






虽说通义万相是目前最好的免费文生视频生成模型,但仍然有很多小伙伴无法直接使用该模型生成自己想要的完美视频,这是为什么呢?其实想要生成一条完美的视频,光学习提示词工+使用模型还是不够的,还需要搭载素材lora,实现细节性微调,达到逼真视频质感。那么今天我们就介绍更详细的通义万象LoRA炼丹!咱们无阶未来通义万象wan2.1炼丹炉已上线!!欢迎体验!!
感谢本文作者轻松提供本次训练教程。

这里我们将为你介绍各部分参数的意义以及如何进行修改。以及最后使用Lora的效果。使用Lora的意义是为了让通义万相能生成我们需要的特定人物或者动作的视频,我们以爆火的哪吒经典形象为例,使用训练的Lora来生成电影中的哪吒的形象。LORA丹炉不可直接点开,还是一样需要在jupyter内进行使用!!!
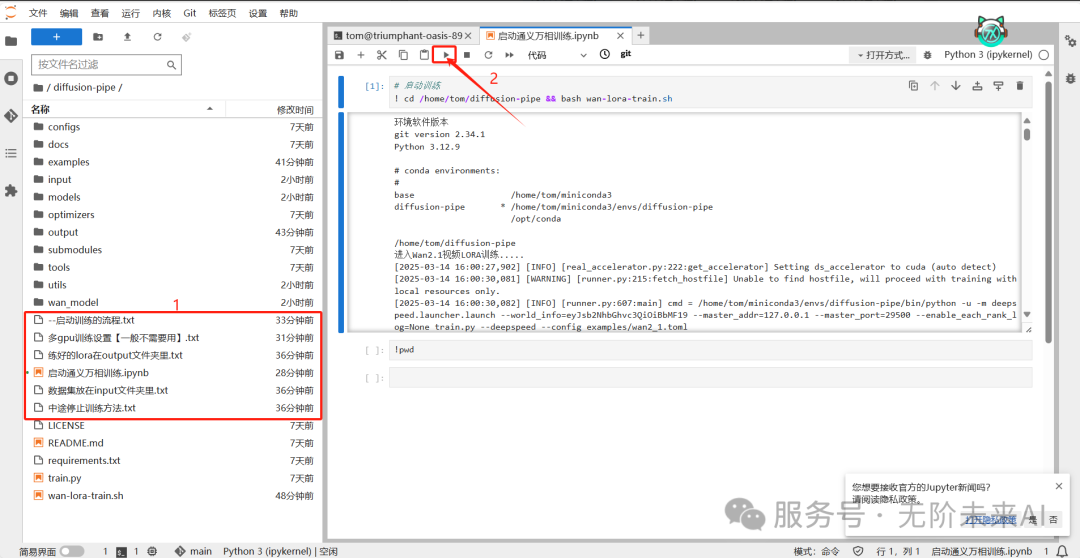
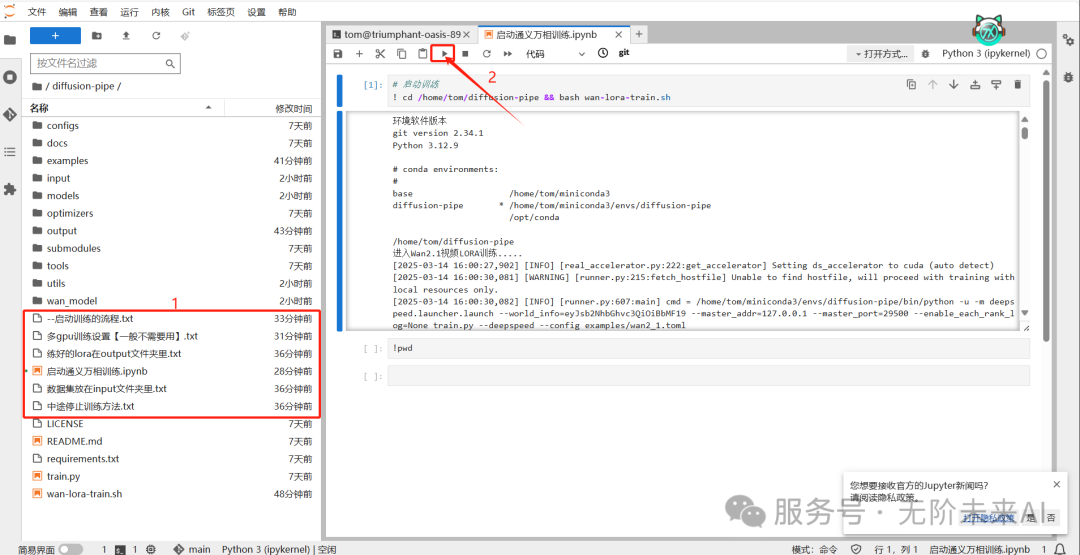
首先我们进入jupyter后,如图中左侧文件夹所圈选的地方,已经有较为完整的镜像教程,你可以点击查看。上部框选的横向三角点击后即可开始训练。当然这篇文章我们会比镜像中的教程更为详细,但仍然建议你在使用镜像的时候看看里面的教程。
在训练之前,我们需要准备好相应的训练集。本次我们依旧使用哪吒,当然你的每张图片都需要打上对应的标签,并且要是自然语言的标签。这里推荐的自然语言打标器为joy-caption2以及Florence 2。打标后的内容如下图,首个词为触发词,一定要写触发词,否则模型无法识别该形象,如果你觉得描述不够准确,可以人为进行调整。


