






目录
•Kaggle,https://www.kaggle.com/
•阿里云天池,https://tianchi.aliyun.com/
•百度AI, AI算法大赛 - 百度AI Studio - 人工智能学习与实训社区
•DataFountain,https://www.datafountain.cn/
•和鲸HeyWhale https://www.kesci.com/home/competition
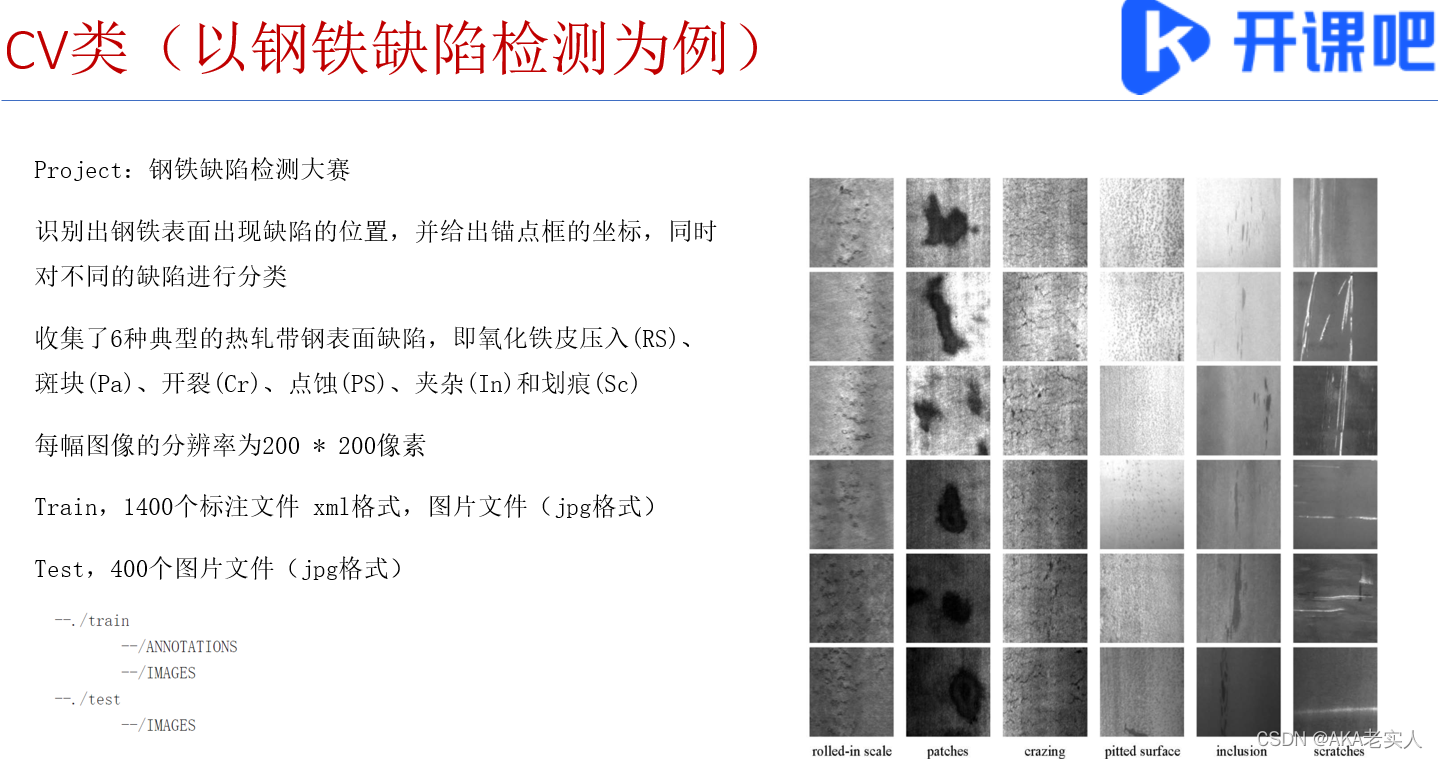
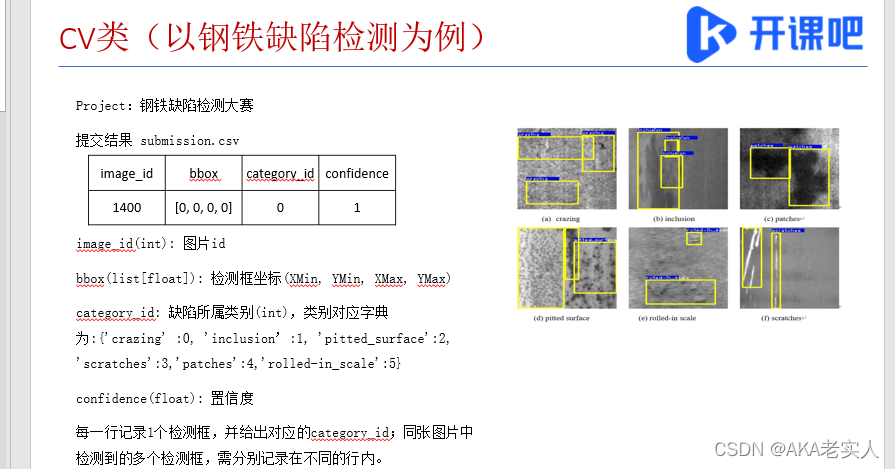
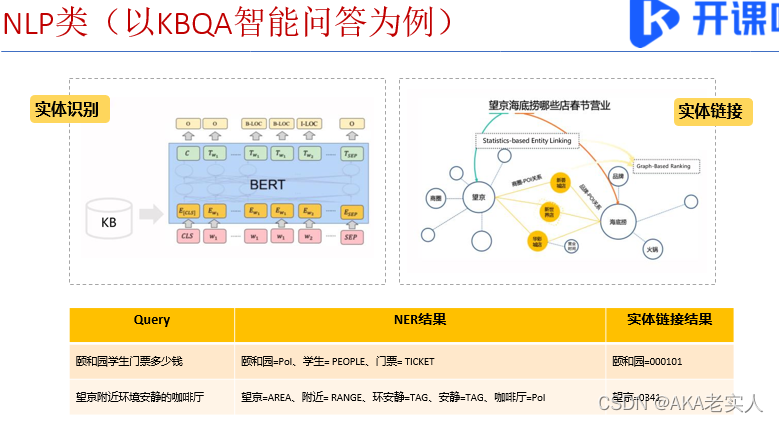
第一节:ai大赛概况 个贷违约预测
一.机器学习模型
——10大经典模型
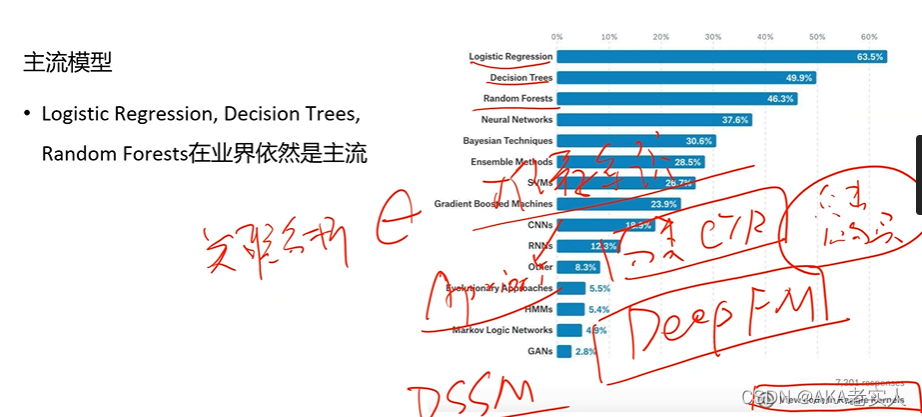
机器学习包:sklearn CGB catboost 
二.常见比赛分类
•Kaggle,https://www.kaggle.com/
全球最大的数据科学社区,常见有4种比赛:
1)Getting Started, 对新手友好,比如Titanic
2)Playground,趣味性为主
比Getting Started难,对新手较友好
3)Research, 实验性为主
比如Google Landmark Recognition Challenge, Google Landmark Recognition Challenge | Kaggle,
世界上最大的地标识别数据集“Google Landmarks”,检索比赛可以发表CVPR的workshop
Research比赛:Hacking the Kidney
Identify glomeruli in human kidney tissue images
在人体肾脏组织图像中识别肾小球
https://www.kaggle.com/c/hubmap-kidney-segmentation/overview
和人类基因组计划一样,人类生物分子图谱计划(HuBMAP)也是一项重大计划,首先以单细胞分辨率来绘制人类肾脏图谱,比赛的目的是来识别肾小球
4)Featured, 难度较高
大部分为企业或政府的需求,实用性及商业属性强
Jane Street Market Prediction,https://www.kaggle.com/c/jane-street-market-prediction
量化交易允许在几分之一秒内进行数千次交易,导致有几乎无限的获利的机会,Jane Street是一个量化交易机构,开发了很多交易模型并获利,量化交易模型是他们的日常工作。
Jane Street希望能通过举办Kaggle比赛看到新的创新方法来解决量化交易问题
•阿里云天池,https://tianchi.aliyun.com/
和Kaggle类似,新人友好 + 商业比赛
让选手用算法解决业务问题
•百度AI, AI算法大赛 - 百度AI Studio - 人工智能学习与实训社区
深度学习需要使用Paddle paddle 提供v100 gpu
•DataFountain,https://www.datafountain.cn/
CCF有很多比赛会放到上面
•和鲸HeyWhale https://www.kesci.com/home/competition
模型算法能力
1)机器学习
2)深度学习
3)启发式算法
业务理解能力
很多比赛都是需求方提出来的(政府、企业),比如天池上政府举办的比赛(广东工业制造大数据创新大赛)
解决方案的积累
工作中很多时候,在和数据质量打交道
比赛数据相对规整,更容易看到结果

反内卷 2333333333333

金融>汽车
三.步骤
xgboost 、 ltgbm > lr catboost不容易过拟合
先把字段聚类--降维
- Step1,数据加载
- Step2,数据探索(缺失值,唯一值个数)
- Step3,特征工程
1)日期类型字段 日期类型字段 多尺度/diff 时间差
2)分类字段处理 分类字段处理:标签二值化 目标编码
3)是否构造新特征
查看唯一值个数
1)唯一值个数很少,比如为0
2)唯一值个数很多,比如为1000
Thinking:对于分类特征,怎么构造新特征对分类进行解释?可以将分类特征与Target进行交叉特征,比如mean, std, count
对不稳定的分类特征,进行合并
连续特征离散化
特征交叉组合
缺失值补全策略
分箱
=> TO DO Version2:LightGBM + TargetEncoding
- Step4,机器学习神器使用
XGBoost, LightGBM, CatBoost
- Step5,五折子模型融合
类别过多不做target-mean
和结果做一个交叉
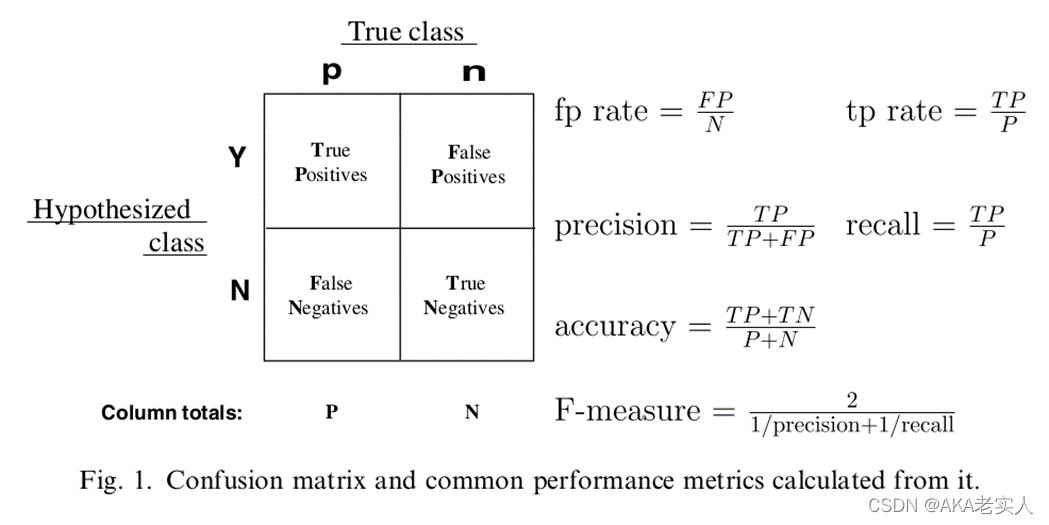
评测指标:
1.F1值
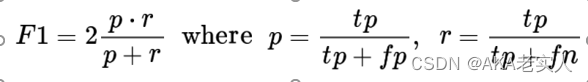
采用F1值,可以很好的平衡精确率和召回率
精确率 Precision:True Positive在all predicted positives的比例召回率 Recall:True Positive在all actual positives的比例
2.AUC
本次挑战的是经典的预测任务,以AUC作为衡量标准。
评测指标
使用ROC曲线下面积AUC(Area Under Curve)作为评价指标。AUC值越大,预测越准确。
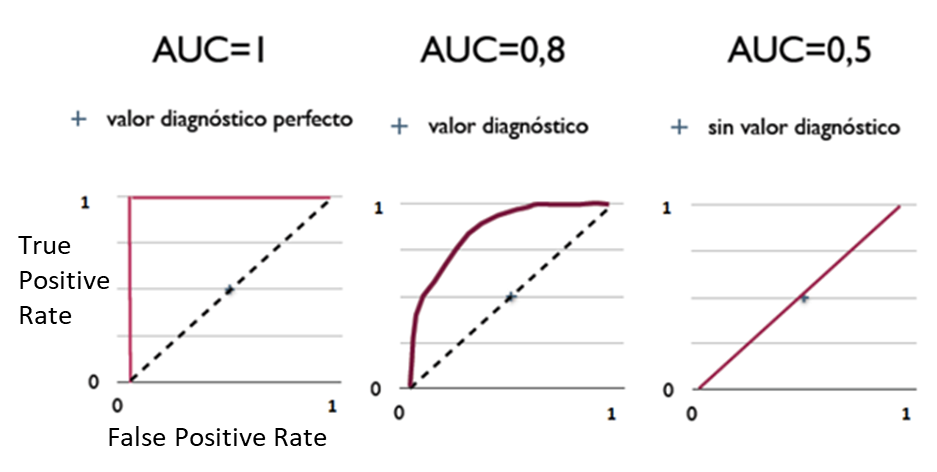
AUC值范围为[0,1],AUC值越高,表示二分类的预测结果越令人满意。
AUC = 1 时,表明在任何分类阈值下,分类结果都正阳性。
AUC = 0.5 时,表明分类结果为完全随机。
AUC < 0.5 时,表明分类结果弱于随机结果。
对算法工作的思考:
1)掌握常用的分类模型 => 搭建Baseline
2)能使用特征工程 => 提升Baseline
构造新特征,特征组合,特征分段等
3)尝试多元数据,更大样本量的其他任务
=> 提升Baseline
这里会遇到很多挑战,比如多元数据是属于其他任务,和本任务的相关性不如其原始数据高
原始数据的数据量少,容易导致特征分段不稳定
Level1:常见分类模型
分类算法:LR,Decision Tree,Naive Bayes,SVM,KNN
树模型:RandomForest, AdaBoost, GBDT,XGBoost,LightGBM,CatBoost,NGBoost
神经网络:MLP,LSTM
选手可以自行选择多种模型进行分类训练
Gradient Boosting集成学习:
XGBoost, LightGBM, CatBoost, NGBoost实际上是对GBDT方法的不同实现,针对同一目标、做了不同的优化处理
Baseline基线模型调优:
四.机器学习神器
金融科技领域:
机器学习使用较多,比如XGBoost, LightGBM等,注重特征的可解释性
评分卡模型是模型可解释性的重要工具之一
如果AUC没有达到预期,或者存在一定不好找的规律 => 可能缺失某些重要特征,比如 salary 或者 salary_grade
神经网络用于NLP,CV,推荐系统领域较多
比如 NER命名实体识别,票据印章识别等
NLP常用模型:TFIDF+XGBoost, LSTM, BERT
CV常用模型:ResNet, Yolo, Faster-RCNN
推荐系统模型:Wide & Deep, DeepFM
