







前言
Yi-34B大模型,相关的类型还有LLaMA2-70B和Falcon-180B,此文章着重Yi-34B的CPU版本本地部署和使用,还有一些相关的部署和初步使用的问题解决。
一、相关下载
Yi-34B-Chat:(我使用的是这个,可以转换为GGUF,并且可以量化)
Yi-34B-Chat-4bits:(这个是量化完成的,不能转换为GGUF)
koboldcpp(运行模型的工具)
Releases · LostRuins/koboldcpp · GitHub
二、关于llama.cpp的操作
要在CPU上跑起来,需要注意两点,一是GGUF模型,二就是量化,llama.cpp的主要目标是能够在各种硬件上实现LLM(大型语言模型)推理,无论是本地还是云端,都只需最少的设置,并提供最先进的性能。提供1.5位、2位、3位、4位、5位、6位和8位整数量化,以加快推理速度并减少内存使用。
1.创建llama.cpp项目
#windows 10
#进入D盘
D:
#下载llama.cpp项目
git clone https://github.com/ggerganov/llama.cpp
#进入下载的文件夹
cd llama.cpp
#创建构建文件夹
mkdir build
2.下载编译工具
NET Framework 4.8 Developer Pack - CHS Language Pack(Visual Studio 2022需要4.6及以上.net版本)
下载 .NET Framework 4.8 Developer Pack - CHS Language Pack
Visual Studio 2022
创建基于网络的安装 - Visual Studio (Windows) | Microsoft Learn
CMake
3.下载llama.cpp
git clone https://github.com/ggerganov/llama.cpp.git
4.编译llama.cpp
打开CMAKE
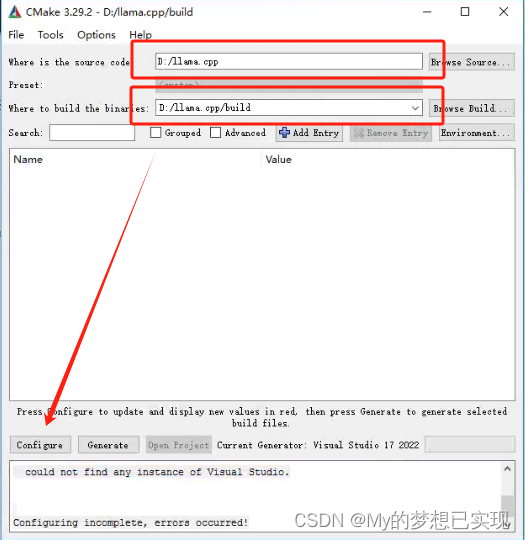
点击Configura,处理错误:
CMake Error at CMakeLists.txt:2 (project):
Generator
Visual Studio 17 2022
could not find any instance of Visual Studio.
Configuring incomplete, errors occurred!
解决:这是因为VS Studio的扩展没有安装上,需要MSBuild,Desktop C++

