杂度的问题,我们提出了双路径注意力快(DAB),并行利用沿时间和频率维度的相关性。We further discover that the attention maps for different samples resemble each other, indicating sample-independent correlation is sufficient. 因此,我们在网络模型中采用了sample-independent DABs(SDABs)来平衡性能和计算成本。
2. Related Work
-
时频域方法:T-F域方法的成功得益于T-F谱图中丰富的听觉模式。作者认为沿着时间轴和频率轴同时学习长距离依赖是有必要的,因为语音中存在谐波,有效的区分噪声需要进行长期的统计。此外,并行的学习两种依赖关系可以更好的融合学习到的特征。
-
时域方法:时域方法的提出是为了解决T-F域方法中存在的问题。虽然诸如Conv-TasNet等网络模型在语音分离任务中取得了较好的结果,但当我们用此类方法解决语音增强问题时,往往无法取得超过T-F域方法的性能。造成这种现象的可能原因是语音和噪声模式在T-F域表示上很容易区分,而基于时域的方法无法利用这种先验知识。
3. The Proposed Scheme
本文设计的网络模型主要瞄准两个目标:
- 充分利用T-F谱的先验知识,因此模型以时频谱特征作为输入,此外通过双路注意力块分别沿时间和频率轴捕获长期依赖关系。
- 模型要克服T-F域方法的缺点,因此模型使用跨域框架,直接利用时域指标监督网络模型训练。
3.1 The TFT-Net Framework
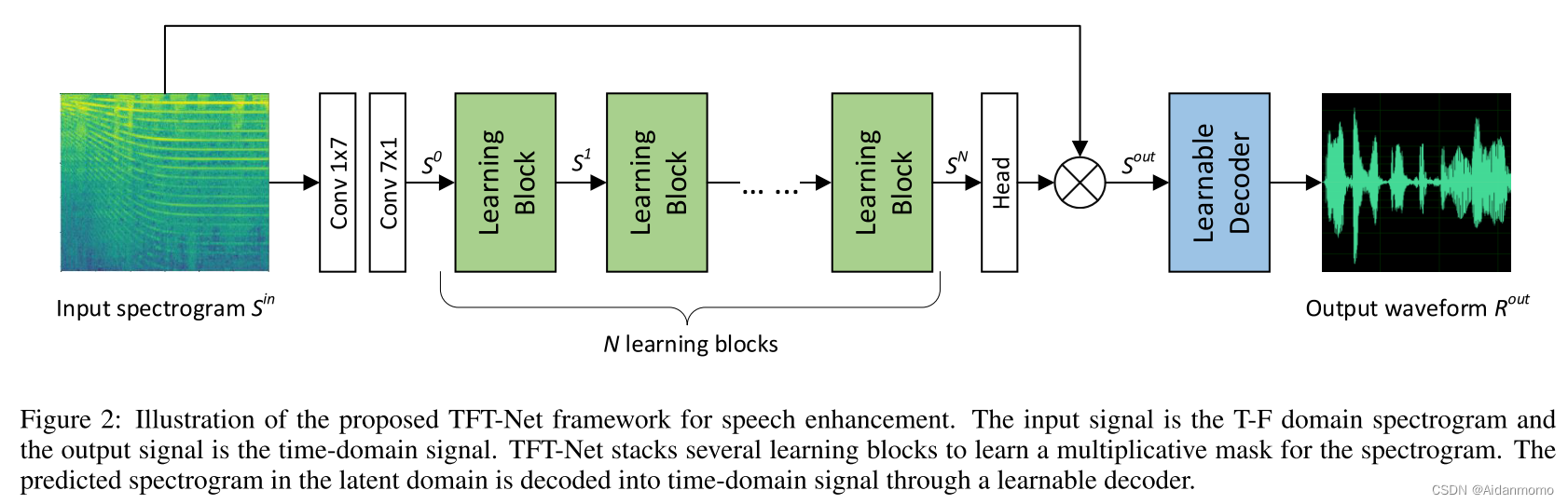
输入特征
S
i
n
∈
R
T
×
F
×
2
S^{in}\in \mathbb{R}^{T \times F \times 2}
Sin∈RT×F×2是复数谱。输入特征首先经过两个2D卷积层,生成特征
S
0
∈
R
T
×
F
×
C
S^0 \in \mathbb{R}^{T \times F \times C}
S0∈RT×F×C,之后,输入到N个堆叠的可学习块。
每个可学习块包含两个部分,如图3所示:
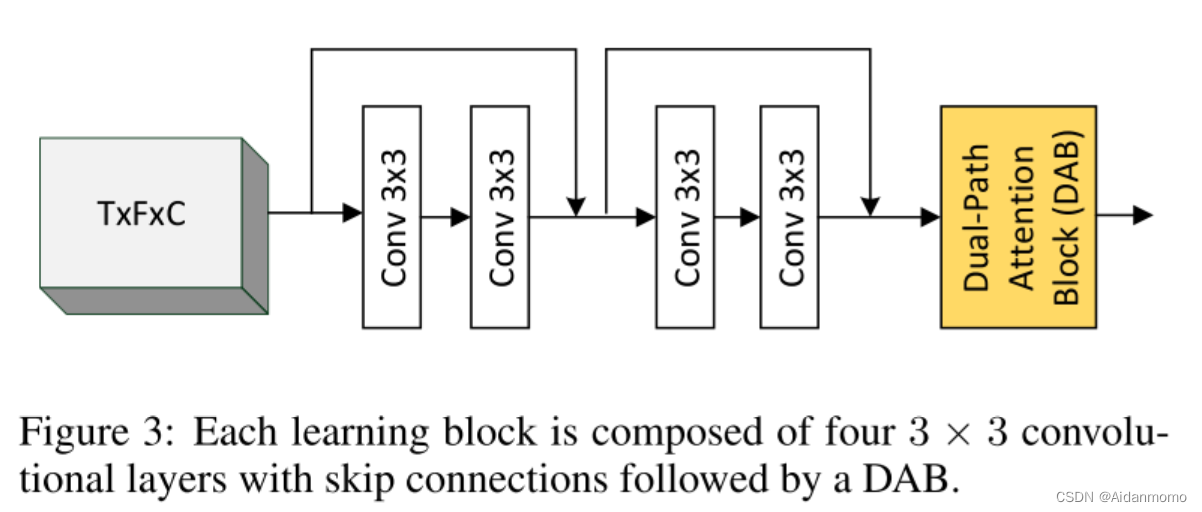
第一步部分是一组3x3卷积层,用于捕获局部依赖关系,本文模型中使用了4个卷积层,每个卷积层后连接批归一化。第二部分是DAB模块,用于学习长期依赖关系。每个可学习块的输出特征用
S
i
S^i
Si表示。
经过N个可学习块后,特征进入head layer,用于预测掩码
M
∈
T
×
F
×
C
m
M \in T \times F \times C_m
M∈T×F×Cm,增强后的谱
S
o
u
t
S^{out}
Sout可通过下式得到:

head layer使用1x1卷积层,
C
m
=
2
C_m=2
Cm=2,
f
(
M
)
=
t
a
n
h
(
∣
M
∣
)
∗
M
/
∣
M
∣
f(M)=tanh(|M|)*M/|M|
f(M)=tanh(∣M∣)∗M/∣M∣,
g
(
S
i
n
)
=
S
i
n
g(S_{in})=S_{in}
g(Sin)=Sin,符号表示复数乘法。最后,特征输入decoder,得到时域信号。损失函数为对数MSE loss。
在传统的做法中,编码器和解码器大多成对出现。虽然在Conv-TasNet中,作者说明decoder不一定要执行encoder的精确逆运算,本文依然使用了一些策略来确保网络模型的收敛性:可学习解码器的网络结构设计成与ISTFT的卷积实现完全相同,具体来说,该部分是一个一维反卷积层,其核大小和步长大小是STFT变换的窗长和hop size。
3.2 Dual-path Attention Block
针对T-F谱的长距离相关性包括时间轴和频率轴的相关性,音频信号作为时间序列,很明显具有时间轴上的全局相关性,此外,在频率轴上,存在着谐波关联性。本文将DAB设计成一个轻量级的解决方案,用于捕获长距离依赖性。

如图4所示,我们将二维T-F频谱特征分解为两个一维信号,一个沿着频率轴,一个沿着时间轴。
理想情况下,我们可以使用自注意力学习每个样本的注意力图,这样的操作可能是没有必要的。在经典的语音增强文献[Scalart and FILHO, 1996]中,使用了一个统一的非线性函数,在频率轴上重构谐波,这也与谐波相关是与样本无关的特性相匹配。在时间轴上,当计算信噪比(SNR)时,使用递归关系中的同一组参数,这表明时间相关性是时间不变的。基于以上分析,本文提出了一个与样本无关的DAB,或称为SDAB。F和T上的注意力层使用全连接层FC代替。沿着时间路径,FC层的输入和输出尺寸为T。沿着频率路径,FC层的输入和输出尺寸为F。FC层是一种使用可学习权重参数的注意力操作。换句话说,每两个元素之间的关系不是输入数据的函数。因此,使用FC层相当于为所有的训练数据学习一个与样本无关的相关性。SDAB进一步降低了网络的计算复杂性。
[Scalart and FILHO, 1996] Pascal Scalart and Jozue VIEIRA FILHO. Speech enhancement based on a priori signal to noise estimation. In ICASSP, volume 2, pages 629–632, 1996.
4. Experiments
4.1 Datasets
- AVSpeech + AudioSet
- Voice Bank + DEMAND
4.2 Evaluation Metrics
SDR, PESQ
CSIG,CBAK,COVL,SSNR
4.3 Implementation Details
STFT变换:25ms Hann窗,hop length=10ms,FFT size=512.输入特征大小为 301x257x2
卷积操作使用zero padding, dilation=1, stride=1,通道数为96
除了Head层,所有网络层后使用ReLU激活函数。所有卷积层后使用Batch Normalizaiton。
4.4 Ablation Study
学习率0.0002,Adam优化器,批大小为8。
4.4.1 One-path attention versus Dual-path attention