GBDT的三种工程实现版本:
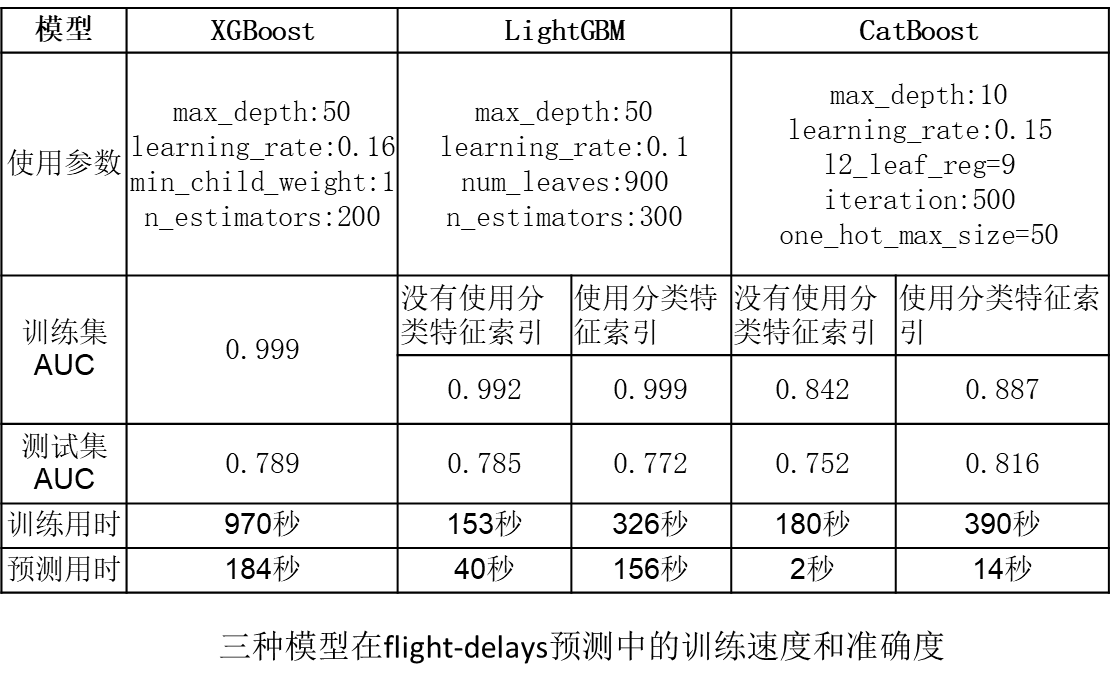
1.常用机器学习神器 LightGBM
LightGBM与XGBoost:
- 模型精度:两个模型相当
- 训练速度:LightGBM训练速度更快 => 1/10
- 内存消耗:LightGBM占用内存更小 => 1/6
- 特征缺失值:两个模型都可以自动处理特征缺失值
- 分类特征:XGBoost不支持类别特征,需要对其进行OneHot编码,而LightGBM支持分类特征
LGBMClassifier经验参数
import lightgbm as lgb
model_lgb = lgb.LGBMClassifier(
num_leaves=2**5-1, reg_alpha=0.25, reg_lambda=0.25, objective='binary',
max_depth=-1, learning_rate=0.005, min_child_samples=3, random_state=2022,
n_estimators=2000, subsample=1, colsample_bytree=1,
)
import lightgbm as lgb
model_lgb = lgb.LGBMClassifier(n_estimators=500)
model_lgb.fit(train.drop(['is_default'],axis=1),train['is_default'])
y_pred = model_lgb.predict_proba(test)
y_pred
num_leavel=2**5-1 #树的最大叶子数,对比XGBoost一般为2^(max_depth)
- reg_alpha,L1正则化系数
- reg_lambda,L2正则化系数
- max_depth,最大树的深度
- n_estimators,树的个数,相当于训练的轮数
- subsample,训练样本采样率(行采样)
- colsample_bytree,训练特征采样率(列采样)
LightGBM工具:
- import lightgbm as lgb
- 官方文档:http://lightgbm.readthedocs.io/en/latest/Python-Intro.html
参数:
- boosting_type,训练方式,gbdt
- objective,目标函数,可以是binary,regression,multiclass
- metric,评估指标,可以选择auc, mae,mse,binary_logloss,multi_logloss
- max_depth,树的最大深度,当模型过拟合时,可以降低 max_depth
- min_data_in_leaf,叶子节点最小记录数,默认20
Bagging参数:bagging_fraction+bagging_freq(需要同时设置)
•bagging_fraction,每次迭代时用的数据比例,用于加快训练速度和减小过拟合
•bagging_freq:bagging的次数。默认为0,表示禁用bagging,非零值表示执行k次bagging,可以设置为3-5
•feature_fraction,设置在每次迭代中使用特征的比例,例如为0.8时,意味着在每次迭代中随机选择80%的参数来建树
•early_stopping_round,如果一次验证数据的一个度量在最近的round中没有提高,模型将停止训练
参数:
- lambda,正则化项,范围为0~1
- min_gain_to_split,描述分裂的最小 gain,控制树的有用的分裂
- max_cat_group,在 group 边界上找到分割点,当类别数量很多时,找分割点很容易过拟合时
- num_boost_round,迭代次数,通常 100+
- num_leaves,默认 31
- device,指定cpu 或者 gpu
- max_bin,表示 feature 将存入的 bin 的最大数量
- categorical_feature,如果 categorical_features = 0,1,2, 则列 0,1,2是 categorical 变量
- ignore_column,与 categorical_features 类似,只不过不是将特定的列视为categorical,而是完全忽略
LightGBM的Histogram算法:
- 替代XGBoost的预排序算法
- 思想是先连续的浮点特征值离散化成k个整数,同时构造一个宽度为k的直方图,即将连续特征值离散化到k个bins上(比如k=255)
- 当遍历一次数据后,直方图累积了需要的统计量,然后根据直方图的离散值,遍历寻找最优的分割点
- XGBoost需要遍历所有离散化的值,LightGBM只要遍历k个直方图的值
- 候选分裂点数量 = k-1
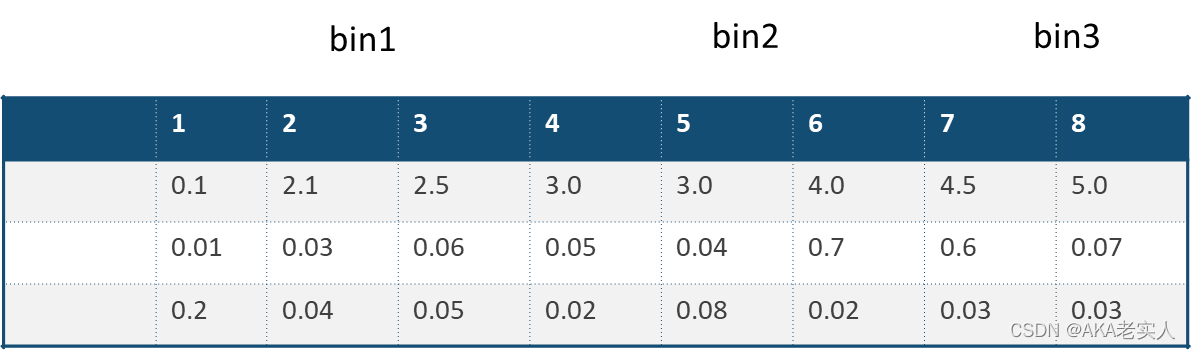

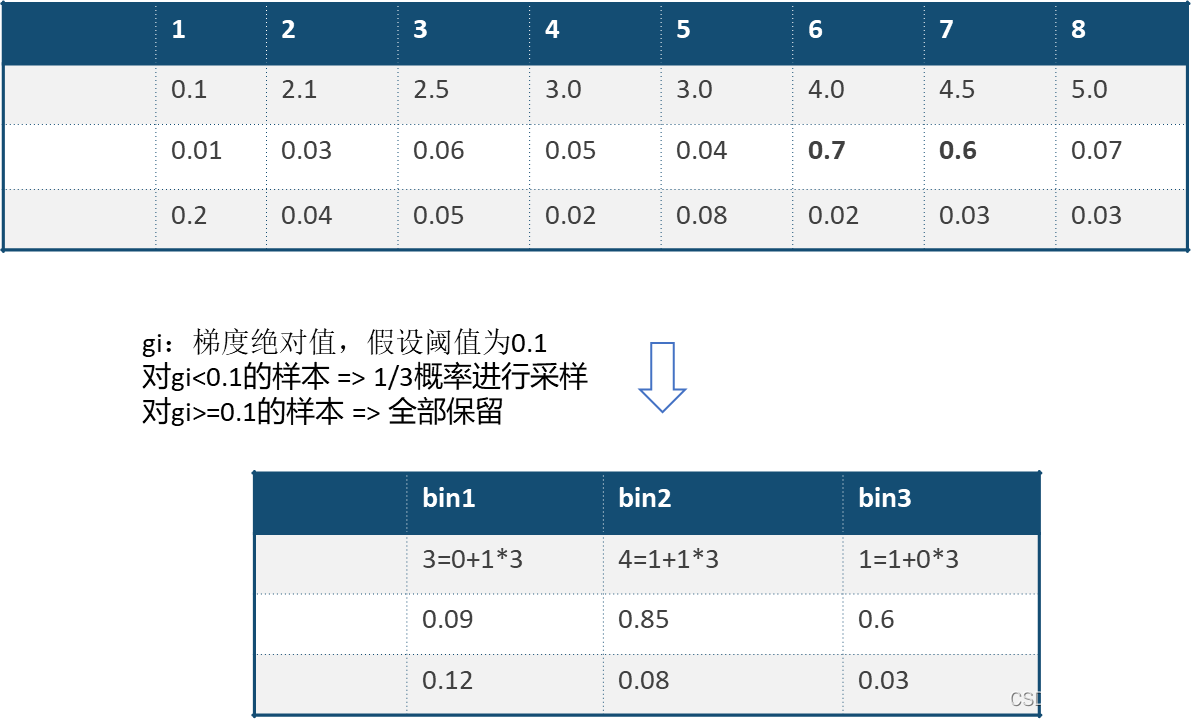
GOSS算法:
Gradient-based One-Side Sampling,基于梯度的单边采样算法
思想是通过样本采样,减少目标函数增益Gain的计算复杂度
单边采样,只对梯度绝对值较小的样本按照一定比例进行采样,而保留了梯度绝对值较大的样本
因为目标函数增益主要来自于梯度绝对值较大的样本 => GOSS算法在性能和精度之间进行了很好的trade off
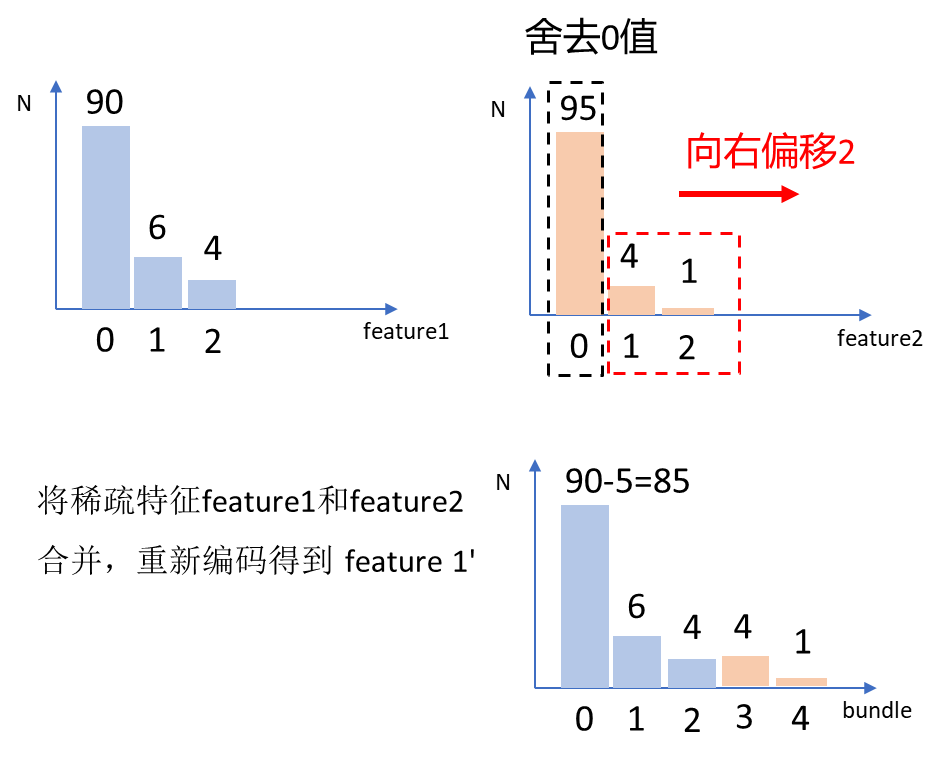
EFB算法:
Exclusive Feature Bundling,互斥特征绑定算法
- 思想是特征中包含大量稀疏特征的时候,减少构建直方图的特征数量,从而降低计算复杂度
- 数据集中通常会有大量的稀疏特征(大部分为0,少量为非0)我们认为这些稀疏特征是互斥的,即不会同时取非零值
- EFB算法可以通过对某些特征的取值重新编码,将多个这样互斥的特征绑定为一个新的特征
- 类别特征可以转换成onehot编码,这些多个特征的onehot编码是互斥的,可以使用EFB将他们绑定为一个特征
- 在LightGBM中,可以直接将每个类别取值和一个bin关联,从而自动地处理它们,也就无需预处理成onehot编码
2.常用机器学习神器 XGBoost
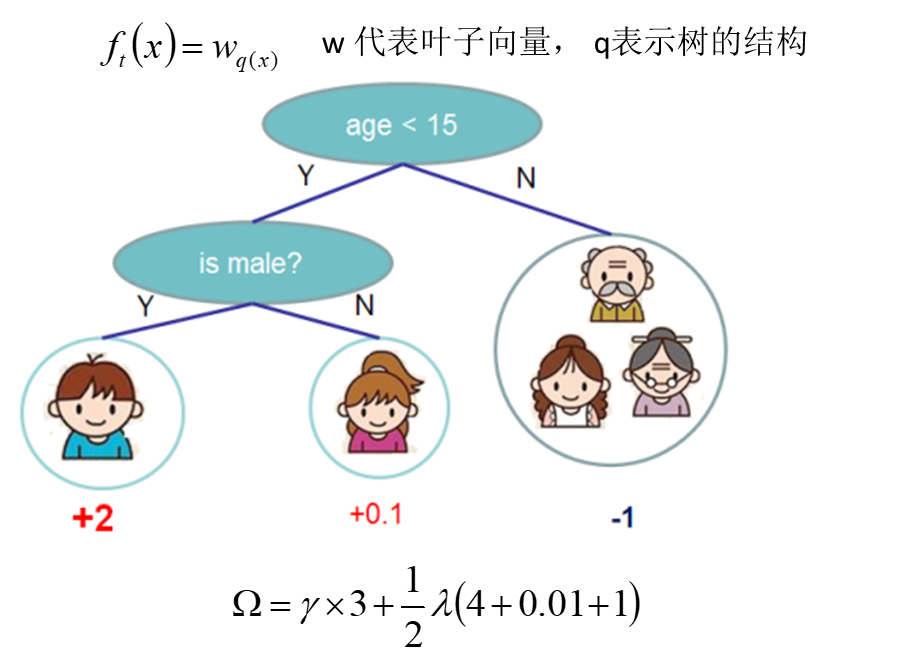
XGBoost:
目标函数=损失函数 + 正则化项

误差函数尽量拟合训练数据,正则化项鼓励简单的模型
![]() 用于控制树的复杂度,防止过拟合,使得模型更简化,也使得最终的模型的预测结果更稳定
用于控制树的复杂度,防止过拟合,使得模型更简化,也使得最终的模型的预测结果更稳定

XGBoost的分裂节点算法:
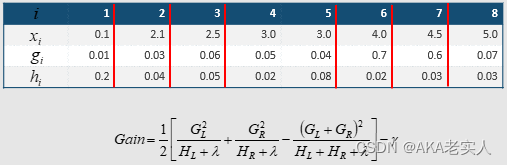
- 贪心方法,获取最优分割节点(split point)
将所有样本按照gi从小到大排序,通过遍历,查看每个节点是否需要分割
对于特征值的个数为n时,总共有n−1种划分
- Step1,对样本扫描一遍,得出GL,GR
- Step2,根据Gain的分数进行分割
- 通过贪心法,计算效率得到大幅提升,XGBoost重新定义划分属性,即Gain,而Gain的计算是由目标损失函数obj决定的

XGBoost的分裂节点算法(近似算法,Histogram 2016 paper):
- 对于连续型特征值,样本数量非常大,该特征取值过多时,遍历所有取值会花费很多时间,且容易过拟合
