






点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
转载自:Smarter
本文可以认为是Swin Transformer的进阶版本,提出通过十字形等宽的windows做self-attention,减少计算量,然后又提出LePE来做position encoding,进一步提升性能,最终跟SwinT相同计算量下,可以提升2个点左右,最终在ADE20k 语义分割数据集上刷到55.2 mIOU!
可以先看一下SwinT,Swin Transformer对CNN的降维打击
CSWin Transformer: A General Vision Transformer Backbone with Cross-Shaped Windows

论文:https://arxiv.org/abs/2107.00652
01
CSWin Transformer
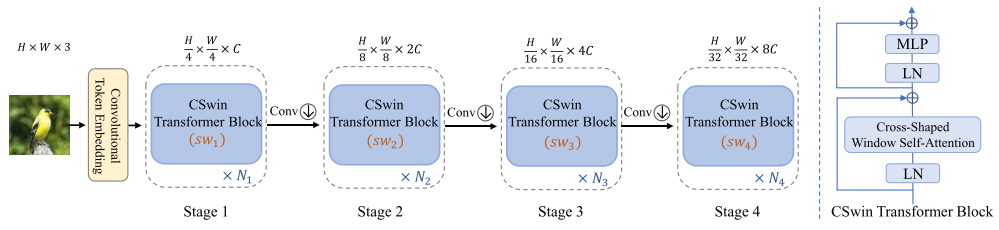
CSWin Transformer整体结构如左图所示。将维度为HxWx3的图片送入CSwin Transformer,先用一个7x7步长为4的卷积进行下采样(相比SwinT,把patchify stem替换成了convolutional stem,这和前几天FAIR的研究不谋而合Convolutional stem is all you need! 探究ViT优化不稳定的本质原因,看来stem用重叠patch的效率更高啊),然后跟SwinT类似构建4个stage,但是Transformer Block替换成了本文的CSwin Transformer Block。另外stage之间的downsample,从merge patch替换成了3x3步长为2的卷积(这又回到了CNN架构的downsample设计了)。
CSWin Transformer Block的结构如右图所示。由两个LN,一个MLP和CSWin Self-Attention组成,还有两个skip connection连接。
Cross-Shaped Window Self-Attention
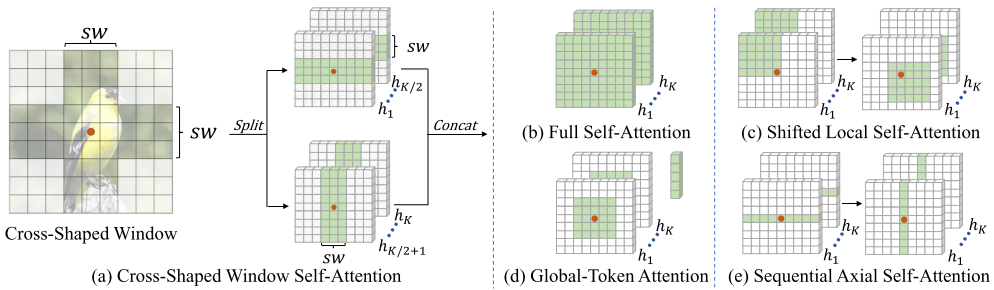
红色点表示query,绿色区域表示key,之前的一些self-attention设计如右图所示。图(b)是一个query点和global区域的key做相关性计算,图(c)是一个query点和local区域的key做相关性计算,通过串联shifted local区域关联更多的区域,图(d)一个query点和local区域的key做相关性计算,图(e)一个query点和横向区域的key做相关性计算,通过串联纵向区域关联更多的区域。
