






点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达

全文链接:https://arxiv.org/abs/2102.04848
本文是阿里巴巴达摩院视觉实验室潘攀博士团队在自监督学习方面的一次尝试。目前基于实例区分(Instance Discrimination)的自监督学习方法在图像领域取得了领先的结果,但现在基于实例区分思路大多采用非参数化对比学习(Contrastive Learning)方法,需要采用双分支(Dual-branch)网络、Momentum Encoder、大Batch Size等较为复杂的特殊设计来处理负样本缺失以及信息泄漏问题。
本文提出了一种单分支(One-branch)的参数化实例分类方法,将每一张图像看做一个类,可以充分利用负样本,同时避免了信息泄露问题。我们经过一系列创新实现了百万类别的实例分类,从而实现自监督学习,在多个下游迁移任务上取得了SOTA的结果。
一、简介
目前在视觉自监督学习领域,基于对比学习(Contrastive Learning)的自监督预训练方法在下游任务取得了媲美有监督学习预训练的效果,但现在的基于对比学习的方法大多采用了双分支结构,并依赖Memory Bank、较大的Batch Size、Momentum Encoder等手段来缓解负样本缺少问题。
在本文中,我们提出了一种基于大规模实例分类的单分支结构,可以充分利用数据集中的全部负样本,图1显示了本文方法的整体思路。
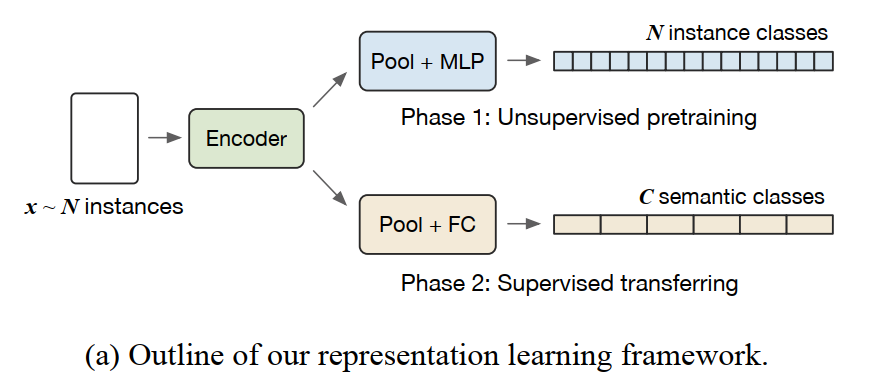
图1. 基于实例分类的自监督学习框架
由于实例分类将数据集中的每一个数据样本看成一类,则分类的类别数通常就会非常巨大(比如,ImageNet-1K含有128万图像、则对应分类数就是128万)。如此巨大的分类数则会随之带来三个问题:
