






点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
本文作者:heryms | 来源:知乎(已授权)
https://zhuanlan.zhihu.com/p/354647467
今天介绍一下我自己的一篇cvpr2021的文章,熟悉我的人应该都知道我做了挺久的三维相关的任务,尤其是点云,去年的HVNet也是第一次尝试将idea成稿,今年的TPCN就是彻底地把点云还有indexing系统迁移到prediction任务。
TPCN: Temporal Point Cloud Networks for Motion Forecasting

论文:https://arxiv.org/abs/2103.03067
Introduction
随着自动驾驶的深入,planning以及prediction成为越来越关键的任务。以往的方法,其实大致可以分为三种,一种是ruled based的方式,通过运动学模型以及高精度地图进行约束。第二种就是纯learning based的model,第三种就是planning + learning的方式,通过一个传统的prediction或者planning模块提供高质量的proposal,然后通过learning的方式进行refine以及classification,有点像RCNN。对于纯learning based的方式,根据输入的representation也可以分为rasterization image(MultiPath, ChauffeurNet等), vector representation(VectorNet),以及以laneconv为代表的图卷积神经网络。
总体来说prediction任务,其实是一个时间加空间信息相关的任务(给定地图信息以及一系列agent历史的轨迹,推测agent未来的轨迹),1)时间信息可以提供运动信息比如速度加速度,2)空间信息更多的强调跟周围环境(地图)或者物体的交互信息。时间空间在这个任务里都是非常重要的部分,缺一不可。
motivation
对于这项任务,其实输入的就是离散的点,即使地图的车道线也可以离散化成地图点,同时这些点在空间上又具有稀疏性,离散稀疏,permutation invariant,尺度不变性,这几个属性其实就是点云数据的属性,只不过这些点有点带了时序信息,比如同一个agent在不同时刻的位置。因此点云处理的想法是非常有潜力应用在这个任务,只不过我们得通过额外的处理手段去提取时序信息。因此,我们提出了TPCN,这是一个灵活而且同一的框架用来处理prediction问题中时序空间信息,以及二者信息的融合。总体来说,TPCN核心包含了两个模块,1). Dual-representation Spatial Learning 2). Dynamic Temporal Learning
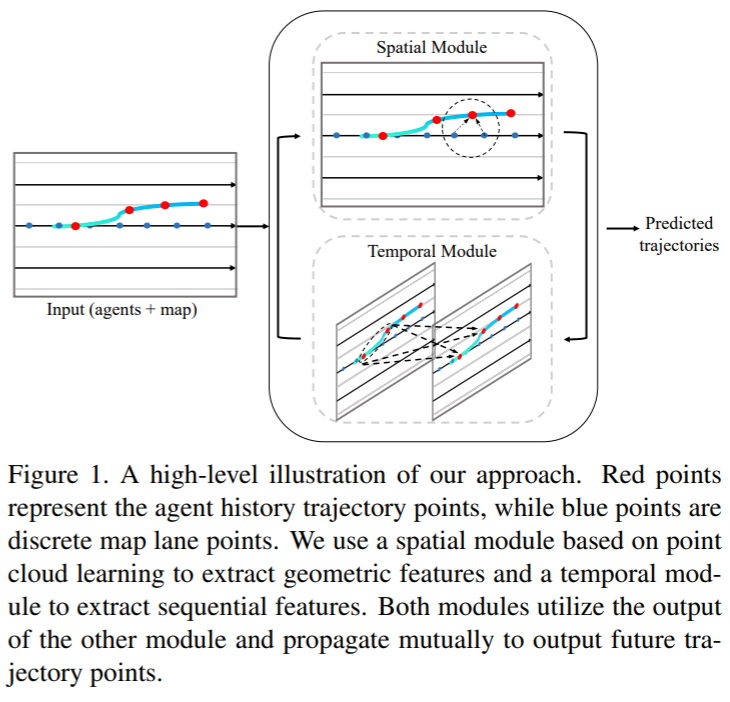
Approach
1). Dual-representation Spatial Learning.