不同于之前的设计,cross-shaped window self-attention将multi-head平均split成两个部分,一部分做横条纹self-attention,另一部分做纵条纹self-attention,然后将输出进行concat。例如图(a),维度为HxWxC的feature map同linearly projected到K个head(每个head的feature map通道数为C/K),然后平均split成两部分,一部分是 到 ,另一部分是 到 ,假设条纹的宽度为sw,将每个head的feature map根据sw划分成不重叠的横条纹(或者纵条纹),记作 ,其中 ,并行计算出所有横纵条纹的self-attention,最后将输出concat起来。CSWin Self-Attention随着stage的加深,增加sw宽度来关联更多的区域。
Locally-Enhanced Positional Encoding

因为self-attention是没有位置信息的,之前的vision transoformer通过引入positional encoding来得到位置信息。比如APE和CPE直接将位置信息添加到self-attention的input token,然后送入vision transformer中,RPE直接将位置信息嵌入到transformer block的相关性计算中,本文提出的LePE直接通过深度卷积学习出value的位置信息,用残差的方式相加,非常方便的嵌入到transformer block中,公式如下:
复杂度
假设
那么4个linear projection需要 ,横条纹的self-attention的 需要 ,与V相乘需要 ,纵条纹同理, 需要 ,与V相乘需要 。
总的复杂度为:
由于横纵两个方向的并行计算和sw宽度的灵活性,CSWin Transformer可以在不增加计算量的情况下,大幅度提升精度。
02
实验
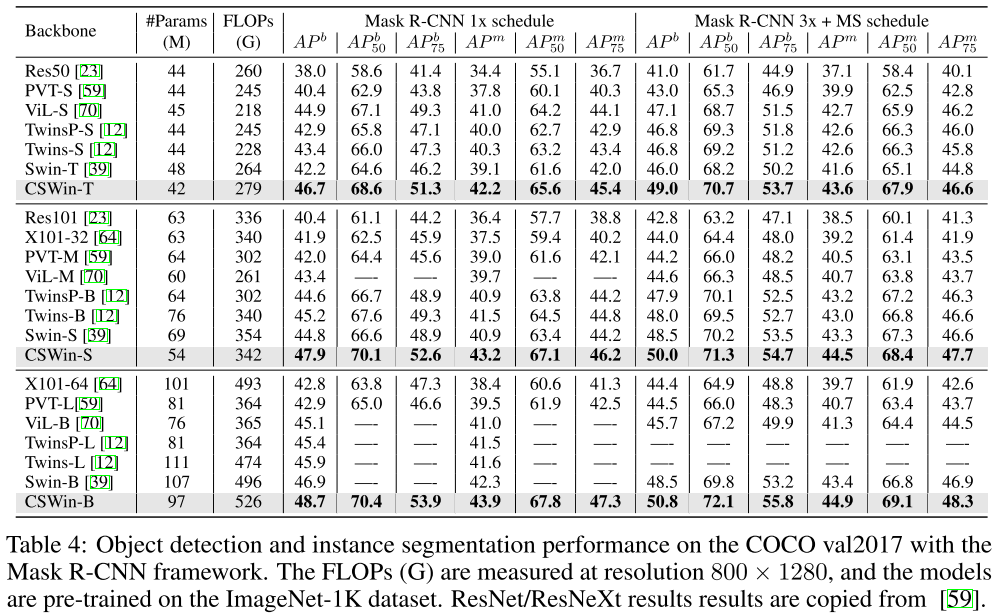
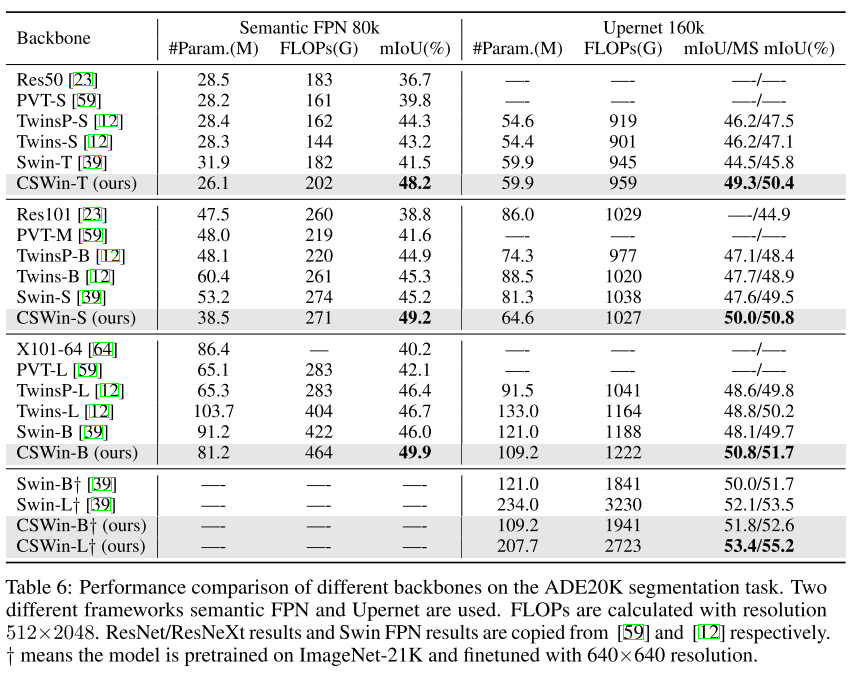
CSwin Transformer在图像分类、目标检测和语义分割中,都大幅度的超过之前的Swin Transformer 大约2个点,并且在ADE20K语义分割数据集上刷到了55.2 mIOU!
