







一、引言
Blog链接:https://ai.meta.com/blog/meta-llama-3/
MODEL CARD: https://github.com/meta-llama/llama3/blob/main/MODEL_CARD.md
体验链接:https://meta.ai/ or https://huggingface.co/chat/
4月18日,Meta突然发布Llama 3, 在Llama 2的基础上进行了进一步的升级,包括使用更高质量的数据集、模型架构的改进、引入新的信任和安全工具(如Llama Guard 2、Code Shield和CyberSec Eval 2)等;
这次Llama 3 的发布包括了8B 和 70B 两种规模的预训练和指令微调生成文本模型。

Llama 3型号将很快在AWS、Databricks、Google Cloud、huggingFace、Kaggle、IBM WatsonX、微软Azure、NVIDIA NIM和Snowflake上推出,并得到AMD、AWS、戴尔、英特尔、NVIDIA和高通提供的硬件平台的支持
二、卓越的性能
2.1 标准测试
这次的 Llama 在性能上展现了大幅度提升,包括最直接的 8k 上下文(之前是4k),以及可以更好地完成输出任务。
通过pre-training和post-training的改进,Llama 3的预训练和指令微调模型是目前在8B和70B参数尺度上存在的最好的模型(截止至发布日期)。
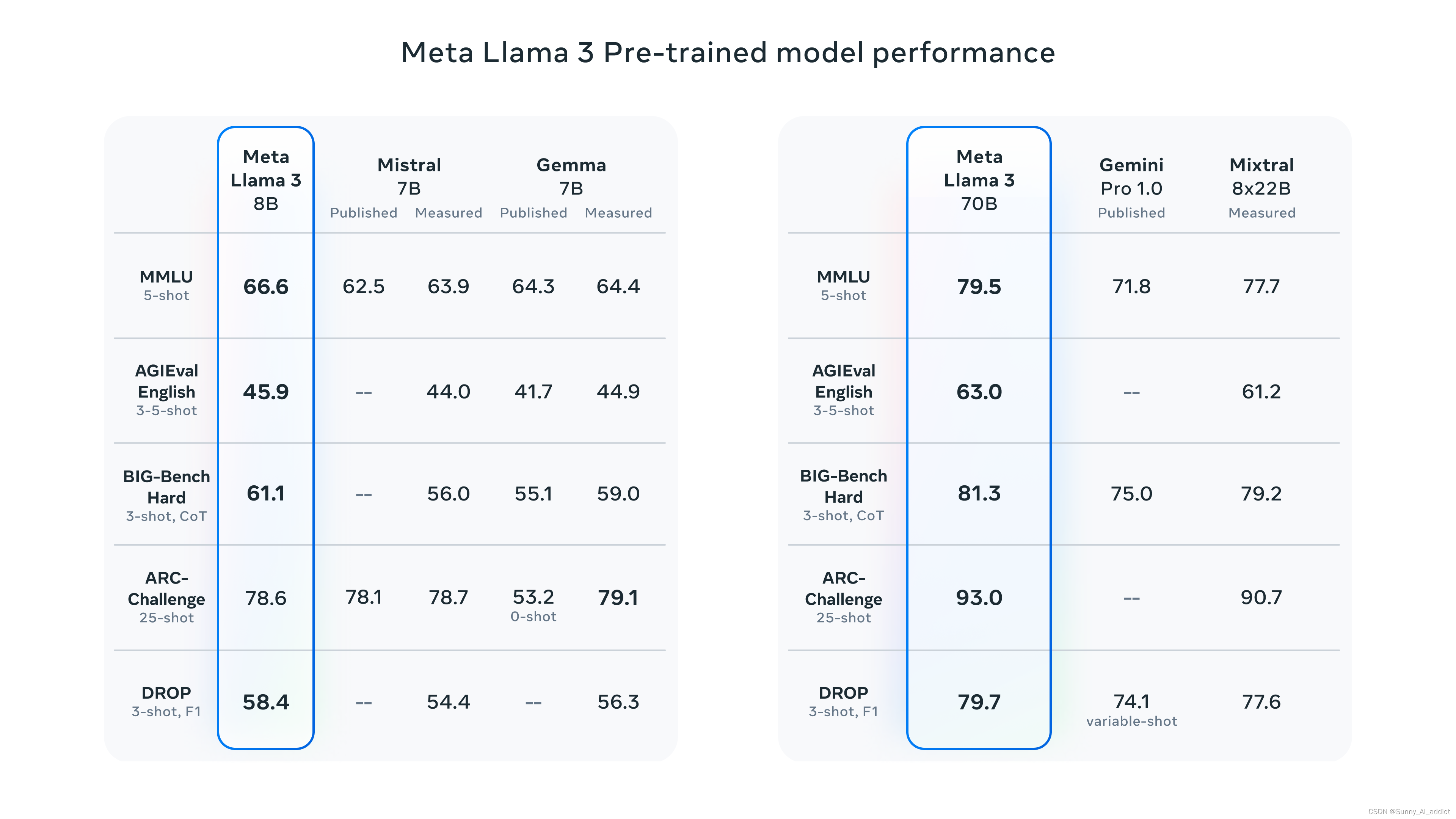
Post-training的改进大大降低了错误拒绝率,改善了一致性,增加了模型响应的多样性;Llama 3在推理、代码生成和指令跟踪等功能上有极大的提升,具体看一下对比数据:
(Llama 3 Pretrained模型)
