








一.前置知识
DMA的基本概念
DMAC对数据传送的控制是建立在掌握系统总线的使用权基础上的
正常工作下,系统总线的使用权归CPU所有
DMAC要控制DMA传送,必须要从CPU得到总线使用权
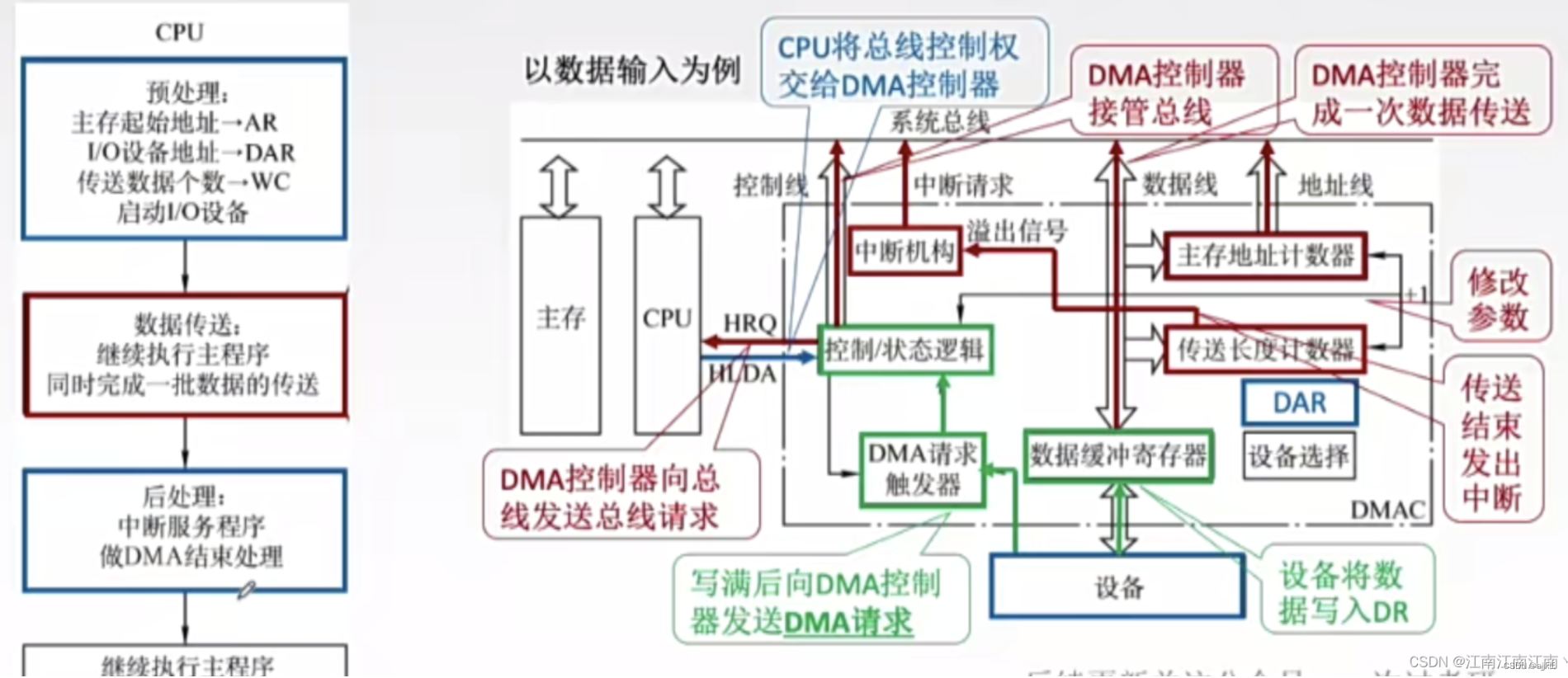
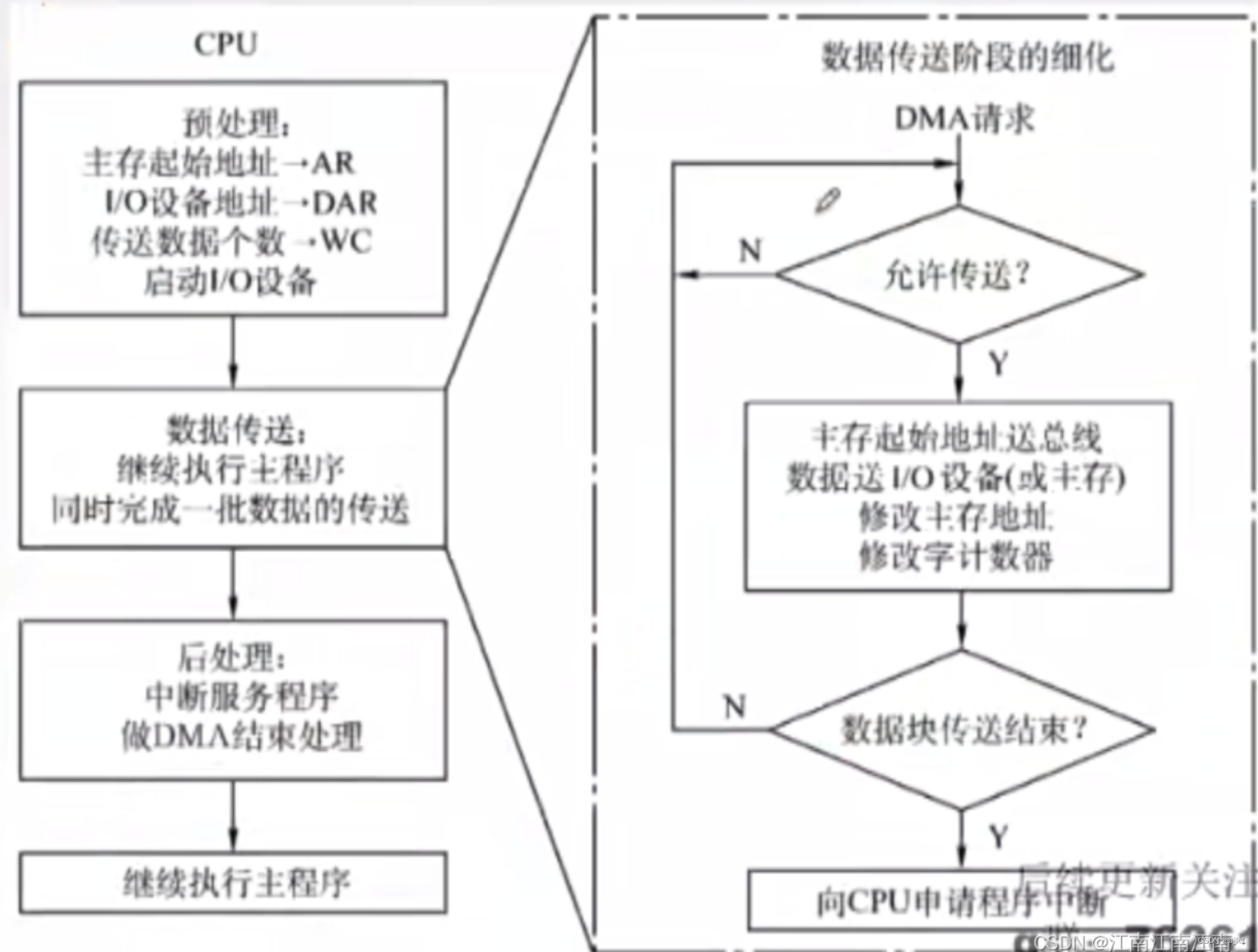
DMAC传送的过程
1.总线申请阶段
2.总线响应阶段
3.数据传送阶段
4.传送结束阶段
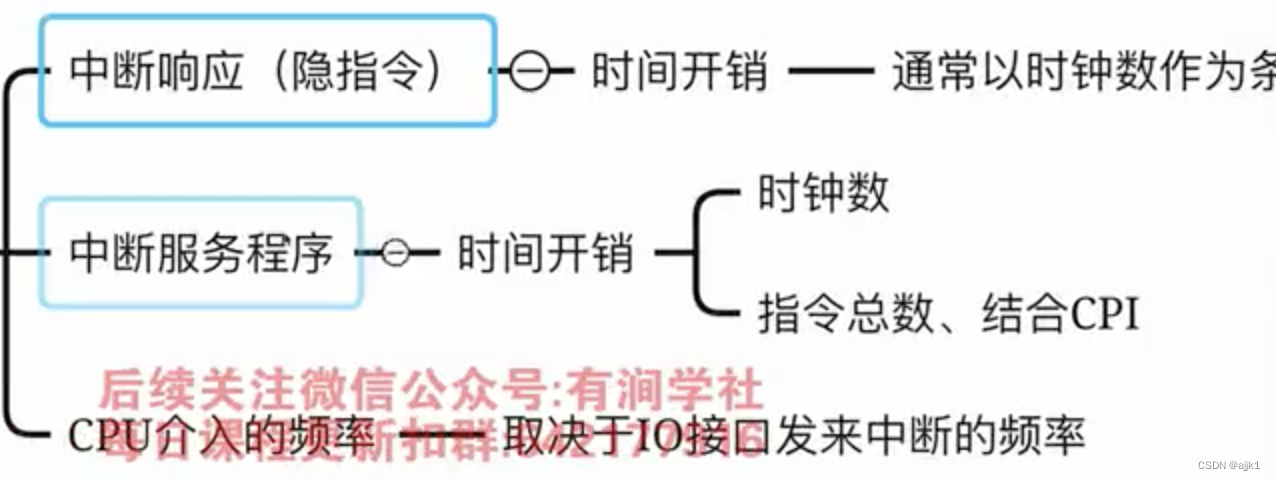
DMA方式和中断控制方式的区别
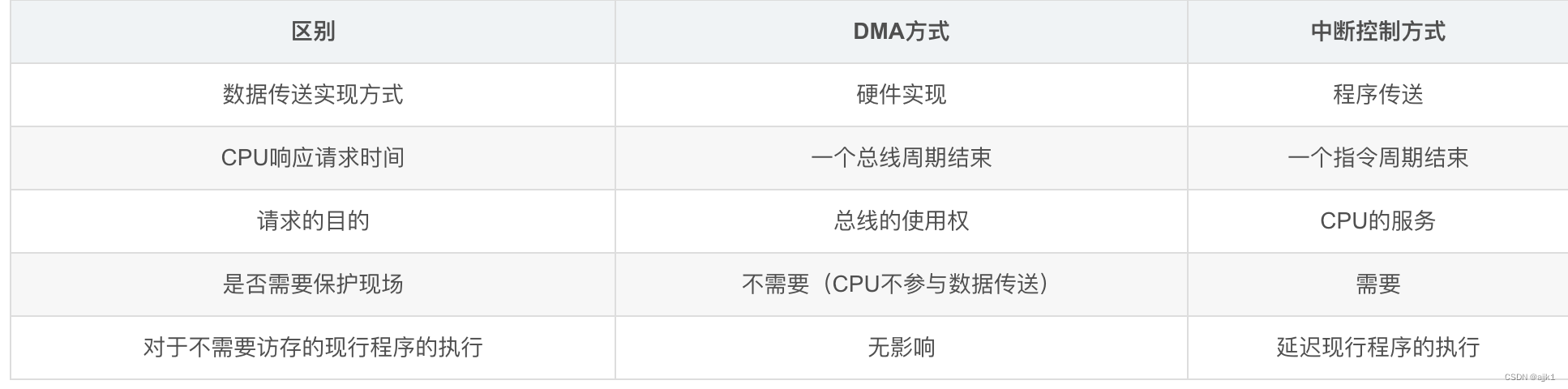
DMA的优先权高于中断的优先权(因为DMA可以在指令周期(总线周期结束)内获取总线控制权,而中断需要在指令周期结束后
DMA传送方式
- 停止CPU访问方式(连续方式)
- 周期挪用方式(单字节方式)
- DMA与CPU交替访问方式(透明DMA方式)
周期挪用
在这种方法中,每当I/O设备发出DMA请求时,I/O设备便挪用或窃取总线占用权一个或几个主存周期,而DMA不请求时,CPU仍继续访问主存。