- 方法,在寻找split节点的时候,不会枚举所有的特征值,而会对特征值进行聚合统计,然后形成若干个bucket(桶),只将bucket边界上的特征值作为split节点的候选,从而获得性能提升
- 从算法伪代码中该流程还可以分为两种,全局的近似是在新生成一棵树之前就对各个特征计算分位点并划分样本,之后在每次分裂过程中都采用近似划分,而局部近似就是在具体的某一次分裂节点的过程中采用近似算法
XGBoost模型的复杂度:
- 模型复杂度 = 树的棵数 X 每棵树的叶子数量 X 每片叶子生成复杂度
- 每片叶子生成复杂度 = 特征数量 X 候选分裂点数量 X 样本的数量 针对XGBoost的优化:
- Histogram算法,直方图算法 => 减少候选分裂点数量
- GOSS算法,基于梯度的单边采样算法 => 减少样本的数量
- EFB算法,互斥特征捆绑算法 => 减少特征的数量
- LightGBM = XGBoost + Histogram + GOSS + EFB
XGBoost的预排序(pre-sorted)算法:
将样本按照特征取值排序,然后从全部特征取值中找到最优的分裂点位
预排序算法的候选分裂点数量=样本特征不同取值个数减1
XGBoost VS LightGBM
XGBoost效果相对LightGBM可能会好一些
import xgboost as xgb
model_xgb = xgb.XGBClassifier(
max_depth=6, learning_rate=0.05, n_estimators=2000,
objective='binary:logistic', tree_method='gpu_hist',
subsample=0.8, colsample_bytree=0.8,
min_child_samples=3, eval_metric='auc', reg_lambda=0.5
)
- max_depth ,树的最大深度
- learning_rate, 学习率
- reg_lambda,L2正则化系数
- n_estimators,树的个数,相当于训练的轮数
- objective,目标函数, binary:logistic 用于二分类任务 binary:logistic, multi:softmax
- tree_method, 使用功能的树的构建方法,hist代表使用直方图优化的近似贪婪算法
- subsample,训练样本采样率(行采样)
- colsample_bytree,训练特征采样率(列采样)
subsample, colsample_bytree是个值得调参的参数,
典型的取值为0.5-1(取0.7效果可能更好)
- n_estimatores:总共迭代的次数,即决策树的个数
- early_stopping_rounds:
含义:在验证集上,连续n次迭代,分数没有提高,就终止训练
调参:防止overfitting
- max_depth
含义:树的深度,默认值为6,典型值3-10
调参:值越大,越容易过拟合;值越小,越容易欠拟合
- min_child_weight
含义:默认值为1
调参:值越大,越容易欠拟合;值越小,越容易过拟合(值较大时,避免模型学习到局部的特殊样本)
- subsample
含义:训练每棵树时,使用的数据占全部训练集的比例。默认值为1,典型值为0.5-1
调参:防止overfitting
- colsample_bytree
含义:训练每棵树时,使用的特征占全部特征的比例。默认值为1,典型值为0.5-1
调参:防止overfitting
- learning_rate
含义:学习率,控制每次迭代更新权重时的步长,默认0.3
调参:值越小,训练越慢, 典型值为0.001-0.05
- objective 目标函数
回归任务:reg:linear (默认),reg:logistic
- 二分类:
binary:logistic 概率 ,binary:logitraw 类别
- 多分类
multi:softmax num_class=n 返回类别
multi:softprob num_class=n 返回概率
- eval_metric
- 回归任务(默认rmse):rmse--均方根误差,mae--平均绝对误差
- 分类任务(默认error)
auc--roc曲线下面积
error--错误率(二分类)
merror--错误率(多分类)
logloss--负对数似然函数(二分类)
mlogloss--负对数似然函数(多分类)
gamma,惩罚项系数,指定节点分裂所需的最小损失函数下降值
alpha,L1正则化系数,默认为1
lambda,L2正则化系数,默认为1
3.常用机器学习神器 CatBoost
from catboost import CatBoostClassifier
model_cb = cb.CatBoostClassifier(iterations=5000,
depth=7,
learning_rate=0.001,
loss_function='Logloss',
eval_metric='AUC',
logging_level='Verbose',
metric_period=50)
CatBoost算法:
- 俄罗斯科技公司Yandex开源的机器学习库(2017年)
- https://arxiv.org/pdf/1706.09516.pdf
- CatBoost = Catgorical + Boost
- 高效的处理分类特征(categorical features),首先对分类特征做统计,计算某个分类特征(category)出现的频率,然后加上超参数,生成新的数值型特征(numerical features)
- 同时使用组合类别特征,丰富了特征维度
- 采用的基模型是对称决策树,算法的参数少、支持分类变量,通过可以防止过拟合
4.特征重要性查看:
1.xgboost
特征重要性查看:
from xgboost import plot_importance
fig, ax = plt.subplots(figsize=(10,8))
plot_importance(model_xgb, max_num_features=20, ax=ax)
plt.show()
2.lightgbm
特征重要性查看:
from lightgbm import plot_importance
fig, ax = plt.subplots(figsize=(10,8))
plot_importance(model_lgb, max_num_features=20, ax=ax)
plt.show()
3.
Thinking:如果特征值很多,如何呈现更适合?
转换为DataFrame形式,方便后续对比和使用
feature_df = pd.DataFrame()
feature_df['feature_name'] = X_train.columns
feature_df['feature_importance'] = clf_ex.feature_importances_
feature_df = feature_df.sort_values('feature_importance',ascending = False)
feature_df
特征重要性查看:
import matplotlib.pyplot as plt
feature_df = pd.DataFrame(columns=['name', 'importance'])
feature_df['name'] = model_cb.feature_names_
