






1、helloworld
环境配置
conda create -n llama3 python=3.10
conda activate llama3
conda install pytorch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2 pytorch-cuda=12.1 -c pytorch -c nvidia
下载模型
ln -s /root/share/new_models/meta-llama/Meta-Llama-3-8B-Instruct ~/model/Meta-Llama-3-8B-Instruct
Web Demo 部署
cd ~
git clone https://github.com/SmartFlowAI/Llama3-XTuner-CN
cd ~
git clone -b v0.1.18 https://github.com/InternLM/XTuner
cd XTuner
pip install -e .
streamlit run ~/Llama3-XTuner-CN/tools/internstudio_web_demo.py \
/root/model/Llama-3-8B-Instruct
坑:
1、我本地之前link过,路径不对。streamlit run ~/Llama3-XTuner-CN/tools/internstudio_web_demo.py \
/root/model/Meta-Llama-3-8B-Instruct
2、路径对了可能不需要改代码:

搞定后

2、XTuner 微调 Llama3 个人小助手认知
自我认知训练数据集准备
cd ~/Llama3-XTuner-CN
python tools/gdata.py
大概2句话2000次?

XTuner配置文件准备
mkdir /root/project/
mkdir /root/project/llama3-ft
cp -R ./configs /root/project/llama3-ft
吃一堑长一智,
pack_to_max_length = False
修改
vi configs/assistant/llama3_8b_instruct_qlora_assistant.py
训练模型
cd /root/project/llama3-ft
# 开始训练,使用 deepspeed 加速,A100 40G显存 耗时24分钟
xtuner train configs/assistant/llama3_8b_instruct_qlora_assistant.py --work-dir /root/llama3_pth
# Adapter PTH 转 HF 格式
xtuner convert pth_to_hf /root/llama3_pth/llama3_8b_instruct_qlora_assistant.py \
/root/llama3_pth/iter_500.pth \
/root/llama3_hf_adapter
# 模型合并
export MKL_SERVICE_FORCE_INTEL=1
xtuner convert merge /root/model/Meta-Llama-3-8B-Instruct \
/root/llama3_hf_adapter\
/root/llama3_hf_merged
其实1个epoch足以。10分钟加载,10分钟训练,差不多可以搞定2000次还可以减少些,600次差不多。后面loss居然为0.看啦llama3确实学的快啊,微调快。

推理验证
streamlit run ~/Llama3-XTuner-CN/tools/internstudio_web_demo.py \
/root/llama3_hf_merged
XTuner 微调 Llama3 图片理解多模态
貌似44g显存,得额外申请算力,100%才能玩,目前只能申请50%
群里5.4给出了解决办法
避坑建议:
所有学习第三课的同学,如果你申请的显存不会100%,只是30%,请在微调的过程中,请一定xtuner train命令后追加***_offload,要不然会报内存不足。
xtuner train ~/Llama3-Tutorial/configs/llama3-llava/llava_llama3_8b_instruct_qlora_clip_vit_large_p14_336_lora_e1_finetune.py --work-dir ~/llama3_llava_pth --deepspeed deepspeed_zero2_offload
conda create -n llama3 python=3.10
conda activate llama3
conda install pytorch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2 pytorch-cuda=12.1 -c pytorch -c nvidia
cd ~
git clone -b v0.1.18 https://github.com/InternLM/XTuner
cd XTuner
pip install -e .[all]
cd ~
git clone https://github.com/SmartFlowAI/Llama3-Tutorial
cd ~
git clone https://github.com/InternLM/tutorial -b camp2
#数据准备
python ~/tutorial/xtuner/llava/llava_data/repeat.py \
-i ~/tutorial/xtuner/llava/llava_data/unique_data.json \
-o ~/tutorial/xtuner/llava/llava_data/repeated_data.json \
-n 200
模型准备
mkdir -p ~/model
cd ~/model
ln -s /root/share/new_models/meta-llama/Meta-Llama-3-8B-Instruct .
mkdir -p ~/model
cd ~/model
ln -s /root/share/new_models/openai/clip-vit-large-patch14-336 .
mkdir -p ~/model
cd ~/model
ln -s /root/share/new_models/xtuner/llama3-llava-iter_2181.pth .
开始训练,果然ok,预计3小时
xtuner train ~/Llama3-Tutorial/configs/llama3-llava/llava_llama3_8b_instruct_qlora_clip_vit_large_p14_336_lora_e1_finetune.py --work-dir ~/llama3_llava_pth --deepspeed deepspeed_zero2_offload