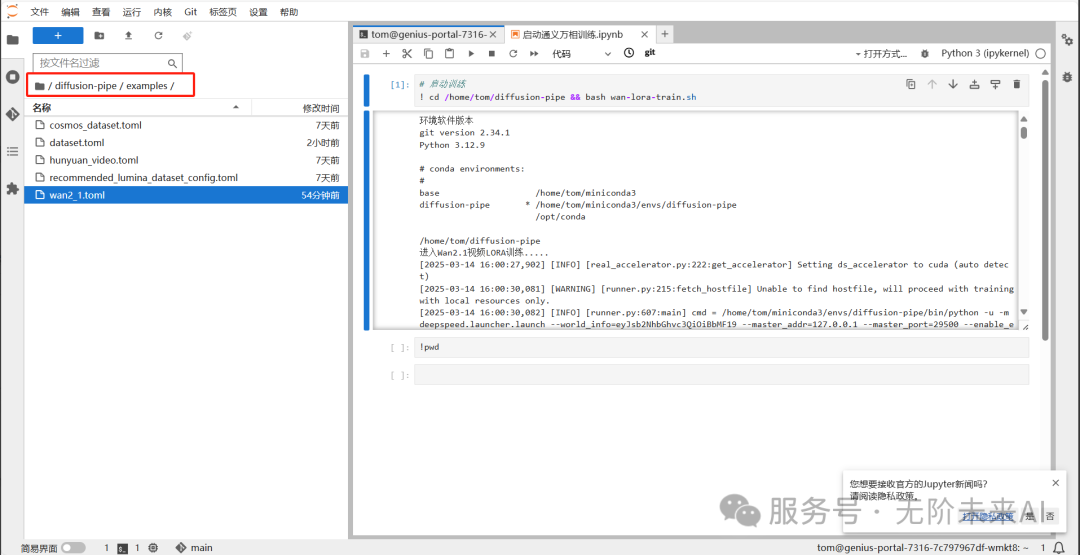
接着我们来看参数,参数文件在如下图的位置:点开wan2_1.toml文件。这套参数已经是配好的训练效果较好的参数,大部分情况不需要进行修改。
基础配置:
output_dir = '/home/tom/diffusion-pipe/output'
训练结果的输出目录
dataset= 'examples/dataset.toml'
训练数据集配置文件路径(TOML格式)
训练设置:
epochs= 30
总训练轮数
micro_batch_size_per_gpu= 1
单个GPU的微批次大小(实际批次大小 = micro_batch_size × GPU数量 × gradient_accumulation_steps)
pipeline_stages= 1
流水线并行度,模型分割到多个GPU的数量(1表示无流水线并行)
gradient_accumulation_steps= 4
梯度累积步数,用于增大有效批次大小,提升GPU利用率
gradient_clipping= 1.0
梯度裁剪阈值,防止梯度爆炸
warmup_steps= 50
学习率预热步数,逐步提升学习率到初始值
评估设置:
eval_every_n_epochs= 1
每n轮进行一次评估
eval_before_first_step= true
是否在训练开始前执行首次评估