I/O设备要求DMA传送会遇到三种情况,一种是此时CPU不需访问主存(如CPU正在执行乘法指令,由于乘法指令执行时间较长,此时CPU不需访问主存),故I/O设备访存与CPU不发生冲突。第二种情况是I/O设备要求DMA传送时,CPU正在访存,此时必须待存取周期结束时刻,CPU才能将总线占有权让出。第三种情况是I/O设备要求访存时,CPU也要求访存,这就出现了访存冲突。此刻,I/O访存优先于CPU访存,因为I/O不立即访存就可能丢失数据,这时I/O要窃取一二个存取周期,意味着CPU在执行访存指令过程中插入了DMA请求,并挪用了一二个存取周期,使CPU延缓了一二个存取周期再访存。
与CPU暂停访存的方式相比,它既实现了I/O传送,又较好地发挥了主存与CPU的效率,是一种广泛采用的方法。
应该指出,I/O设备每挪用一个主存周期都要申请总线控制权、建立总线控制权和归还总线控制级权。因此,尽管传送一个字对主存而言只占用一个主存周期,但对DMA接口而言,实质上要占2—5个主存周期(由逻辑线路的延迟特性而定)。因此周期挪用的方法比较适合于I/O设备的读写周期大于主存周期的情况。
这里做一个小总结:
- CPU此时不访存,直接占用
- CPU正在访存,等待访存周期完成
- CPU与DMA同时请求访存:此时CPU将总线控制权让给DMA
暂停CPU访问方式
CPU放弃了对总线的控制权,放弃了对主存的访问。控制简单CPU处于不工作状态或保持状态,未充分发挥CPU对主存的利用率,这里是I/O一块数据块只发出一次请求,一次占用总线控制权到底
DMA与CPU交替访问
CPU工作周期:C1专供DMA访存,C2专供CPU访存不需要申请、建立和归还总线的使用权(还没有考过,但是应该有所了解,此时DMA请求次数为0)
DMA传送过程
DMA请求和DMA中断请求的区别:
DMA请求表示DMA将要和主存进行一个字的传输
DMA中断请求表示DMA和主存已经完成一整块的传输
二.解题思路
(1),由题目背景知Cache的命中率为99%,则Cache的缺失率为0.01,平均每秒的缺Cache次数
,若要满足CPU的访存要求.访存的次数我们已知是0.3M次,要满足访存要求,则主存带宽为0.3M*16B=4.8MB/s(直接访存在Cache缺失后发生)