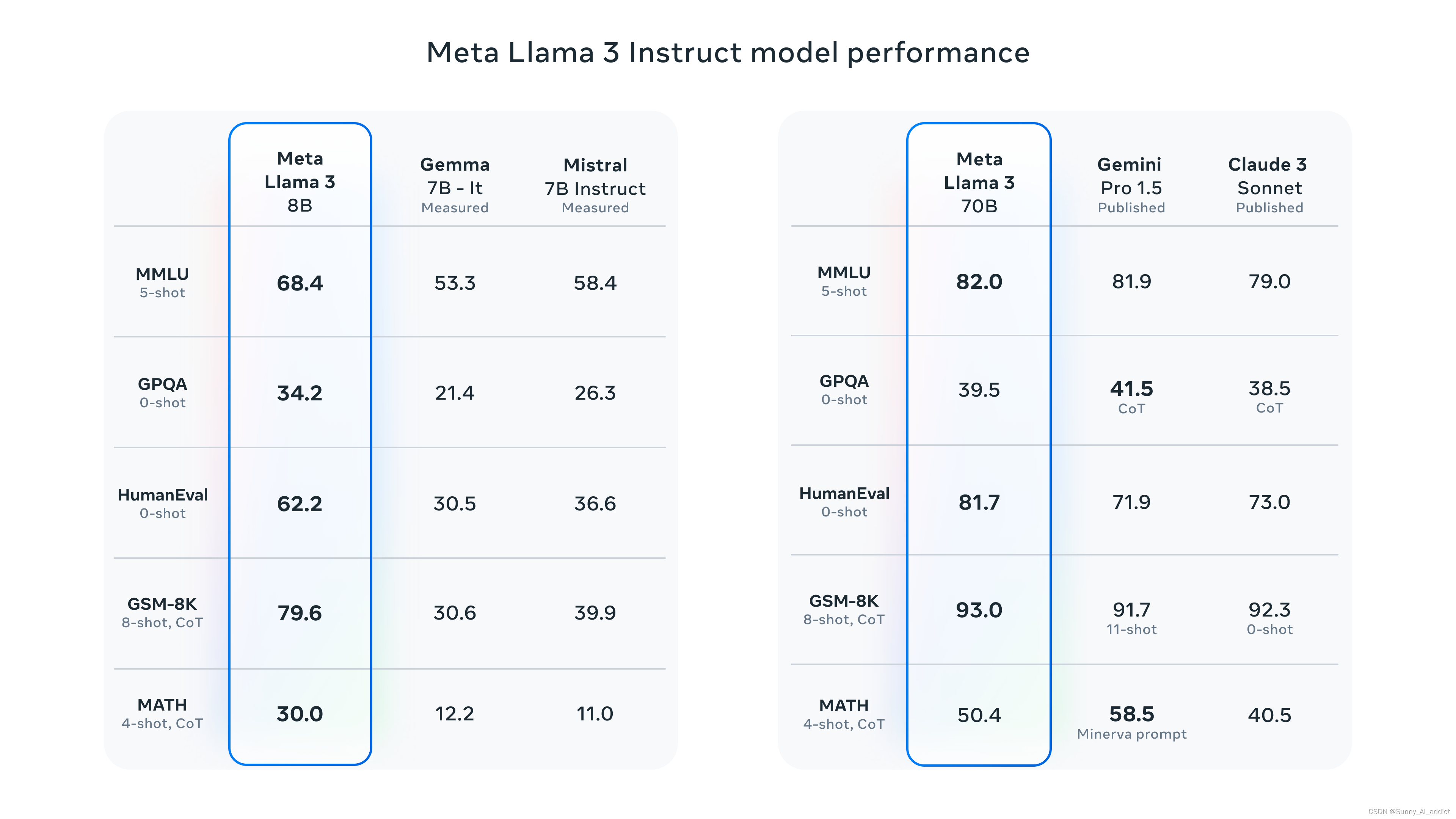
(Llama 3 Instruct模型)
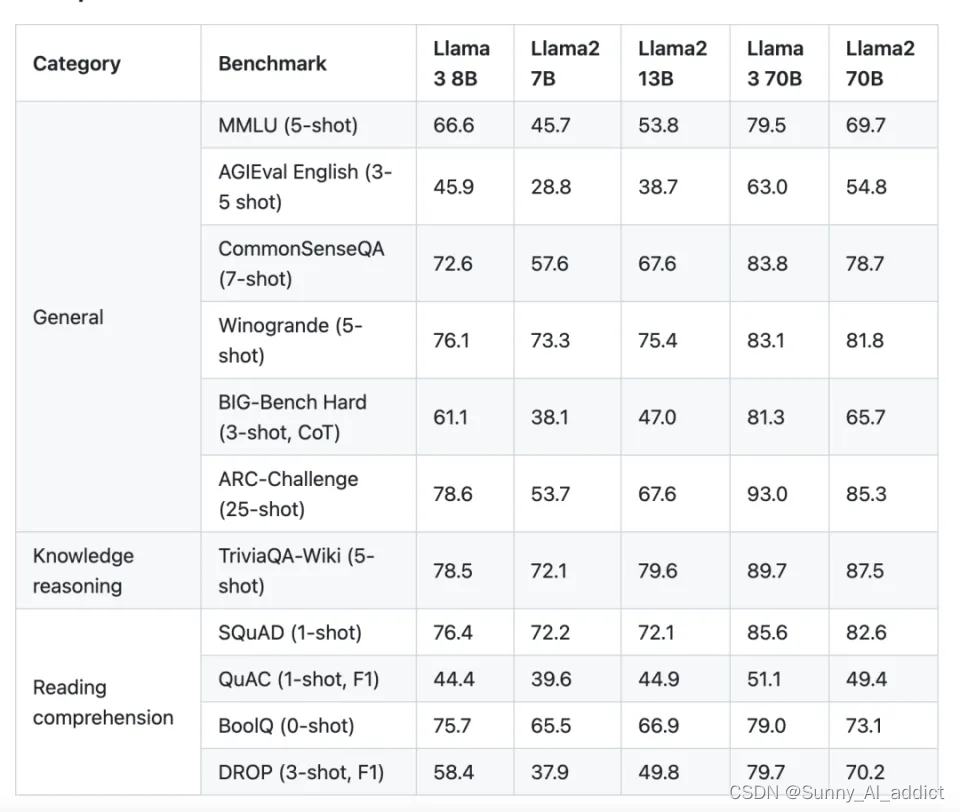
(这里再附一张 Llama 2 和 3 的对比)
2.2 人类偏好测试
在Llama 3的开发过程中,为了优化实际场景的性能,Meta开发了一个新的高质量的人类评价集。这个评估集包含1800个提示,涵盖了12个关键用例:征求建议、头脑风暴、分类、封闭式问题回答、编码、创造性写作、提取、作为一个角色/角色中、开放式问题回答、推理、重写和总结。
下面的图表显示了模型对这些类别的人类评估的汇总结果:
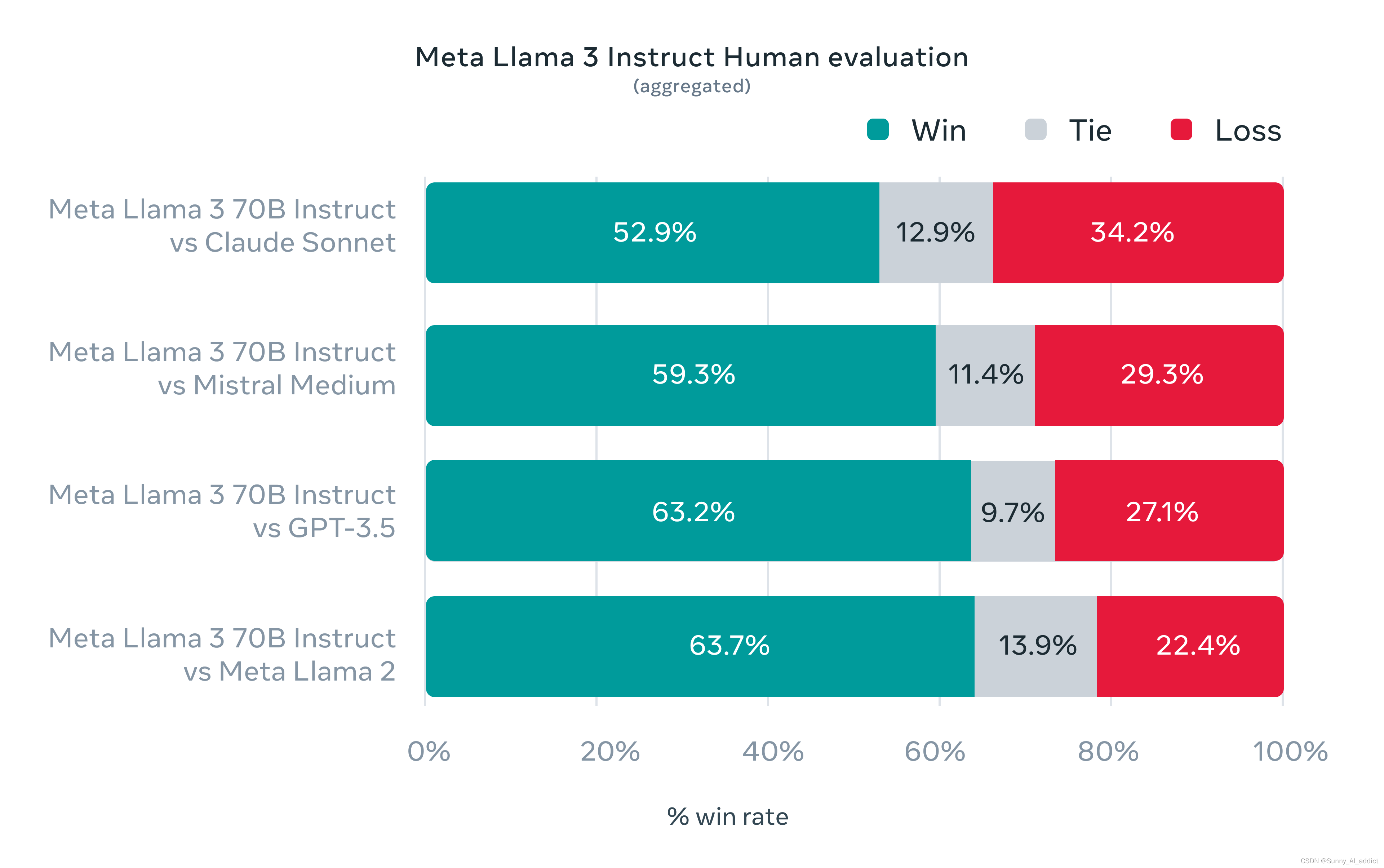
根据人类评估者的偏好排名,Llama 的 70B 参数模型在实际应用场景中的表现,尤其是在指令跟随方面,相较于其他相当规模的模型表现出了显著的优势。
三、优化之处
3.1 模型架构
3.1.1 Tokenzier
分词器:与Llama 2不同的是,Llama 3将tokenizer由sentencepiece换成tiktoken,词汇量从 的32K增加到 128K,增加了 4 倍 (更大的词汇库能够更高效地编码文本,增加编码效率,可以实现更好的下游性能。不过这也会导致嵌入层的输入和输出矩阵尺寸增大,模型参数量也会增大)。
序列长度:输入上下文长度从 4096(Llama 2)增加到 8192。但相对于GPT-4 的 128K来说还是相当
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 20万+
20万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