再次点击Configura

再点击Generate

再点击Open Project,并在VS里右边第一个选项上右键,点击生成
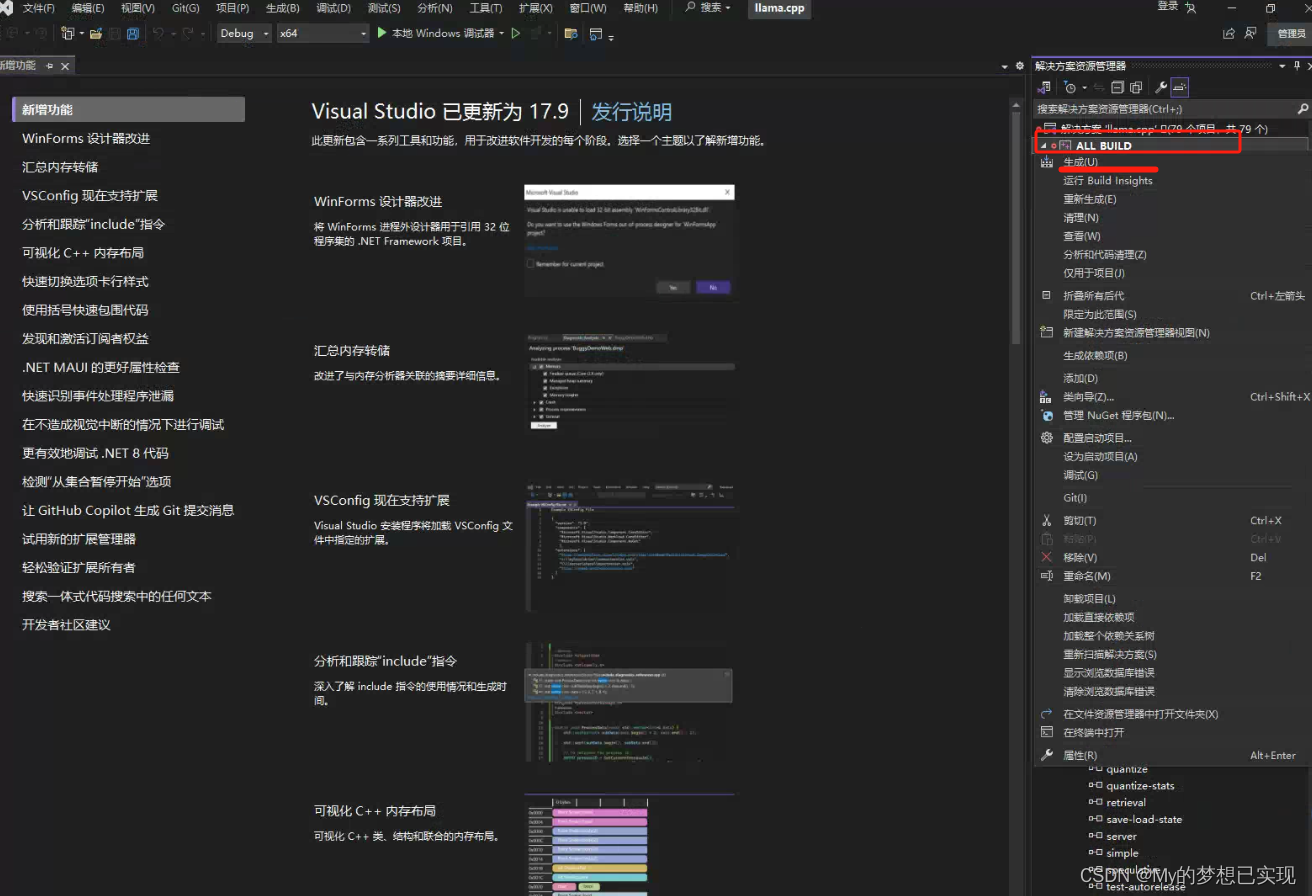
生成成功后,会存储在我们之前建立的build目录下

例如本项目的地址:D:\llama.cpp\build\bin

三、转换模型
转换模型会直接用llama.cpp项目中的convert.py量化会用到我们生成的quantize.exe。
1.安装虚拟环境
参考【AI开发:环境篇】Anaconda安装和基础命令-CSDN博客
2.创建一个虚拟环境来运行py文件
conda create --name llama python=3.9
3.激活环境
conda activate llama
4.安装llama.cpp相关环境
D:
cd llama.cpp
pip install -r requirements.txt
5.开始转换convert.py
#python .\convert.py 模型目录
python .\convert.py D:\BaiduNetdiskDownload\Yi-34B-Chat
6.试运行
模型的精度是F32,我的电脑是32G内存,测试了下,跑不动,我们打算做到4B的,准备的量化。
启动