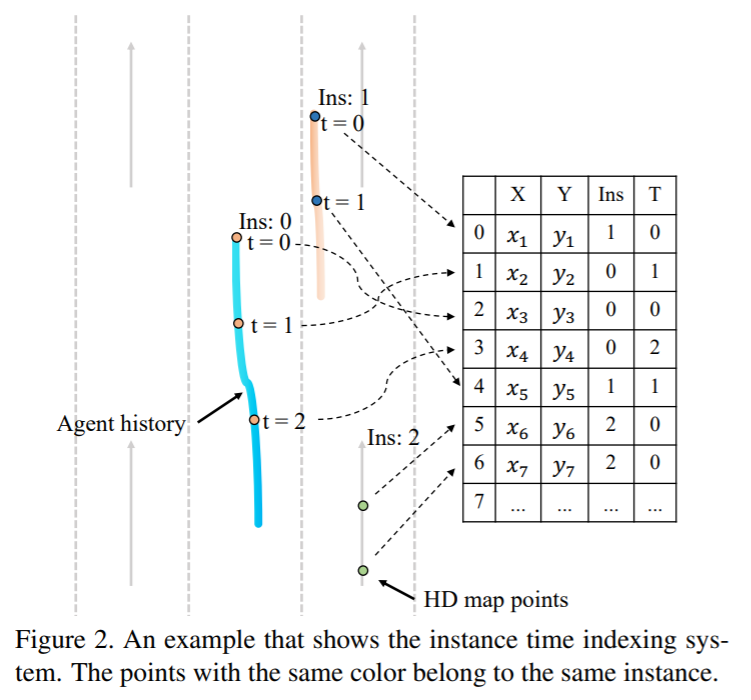
在点云任务中,PVCNN,PVRCNN等提出也论证了多视角,多种表征方式在点云特征学习的重要性,因此我们也采用了这种方式。本质上来说,这些方式其实都维护了不同表征下同一个点的一对一的索引关系,这里我们称之为indexing系统,有了这种一对一的mapping,我们可以很简单的完成point-level的的融合。在这种想法的引导下,其实空间跟时间的点在这个任务其实也存在一对一的映射关系,因此我们也可以建立一套空间点到时间点的一对一的映射关系,我们称为Instance Time Indexing的系统。Figure 2展示了一个简单的例子
2). Dynamic Temporal Learning.
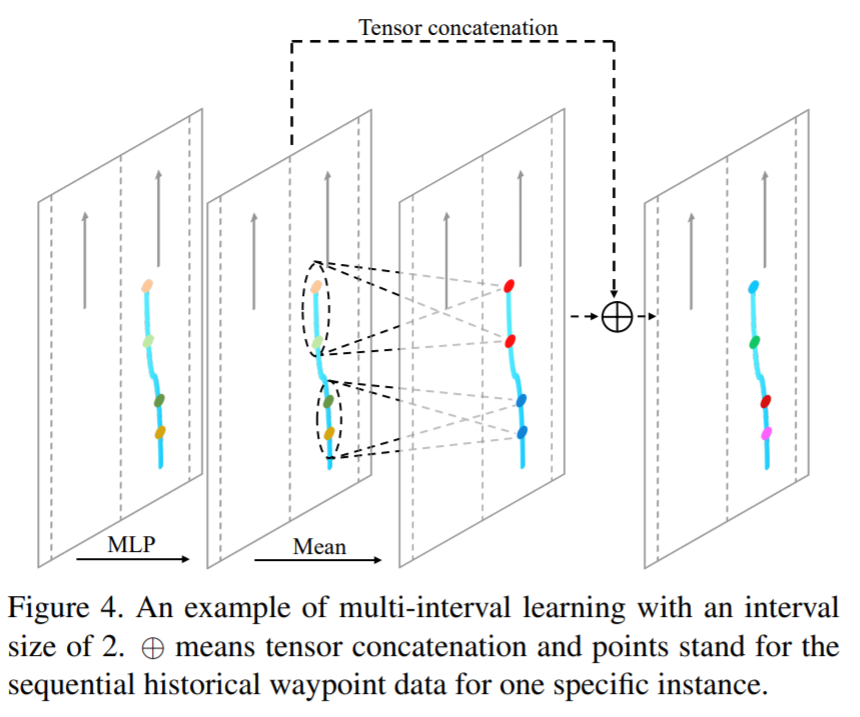
一旦有了一套Instance Time Indexing,我们就可以非常方便在时间跟空间两个作用域进行point-level features的propagation,也可以时间跟空间上的point-level features的融合,这里之所以成为dynamic,是因为相比以前的方法,LaneConv是需要把所有的agents pad到固定的时间长度,然后处理的时间需要做masking,而我们的方式是没有任何冗余的特征表示形式。在此基础上,我们借鉴了PSPNet,利用GPU上的scatter,gather,unique等操作(从代码的实现角度来说,也有不少的成熟库实现了相关的操作,比如pytorch_scatter),实现了多尺度的时间上的Multi-interval Learning以及Instance Pooling,具体操作可以参考文章的Sec.3.2.
3). Joint Learning
有了时序特征以及空间特征,我们就在point-level的基础上就可以从时间转换到空间,也可以从空间转换到时间,时序特征以运动信息为主,空间信息关注地图,agent之间的交互,最后达到了一个统一灵活的学习框架。