feature_df['importance'] = model_cb.feature_importances_
feature_df.sort_values(by=['importance'], ascending=True, inplace=True)
plt.figure(figsize=(10, 10))
plt.barh(feature_df['name'], feature_df['importance'], height=0.5)
4.如何看到更细粒度的特征重要性排名?
比如 auto_model中的哪款车型
incident_severity中的哪个严重等级
Insured_hobbies中的哪个兴趣
联系机构中的哪个机构
# 将分类特征全部展开
all_data = pd.get_dummies(data)
5.AutoGluon使用:
- Step1,数据加载
- Step2,数据探索(缺失值,唯一值个数)
- Step3,使用AutoML工具(AutoGluon)
- 1.自动判断任务:'binary', 'multiclass', 'regression'
- 2.自动特征工程:自动处理表格数据的神经网络(将每个类型特征单独训练Embedding向量),连续特征处理
- 3.多模型融合:KNN, LightGBM, RandomForest, CatBoost, ExtraTrees等
- Step4,针对测试集进行预测
AutoGluon使用:
亚马逊开源的AutoML工具,使用15倍于单次训练的代价,得到调参结果比手调要好,适用于CV, NLP和Tabular表格
特点:无需数据清洗,自动进行特征工程、超参优化、模型选择
from autogluon.tabular import TabularPredictor
# 创建AutoML模型
model = TabularPredictor(label="target", path="model")
# 可以指定训练时长
model.fit(train, time_limit=300)
# 查看Leaderboard
model.leaderboard()
# AutoML预测
y_pred = model.predict(test)
1)使用表格神经网络
2)多模型融合
3)鲁棒的数据预处理
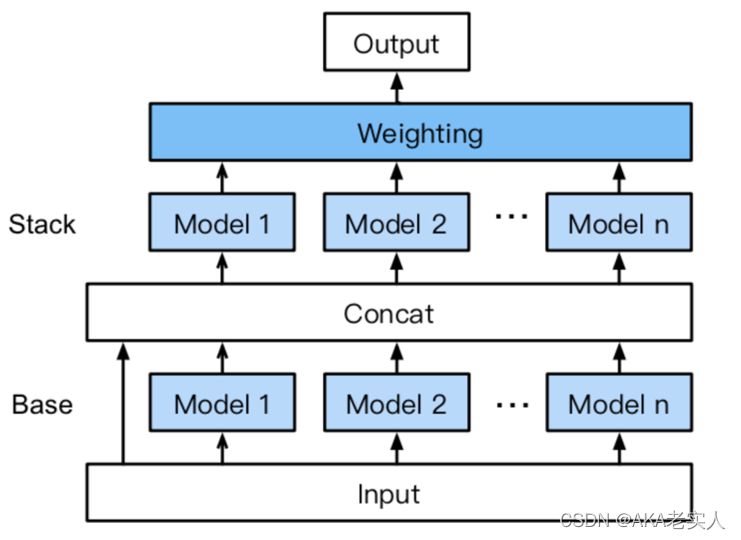
AutoGluon中的多模型融合
Stack Level 1:多模型的输出结果
Stack Level 2:通过WeightedEnsemble模型进行加权融合
查看不同模型的表现: model.leaderboard()
针对regression任务,默认metric为RMSE,从小到大进行排序
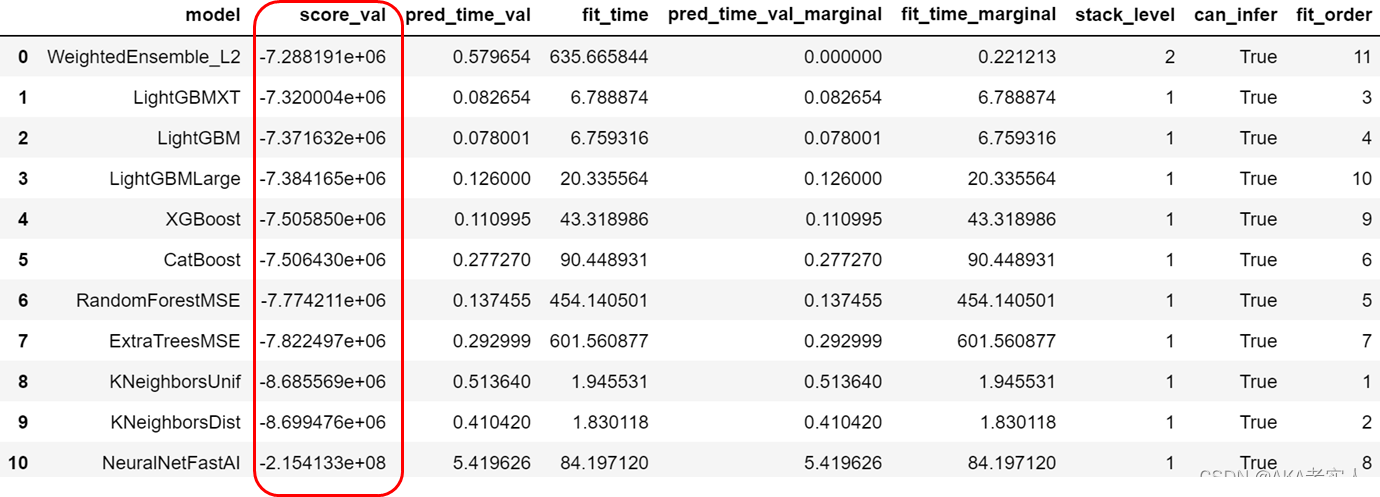
查看模型详细配置: model.fit_summary()
'model_hyperparams': {'KNeighborsUnif': {'weights':'uniform', 'n_jobs': -1},'KNeighborsDist': {'weights': 'distance', 'n_jobs': -1}, 'LightGBMXT': {'num_boost_round': 10000, 'num_threads': -1, 'learning_rate': 0.05, 'objective': 'regression', 'verbose': -1, 'boosting_type': 'gbdt', 'two_round': True, 'extra_trees': True}, 'LightGBM': {'num_boost_round': 10000, 'num_threads': -1, 'learning_rate': 0.05, 'objective': 'regression', 'verbose': -1, 'boosting_type': 'gbdt', 'two_round': True}, ……
AutoGluon的训练参数:
model = TabularPredictor(label, eval_metric=metric, path=save_path).fit(train_data, presets='best_quality')
6. DeepFM算法
TO DO Version3:使用DeepFM
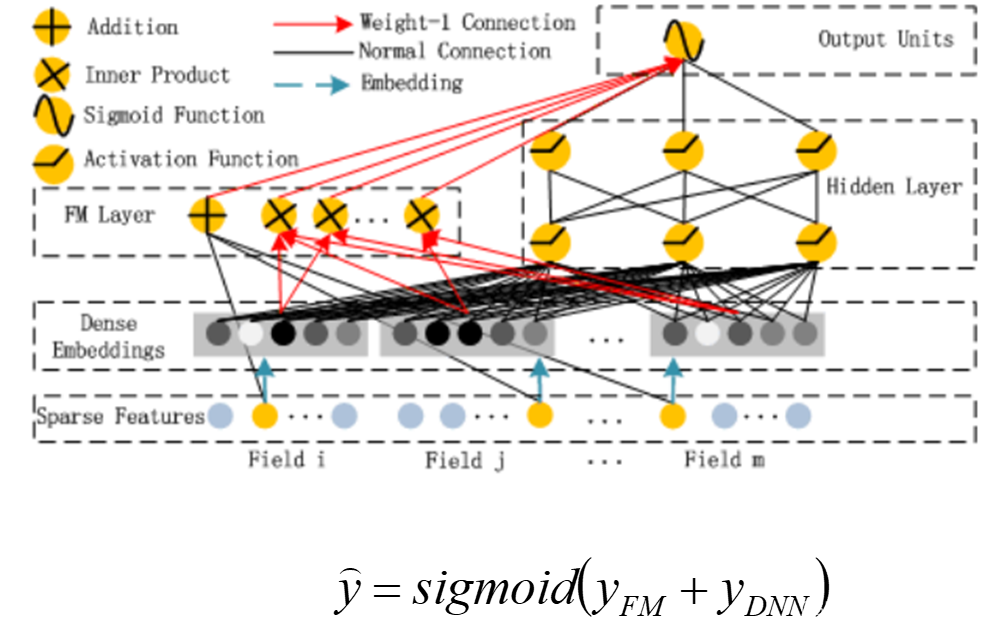
- DeepFM = FM + DNN:
- 提取低阶(low order)特征 => 因子分解机FM 既可以做1阶特征建模,也可以做2阶特征建模
- 提取高阶(high order)特征 => 神经网络DNN
- end-to-end,共享特征输入
- 对于特征i,wi是1阶特征的权重,
- Vi表示该特征与其他特征的交互影响,输入到FM模型中可以获得特征的2阶特征表示,输入到DNN模型得到高阶特征。
1)区分分类特征,数值特征
cat_columns = ['job', 'marital', 'education', 'default', 'housing',
'loan', 'contact', 'month', 'day_of_week', 'poutcome’]
num_columns = ['age', 'duration', 'campaign', 'pdays', 'previous',
'emp.var.rate', 'cons.price.idx', 'cons.conf.idx', 'euribor3m', 'nr.employed']
2)转换为DeepFM的特征表达
from deepctr.feature_column import SparseFeat,DenseFeat, get_feature_names
fixlen_feature_columns = [SparseFeat(feature, int(df[feature].max())+1, embedding_dim=8)
for feature in sparse_features] + [DenseFeat(feat, 1, ) for feat in dense_features]
linear_feature_columns = fixlen_feature_columns
dnn_feature_columns = fixlen_feature_columns
feature_names = get_feature_names(linear_feature_columns + dnn_feature_columns)
3)将训练集、测试集转换为deepfm的数据格式
train_model_input = {name:train2[name].values for name in feature_names}
test_model_input = {name:test2[name].values for name in feature_names}
4)使用DeepFM进行训练
model = DeepFM(linear_feature_columns, dnn_feature_columns, task='binary')
model.compile("adam", "binary_crossentropy", metrics=['accuracy', 'binary_crossentropy'], )