1. 超大规模分类的实现:由于最后一层全连接的输出节点数等于分类数目,大规模分类会对显存和计算都带来极大的挑战;
2. 每个类别样本低访问频率导致的收敛困难:由于每个类只有一个样本,在每一个训练周期,每个类也只能“见到”一个对应的样本,会导致训练收敛非常困难;
3. 负样本噪声:实例分类在充分利用更多负样本的同时,也面临负样本噪声的问题,这会对模型最终性能造成不利影响。
针对上述问题,我们提出了有效的解决方案,包括混合并行、对比先验、标签平滑等技术,下面进行逐一介绍。
二、方法
1. 混合并行(Hybrid Parallelism)
对于大规模分类,需要一个和类别数相同数量输出的全连接层,而受限于显存和计算问题,通常采用的数据并行(distributed data parallel,DDP)训练框架基本是不可行的。我们引入了混合并行框架(distributed hybrid parallel,DHP)来解决这一问题。图2显示了混合并行框架的整体流程。
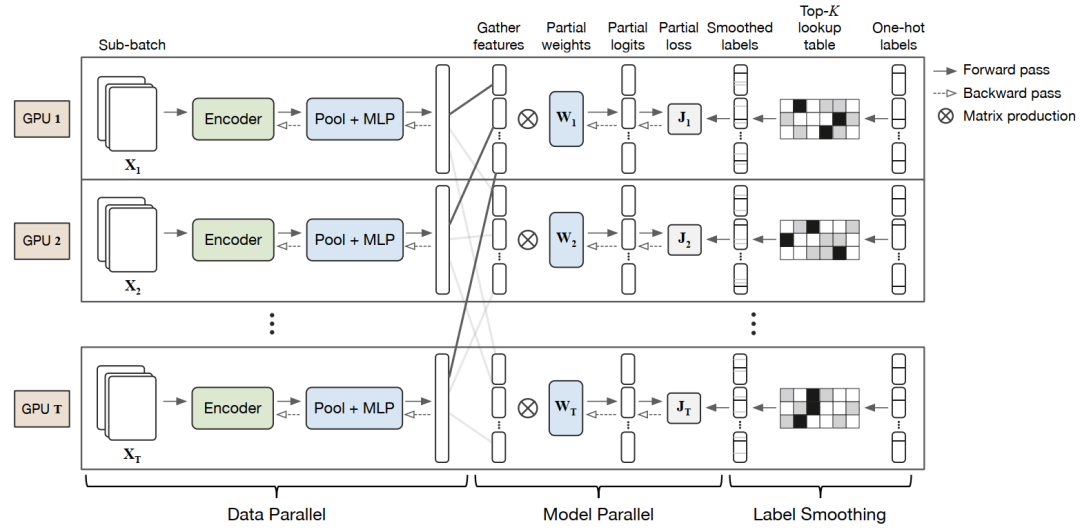 图2. 混合并行训练框架示意图
图2. 混合并行训练框架示意图
对于encoder和MLP层,我们采用数据并行方式;对于大规模FC层,我们采用模型并行方式,将其权重参数均分到各个GPU上。在每次迭代前向计算过程中,数据并行节点对各自的输入图像提取特征后发送给模型并行节点,每个模型并行节点接收到数据后进行前向计算并得到最终softmax的结果;在反向计算过程中,模型并行节点完成反向计算后需要做一次梯度同步,然后将数据并行节点所需的梯度回传,数据并行节点进行反向计算及同步操作后完成最终的模型参数更新。
2. 对比先验(A Contrastive Prior)