Useful Tricks and Learning
1). Displacement Prediction and Learning.
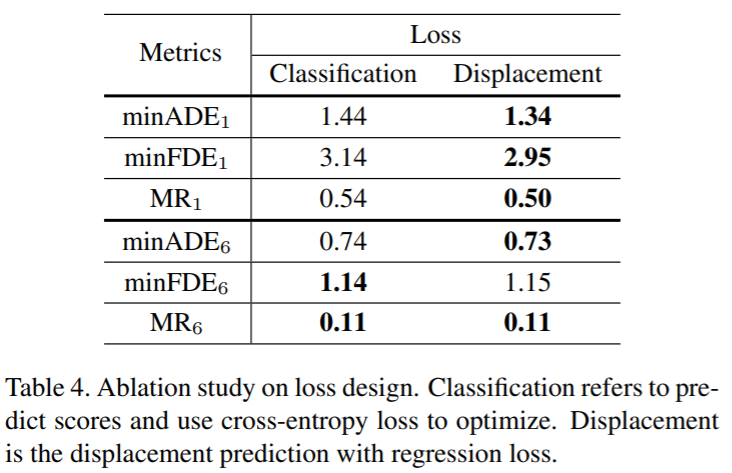
因为prediction任务的多模态性质,很多时候网络会输出多条轨迹以及各自的概率,训练的过程中,一般是选择当前mFDE最小的轨迹进行反传,但是这个时候如果有两条的轨迹相当接近真值,其实也只会有一条进行反传,其实这是不合理的。因此受到IoU Loss的启发,我们不预测概率而是预测displacement error,这样在分类的loss branch,所有的样本以及预测的displacement都可以进行反传,这里不涉及到label的分配,把分类问题转化为回归问题,变成了一个类似于soft label的regression problem,实验证明displacement loss优于分类的loss
2). Data augmentation
同时对数据的分布的统计,我们也做一些data augmentation,比如随机缩放,random point drop这些小的trick对于最后模型性能也存在一定的提升
Experiments
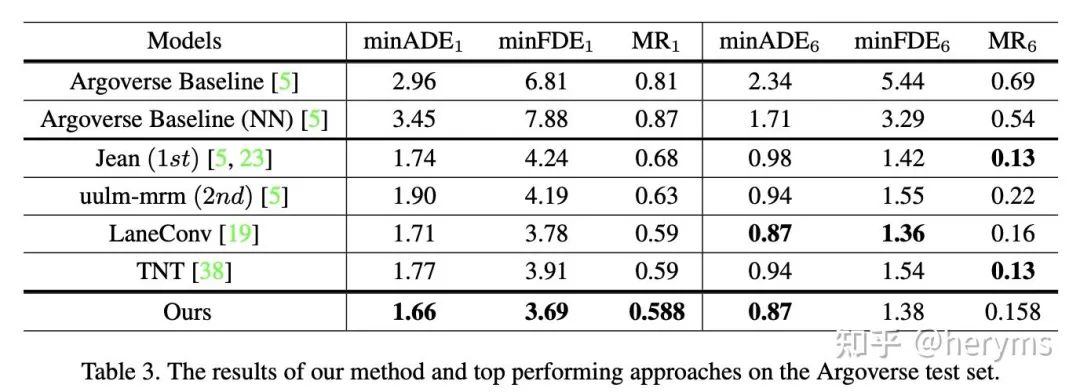
最后我们在argoverse上面的验证集以及测试集验证了我们方法的有效性,包含了各个模块的消融实验
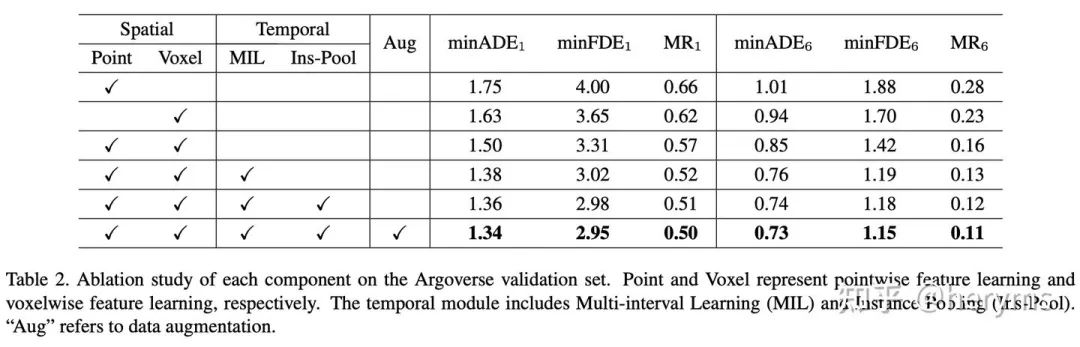
最后在argoverse测试集的成绩,我们的TPCN有效提高的SOTA~
Rethinking
对于TPCN的时空模块来说,我们使用了sparse conv这种相比于rasterization image的方式,可以节省更多的内存,也是更compact的一种特征表达方式