4.4.2 Sample-dependent versus Sample-independent
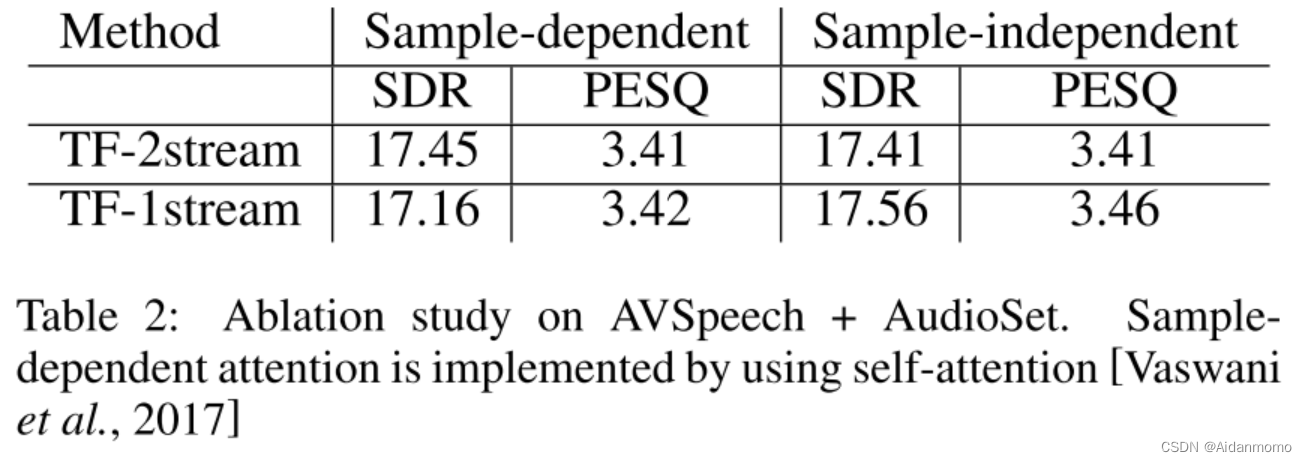

4.4.3 Cross-domain Framework

TF-1 stream 表示在T-F域框架下训练网络模型。SDR提升了0.84dB, PESQ下降了0.05,作者分析是因为使用了对数MSE损失函数的缘故。
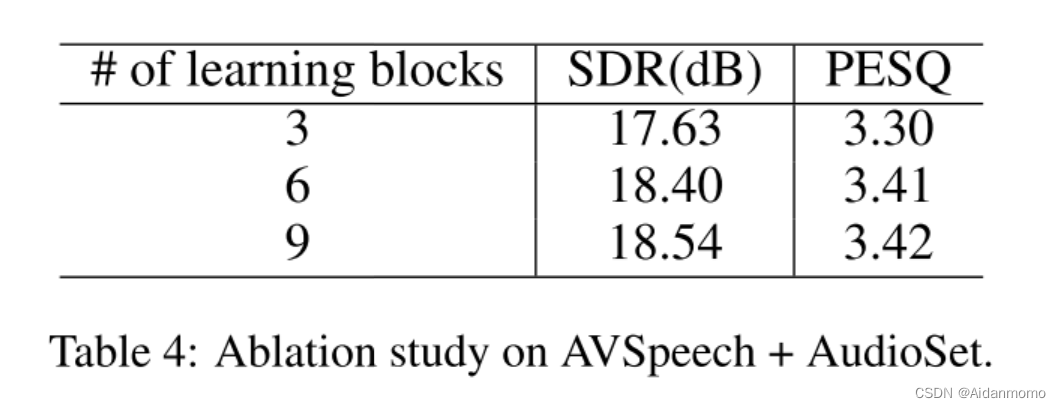