五.模型部署
To DO:以波士顿房价预测为例,部署一个在线服务
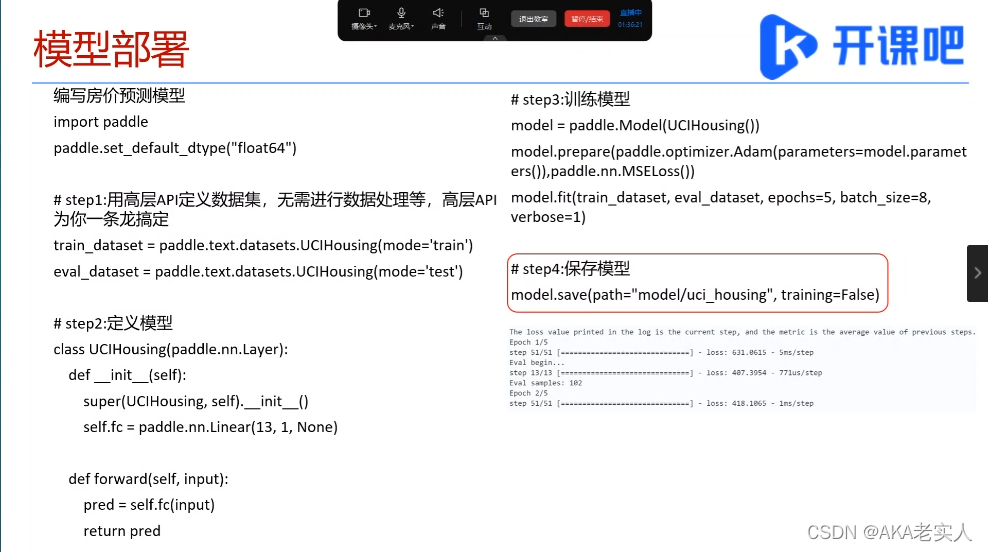
Step1,编写房价预测模型
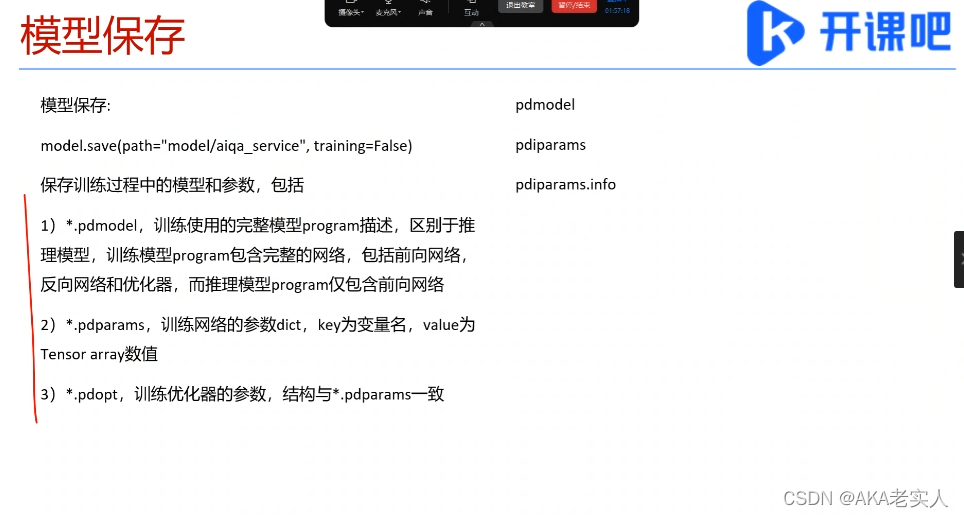
Step2,导出模型,使用model.save(path="model/uci_housing", training=False)
Step3,开始部署
1)点击部署按钮
2)选择保存好的模型

3)填写输入输出格式
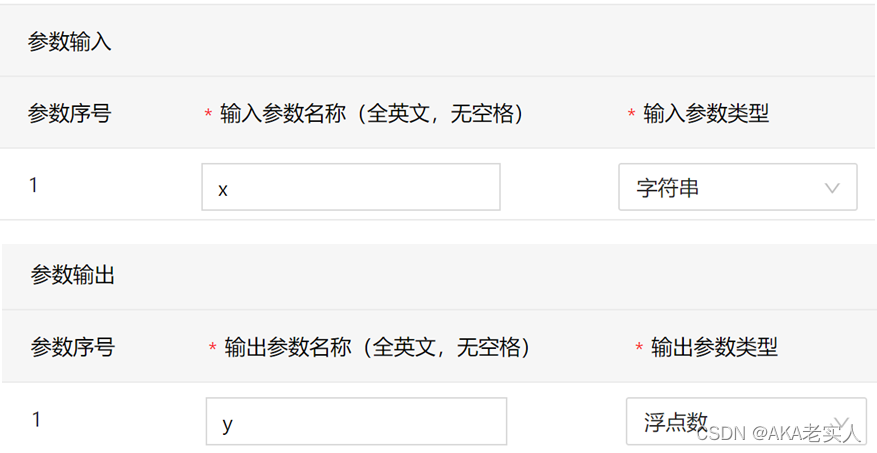
百度上用xgb超级快, lgb不行


第二节:心跳信号分类预测
一.细节
1.loss metrics
model.compile(loss='目标函数 ', optimizer='adam', metrics=['accuracy'])
常用metrics包括:accuracy, mae, mse
常用loss包括:
- mean_squared_error,即MSE
- mean_absolute_error, 即MAE
- mean_absolute_percentage_error,即mape
- binary_crossentropy 对数损失,即logloss
- categorical_crossentropy 多类的对数损失
2.内存压缩
运行容易发生内存溢出,可以对DataFrame大小进行压缩
1)针对int类型 => int8, int16, int32, int64
2)针对float类型 => float16, float32, float64
在转换之前需要确保格式正确,比如object类型,可能为float类型,需要先转换为float类型
for col in range(205):
train[col] = train[col].astype(float)
Thinking:如何查看DataFrame大小?
- 方法1:train.info()
- 方法2:train.memory_usage().sum() / 1024 / 1024
-
# 通过数据转换, 减小数据存储内存 def reduce_mem_usage(df): start_mem = df.memory_usage().sum() / 1024 / 1024 print('DataFrame内存占用{}M'.format(round(start_mem, 1))) # 对每个col进行压缩 for col in df.columns: col_type = df[col].dtype if col_type != object: c_min = df[col].min() c_max = df[col].max() if str(col_type)[:3] == 'int': if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max: df[col] = df[col].astype(np.int8) elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max: df[col] = df[col].astype(np.int16) elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max: df[col] = df[col].astype(np.int32) elif c_min > np.iinfo(np.int64).min and c_max < np.iinfo(np.int64).max: df[col] = df[col].astype(np.int64) else: if c_min > np.finfo(np.float16).min and c_max < np.finfo(np.float16).max: df[col] = df[col].astype(np.float16) elif c_min > np.finfo(np.float32).min and c_max < np.finfo(np.float32).max: df[col] = df[col].astype(np.float32) else: df[col] = df[col].astype(np.float64) else: df[col] = df[col].astype('category') end_mem = df.memory_usage().sum() / 1024 / 1024 print('压缩后内存占用: {}M'.format(round(end_mem, 1))) return df3.使用时序特征预测
- Step1,数据加载
- Step2,数据可视化
- Step3,特征抽取
-
时序数据特征提取 tsfresh
tsfresh是处理时间序列的关系数据库的特征工程工具,能自动从时间序列中提取100多个特征,这些特征描述了时间序列的基本特征,包括:峰数、平均值,最大最小,以及更复杂的特征,比如时间反转对称统计,并通过假设检验来将特征消减,即去相关性
我们可以在tsfresh构造的特征基础上进行建模 -
from tsfresh import extract_features extracted_features = extract_features(timeseries, column_id="id", column_sort="time") extract_features函数: extract_features(df, column_id='id', column_sort='time', default_fc_parameters = extraction_settings, impute_function=impute) 这里 extraction_settings 有多种模式: from tsfresh.feature_extraction import ComprehensiveFCParameters, EfficientFCParameters, MinimalFCParameters extraction_settings = ComprehensiveFCParameters() extraction_settings = EfficientFCParameters() extraction_settings = MinimalFCParameters() impute函数:过滤特征之前要先去除非数(NaN) select_features函数:选择与标签y相关性最高的特征 from tsfresh import select_features from tsfresh.utilities.dataframe_functions import impute impute(extracted_features) features_filtered = select_features(extracted_features, y) #extract_relevant_features函数:直接抽取相关特征 extract_relevant_features(df, y, column_id='id', column_sort='time',default_fc_parameters=extraction_settings)Thinking:tsfresh运行时间比较长,可能会因为memory不足导致失败,有什么方式可以有效执行特征提取?