实例分类通常会遇到收敛困难的问题,这是由每个类别的训练样本遇到的低访问频率导致(每个epoch每个类只出现一次对应训练样本)。我们提出一种简单的全连接层初始化方式,有效的解决此问题。具体而言,在第一个epoch,利用随机初始化网络,放开Batch Normalization层的均值、方差统计机制,对每个样本提取对应的特征向量,并用此特征向量初始化对应的全连接层参数矩阵。
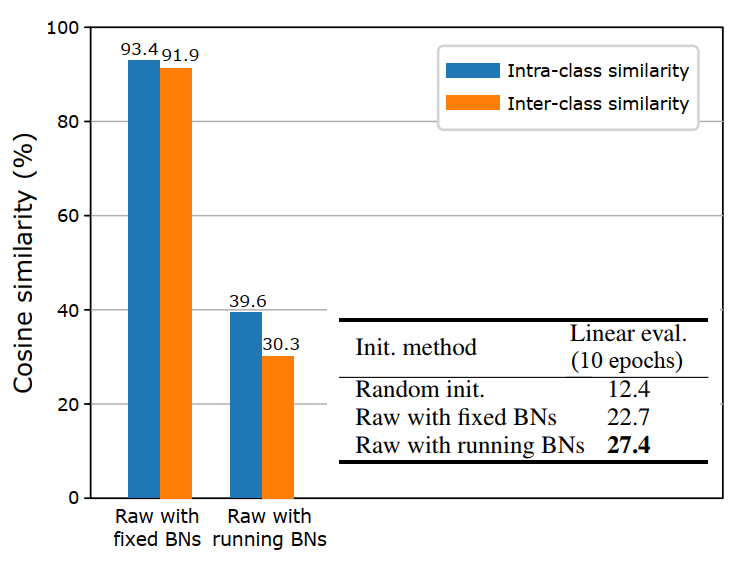
图3.分类矩阵权重不同初始化方法对比
这样做的背后思考有两个方面:
1)由于经过Batch Normalization层的特征向量会减去其他样本的特征滑动均值,因此会使得不同样本的特征分布散开;
2)将每个样本的特征向量直接赋给全连接层的参数矩阵,这样会使得在训练任务早期类似于pair-wise度量学习,使得收敛较为容易。图3显示了不同的初始化方法的区别,可以看到使用了对比先验的特征区分能力更强,同时实例分类收敛也更快。
3.标签平滑(Smoothing Labels of Hardest Classes)
实例分类在充分利用更多负样本的同时,也会将很多同一语义的样本视为不同类别,因此带来较大的分类噪声。因此,我们将每个类的标签和其对应的top-K相似标签进行平滑操作,降低噪声标签带来的影响。我们利用全连接层参数矩阵的每类代表向量之间的相似度进行top-K计算,每个epoch进行一次即可,因此带来的额外计算很小,可忽略不计。
具体而言,原始的数据xi平滑后的标签为:
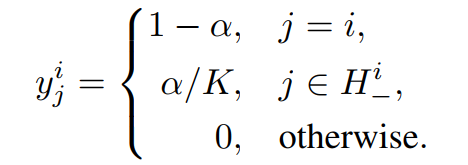
同时对应的loss函数为:
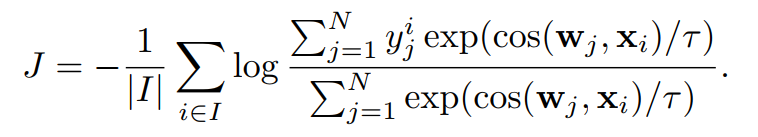
三、结果
本文在ImageNet1K数据集上进行了自监督预训练,并在下游线性分类、检测、分类任务上进行了验证。表6展示了本文方法和其他SOTA方法在ImageNet 1K 线性分类结果对比,我们方法超过SimCLR、PIC和MoCoV2。