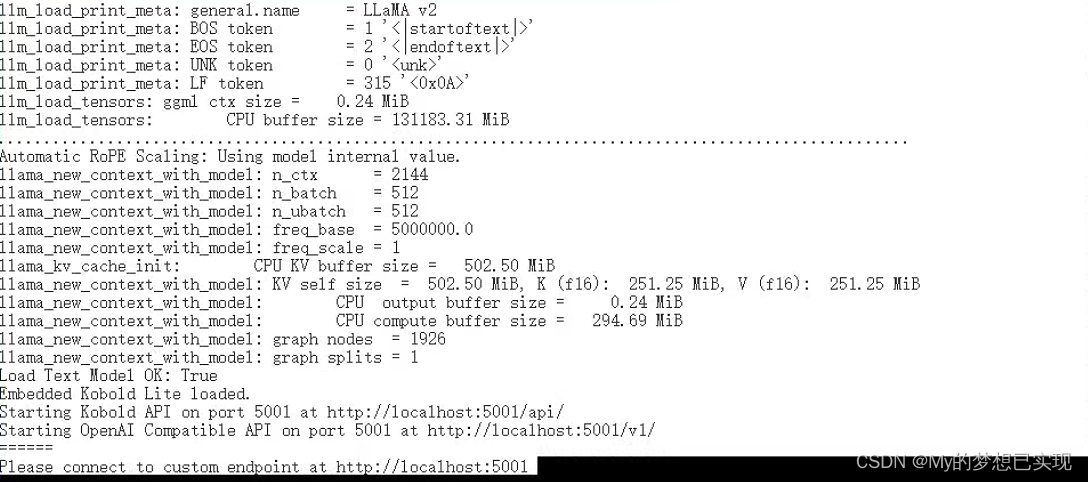
启动页面
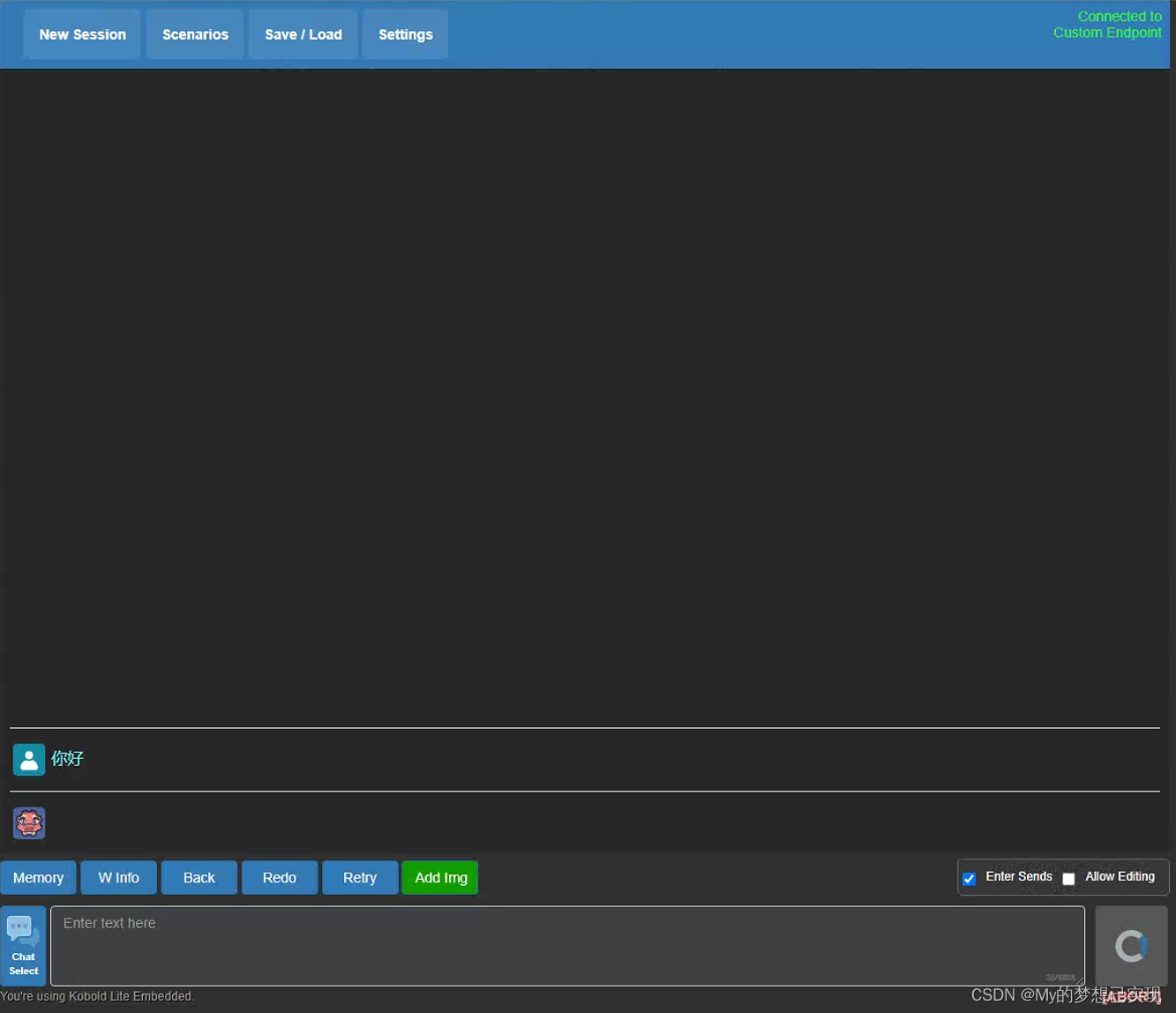
性能堪忧