eval_micro_batch_size_per_gpu= 1
评估时的微批次大小(通常小于训练批次)
eval_gradient_accumulation_steps= 1
评估时的梯度累积步数
其他设置:
save_every_n_epochs= 2
每隔n轮保存一次模型
checkpoint_every_n_minutes= 120
每隔n分钟保存训练状态检查点(与checkpoint_every_n_epochs二选一)
activation_checkpointing= true
激活检查点技术,通过时间换显存
partition_method= 'parameters'
模型分片策略(基于参数数量划分)
save_dtype= 'bfloat16'
模型保存精度(可不同于训练精度)
caching_batch_size= 1
预缓存潜在特征和文本嵌入的批次大小
steps_per_print= 1
控制DeepSpeed的日志打印频率
video_clip_mode= 'single_middle'
视频片段采样方式(从视频中间取单片段)
模型配置 ([model]):
type= 'wan'
模型架构类型(支持flux/ltx-video/hunyuan-video/wan)
ckpt_path
预训练模型检查点路径
dtype= 'bfloat16'
基础计算精度
适配器配置 ([adapter]):
type= 'lora'
适配器类型(当前仅支持LoRA)
rank= 32
LoRA的低秩矩阵维度
dtype= 'bfloat16'
LoRA权重的训练精度
优化器配置 ([optimizer]):
type= 'adamw_optimi'
优化器类型(使用Optimi库的AdamW实现)
lr= 2e-5
初始学习率
betas= [0.9, 0.99]
Adam的动量参数
weight_decay= 0.01
权重衰减系数
eps= 1e-8
数值稳定项
而这么多数值,我们大部分都不需要进行改动,我们主要修改的地方为;
epochs,save_every_n_epochs,rank,lr这几个数值。
Epoch:将图片训练多少轮次。
save_every_n_epochs:每几轮存一次模型,
Rank:你在这里将他理解为概念容纳量即可
Lr:学习率
当你觉得学的不够像的时候,epoch,rank,lr都可以进行适当的调高。这里的epoch数约20左右即可,我们见下面的测试。
这里我们就在启动器页面点击横向三角开始训练。
我们看到如下图中step数开始变化的话,就代表Lora开始训练了:
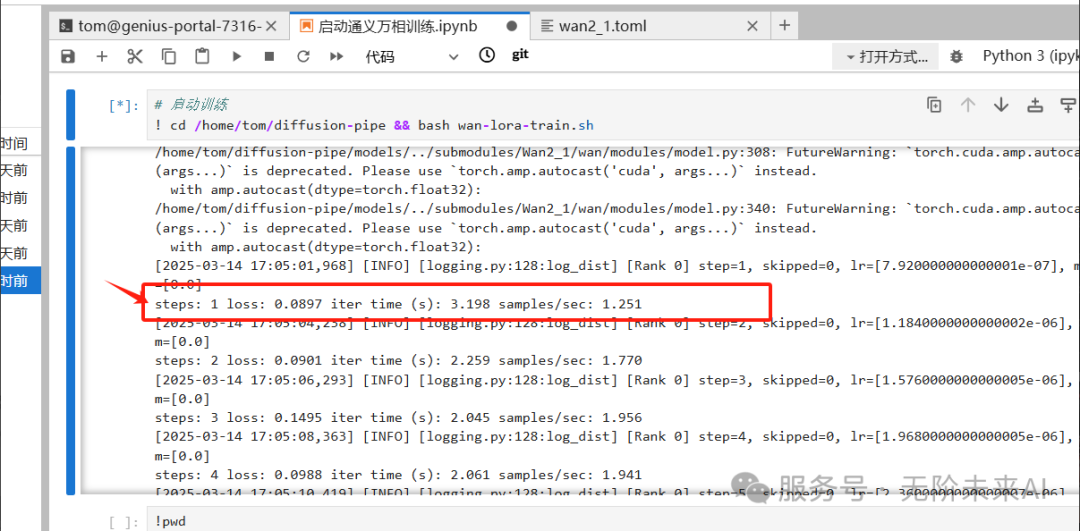
这里训练采用的是40G显存的A100进行训练,训练集图片数为19。这里建议lora训练尽可能选择显存较高的卡型,这样效果比较好,或者如果使用4090及以下配置,建议至少开2张,效果才能比较不错。
还是一样的操作,我们将训练好的素材在output文件夹找到,然后重新进入【通义万相满血版】应用内,载入训练好的lora,查看效果。载入方法还是一样,打开通义万相满血版应用,进入jupyter,找到lora文件夹,上传你训练好的lora即可。