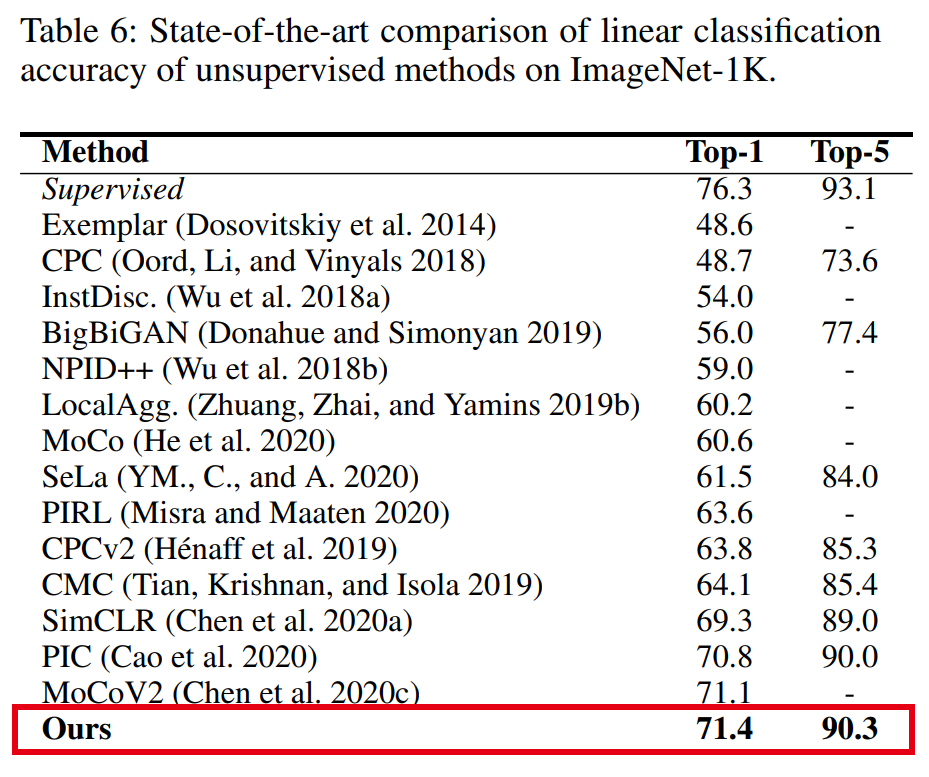
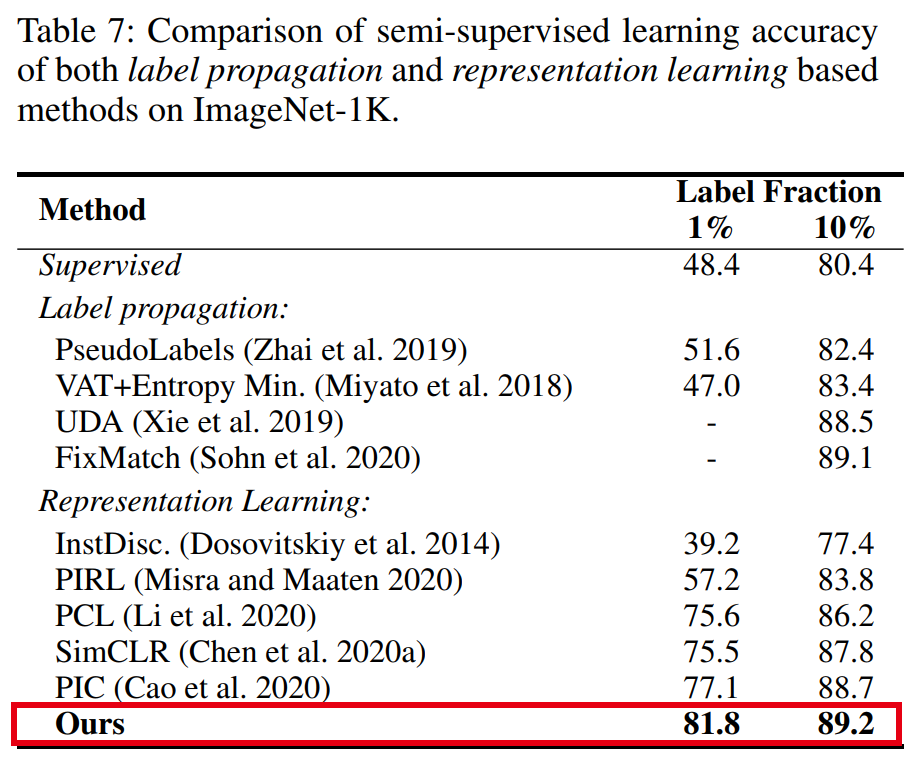
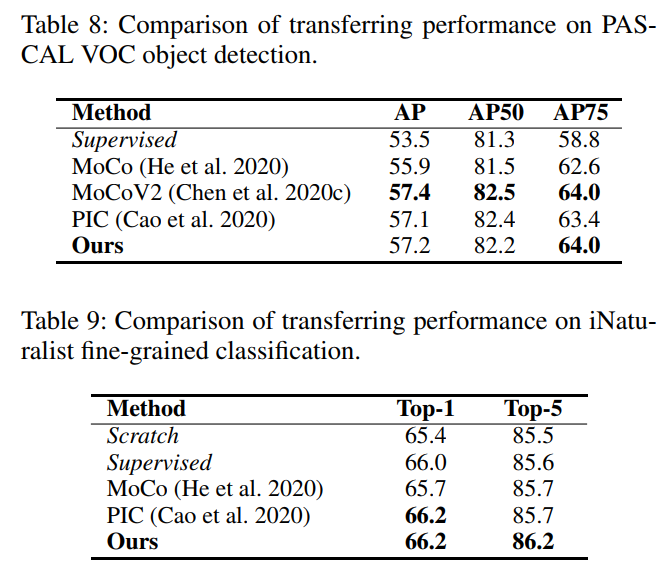
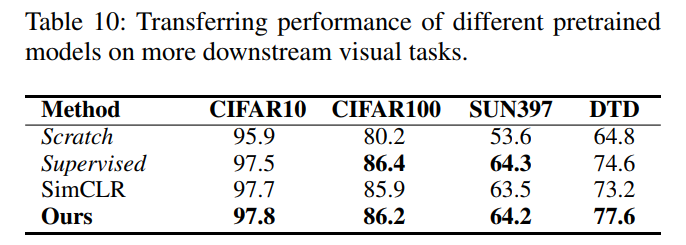
表7~10分别展示了我们的方法和SOTA方法在ImageNet半监督学习、PASCAL VOC物体检测、iNaturalist细粒度识别以及更多下游识别任务的迁移效果对比,可以看到,我们的方法性能均与之前最好的方法相当或优于之前的方法。
*更多文章细节,欢迎参考我们的论文原文。欢迎有志在计算机视觉方面有所作为的同学加入我们,21年、22年毕业生皆可,简历可投递:ly103369 @alibaba-inc.com
论文PDF下载
后台回复:0415,即可下载上述论文PDF
CVPR和Transformer资料下载
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的两篇Transformer综述PDF
CVer-Transformer交流群成立
扫码添加CVer助手,可申请加入CVer-Transformer 微信交流群,方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加小助手微信,进交流群
▲点击上方卡片,关注CVer公众号
整理不易,请给CVer点赞和在看![]()















 367
367











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