发送一个 你好,电脑就要爆炸了的感觉,等了30分钟都没给我回复。干脆也就不浪费时间了,结束进程,准备量化。

7.量化模型
当然精度越高,效果越好,但是目前我们的测试机 是跑不动那么大的模型的。所以我们先用8位的来进行测试。
#quantize.exe gguf文件 目标Q4_0.gguf Q8_0
#quantize.exe 量化工具
#gguf文件 要量化的模型
#目标Q4_0.gguf 自定义量化后文件名
#Q8_0 8位 Q4_0 4位 Q16_0 16位
D:
cd D:\llama.cpp\build\bin\Debug
./quantize.exe D:\BaiduNetdiskDownload\Yi-34B-Chat\ggml-model-f32.gguf D:\BaiduNetdiskDownload\Yi-34B-Chat\ggml-model-Q8_0.gguf Q8_0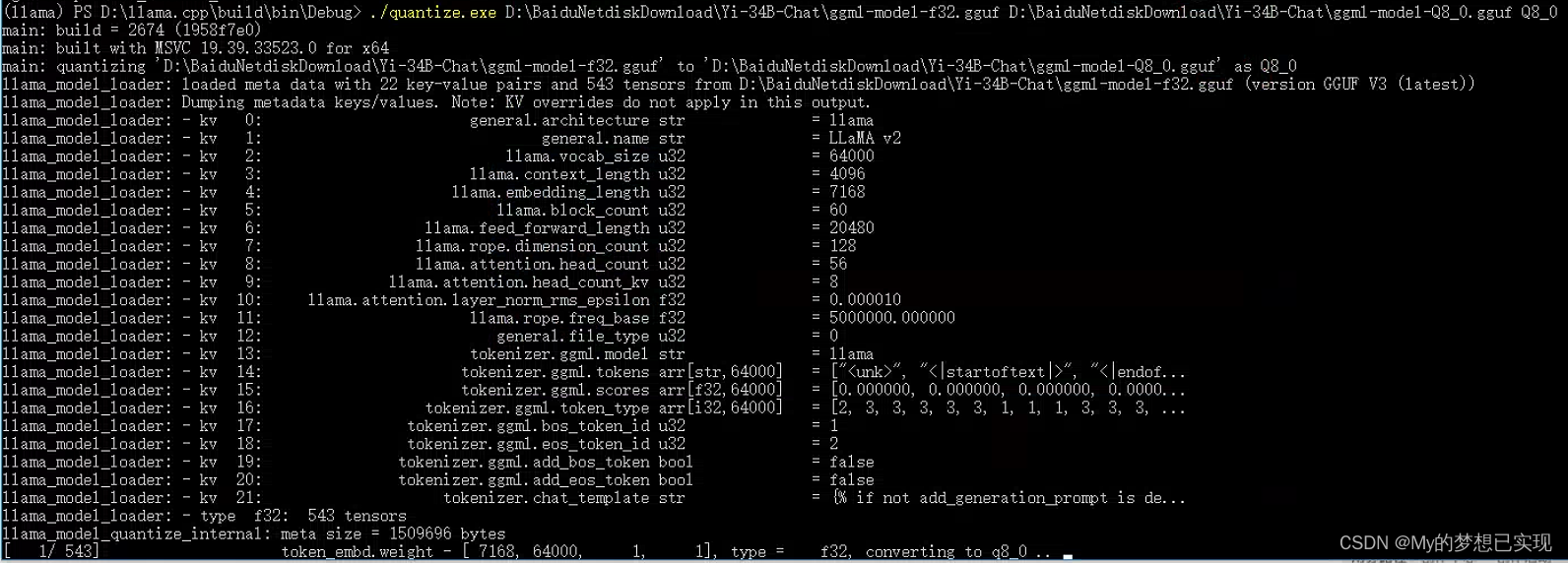