我们先看epoch10的效果:特征已经在拟合。
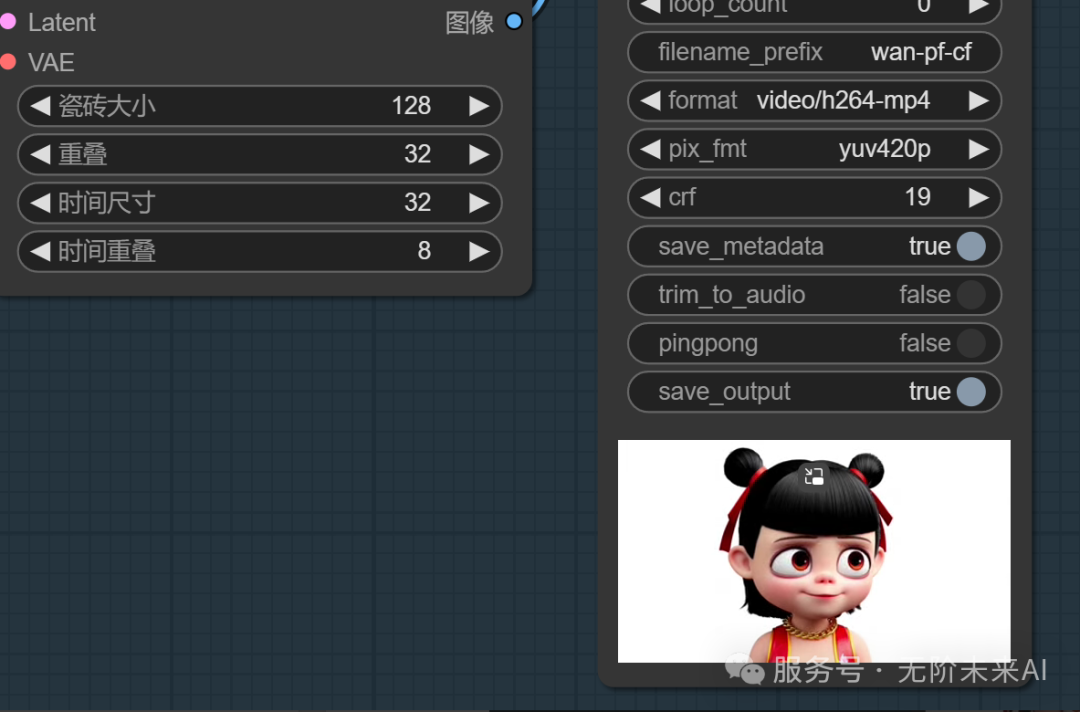
再看16epoch的效果:哪吒形象已经拟合,我们可以再等几个epoch,让特征更稳定。
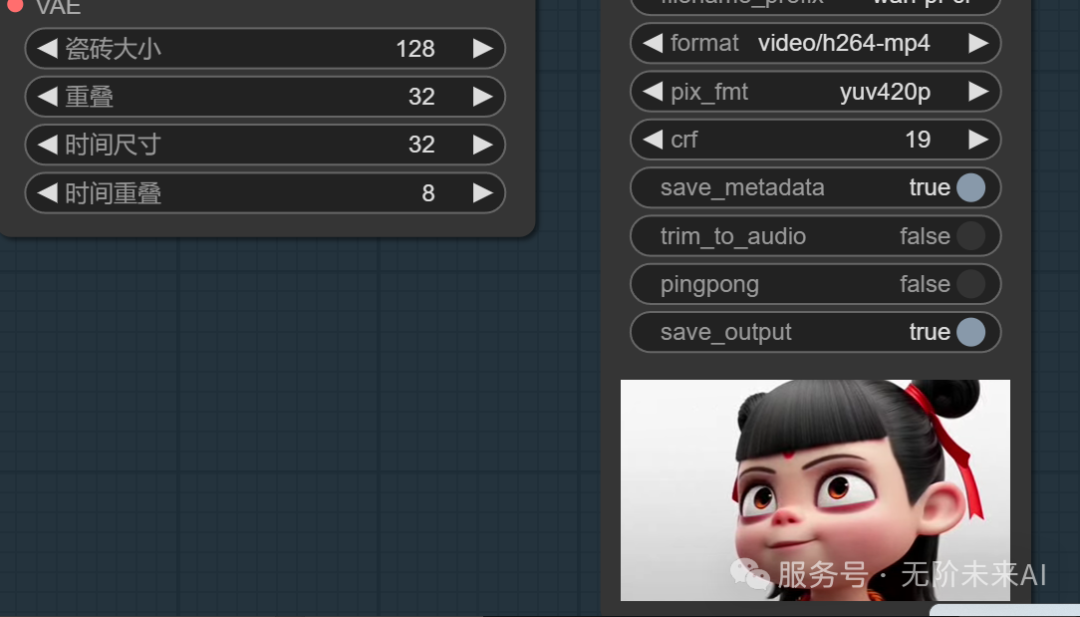
我们再看epoch20的效果:效果已经很好,已经可以用于生成哪吒的视频了,但我们可以等到镜像中给的最大训练数epoch30。
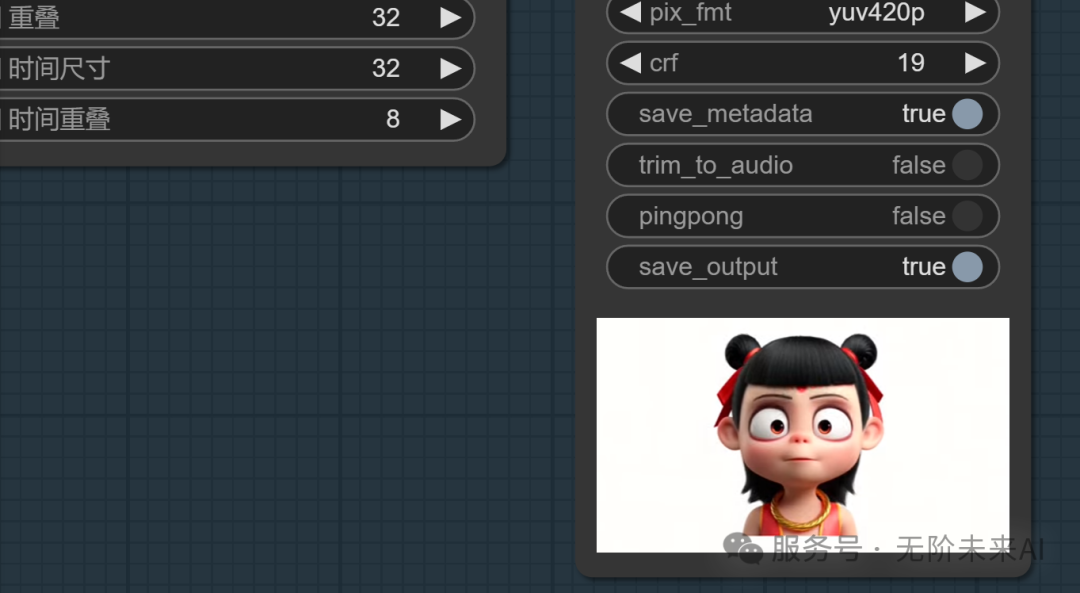
我们在epoch20的时候的实际时间为:19:57分,我们的开始时间为19点整,也就是19张训练集在上述情况下,该参数训练所需时间约为60分钟左右。我们控制epoch到30以内基本都可以较好拟合。

出现下图中框中所示即为训练完成,同时我们可以看到训练30个epoch的时间约为1小时30分钟。

我们最后再来看下epoch30最终的效果:效果非常好,对比咱们之前同样参数的混元训练,通义显然清晰度、识别度均高出很多。

最后,开源社区仍然在发展,笔者衷心希望我们能够共同学习,一起进步。想学习更多炼丹知识的小伙伴,欢迎加入无阶未来官方社群,一键学习更多的AI知识。
欢迎加入无阶未来用户群,一键学习更多AI生图内容!


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