4.4.4 The number of learning blocks
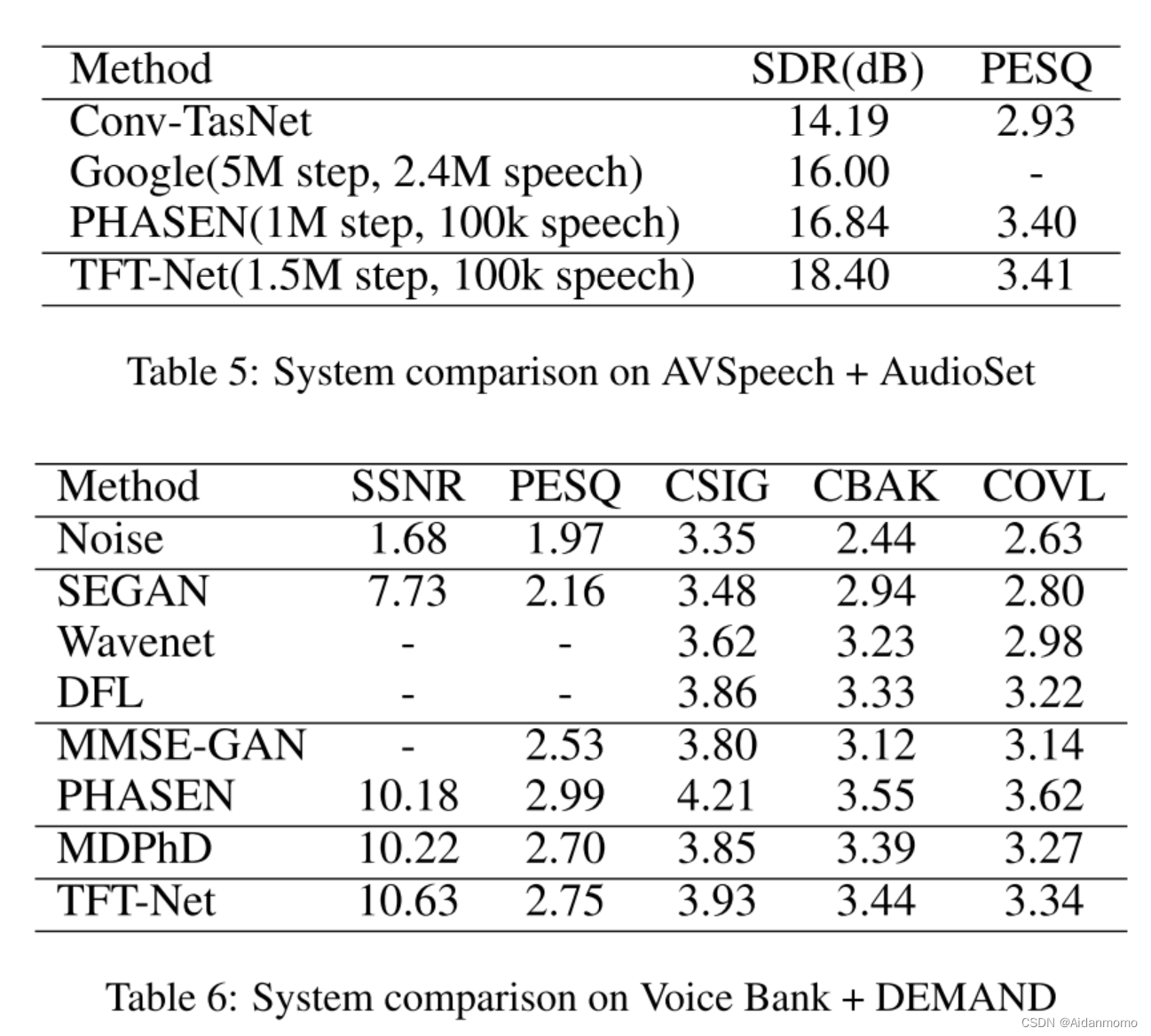
4.5 Comparision to State-of-the-Arts
















 3364
3364











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