四、运行4位
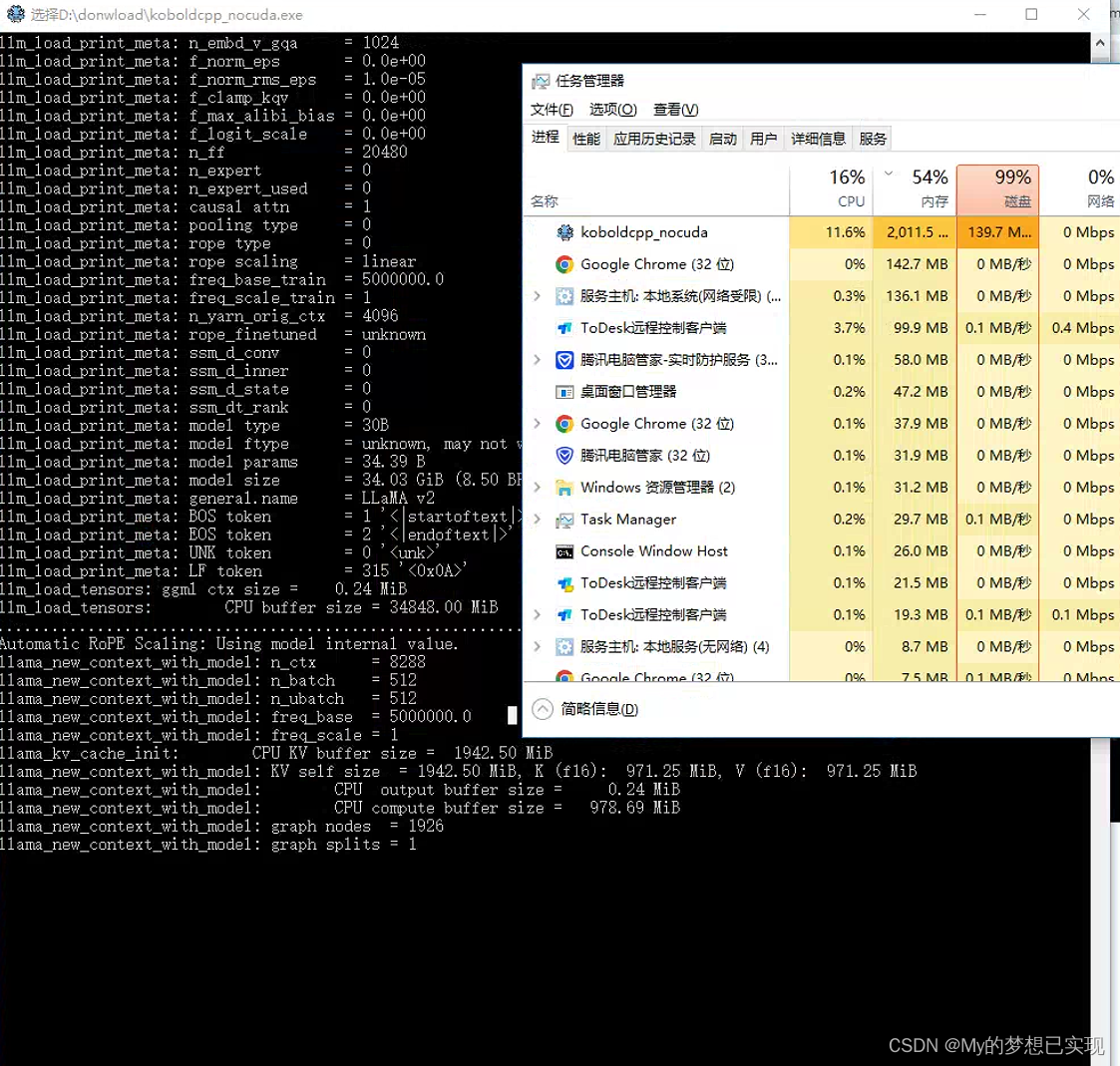
我承认,我肤浅了,没跑起来。。。还是阻塞,切换4位吧。
终于跑起来了哦!但是 CPU的反应真的是慢啊。