- 方法1:全量样本,使用extract_relevant_features, 采用ComprehensiveFCParameters()
- 方法2:全量样本,使用extract_features,采用extraction_settings = MinimalFCParameters()
- 方法3:单个样本,按照ID进行遍历
- for index, data in enumerate(signals_df.groupby('id')):
- 方法4:小批量样本,每1000个样本执行一次extract_features,使用ComprehensiveFCParameters()
- Step4,特征选择
- Step5,建模
-
2.使用Keras实现
-
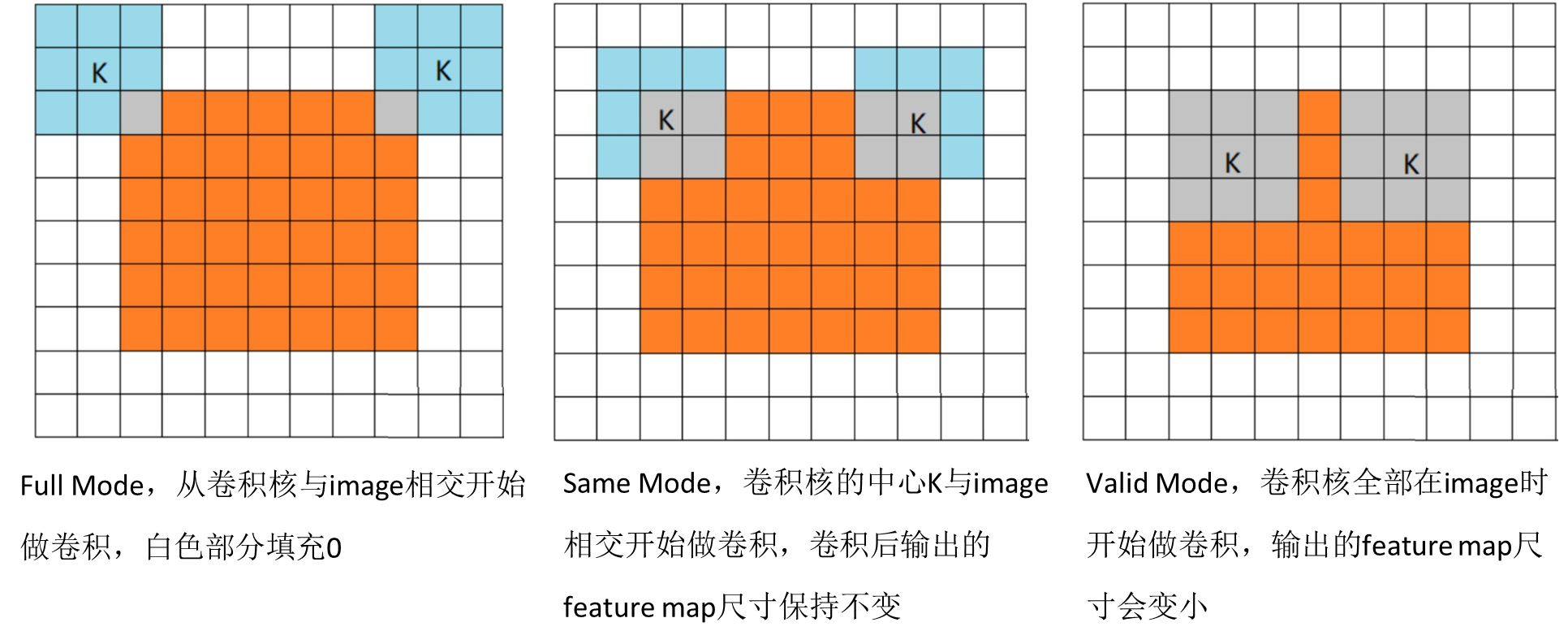
• 卷积的三种形式: full, valid, same ,橙色矩形为 image 大小为 7 * 7 ,蓝色矩形为卷积核,大小 3 * 3
- 三层卷积:32,64,128
- Conv1D(filters=32, kernel_size=5, padding='same', activation=LeakyReLU(alpha=0.001), input_shape = (205, 1))
- 大池化层
- MaxPool1D(pool_size=5, strides=2, padding='same')
- Dropout层,Dropout(0.5)
- Flatten层,Flatten()
- 用来将把多维的输入一维化,用于从卷积层到全连接层的过渡,Flatten不影响batch的大小
- 全连接层
- Dense(units=512, activation=LeakyReLU(alpha=0.001))
3.Paddle实现
1.自定义数据集
数据集需要继承paddle.io.Dataset
- 1)__getitem__: 根据给定索引获取数据集中样本,在 paddle.io.DataLoader 中使用该函数获取样本
- 2)__len__: 返回数据集样本个数, paddle.io.BatchSampler 中需要样本个数生成下标序列
2.构造dataloder
create_data_loader函数用于创建训练和预测时需要的DataLoader对象
- 1)paddle.io.DataLoader返回一个迭代器,该迭代器根据batch_sampler指定的顺序迭代返回dataset数据
- 2)batch_sampler:产生的mini-batch样本
- 3)collate_fn:指定如何将样本列表组合为mini-batch数据。传给它参数需要是一个callable对象,需要实现对组建的batch的处理逻辑,并返回每个batch的数据
Paddle_sample1中的示例:
# 自定义DataSet
class RandomDataset(Dataset):
def __init__(self, num_samples):
self.num_samples = num_samples
def __getitem__(self, idx):
image = np.random.random([IMAGE_SIZE]).astype('float32')
label = np.random.randint(0, CLASS_NUM - 1, (1, )).astype('int64')
return image, label
def __len__(self):
return self.num_samples
dataset = RandomDataset(BATCH_NUM * BATCH_SIZE)
# 定义DataLoader
loader = DataLoader(dataset,
batch_size=BATCH_SIZE,
shuffle=True,
drop_last=True,
num_workers=2)
# 模型训练
for e in tqdm(range(EPOCH_NUM)):
for i, (image, label) in enumerate(loader()):
out = simple_net(image)
loss = F.cross_entropy(out, label)
avg_loss = paddle.mean(loss)
avg_loss.backward()
opt.minimize(avg_loss)
simple_net.clear_gradients()
if i == BATCH_NUM-1:
print("Epoch {} batch {}: loss = {}".format(e, i, np.mean(loss.numpy())))
第三节 肺炎CT图像识别与分割
1.cnn
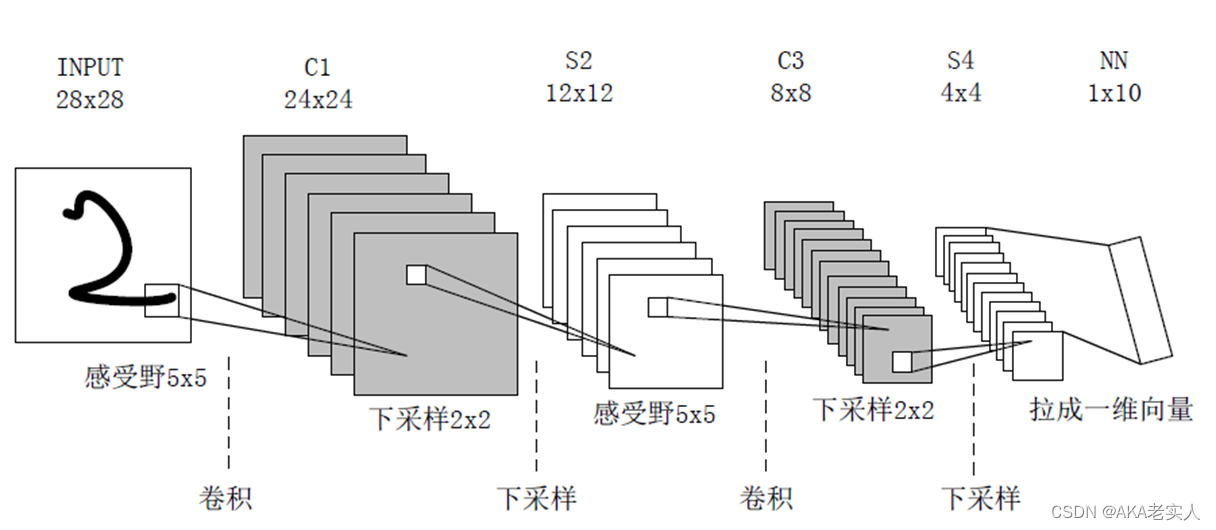
CNN的网络结构:
- 输入层,Input,输入可以是灰度图像或RGB彩色图像(三通道)。对于输入的图像像素分量为 [0, 255],为了计算方便一般需要归一化(如果使用sigmoid激活函数,会归一化到[0, 1],如果使用tanh激活函数,则归一化到[-1, 1])
- 卷积层,C*,特征提取层,得到特征图,目的是使原信号特征增强,并且降低噪音;
- 池化层,S*,特征映射层,将C*层多个像素变为一个像素,目的是在保留有用信息的同时,尽可能减少数据量
- 光栅化:为了与传统的多层感知器MLP全连接
- 多层感知器(MLP):最后一层为分类器,多分类使用Softmax,二分类可以使用Logistic Regression
卷积过程包括:用一个可训练的滤波器fx去卷积一个输入的图像(第一阶段是输入的图像,后面的阶段就是卷积特征图),然后加一个偏置bx,得到卷积层Cx
下采样过程包括:每邻域四个像素求和变为一个像素,然后通过标量Wx+1加权,再增加偏置bx+1,然后通过一个sigmoid激活函数,产生一个缩小四倍的特征映射图Sx+1
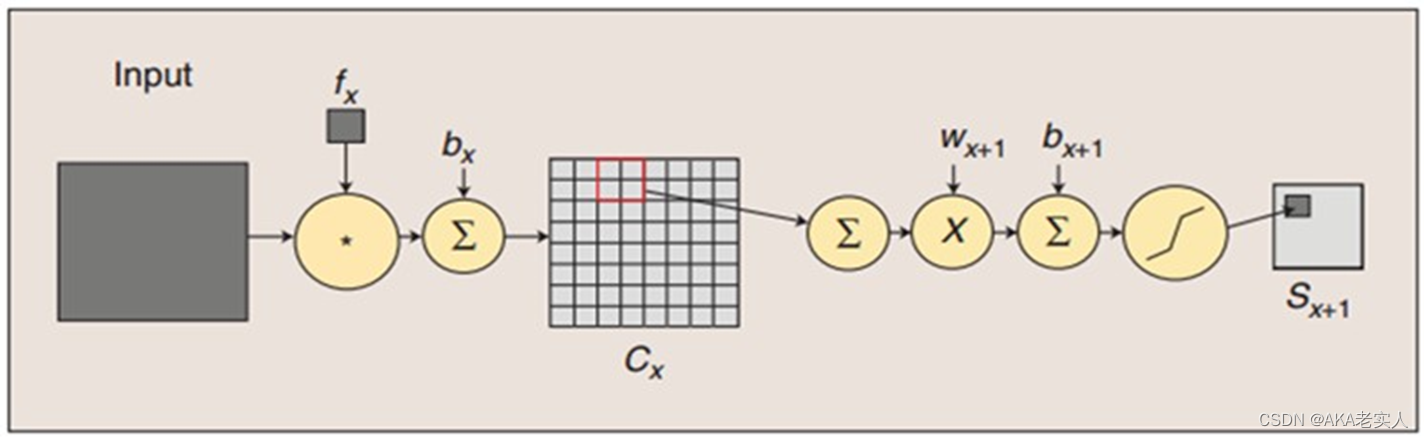
光栅化(Rasterization),为了与传统的MLP(多层感知机)全连接,把上一层的所有Feature Map的每个像素依次展开,排成一列
图像经过下采样后,得到的是一系列的特征图,而多层感知器接受的输入是一个向量,所以需要将这些特征图中的像素依次取出,排列成一个向量
卷积网络可视化
定义4组滤波器,filter后进行可视化:
filter_vals = np.array([
[-1, -1, 1, 1],
[-1, -1, 1, 1],
[-1, -1, 1, 1],
[-1, -1, 1, 1]
])
# 定义滤波器 filters
filter_1 = filter_vals
filter_2 = -filter_1
filter_3 = filter_1.T
filter_4 = -filter_3
filters = np.array([filter_1, filter_2, filter_3, filter_4])
class Net(nn.Module):
def __init__(self, weight):
super(Net, self).__init__()
# 使用4个固定的fiters,初始化卷积层的权重
k_height, k_width = weight.shape[2:] # 4, 4
# 这里有4个grayscale filters
self.conv = nn.Conv2d(1, 4, kernel_size=(k_height, k_width), bias=False)