在训练好之后,我们将原始 image projector 和 我们微调得到的 image projector 都转换为 HuggingFace 格式,为了下面的效果体验做准备。
xtuner convert pth_to_hf ~/Llama3-Tutorial/configs/llama3-llava/llava_llama3_8b_instruct_qlora_clip_vit_large_p14_336_lora_e1_finetune.py \
~/model/llama3-llava-iter_2181.pth \
~/llama3_llava_pth/pretrain_iter_2181_hf
xtuner convert pth_to_hf ~/Llama3-Tutorial/configs/llama3-llava/llava_llama3_8b_instruct_qlora_clip_vit_large_p14_336_lora_e1_finetune.py \
~/llama3_llava_pth/iter_1200.pth \
~/llama3_llava_pth/iter_1200_hf
体验效果
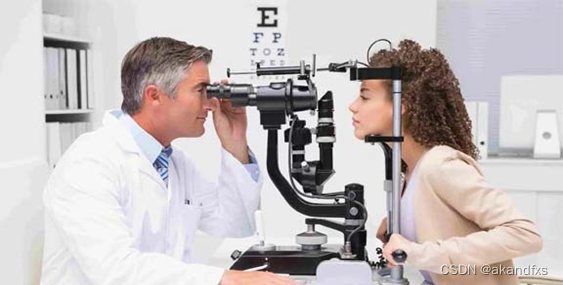
输入图片/root/tutorial/xtuner/llava/llava_data/test_img/oph.jpg
export MKL_SERVICE_FORCE_INTEL=1
xtuner chat /root/model/Meta-Llama-3-8B-Instruct \
--visual-encoder /root/model/clip-vit-large-patch14-336 \
--llava /root/llama3_llava_pth/pretrain_iter_2181_hf \
--prompt-template llama3_chat \
--image /root/tutorial/xtuner/llava/llava_data/test_img/oph.jpg
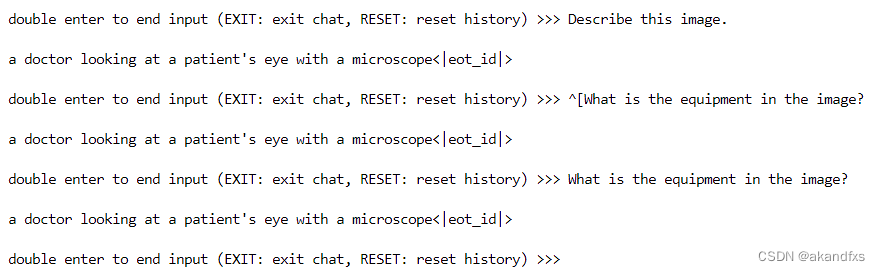
输入问题1:Describe this image. 问题2:What is the equipment in the image?
LMDeploy 高效部署 Llama3 实践
- 环境,模型准备
看着和其它类似,继续用llama3.
pip install -U lmdeploy[all]
- LMDeploy Chat CLI 工具
lmdeploy chat /root/model/Meta-Llama-3-8B-Instruct
唉,智商还是不太够啊

- LMDeploy模型量化(lite)
lmdeploy chat /root/model/Meta-Llama-3-8B-Instruct/ --cache-max-entry-count 0.5
这回随机的智商在线了