五、在GPU上运行4位
测试电脑,8核32G,1060 16g显卡,配置略低。
只需要拷贝 KoboldCpp.exe(注意和noCUDA的区别)还有模型文件ggml-model-Q4_0.gguf
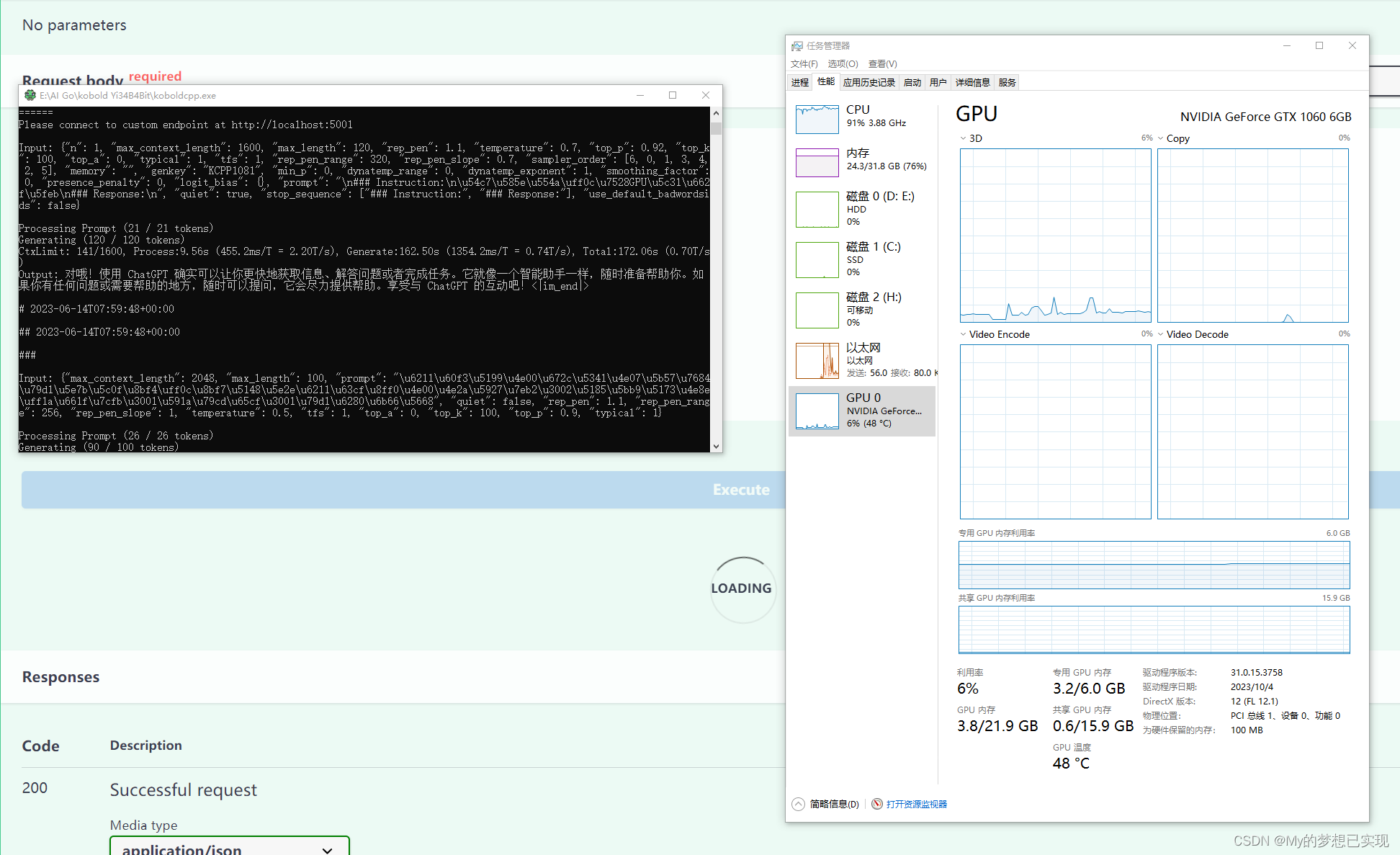