# 初始化卷积层权重
self.conv.weight = torch.nn.Parameter(weight)
self.pool = nn.MaxPool2d(2, 2) # 定义池化层
def forward(self, x):
# 计算卷积层,激活层,池化层输出
conv_x = self.conv(x)
activated_x = F.relu(conv_x)
pooled_x = self.pool(activated_x)
# 返回三层输出结果
return conv_x, activated_x, pooled_x Batch Normalization(BN)
- BN算法目前已经被大量应用
- 网络训练过程中参数不断改变导致后续每一层输入的分布也发生变化,而学习的过程又要使每一层适应输入的分布,因此我们不得不降低学习率、小心地初始化
- 一般在训练网络的时会将输入减去均值,有些时候会对输入做白化等操作,目的是为了加快训练(Thinking 为什么减均值、白化可以加快训练)
-
BN就是通过一定的规范化手段,把每层神经网络任意神经元 这个输入值的分布强行拉回到均值为0方差为1的标准正态分布
-
使得非线性变换函数的输入值落入对输入比较敏感的区域,从而避免梯度消失问题。这样输入的小变化就会导致损失函数较大的变化(使得梯度变大,避免梯度消失问题产生),同时也让收敛速度更快,加快训练速度
-
AlexNet结构
-
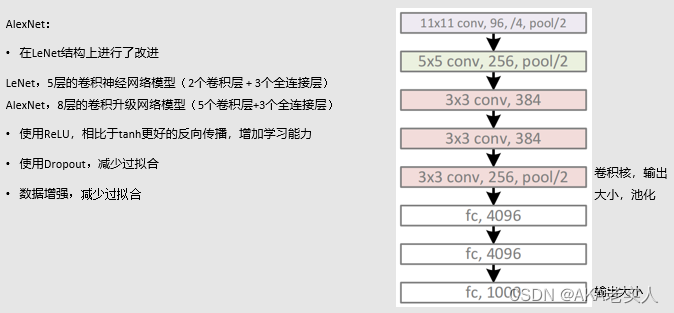
针对MNIST数据,可以修改AlexNet网络的CNN层:
nn.Conv2d(1, 32, 3, 1)
nn.Conv2d(32, 64, 3, 1, 1)
nn.Conv2d(64, 128, 3, 1, 1)
nn.Conv2d(128, 256, 3, 1, 1)
nn.Conv2d(256, 256, 3, 1, 1)
也可以修改AlexNet网络的FC层:
nn.Linear(256*3*3, 1024)
nn.Linear(1024, 512)
nn.Linear(512, 10)
-
AlexNet训练过程:
Step1, 给出训练样本集{Xi,Yi}
Step2, 根据Xi以及CNN的模型结构,前向传播(forword propagation)
Step3, 前向传播结果计算出模型输出Yi,并计算出损失函数
Step4, 根据损失函数进行反向传播(back propagation),计算出所有参数梯度
Step5, 根据参数梯度进行梯度下降算法,不断迭代拟合模型参数
-
ResNet
-
以往的CNN模型,当层数增加到某种程度,模型的效果将会不升反降,即深度模型发生了退化(degradation)
提出残差学习 Residual Learning,解决CNN的效果退化问题
Res是 Residual 的缩写,基于残差学习,让神经网络能够越来越深,准确率越来越高
-
Thinking:深层CNN网络的效果退化是因为过拟合问题么?
网络模型的3种情况:欠拟合,拟合,过拟合
在这个多项式回归问题中,第一个模型是欠拟合(under fit)有很高的偏差(high bias),第二个拟合比较成功,而第三个是典型的过拟合(overfit),这时由于模型过于复杂,导致了高方差(high variance)
-
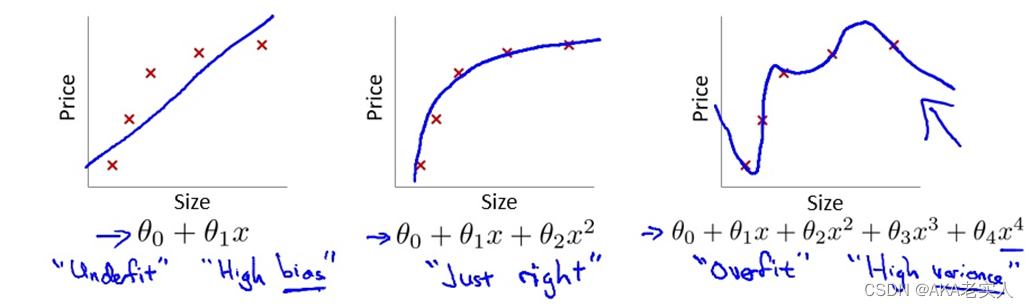 CNN面临的效果退化不是因为过拟合,因为过拟合的现象是训练好,测试不好(高方差,低偏差),而实际上深层CNN的训练误差和测试误差都很大
CNN面临的效果退化不是因为过拟合,因为过拟合的现象是训练好,测试不好(高方差,低偏差),而实际上深层CNN的训练误差和测试误差都很大 Thinking:深层CNN的效果退化是因为什么?
通常,当我们堆叠一个模型时,会认为效果会越堆越好。因为,假设一个比较浅的网络已经可以达到不错的效果,那么再进行叠加的网络如果什么也不做,效果不会变差
事实上,这是问题所在,因为“什么都不做”是之前神经网络最难做到的事情之一
这时因为由于非线性激活函数(Relu)的存在,每次输入到输出的过程都几乎是不可逆的(信息损失) => 所以很难从输出反推回完整的输入
-
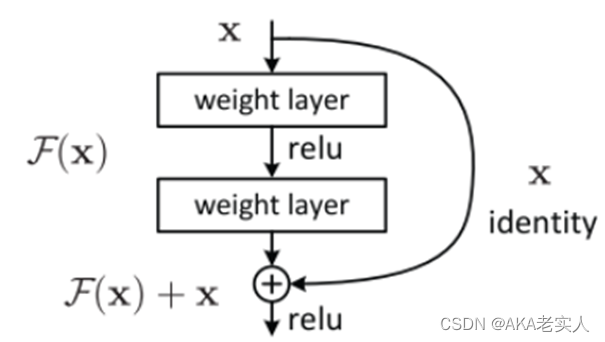
Residual Learning:
如果深层网络后面的层都是是恒等映射,那么模型就可以转化为一个浅层网络 => 需要找到恒等映射关系
ResNet将Residual Learning设计为 H(x)=F(x)+x
直接把恒等映射作为网络的一部分,这样把问题转化为学习一个残差函数 F(x)=H(x)-x
只要F(x)=0,就构成了一个恒等映射H(x) = x
同时,拟合残差要比拟合恒等映射容易
曲线叫做跳接(shortcut connection),通过跳接在激活函数前,将上一层(或几层)之前的输出与本层计算的输出相加,可以将求和的结果输入到激活函数中做为本层的输出
-

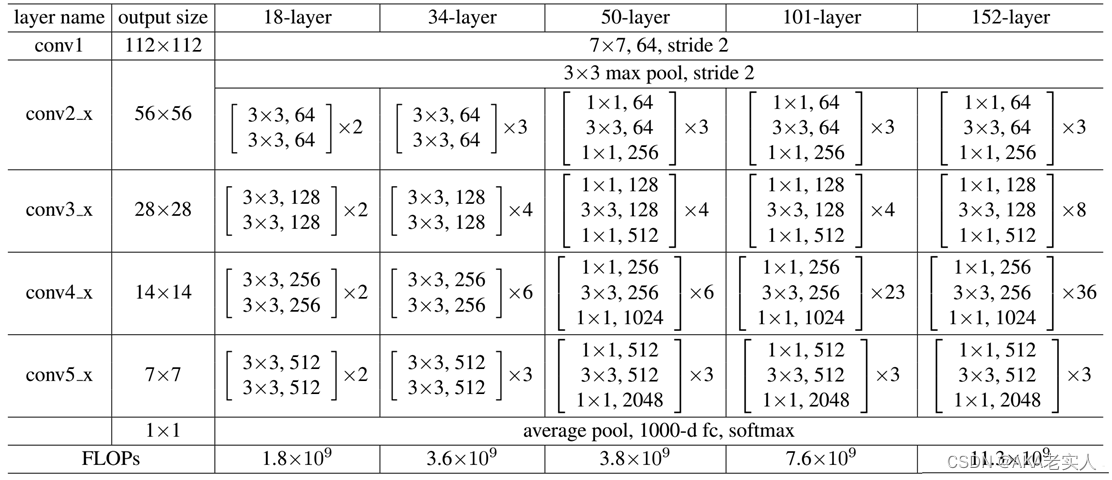
常用的ResNet:
5种常用深度18,34,50,101,152
网络分成5部分,分别是:conv1,conv2_x,conv3_x,conv4_x,conv5_x
网络层数的计算,比如ResNet101
经过3 + 4 + 23 + 3 = 33个building block,每个block为3层,所以有33 x 3 = 99层
再加上第一层的卷积conv1,以及最后的fc层(用于分类),一共是99+1+1=101层
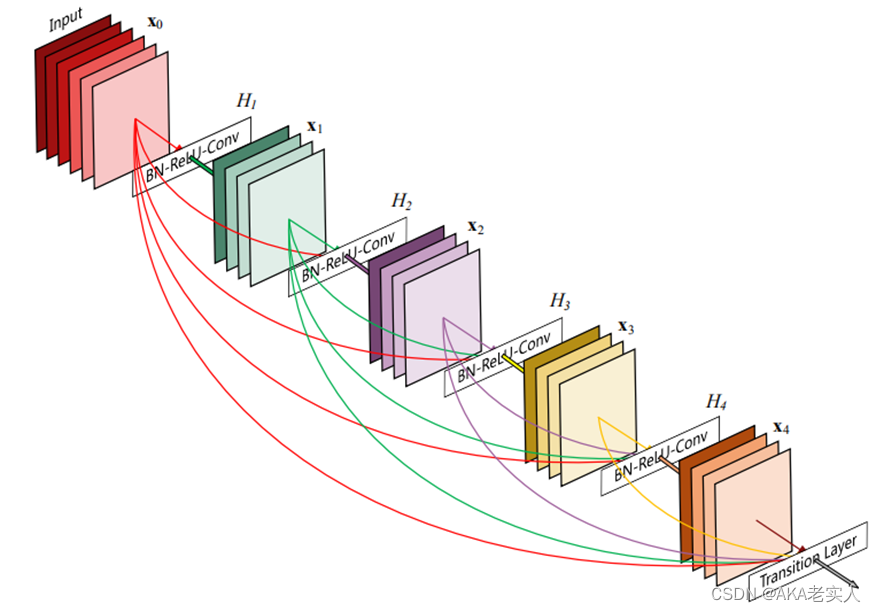
DenseNet
-
提出了DenseNet(密集卷积网络),它的每一层在前向反馈模式中都和后面的层有连接。对于每一层,它的输入包括前一层的输出和该层之前所有层的输入
DenseNet的优点:
缓解了梯度消失
加强了特征传播
增强了特征复用
减少了参数量
-

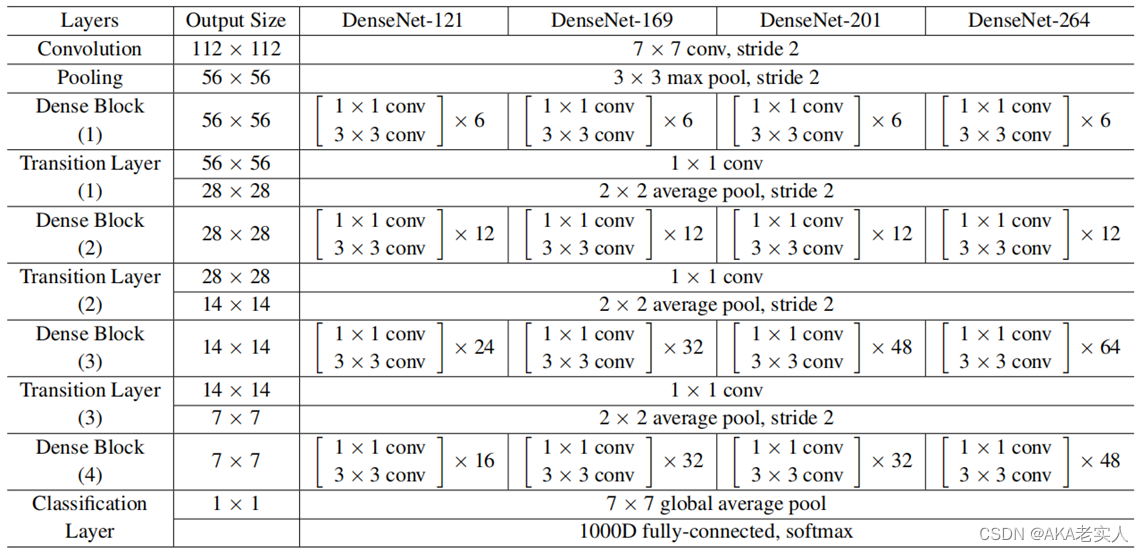
DenseNet网络:
4种深度121,169,201, 264
作者将1x1卷积和3x3卷积连用,作为一组,这里在3x3卷积前用1x1是为了减少输入特征图数量,提高计算效率,事实证明在DenseNet中这种结构很有效,添加了1x1的DenseNet叫做DenseNet-B
DenseNet网络中使用DenseBlock+Transition的结构
DenseBlock是包含很多层的模块,每个层的特征图大小相同,层与层之间采用密集连接方式
Transition模块是连接两个相邻的DenseBlock,并且通过Pooling使特征图大小降低
GPU加速
-
GPU:
GPU全名为Graphics Processing Unit,又称图形显示卡,可以渲染出2D、3D、VR效果
GPU非常适合并行计算,可以加速现代科学计算,现在GPU不再局限于游戏和视频领域
CPU与GPU:
并行计算,主要靠核(Core)来做算术逻辑运算
CPU通常只有2到8个核,GPU可以有上千个核
CPU的处理能力更综合(类似大学生)=> 处理复杂问题
GPU的处理能力更简单(类似小学生)=> 处理简单特定的任务
-
torch.cuda.device_count() 获得能够使用的GPU数量 # 设置使用GPU cuda = torch.device('cuda') # device : GPU or CPU device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") model.to(device)多GPU加速:
单机多GPUs采用DataParallel,默认所有的显卡都会使用
net = torch.nn.DataParallel(model)