(2)在上题中,我们知道每秒缺失Cache的次数为300000次,则平均每秒产生300000*0.000005=1.5次缺页,页面大小为4KB,每秒需要I/O的数据为4KB*1.5=6KB,磁盘I/O接口发出的DMA请求次数至少为6KB/4B=1.5K次=1536次
注:I/O接口与CPU的数据交换以块为单位,I/O设备与I/O接口的数据交换以字为单位(我认为是缓冲区),在周期挪用方式下,缓冲区充满一次发出一次DMA请求,这里对CPU介入I/O的时机做一个补充

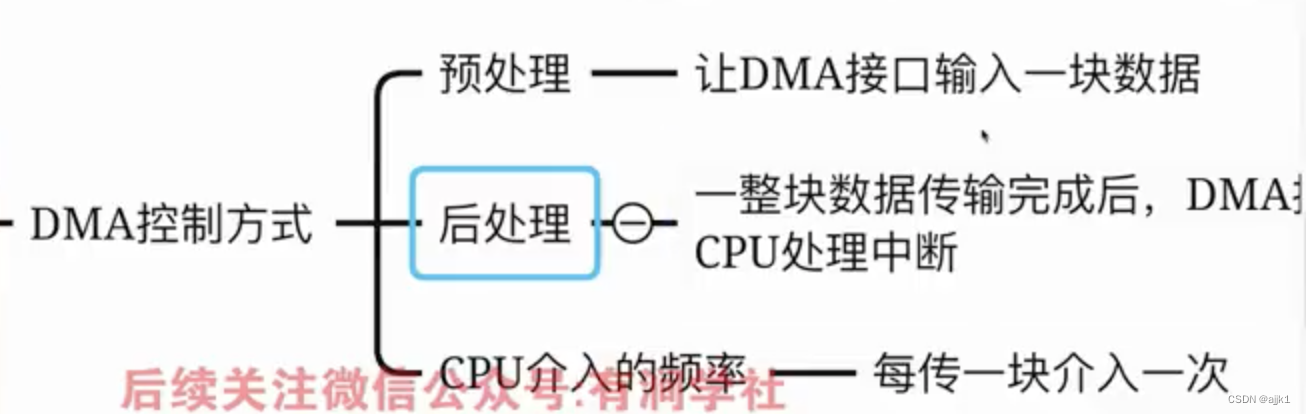
(3)DMA控制器使用存储器总线的优先级更高,因为DMA准备好了块后,如果不及时获得存储器总线则会产生丢失数据的风险(这是DMA不丢失数据的保证)
(4)采用4体低位交叉存储模式,存储体周期为50ns,启动每个存储体的时间为50ns/4=12.5ns,每一次访存,由存储器总线大小为32位,即4B可得,最大带宽为4B/12.5ns=320000B/s

















 1236
1236

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