lmdeploy chat /root/model/Meta-Llama-3-8B-Instruct/ --cache-max-entry-count 0.01

kv的cache居然能占用这么多内存
其实速度还行,仍然智商在线
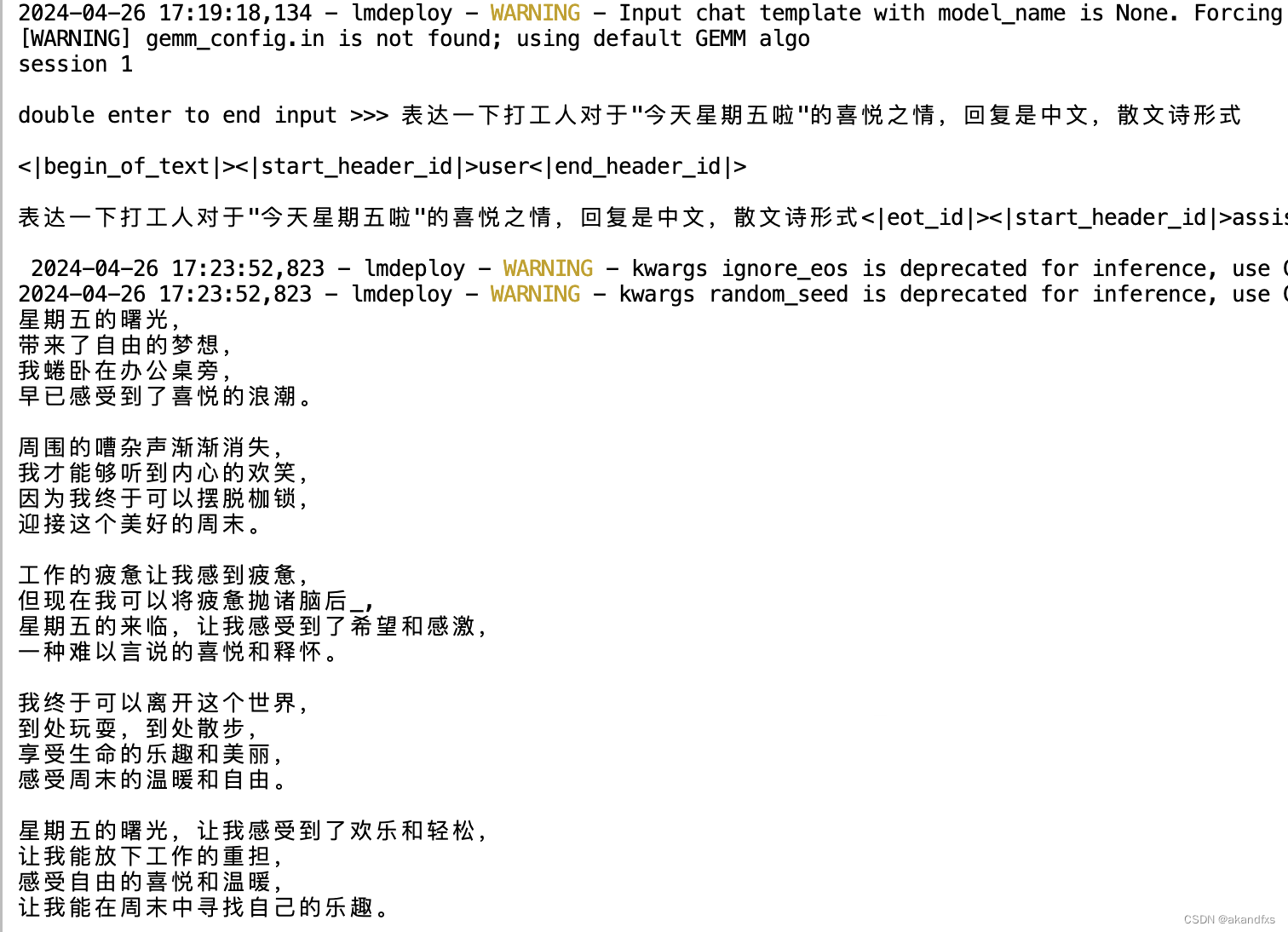
3.2 使用W4A16量化
lmdeploy lite auto_awq \
/root/model/Meta-Llama-3-8B-Instruct \
--calib-dataset 'ptb' \
--calib-samples 128 \
--calib-seqlen 1024 \
--w-bits 4 \
--w-group-size 128 \
--work-dir /root/model/Meta-Llama-3-8B-Instruct_4bit
lmdeploy chat /root/model/Meta-Llama-3-8B-Instruct_4bit --model-format awq
lmdeploy chat /root/model/Meta-Llama-3-8B-Instruct_4bit --model-format awq --cache-max-entry-count 0.01

量化成效卓著
显存只需要6738M,不到7G

速度飞快,智商在线,虽然看着确实下降了一丢丢,重复的比较多了。
3.3 在线量化 KV
这个看着不错,我用的p40显卡机器可以搞搞了。

4. LMDeploy服务(serve)
略。
Llama 3 Agent 能力体验+微调(Lagent 版)
- Llama3 ReAct Demo
按教程默认参数微调需要1天零7个半小时。30%A100,占用内存20g/24g,先不微调,用官方的吧。















 1614
1614











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