对于TPCN来说,类似的idea其实可以拓展到很多领域,比如更多视角的点云空间的学习,其实也就是indexing系统,存在不同视角或者不同表征方式,我们只要能够找到一对一的mapping或者indexing关系,那么我们就可以完成point-level的融合以及特征层面上面的融合,而现有的代码scatter,gather,hashing,unique之类的函数都能够非常容易帮我们完成这一过程
PointCloud learning is all you need
Reference
TNT: Target-driveN Trajectory Prediction
Learning Lane Graph Representations for Motion Forecasting
MultiPath: Multiple Probabilistic Anchor Trajectory Hypotheses
VectorNet: Encoding HD Maps and Agent Dynamics from Vectorized Representation
ChauffeurNet: Learning to Drive by Imitating the Best and Synthesizing the Worst
后台回复:CVPR2021,即可下载CVPR 2021论文和开源代码合集
点击下方卡片并关注,了解CV最新动态
重磅!CVer-3D点云交流群成立
扫码添加CVer助手,可申请加入CVer-3D点云方向 微信交流群,也可申请加入CVer大群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、Transformer、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如3D点云+上海+上交+卡卡),根据格式备注,才能通过且邀请进群

▲长按加微信群
▲点击上方卡片,关注CVer公众号
整理不易,请给CVer点赞和在看!![]()















 1177
1177











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