图像分类

目标检测
语义分割
消融实验
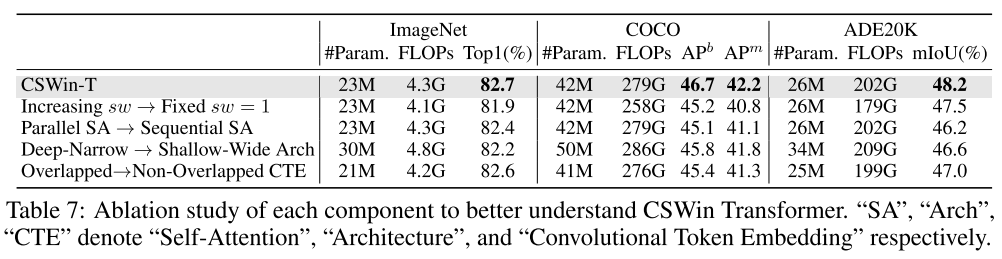
从上表中可以看出,sw宽度随着stage逐渐增加、并行SA、深且窄结构和重叠patch 4个小trick都对最终结果有提升作用。
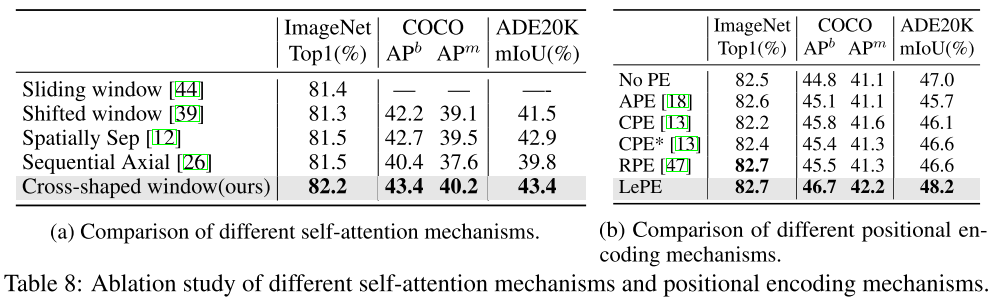
CSWin Self-Attention比起之前的Self-Attention方法更有优势,LePE相比之前引入位置信息的方法更有优势。尤其是在目标检测和语义分割等下游任务中,提升更为明显。
03
总结
事实上CSWin Transformer的实际增益一部分来源于CSWin Self-Attention,另一部分来源于各种杂七杂八的小trick(1. stem部分把不重叠patch改成了重叠patch,2. stage之间用卷积downsample 3.在LePE部分引入深度卷积并且增加了skip connection等等)。
CSWin Self-Attention的优势是,在降低计算量的同时对横纵两个方向并行计算self-attention,并且随着stage的加深,sw宽度变宽,感受野会迅速扩大。
貌似现在vison transformer的stem、downsample、position encoding也都开始倾向于用conv了,退化回CNN架构的设计方式(SwinT使用了CNN的local和hierarchical思想)。到最后,Vision Transformer相比于CNN,可能只有local self-atention是有进步意义的。
上述论文PDF下载
后台回复:最新Backbone,即可下载上述论文PDF
CVPR和Transformer资料下载
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的两篇Transformer综述PDF
CVer-Transformer交流群成立
扫码添加CVer助手,可申请加入CVer-Transformer 微信交流群,方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲长按加小助手微信,进交流群▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