如果只想利用其中一部分,如只使用编号为0、1、2、3的四个GPU
#假设有4个GPU,其id设置如下
device_ids =[0,1,2,3]
#对数据
input_data=input_data.to(device=device_ids[0])
#对于模型
net = torch.nn.DataParallel(model)
net.to(d
GPU加速:
GPU的数量尽量为偶数
数据量较小,采用单GPU,甚至数据很小的时候,不如采用CPU
采用GPU加速是,模型和数据都需要.cuda()或者 to(device)
evice)
-
torchvision使用
-
torchvision工具:
由3个工具组成,分别是:torchvision.datasets、torchvision.models、torchvision.transforms
torchvision.models中包含alexnet、densenet、inception、resnet、squeezenet、vgg等常用的网络
import torchvision model = torchvision.models.resnet50(pretrained=False)如果使用预训练模型,可以设置pretrained=True
model = torchvision.models.resnet50(pretrained=True) -
预训练模型是通过models包下的resnet.py脚本进行的
-
__all__ = ['ResNet', 'resnet18', 'resnet34', 'resnet50', 'resnet101', 'resnet152'] model_urls = { 'resnet18': 'https://download.pytorch.org/models/resnet18-5c106cde.pth', 'resnet34': 'https://download.pytorch.org/models/resnet34-333f7ec4.pth', 'resnet50': 'https://download.pytorch.org/models/resnet50-19c8e357.pth', 'resnet101': 'https://download.pytorch.org/models/resnet101-5d3b4d8f.pth', 'resnet152': 'https://download.pytorch.org/models/resnet152-b121ed2d.pth', }DataLoader使用
-
DataLoader使用:
当数据集较大时,可以进行分批训练
-
train_loader = DataLoader(train_data, batch_size=BATCH_SIZE, num_workers=1, shuffle=False) for epoch in range(EPOCH): for i, data in enumerate(train_loader):需要注意,图片的尺寸需要保持一致,否则会报错
RuntimeError: invalid argument 0: Sizes of tensors must match except in dimension 0. Got 400 and 675 in dimension 2 at /pytorch/aten/src/TH/generic/THTensor.cpp:689
-
使用Resize进行尺寸调整,需要固定神经网络输入,不然维度不一致会起冲突
transform_train = transforms.Compose([ transforms.Resize((224,224)), transforms.ToTensor()])说明使用ResNet网络时,如果图像尺度统一为224×224时,要用transforms.Resize([224, 224]),不能写成transforms.Resize(224),transforms.Resize(224)表示把图像的短边统一为224,另外一边做同样倍速缩放(不一定为224)
数据增广
图像增广(image augmentation)可以通过对训练图像做一系列随机改变
产生相似但又不同的训练样本,从而扩大训练数据集的规模(在深度卷积神经网络中,大规模数据集是成功应用深度神经网络的前提)
降低模型对某些属性的依赖,从而提高模型的泛化能力。比如,对图像进行不同方式的裁剪,使感兴趣的物体出现在不同位置,从而减轻模型对物体出现位置的依赖性。比如调整亮度、色彩等因素来降低模型对色彩的敏感度
常用的图像增广方法:
- 翻转和裁剪
- transforms.RandomHorizontalFlip(),实现一半概率的图像水平(左右)翻转
- 变化颜色
- 可以从4个方面改变图像的颜色:亮度(brightness)、对比度(contrast)、饱和度(saturation)和色调(hue)
- 比如将图像的亮度随机变化为原图亮度的 50% ∼150%
- 叠加多个图像增广方法
- 通过transforms.Compose,可以将多个图像增广方法叠加使用
-
transforms.Resize
输入图像的短边resize到这个int数,长边则根据对应比例调整,图像的长宽比不变
如果输入是个(h,w)的序列,h和w都是int,则直接将输入图像resize到这个(h,w)尺寸,相当于force
-
transforms.RandomResizedCrop
将给定图像随机裁剪为不同的大小和宽高比,然后缩放所裁剪得到的图像为制定的大小
即先随机采集,然后对裁剪得到的图像缩放为同一大小,默认scale=(0.08, 1.0)
transforms.CenterCrop
以输入图的中心点为中心点做指定size的crop操作
transforms.RandomHorizontalFlip
以给定的概率随机水平旋转给定的PIL的图像,默认为0.5
PyTorch模型保存与加载
PyTorch模型保存:
- 保存整个神经网络的的结构信息和模型参数信息,save的对象是网络net
- torch.save(model_object, 'resnet.pt')
- 只保存神经网络的训练模型参数,save的对象是net.state_dict()
- torch.save(model.state_dict(), "resnet.pt")
PyTorch模型加载:
- 对应第一种保存方式,加载模型时通过torch.load('.pt')直接初始化新的神经网络对象
- model = torch.load('resnet.pt')
- 对应第二种保存方式,需要首先导入对应的网络,再通过model.load_state_dict(torch.load('.pt'))完成模型参数的加载
- model.load_state_dict(torch.load("resnet.pt"))
PyTorch模型保存 .pt,.pth,.pkl 的区别:
- torch.save() 函数保存模型文件
- 文件后缀可以是 .pt,.pth,.pkl,均为PyTorch模型文件
- 使用 .pt 或者 .pth 都可以,官方文档使用.pt 更多
- .pkl 这种后缀名,是因为torch.save() 调用了Python pickle来保存模型(pickle是 Python的序列化/反序列化的模块,可以用于保存文件)
-
第四节 中文场景文字识别
- 1.


















 5025
5025

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









