









GAN中的数学原理
一、Generator(生成器)
1、G想做的事情
Generator是一个生成器,可以是全连接神经网络、卷积神经网络等等,通过噪点分布P(z),一般是高斯分布,得到一个生成数据的分布Pg(x),G希望Pg(x)非常靠近Pdata(x),来拟合逼近真实分布。
简单来说:
现在知道Pdata(x)是真实的数据产生的分布。
G在做的事情就是,将z通过一个分布,化成Pg(x),尽量是Pg(x)与真实的Pdata(x)越相近越好。
把G想成一个骗子,你给G一个向量z,他就在想尽办法用这个z生成很像很像Pdata的Pg,试图骗过辨别器。

2、G在数学上做的事情
我们把Pg(x)和Pdata(x)之间的差异的英文名叫divergence,简写成Div,那么我们现在就是要找到一个合适的Generator叫做G*,使Pg与Pdata的Div越近越好。
下面的数学公式就是这个意思(div指的是差异,min是指取到差异的最小值,argmin(G)指的是 取最小差异值时,G的取值)
注解:arg min f(x):当f(x)取最小值时,x的取值
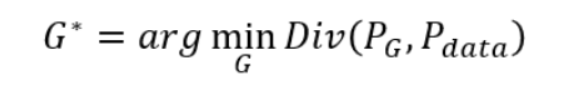
3、G不会的事情
Pg是一些向量通过某种变换生成的,Pdata是真实的数据分布(比如一一张人脸图像,是由很多个像素点通过某种人脸分布形成的,这种分布是未知的),我们都不知道他们的真实公式是什么样子。
但是我们不知道Pg和Pdata的公式,也就不知道怎么算Pg和Pdata的差异,G就无法改进自己,比如下图,蓝星是Pdata中抽样出来的,红星是Pg中抽样出来的。G不知道他俩的分布公式,也就算不出他们分布的差异。
 于是就引入了Discriminator(辨别器)来帮我们做这个事情
于是就引入了Discriminator(辨别器)来帮我们做这个事情
二、Discriminator(辨别器)
1、D想做的事情
Discriminator是一个判别器,需要解决传统的二分类问题,其职责就是有效的区分真实分布和生成分布,即衡量Pg(x)和Pdata(x)之间的差距。
简单来说,我们在上面已知有真实的Pdata和虚假的G生成的Pg两类数据,D想做的事情就是在一堆数据里面尽量把这两类分开,如下图就是找到一种公式把蓝色星星和红色星星分开。那么就给Pdata高分1,给Pg低分0。

2、D在数学上做的事情
定义目标函数为V(G,D)。这个V可以看成Discriminator(D)能识别Generator(G)骗术的能力。
D希望增大V的值让自己可以高效的判别出数据的真假类别,V(G,D)的表达式为:(其中E表示真实数据x和噪点数据z的∑p(data)和∑p(g),由于是连续的,我们可以将其写成微积分的形式来表示)

这一部分在数学上做的事情就是:找到一个合适的Discriminator叫做D*,使V(D ,G)尽可能高,即调Discriminator的参数(假设他有无穷个参数,可以变成任意分布),找到一组合适的参数来尽量区分真实数据与生成的数据,
简单来说,找一个D使V(D,G)越大越好,因为V(D,G)越大,就越能区分真实数据与生成器生成的数据
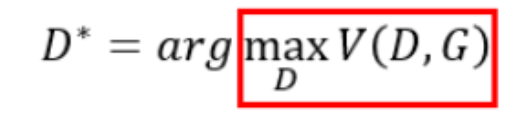
我们把积分里面的式子拿出来看一看:Pdata(x)是固定的,代写成a,Pg(x)是固定的,代写成b,这时,我们只需要求D(x)让这个式子算起来最大。
通过求微分,得到当D=D时这个式子最大。(如果看不懂中间过程也没关系,总之得到D的结果)

之后我们把求出来的D*,代回进V(G,D),则maxV(G,D)=

看上去这个式子很像KL散度公式,我们做进一步代换,代换完发现更像JS散度公式,又进一步代换。过程如下(KL散度和JS散度不懂可以百度一下,实在看不懂就算了,只要知道是在做点数学上的变换):

三、结合起来看
1、G和D的博弈
G希望它生成的Pg(x)非常靠近Pdata(x),来拟合逼近真实分布,而D希望它尽量辨别Pg(x)和Pdata(x),它希望找到一组参数将他们分的越开越好。
将D代入,那么G做的就是最小化最大值问题:

什么意思呢,我们举个例子:
此时红点就代表了D在取到V(G,D)最大值的情况,就是它能把Pdata和Pg分的最清楚的情况,即能分辨骗术的能力上限。
而我们G试了三种骗法:G1、G2、G3。G想要最小化D分辨骗术的最高能力,发现绿色方框时D的能力上限最弱,于是取G3为最佳的骗术。

2、最小化最大值问题
要解这个最小化最大值问题:
Step1:首先固定生成器G,找到一个能够使V最大的D;
Step2:然后固定辨别器D,找到能够使这个最大情况下V最小的G。不停的迭代。

我们从G的方面,引入散度来深入理解:
Step1:初始一个G0
Step2:算PG0与Pdata之间的JS散度
Step3:微调整G0成为G1,降低JS散度
Step4:算PG1与Pdata之间的JS散度
Step5:重复迭代,就可以使G产生的数据不断贴合真实数据

四、具体算法

step1:初始化Generator(生成器)和Discriminator(辨别器)
step2:然后从database中抽取m个图片;从一个分布中抽取m个vector,
使用m个vector产生m个image。
step3:Generator不变,更新Discriminator的参数去最大化V,
使V尽量达到等于JS散度(因为不一定会很快收敛,且JS散度要求无穷参数)
step4:从一个分布中抽取m个vector,
此时Discriminator不变,去更新Generator的参数取最小化V
(少量的调整,调整多了你量出来的JS散度就不对了)

















 4743
4743











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











