







 本文解析了StyleGAN的核心结构,包括基于风格的生成器设计,中间隐空间的引入,以及如何通过AdaIN实现风格控制。重点介绍了生成器的性质,如风格解耦、混合风格生成和噪声的作用。
本文解析了StyleGAN的核心结构,包括基于风格的生成器设计,中间隐空间的引入,以及如何通过AdaIN实现风格控制。重点介绍了生成器的性质,如风格解耦、混合风格生成和噪声的作用。

目录
在未来的一段时间,我会开一个小专题,来介绍下GAN网络的一些经典论文。希望对那些想要入坑的同学提供一点点帮助。考虑到StyleGAN系列论文在相关领域的影响力,我们首先来介绍下StyleGAN的开山之作:A Style-Based Generator Architecture [1]。
简介
GAN网络自2014年由Goodfellow提出后,立刻引起学界和工业界的广泛关注。在数据生成方面,GAN充分利用了深度学习网络对于特征抽取与学习的能力,建立了基于生成判定结构的GAN模型,非常类似金庸小说的左右互搏术。当然,作为早期的工作,GAN网络关于数据生成的实际能力,还有待提高。原因是,对于一个较大的样本空间,完全依靠随机初始化,而不引入有效的结构信息控制方法,会使生成的数据缺乏稳定的语义结构。因此一些学者把注意力首先放在一些比较受控的数据生成问题上,如人脸数据生成。
StyleGAN因此被提出。该项工作的思路比较清晰,就是利用风格迁移研究的一些先验知识 [3],来重构GAN网络的生成器。因为针对人脸数据,对于语义结构能够最大限度的保持其原有的结构信息,使得生成的人脸数据具有以假乱真的效果。事实上,StyleGAN完全可以被认为是针对人脸数据设计的风格迁移算法。在介绍部分,作者说,生成器将输入的隐藏编码嵌入到中间隐藏空间,这对变异因素如何在网络中表示有深远的影响。这里,我还没有搞懂什么是隐藏编码以及中间隐藏空间,以及为什么这种嵌入是有深远影响的。这里作者解释说,原始的隐藏空间需要与输入的训练数据的分布,在概率密度上保持一致,这带来了一些不好的限制。中间隐藏空间解除了这种限制。为了实现该目的,作者提出了两个自动度量:感知路径长度(perceptual path length)和线性可分性(linear separability),以实现对生成器的量化分析。最终,生成器允许更加线性地,较少纠缠的不同因素的变化表示。
基于风格的生成器
原始GAN网络的生成器是一个MLP结构,用来基于一个随机噪声来拟合一个数据分布,使得在判别器进行判定的时候,被错误识别的概率趋近于0.5,即无法区分。StyleGAN的生成器不是由一个随机的噪声开始,而是一个学习获得的固定输入开始,结构如下图:
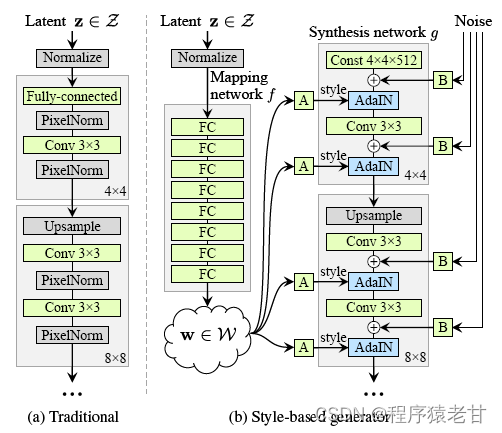
首先将隐空间内的一个分布z通过一系列FC映射到一个中间隐空间w。这里和之前的GAN不一样的是,这个中间隐空间的分布w不是最终结果,而是控制最终结果输出的一个重要的控制变量。作者这里控制维度是512维,z到w的映射为一个8层的MLP来实现。之后用w来实现风格化,即y=(y_s, y_b), 以控制样例归一自适应(adaptive instance normalization, AdaIN):
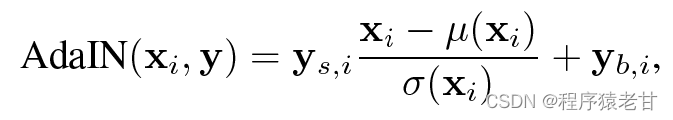
简单理解,就是将x按照分布,转换程w。这是一个按照分布建立的风格迁移方法,以建立基于特征图的仿射变换。w是保证其对后续生成结构的分布要求,但是对x的要求则降低了,因为引入了中间隐空间。作者在原文中说,原始GAN网络对隐空间输入的约束要求较高,会产生较大概率的对抗纠缠。中间隐空间则很好的解决了这个问题。这样,基于一个固定的数据,建立独立于映射网络的合成网络。在合成网络的每一步卷积时,输入源图像进行累加(B),之后使用入AdaIN实现仿射变换,实现风格迁移,这样最终生成的结果,就能够得到一个基于B的结构,A的风格的全新的图片。读到这里我还是有些疑问,比如在实现风格迁移时w和风格图像A的关系是什么;w到y是一个什么样的计算,对应的y_s和y_b是什么东西?这里我看了以下文献[3],发现y_s和y_b就是仿射变换的两个参数,是通过学习获得,与空间位置有关。分布也给出了对应的离散计算公式:
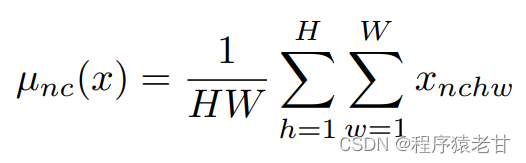
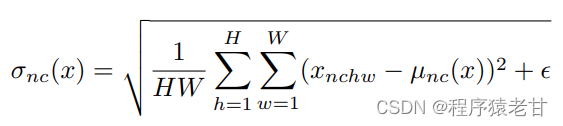
到此处,文章最核心的结构已经被介绍完了。后边很大的篇幅都是在讨论StyleGan对图像质量以及风格迁移的应用。
生成器的性质
生成器架构使得通过对样式进行特定比例的修改来控制图像合成成为可能。我们可以通过观察映射网络和放射变换,基于学习获得的分布,来为每一个风格绘制样本。而合成网络用于从风格数据中生成最终希望获得的图片。每一种风格都被定位在网络中,通过修改某一些特定的风格数据,来实现对图像某些特定属性的编辑。
为了理解这个过程,我们重新审视AdaIN在生成器中的作用。AdaIN归一化每一个通道,变成均值与单位方差,仅应用基于风格的尺度和偏差,以修改相对重要的属性,用于之后的卷积计算。这个过程由于归一化,使得其数据不依赖于原始的分布。因此,每种风格在被下一个AdaIN操作覆盖之前只控制一个卷积。这段话是翻译自原文,我的理解就是实现对风格的解耦。一个合理的推论是,既然风格是能够被解耦并被部分应用于图像生成,那么混合风格是一个很自然的事情。作者提出了混合风格的概念。这里引入两个隐空间编码z1和z2,通过映射网络,就能够得到w1和w2。之后,在将w1和w2按照顺序输入到合成网络对应的位置,即实现了风格混合。下图是按照不同的混合级别混合A与B所建立的生成图片矩阵:
Coarse styles from source B:

Middle styles from source B:

Fine from B:

作者在3.2节讨论了在生成器中的噪声对于生成结果的影响,用来说明加入随机噪声的作用。再后面介绍了一些在对抗生成训练过程中,作者对解纠缠提出的一些解释。这里不再展开讨论。未来如果有机会的话,我会在这个博客更新部分代码讲解,感兴趣的小伙伴可收藏。
总结:
整体来说,StyleGan的最大贡献就是引入了中间隐空间,避免z到样本的直接映射,解除了基于z的硬性分布约束。通过中间隐空间,能够得到解耦后的风格仿射变换,使得能够方便的混合噪声,以得到混合风格的生成图片。可以想象的是,这个映射网络似乎设计的有些粗糙,对于风格解耦的设计没有给出更多可靠的解释,使得对生成图像无法进行精确的风格控制。带着这样的猜测,我们将在下一篇博客来学习针对StyleGan的改进。
Reference
[1] Karras T, Laine S, Aila T. A style-based generator architecture for generative adversarial networks[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2019: 4401-4410.
[2] Goodfellow I, Pouget-Abadie J, et al. Generative adversarial networks[J]. Communications of the ACM, 2020, 63(11): 139-144.
[3] X. Huang and S. J. Belongie. Arbitrary style transfer in real-time with adaptive instance normalization. CoRR, abs/1703.06868, 2017.


















 1913
1913

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