虽然配置略低,但是速度已经有了很大的提升,真是不错呢。
六、KoboldCpp的API接口
好在KoboldCpp提供API接口,我们可以通过接口进行二次开发,这里运行的模型就可以作为一台小型服务器了。
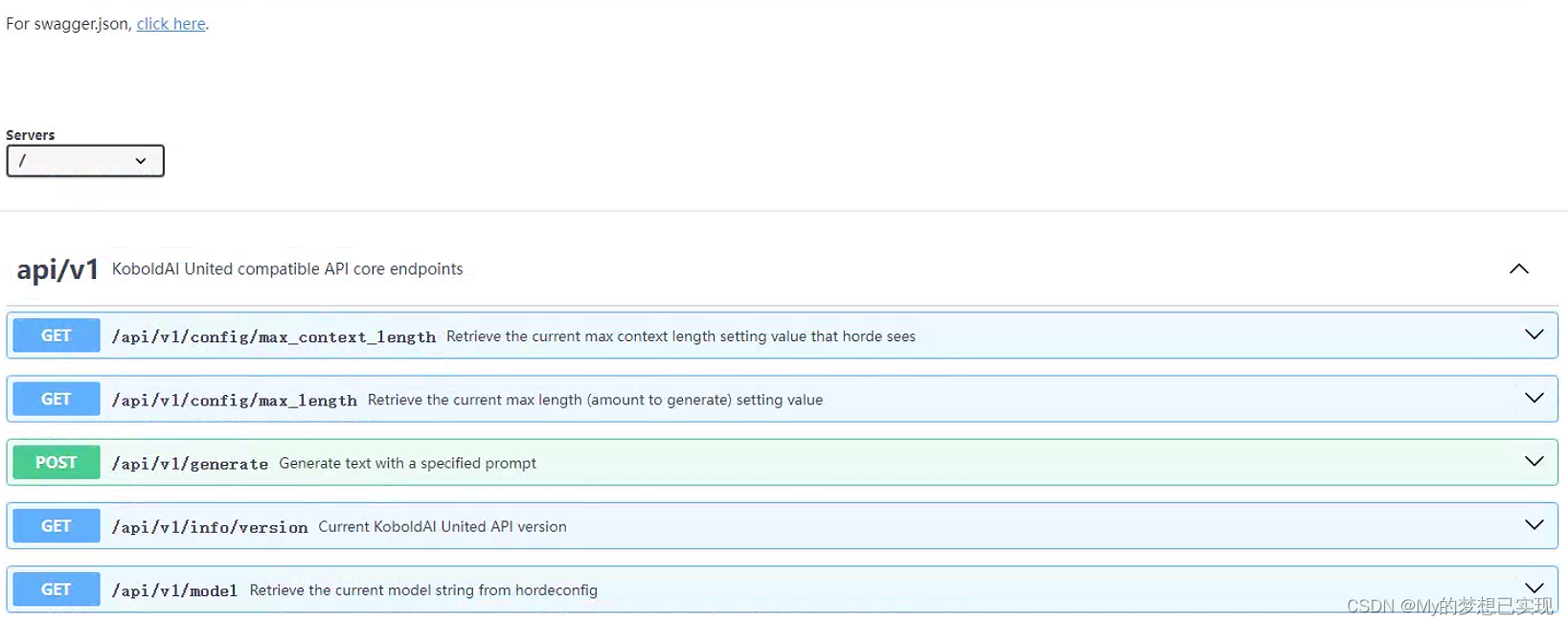

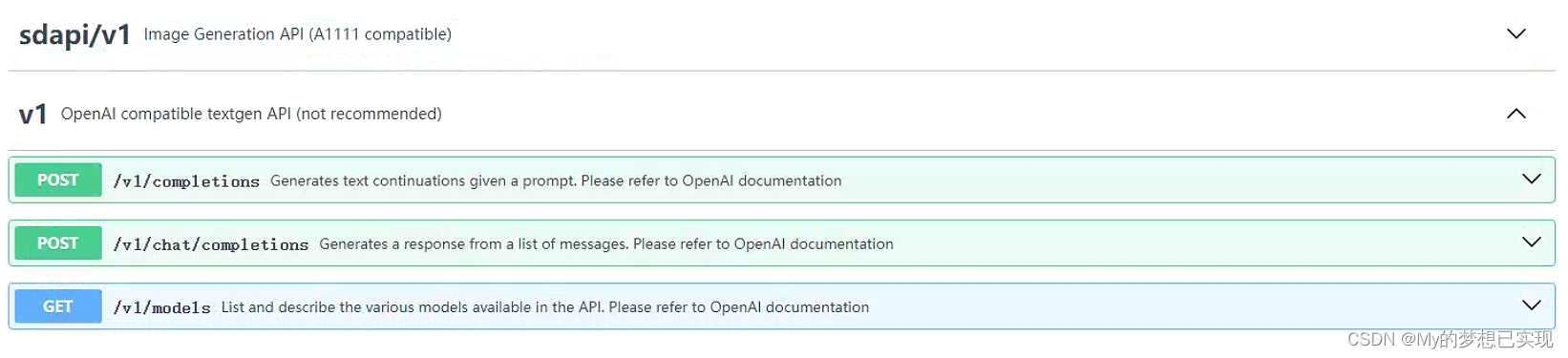
七、关于KoboldCpp的配置说明

-
Vulkan: Vulkan是一个由Khronos Group开发的低开销、跨平台的2D和3D图形API,它也提供了计算着色器功能,可以用于执行通用的GPU加速计算任务。在KoboldCpp中,Vulkan可以作为一种后端技术,用于加速文本生成过程中的计算密集型任务。使用Vulkan可以提高程序的运行速度,尤其是在具有兼容Vulkan的GPU的系统上。
-
CLBlast: CLBlast是一个开源的、针对OpenCL优化的BLAS(基础线性代数子程序)库。BLAS库提供了一系列标准的低级线性代数操作,如矩阵乘法、向量加法等,这些操作是许多科学计算和机器学习算法的基础。CLBlast专门针对OpenCL平台进行了优化,以提高在各种设备上的性能,包括GPU、CPU等。在KoboldCpp中,启用CLBlast可以利用这个库的优化,从而加速文本生成过程中的计算任务。
-
Cublas: Cublas是NVIDIA提供的一个库,它提供了针对其GPU的优化BLAS实现。Cublas同样提供了一系列标准的线性代数操作,但与CLBlast不同,Cublas是专门为NVIDIA的CUDA平台设计的。这意味着,如果你有一个NVIDIA的GPU,使用Cublas可以显著提高计算性能。然而,Cublas是闭源的,并且只能在NVIDIA的硬件上运行。
这个参数大概就是上面所述,根据你自己的设备性能来进行调整,其他设置就是字面意思了。















 2011
2011











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











